ビックデータ編:1では、Cloudera Impalaとの接続検証を、Cloudera社が公開している仮想イメージを活用させて頂く事で実際の手順を含めてご紹介致しました。
今回は、その環境設定の際に見つけたSolr Searchについて同様に接続検証を行いたいと思います。
(1)接続設定
まずは、いつもの通りadminでZoomdataに入り、歯車アイコンのSources画面を出します。
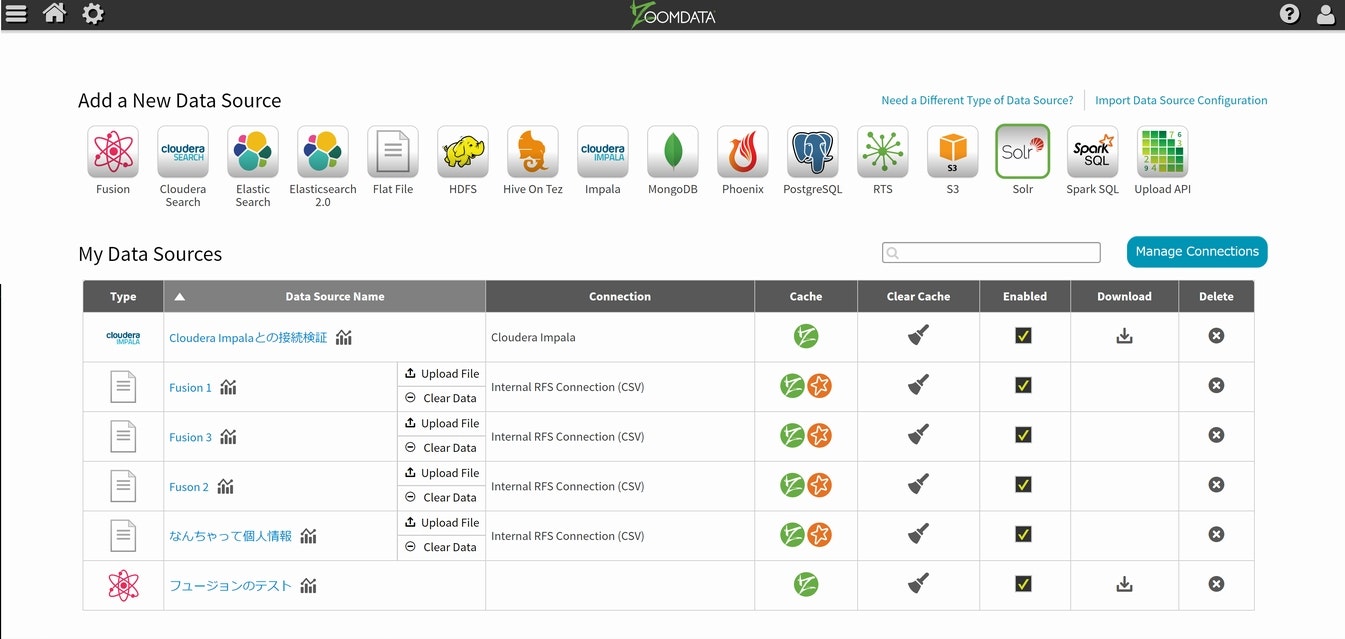
