前回の続き・・・
前回は、Equalumの概要説明を行いましたが、今回の実践編ではリアルにストリーミング処理を行ってみたいと思います。構想としてはPythonを使って自動的にデータを生成する仕組みを作り、そのデータを上流側のデータソースに連続して挿入処理を行う事で実現させる戦略で行こうと思います。
全体の流れ的には・・・
(1)上流側のソーステーブルを定義する(Pythonで実装)
(2)Equalumを使って基本的なストリーミング処理を設定する(今回は実質レプリケーション形式)
(3)自動データ生成ツール(Pythonで実装)を起動してEqualumダッシュボードで観察
(4)動作結果を確認
になります。
まずは、上流側データソースにテーブルを作る仕組みを実装します。実際にはSQLを作業毎に発行しても良いのですが、1回作れば何度も使えるので今回は「再利用性を優先」して下記の通り作ってみました(デキについては・・・・まあ、動けば良いということで(汗))データカラムの設定部分は意図的に3種類に分けておきました。これは、最終的にテーブルをカラムデータを自動分割して3種類の下流側テーブルに挿入する検証計画の為の準備になります。
# coding: utf-8
#
# ストリーミング処理検証用テーブル生成
#
# 事前準備
# MySQL側にカラムのみのテーブルを作成
# 利用するテーブル Demo_Table999
# 利用するデータベース Demo@MySQL_Win10
#
# 初期設定
import sys
stdout = sys.stdout
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdout = stdout
import pymysql.cursors
# 検証処理開始
print("MySQL側に検証用のテーブルを作成します!!")
print
try:
# 既存のテーブルを初期化
Table_Init = "DROP TABLE IF EXISTS Demo_Table999"
# デモ用のテーブル定義 DC1:購買テーブル向け DC2:支払いテーブル向け DC3:物流テーブル向け
DC1 = "dt DATETIME, Product VARCHAR(20),Price INT,Units INT,Shop VARCHAR(20),"
DC2 = "Card VARCHAR(40),Number VARCHAR(30),Payment INT,Tax INT,"
DC3 = "User VARCHAR(20),Zip VARCHAR(10),Address VARCHAR(60),Tel VARCHAR(15),Email VARCHAR(40)"
# 検証用のテーブルの作成
Table_Create = "CREATE TABLE IF NOT EXISTS Demo_Table999(id INT auto_increment primary key,"+DC1+DC2+DC3+")"
# MySQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx', # 今回はWindow版のMySQLをネイティブに使います
port=3306, # お約束のポート番号
user='root',
password='password', # rootアカウントのパスワード
db='Demo', # 検証に利用するデータベース(事前作成)
charset='utf8mb4', # 日本語を処理するので・・
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
# 既存テーブルの初期化
cursor.execute(Table_Init)
db.commit()
# 新規にテーブルを作成
cursor.execute(Table_Create)
db.commit()
except KeyboardInterrupt:
print('!!!!! 割り込み発生 !!!!!')
finally:
# データベースコネクションを閉じる
db.close()
print("処理終了!!")
print
print("引き続きMemSQL側に受け用のテーブルを作成してください")
print
次に自動的に日本語の検証データを生成する仕組みを実装します。今回の検証ではPython界で有名なFakerを使ってみたいと思います。この部分に関する情報は既に多くの先人の皆様がネット上に情報を発信されていますので、この場では詳しい解説等は省かせて頂きますので、何卒ご理解居の程を・・・(冷汗)
# coding: utf-8
#
# ストリーミング処理用日本語データの自動生成
#
# 事前準備
# MySQL側にカラムのみのテーブルを作成
# 利用するテーブル Demo_Table999
# 利用するデータベース Demo@MySQL_Win10
#
# 初期設定
import sys
stdout = sys.stdout
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdout = stdout
import time
import pymysql.cursors
# 検証処理開始
print("データの自動生成開始!!")
