今回は各機能の検証と少し複雑な(?)FLOWを作ってみる!
前回の検証で、Equalumを使うと複雑なコーディングを実施しないで、データベースを含むSQL周辺の基本が抑えられていれば、誰でもリアルタイム・ストリーミングをデータ処理のプロセスに活用出来る事が確認出来ました。そこで今回はこのデータ処理を便利に行う為に、標準で提供されている幾つかのオペレーターに関する基本的な検証を行ってみたいと思います。
まずはJOINから・・
JOINはデータベースを取り扱った経験をお持ちの方であれば、その概要や留意点についての基本的な情報は理解されていると思いますので、この場ではそれらの詳細についての解説は割愛させて頂き、Equalumではどう使うのか?について検証して行きます。
まずは、前回同様にEvent Stream形式のソース側を2個用意します。
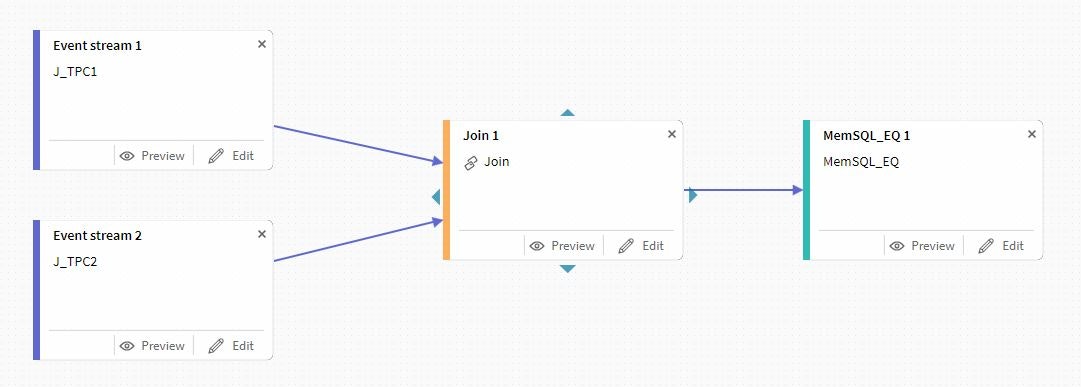
次にOperatorメニューからJOINを選択します。
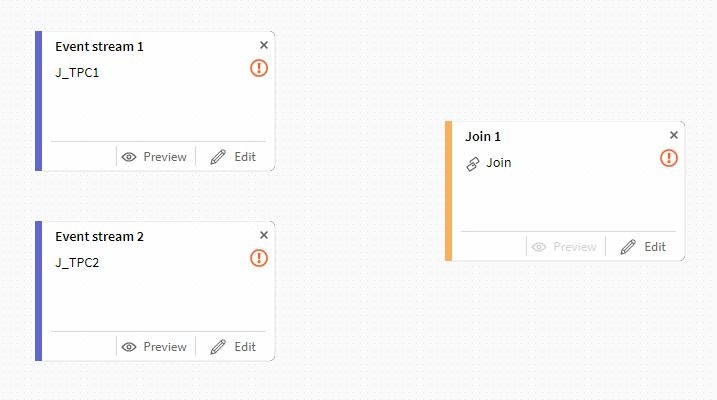
先ほど設置したEvent Streamを接続します。
JoinにあるEditボタンを選択して必要事項を設定します。
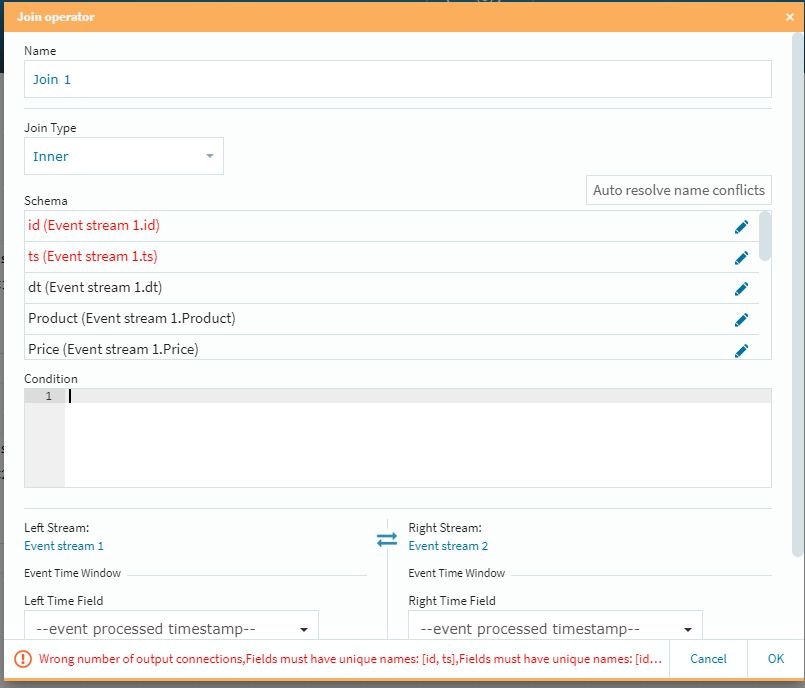
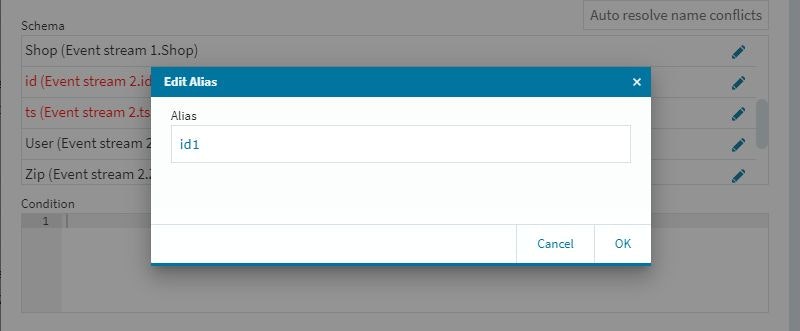
修正が必要な個所が赤字で指示されますので、適宜それらを修正して行きます。今回はidとtsが衝突していますので、この場所で編集作業を行います。編集は、各項目の右端にある編集アイコンを選択して行います。
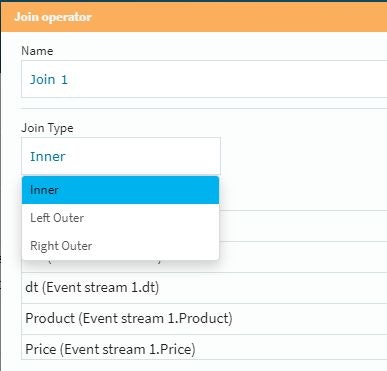