Solrのアイコンが有りますので、それを選択します。
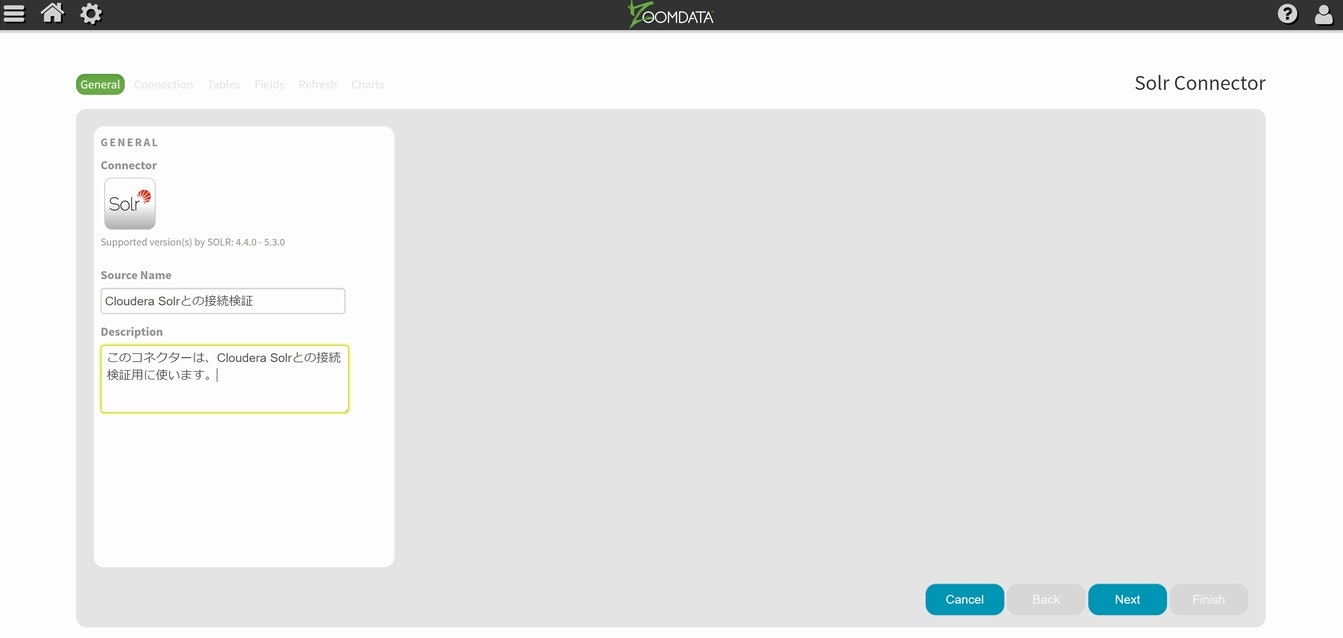
必要事項を入力してNextを選択します。
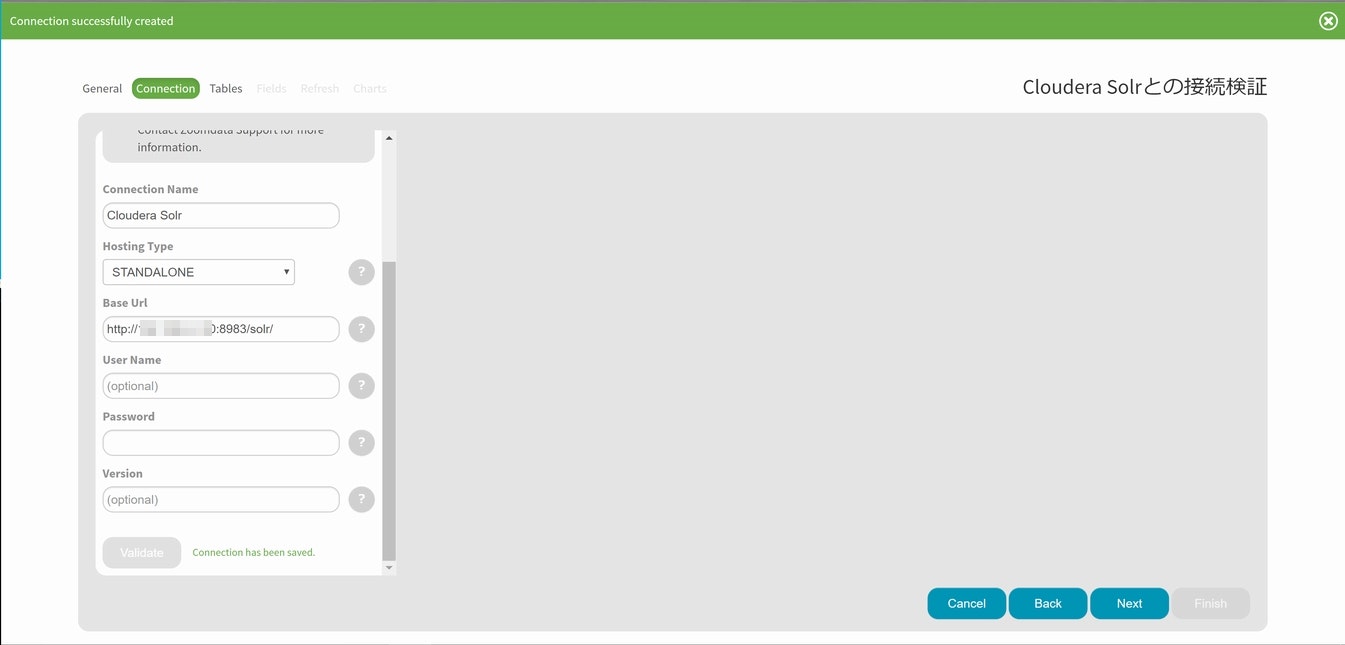
接続に関する情報を設定しますが、今回は以下の通りとしました。
Connection Name : Cloudera Solr
Hosting Type : STANDALONE
Base Url : http://xxx.xxx.xxx.xxx:8983/solr/