JOINのタイプはプルダウンメニューで選択できます。今回はInnerで検証してみます。
次にConditionの項目にJOINの条件を設定します。今回はデータのIDで強制的に突合させてしまいます。
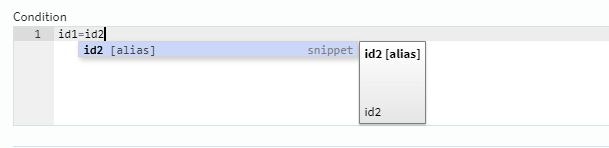
最後に、ストリーミング処理ならでは(?)の条件を忘れずに設定しておきます。
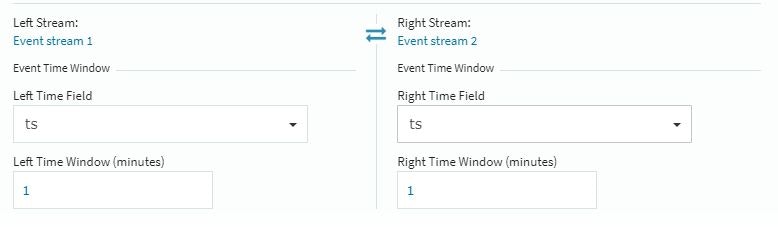
Time Windowについては調整項目になる様ですが、今回の小規模環境では1を設定して検証しました。
次にターゲットのデータソースを定義します。
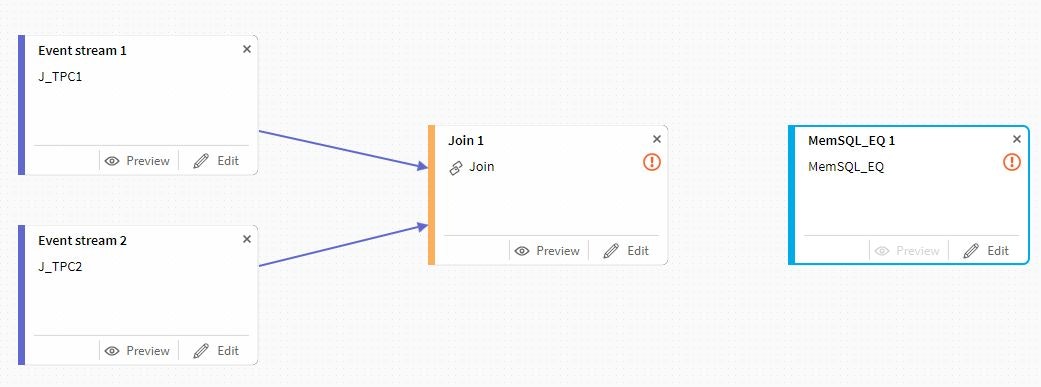
ここまでくれば、Joinとターゲットを接族してターゲット側のEditボタンを選択して、前回同様の設定を行って行けばOKです。テーブル定義もこの場所で自動的にSQL文を生成してくれますので、問題が無ければ確認してそのまま利用できますが、今回の検証では事前定義したテーブルに着地させる事にします。
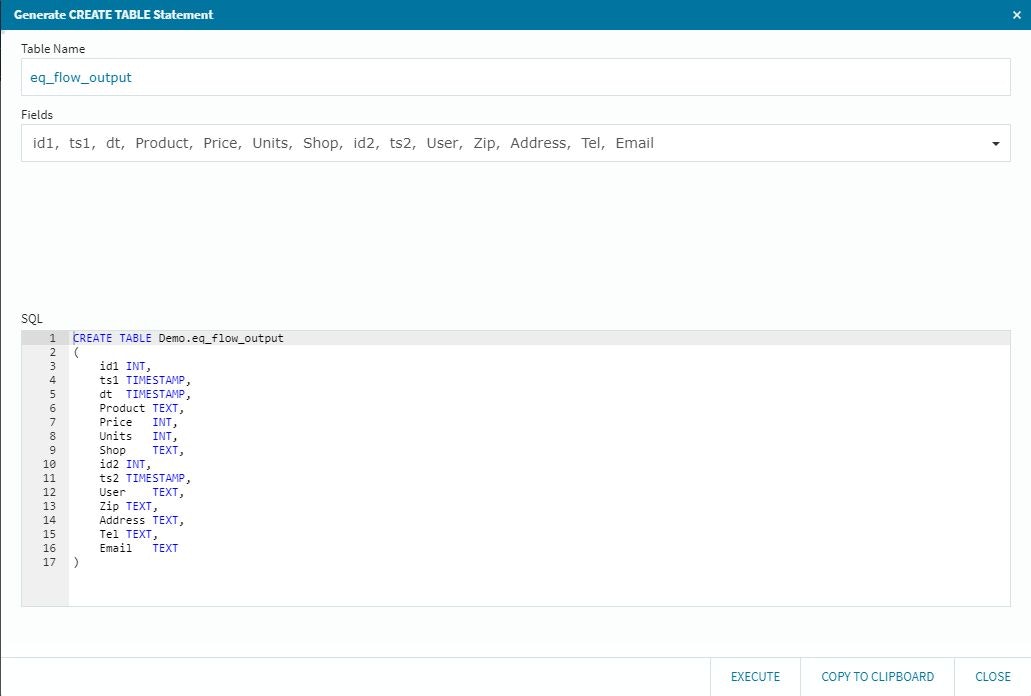
この状態で、前回の検証同様に上流側のデータソースにPythonで自動的にデータを連続挿入し(2つのテーブルにそれぞれ1秒間隔で)、その結果をストリーミング処理しながら下流側のデータソースのテーブルに反映させます。(シンプル&力技でのJOINですので、出来上がりは美しくないかもしれませんが・・・そこは基本機能の検証という事でご容赦の程。。)
まずは、下流側のターゲットソース上のテーブルを確認します。

上流側のテーブルを確認します。