ここで、xxx.xxx.xxx.xxxは、Cloudera Solrをセットアップした仮想サーバのアドレスを使います。
設定が終わりValidateを選択するとパラメータに問題が無ければ、画面上部に緑のポップアップが出てきますので、下部左側にあるNextを選択してください。
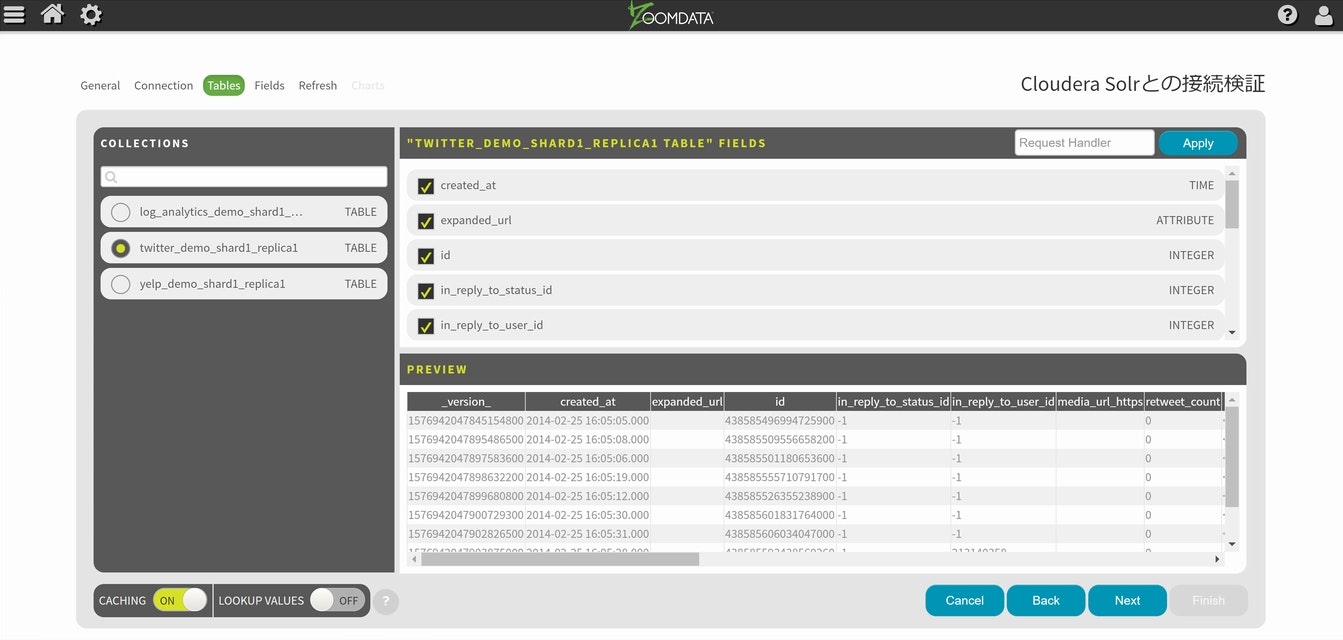
デモ環境が幾つか出てくると思いますので、今回は・・・twitter_demo_shard1_replica1を選択してみます。