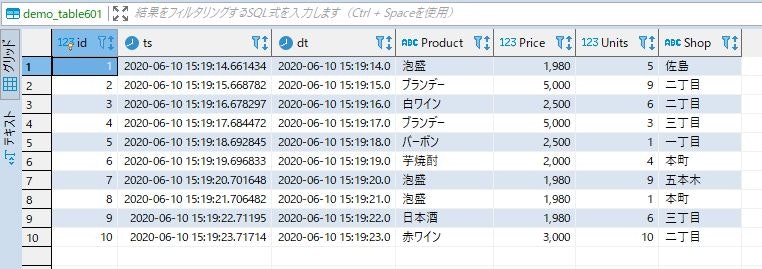
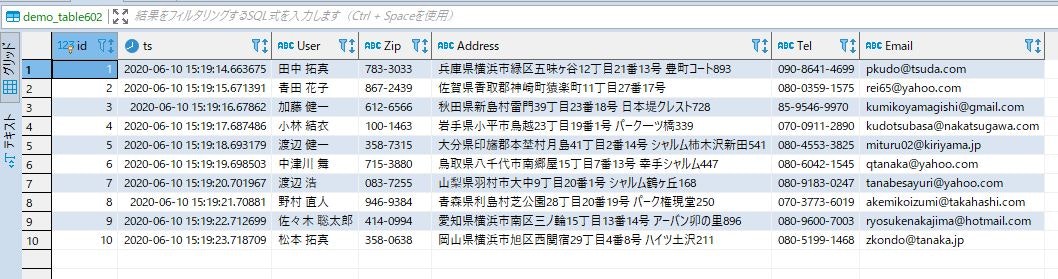
データ数が少なかったので、上流側のテーブルに挿入が始まってから終わるまでの時間が一瞬で終了し、ほぼ同時に下流側のストリーミングJOIN処理も出来上がってしまいましたので呆気なく検証は終了です。
たぶん一番使いそうなTransformを検証
次にTransformを検証してみます。
この検証では、シナリオとして消費税のカラムを現状のデータフローに対して「後付け」で設定して下流側のテーブルに反映させてみる事にします(その位の準備は事前に・・・という話もありますが・・・)
まずは、最上流のデータソースの準備をいつも通りに行い、OperatorからTransformを選択してFlowを接続します。