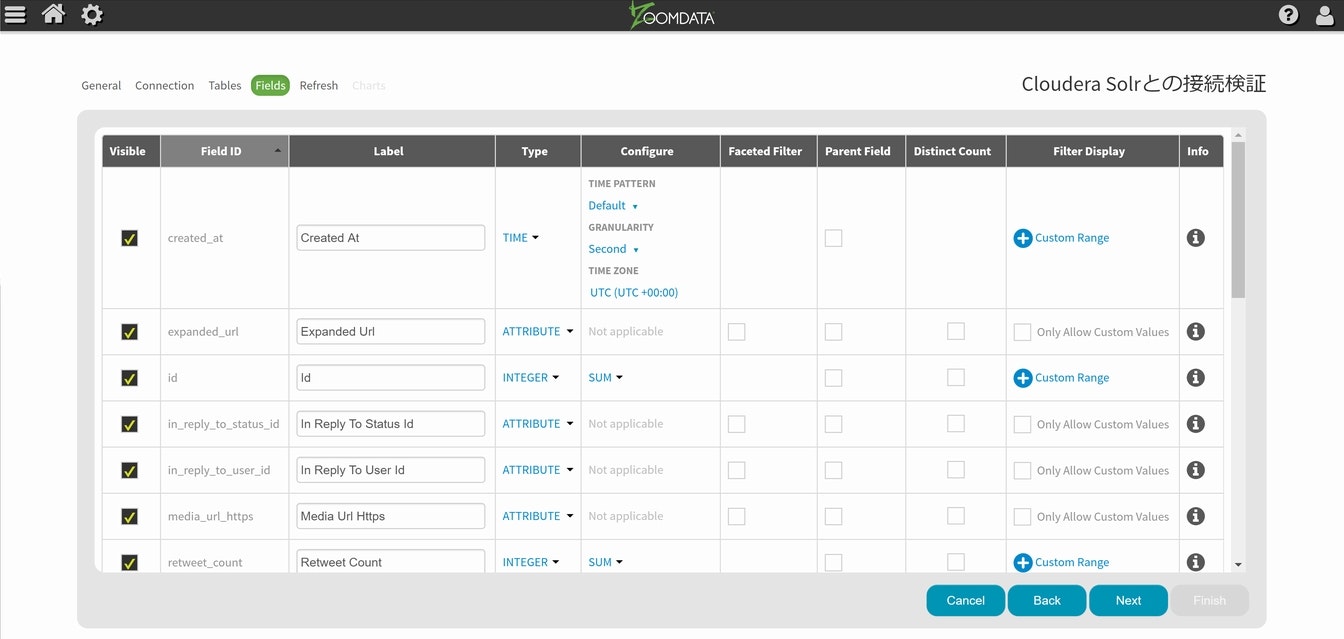
時間軸に関して、created_atがそのまま使えそうなので、残りの項目はサクッと進めていきます。
(2)ダッシュボードで検証
前回までは、一旦メイン画面まで戻ってから作業を行っていましたが、今回は設定成功の画面上からダッシュボードを作成してみます。
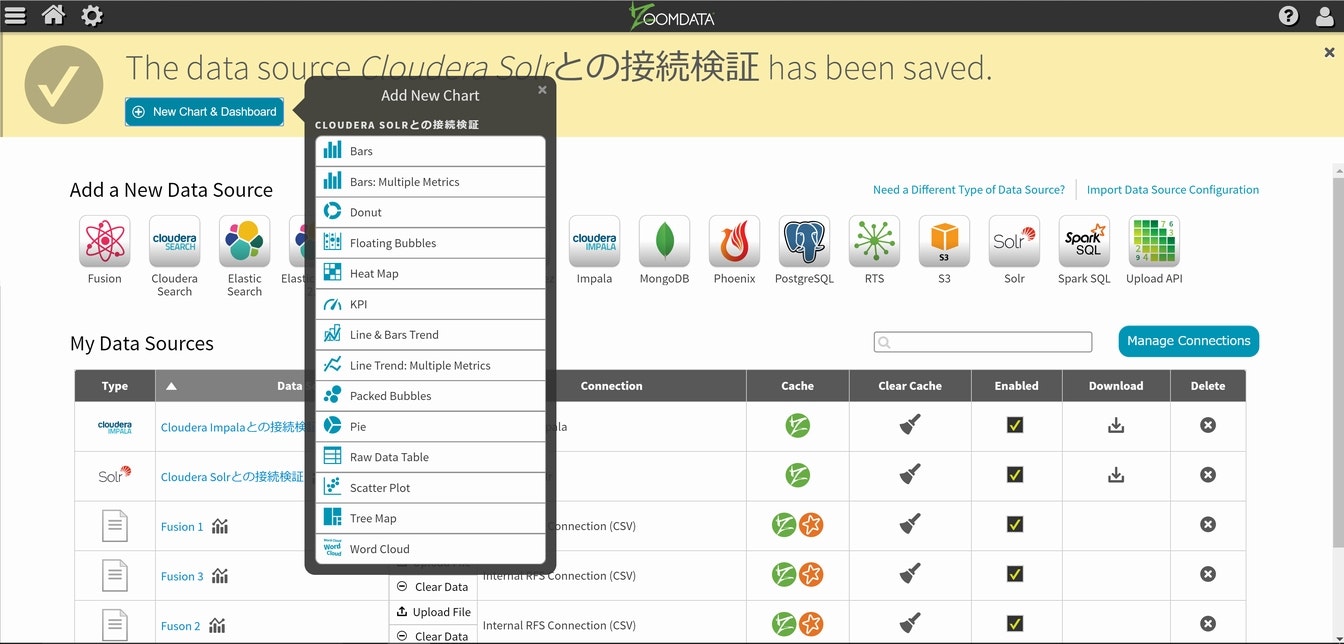