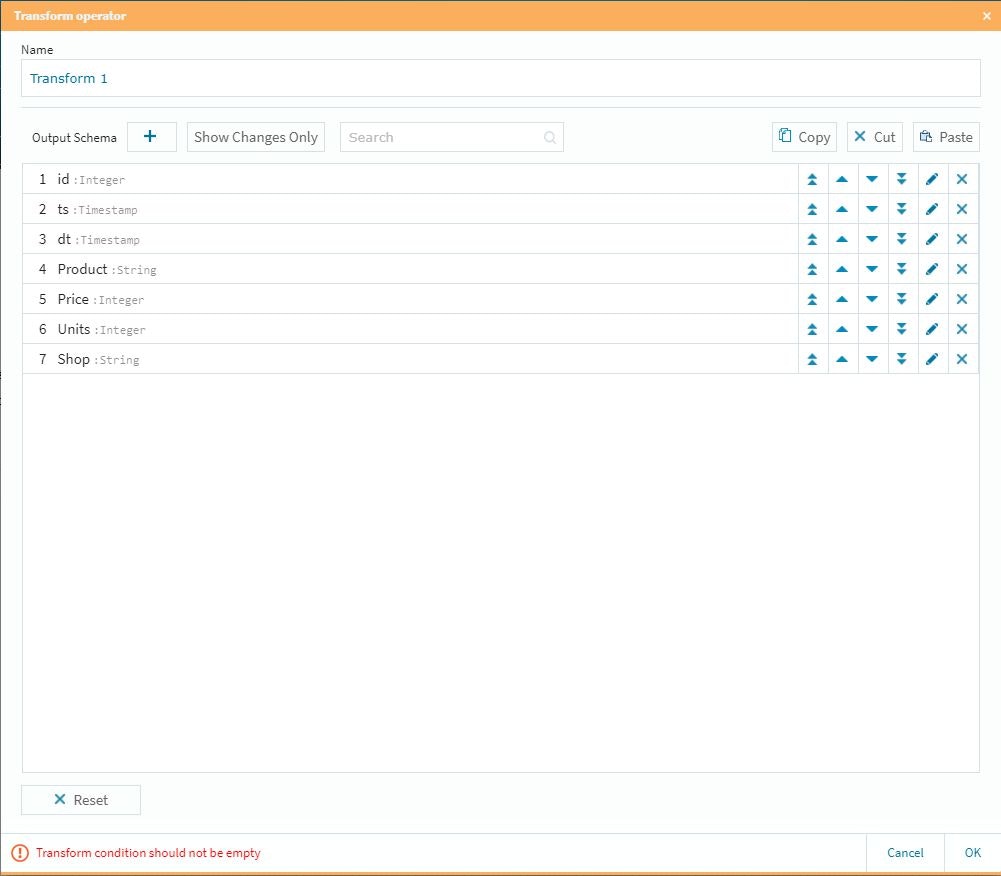
次に「+」ボタンを選択し
取り扱うフィールドを追加します。
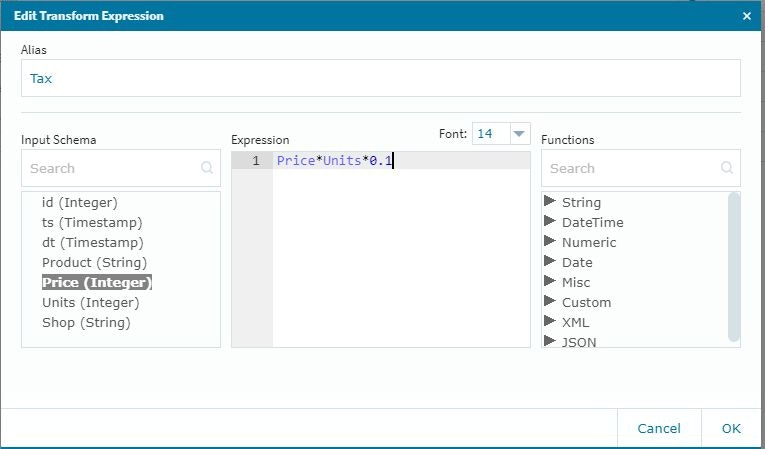
基本的にこの設定で新たなカラムが「この段階で設定される」事になります。
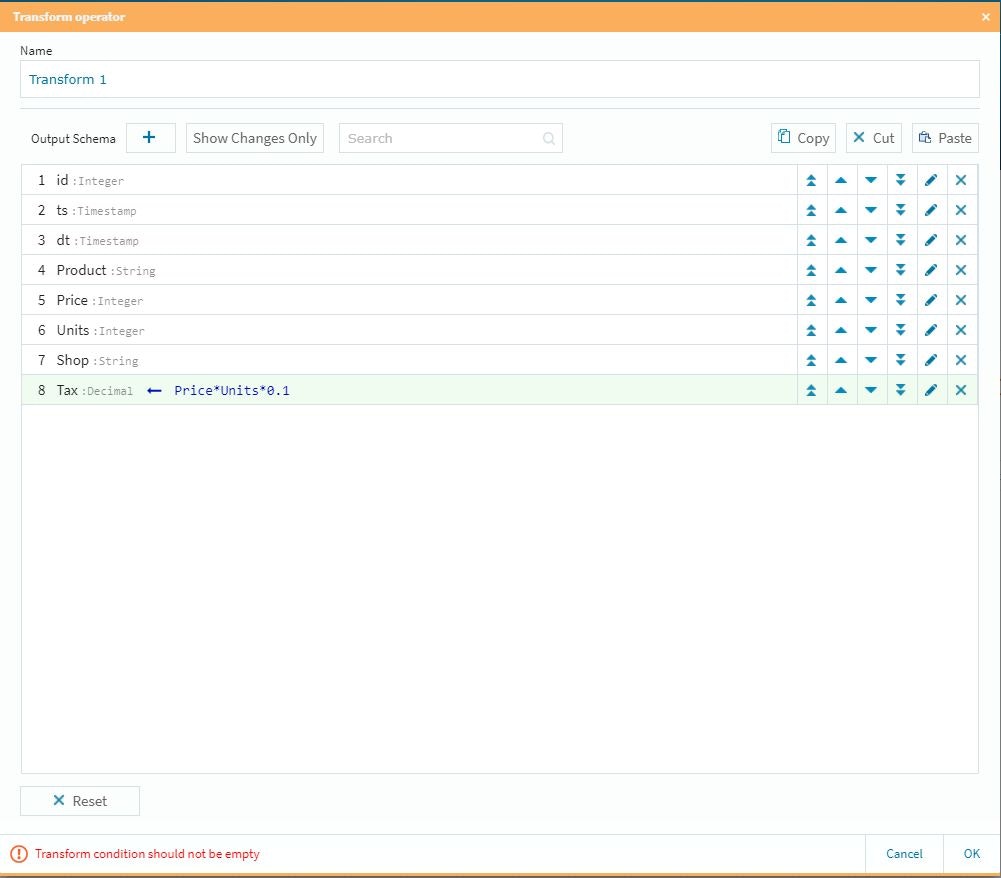
カラムの順番は右側の上下ボタンで調整が可能です。
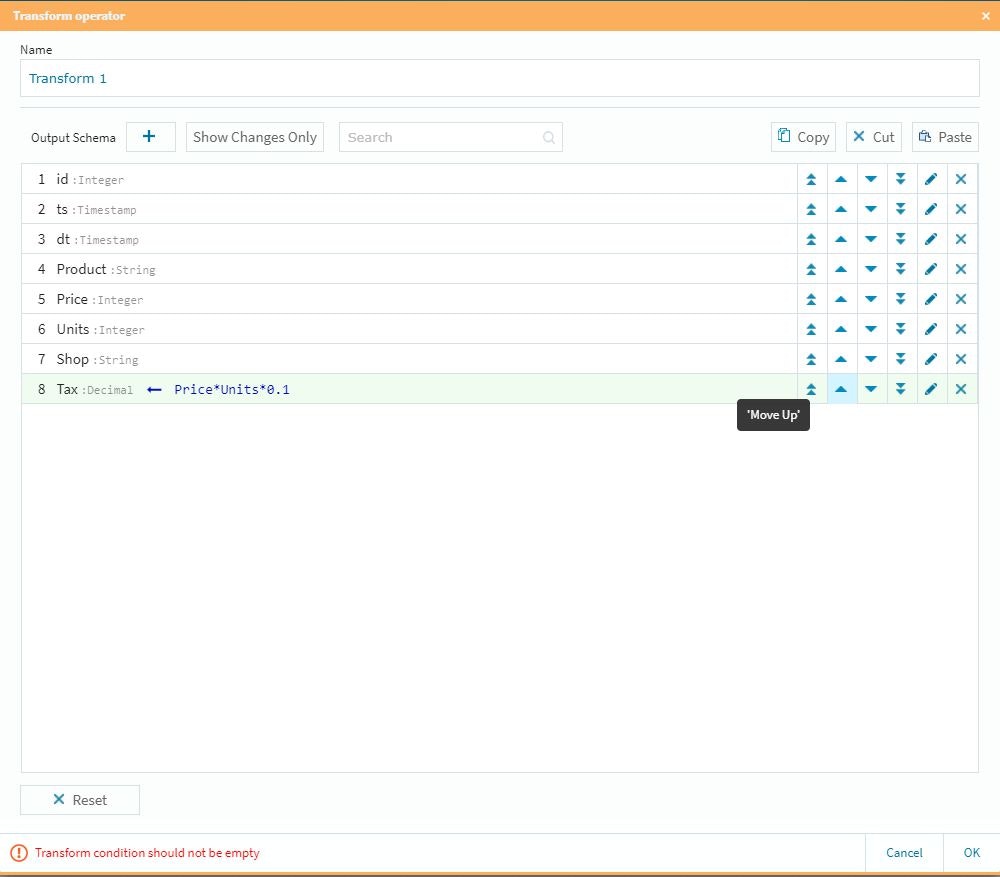
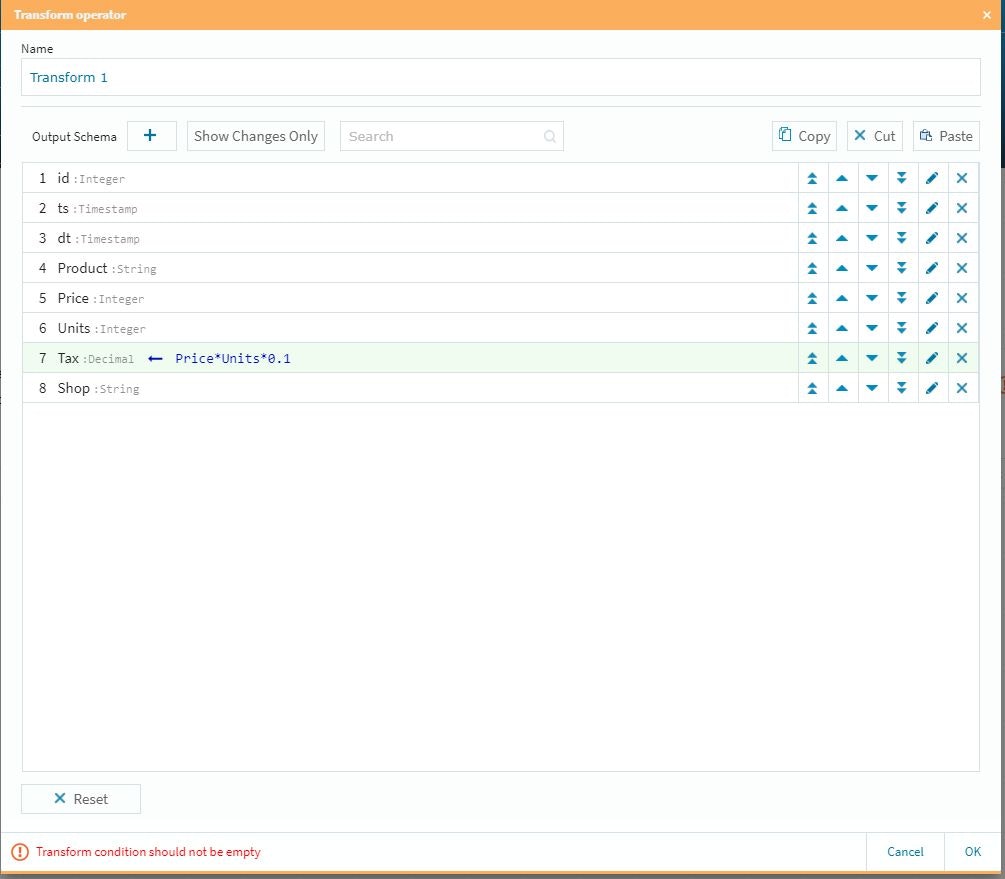
これで右下のOKボタンを選択し、ターゲットのデータソース(この場合もFlow設定すると上流側である今回のTransform情報をベースにプロトタイプを作成してくれますので、その情報を活用してテーブルを