画面右上にある緑色の+ New Chart & Dashboardを選択すると、利用可能なチャートのメニューがポップアップしてきますので、その中からWord Cloudを使ってみます。
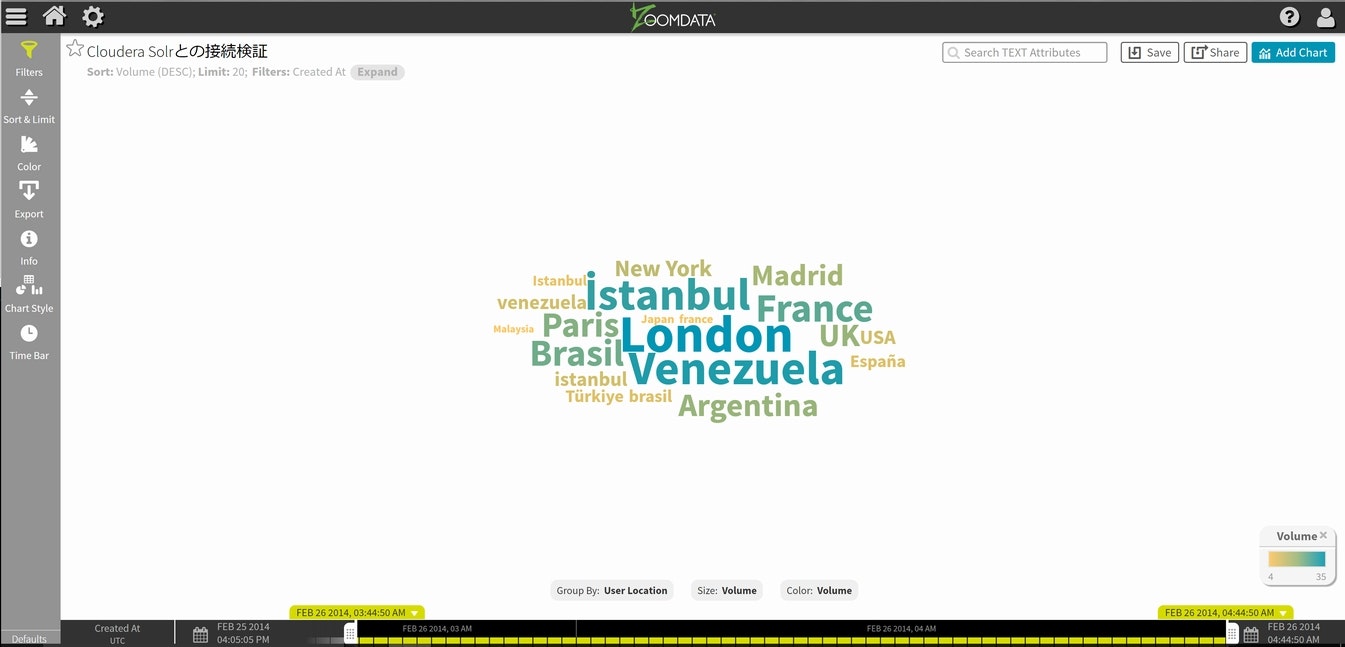
SNSの発信ユーザのロケーションに関する傾向が地名の大きさと色で表示されてくると思います。
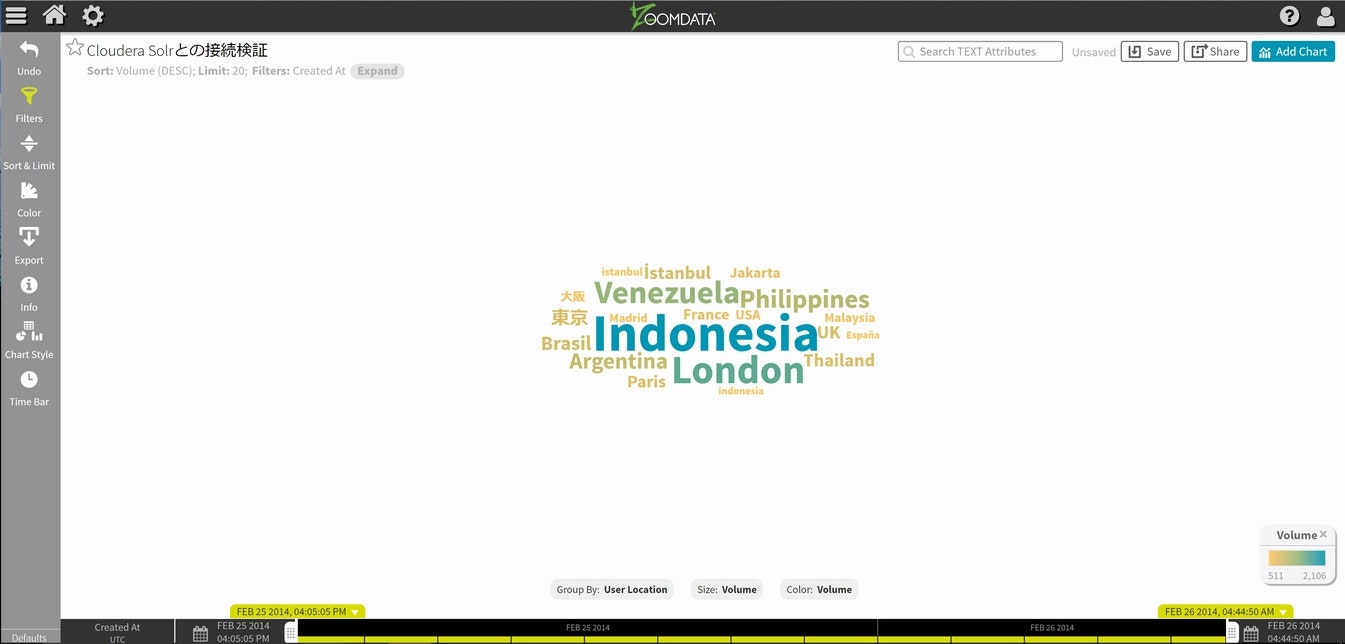
次に、画面下側にあるTime Barを左右に移動させてみてください。その情報にリンクする形でWord Cloudの表示が変わっていく事が確認できると思います。
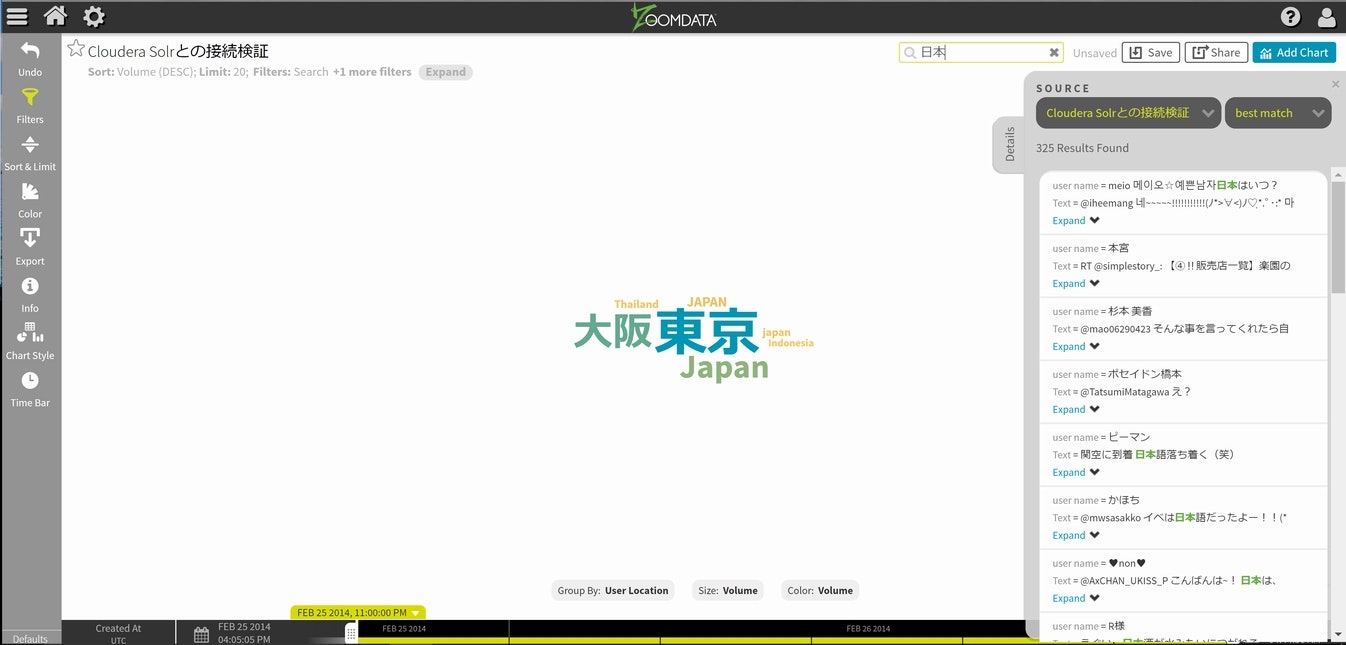
また、画面の右上部分にあるSearchフィールドに検索対象の文字列を入力する事により、Solr上に格納されている実際のデータを検索する事が可能です。(同時にその条件での発生場所とその頻度の表示が変わります)
同様にSolr上に格納されている幾つかのデータに関して、今までの検証と同様にチャートを作成してみます。