生成する事が可能です)を設定し、今まで同様に1秒毎にデータを自動生成して上流側に挿入すれば、そのアクションを自動検知して今回設定した手順の処理を行い、下流側のターゲットテーブルを即時生成していく形になります。
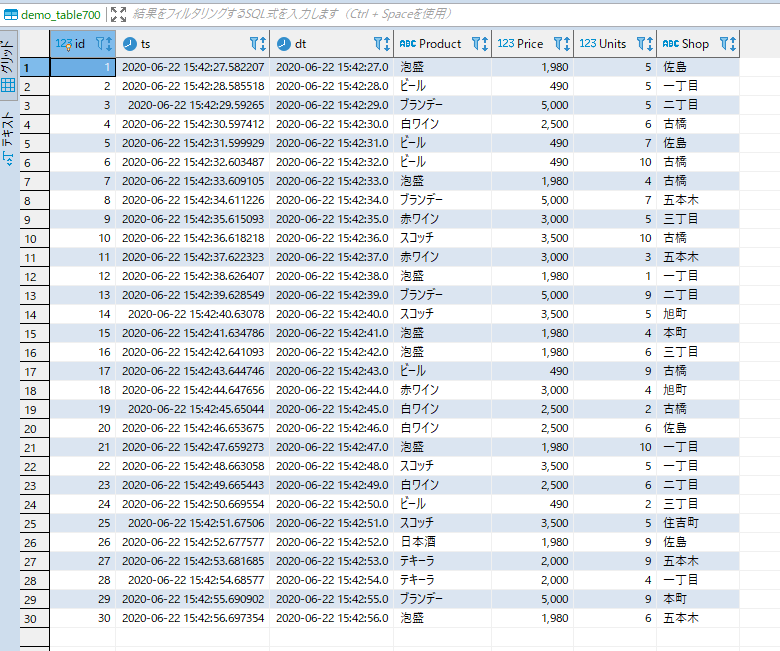
上流側に自動挿入されたデータはこんな感じになります。
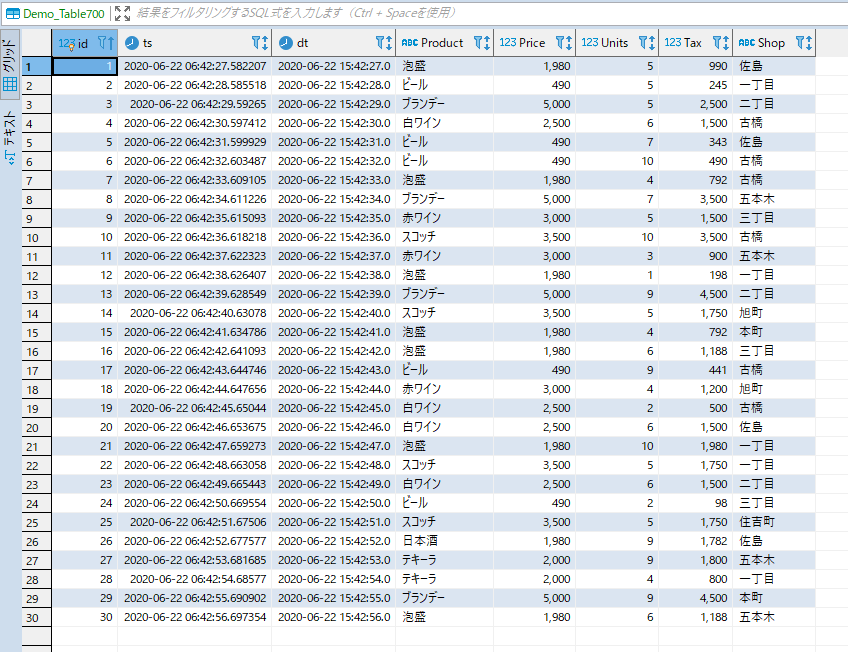
Tax項目を途中追加して生成された下流側のテーブルはこんな感じになります。
今回のまとめ
駆け足になりましたが、今回はJOINとTRANSFORMの検証を行いました。
複雑なkafka系コーディングや、Spark連携等の作業を考える必要なく、かなり高度なリアルタイム・データストリーミングをデザイン出来る可能性は感じて頂けたかと思いますが、次回の検証では
さらに複雑(?)な流れ
の作成に挑戦してみたいと思います。
ゼロコーディングで高度なkafka/Spark連携のストリーミング環境を構築!
専用の最適化・専用実装を行ったDeepなkafkaの世界には負けるかもしれませんが、誰でもかなり早いkafkaストリーミングでのデータ連携・活用環境が作れる!という点においては、非常に可能性を秘めた環境であると言えるでしょう。
バッチ処理しか選択肢が無い時代は過去の話になりました。
今をデータ活用で変えるのであれば、その選択肢は必然的にリアルタイム・ストリーミングになると思います。
データで今を変えて未来を創る!!
これがDxにおけるデータ・ドリブンの真骨頂なのだと思います・・・
謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。