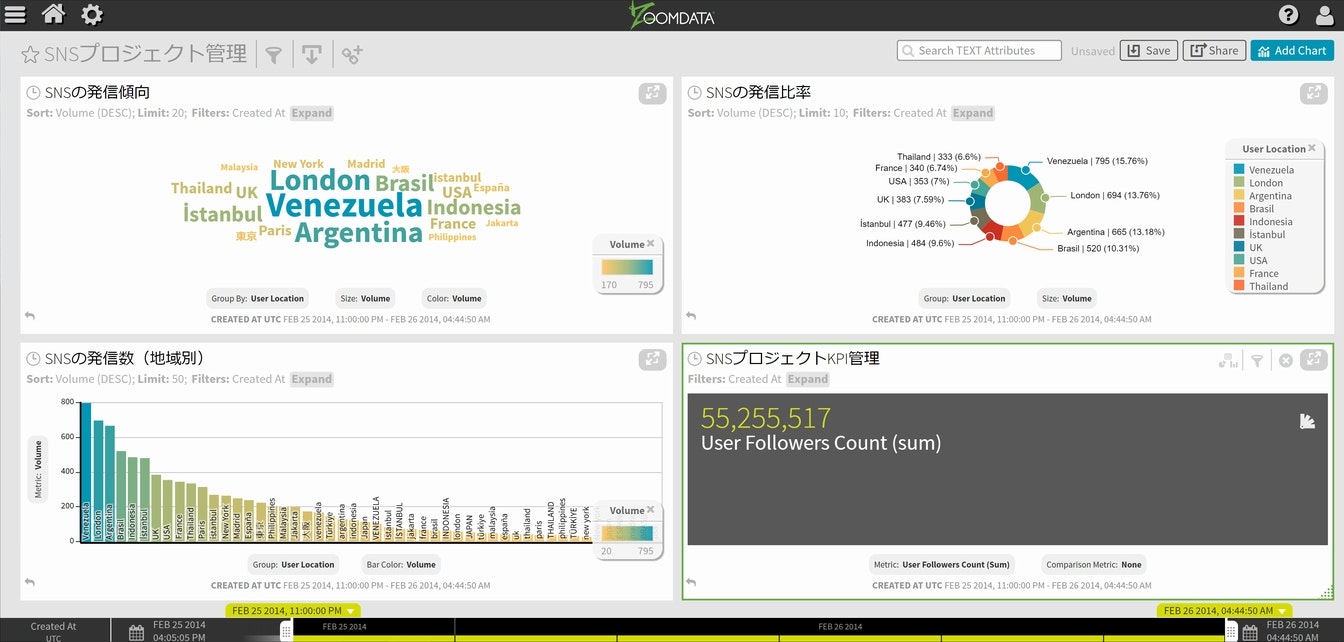
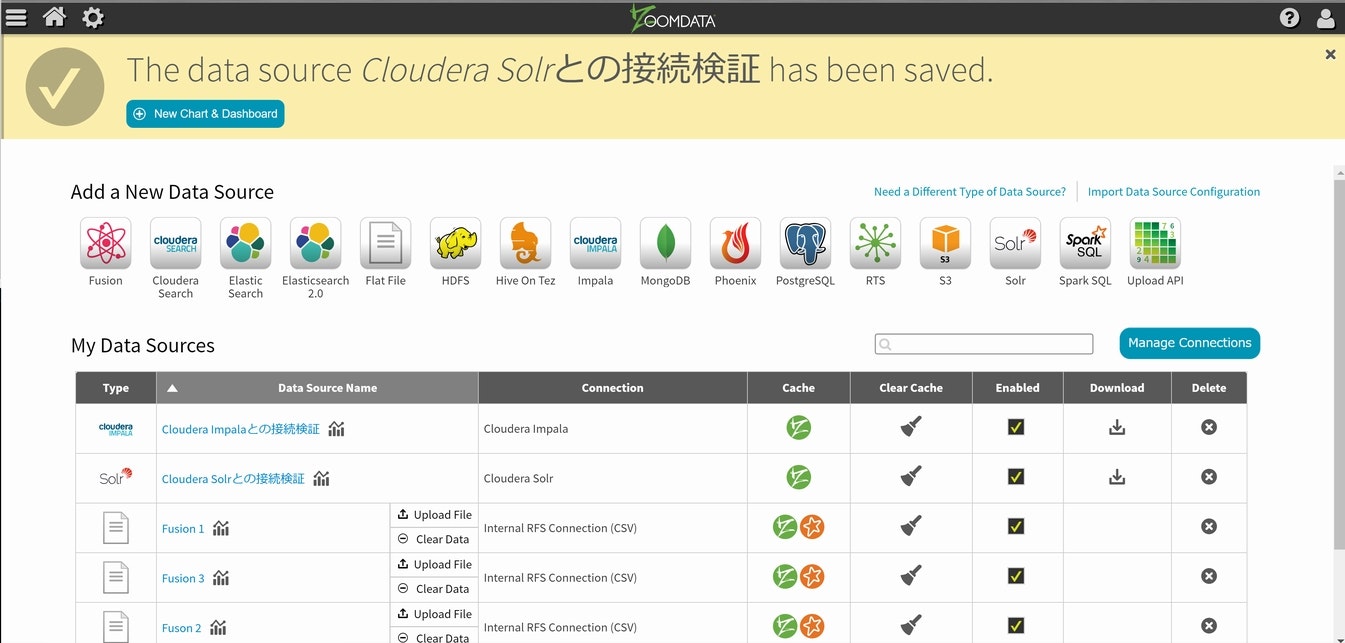
次回以降の為に、出来たダッシュボードを保存します。
無事に保存が出来ましたので、次回以降はここからスタート出来る様になりました。
(3)今回のまとめ
今回の接続検証では、SNS情報がスタティックに事前格納されたデータに対してのアクセス検証になりましたが、例えば時々刻々とSolrに対して追記される構成にし、そのデータソースに対するアクセスをZoomdata側で柔軟に設定する事により、単純なビッグデータへのアクセスとして高効率・高速に取り扱う事が可能になりますので、シンプルで柔軟なリアスタイム・ストリーミング解析を実現する事ができるようになります。
マイクロクエリーとオンメモリ技術の相乗効果は、今まで諦めていたようなビッグデータの利用法に新しい可能性をもたらすと同時に、最終データが出来上がる過程を観測・解析する事による、大きな付加価値と競合優位性を実現できるようになるでしょう。
次回は、Hive On Tezを使った接続をご紹介したいと思います。