print
try:
# Pythonのデータ自動生成機能の設定
from faker.factory import Factory
Faker = Factory.create
fakegen = Faker()
fakegen.seed(0)
fakegen = Faker("ja_JP")
# デモで使うメタデータ定義
Product_Name = ["日本酒","バーボン","ビール","芋焼酎","赤ワイン","白ワイン","スコッチ","ブランデー","泡盛","テキーラ"]
Product_Price = [1980, 2500, 490, 2000, 3000, 2500, 3500, 5000, 1980, 2000]
Shop_Name = ["旭町","三丁目","本町","二丁目","西新町","一丁目","住吉町","佐島","五本木","古橋"]
# 生成するデータの総数 -> ここは適宜変更
Loop_Count = 500
# 発生タイミングの調整
# それっぽくする(ランダム的に)場合
Base_Count = 1600000
# 一定間隔の場合(システム時間で秒単位)
Sleep_Wait = 1
# 消費税率(10%)
Tax_Unit = 0.1
# その他の変数
Counter = 0
Work_Count = 1
# 書き込み用のデータカラム DL1:購買 DL2:支払い DL3:物流
DL1 = "dt,Product,Price,Units,Shop,"
DL2 = "Card,Number,Payment,Tax,"
DL3 = "User,Zip,Address,Tel,Email"
# MySQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx',
port=3306,
user='root',
password='password',
db='Demo',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
# 検証データの生成
while Counter < Loop_Count:
# 受付日時の情報
from datetime import datetime
dt = datetime.now().strftime("%Y/%m/%d %H:%M:%S")
# 購買情報の生成
Product_ID = fakegen.random_digit()
Product = Product_Name[Product_ID]
Price = Product_Price[Product_ID]
Shop = Shop_Name[fakegen.random_digit()]
Units = fakegen.random_digit() + 1
# 支払情報の生成
Payment = Price * Units
Tax = int(Payment * Tax_Unit)
if str(fakegen.pybool()) == "True":
Card = "Cash"
else:
Card = fakegen.credit_card_provider()
Number = fakegen.credit_card_number()
if Card == "Cash": Number = "N/A"
# 物流情報の生成
User = fakegen.name()
Zip = fakegen.zipcode()
Address = fakegen.address()
Tel = fakegen.phone_number()
Email = fakegen.ascii_email()
# 此処から先を各データベースの規程テーブルへ書き込む
DV1 = dt+"','"+Product+"','"+str(Price)+"','"+str(Units)+"','"+Shop+"','"
DV2 = Card+"','"+Number+"','"+str(Payment)+"','"+str(Tax)+"','"
DV3 = User+"','"+Zip+"','"+Address+"','"+Tel+"','"+str(Email)
sql_data = "INSERT INTO Demo_Table999("+DL1+DL2+DL3+") VALUES('"+DV1+DV2+DV3+"')"
# データベースへの書き込み
cursor.execute(sql_data)
db.commit()
# コンソールに生成データを表示(不要な場合はコメントアウトする)
print sql_data
print
# 時間調整用(一定間隔)
time.sleep(Sleep_Wait)
# 乱数を用いた生成タイミングの調整(今回の検証では使いません)
#Wait_Loop = Base_Count * fakegen.random_digit() + 1
#for i in range(Wait_Loop):
# Work_Count = Work_Count + i
# ループカウンタの更新
Counter=Counter+1
# デバッグ用データ表示
#print("生成済みデータ番号 : " + str(Counter))
except KeyboardInterrupt:
print('!!!!! 割り込み発生 !!!!!')
finally:
# デバッグ用データ表示
print
print("生成したデータの総数 : " + str(Counter))
# データベースコネクションを閉じる
db.close()
print("処理終了!!")
MySQL側の設定について
Equalumは、MySQLが機能として実装しているバイナリログの状況変化を活用する形で、非常に高速・高効率なストリーミング機能を実現しています。(MySQL以外のデータベースでも、類似の機能を実装している場合(Oracle,MS-SQL等)には、同様にストリーミング機能を活用する事が出来るようになっています)
今回検証で利用するMySQLの場合、各プラットホーム上で設定される初期化ファイルの中に、バイナリログを使う設定を記述しなければなりませんので、下記の情報を参考に忘れずに初期化ファイルを更新しておく必要が有るので、取り急ぎ以下の作業を行います。
今回は、WindowsネイティブのMySQLを使いますので、エクスプローラのオプションで隠しファイル等を見れるようにしてから、

ProgramDataフォルダ(通常は隠れています)を開いてMySQLフォルダ内の利用バージョンフォルダに移動します。
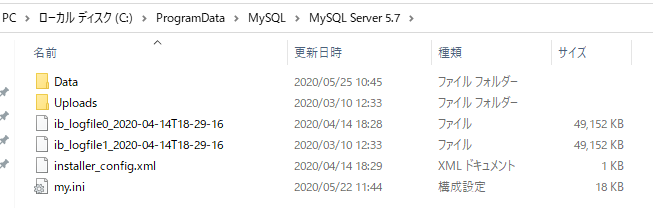
この中にmy.iniというファイルが有ると思いますので、そのファイルに以下の情報を設定します。
[mysqld]
log-bin=mysql-bin
server-id=9
binlog_format=row
binlog_row_image=full
expire_logs_days= 10
idについては、ユニークであれば問題無いと思いますので、今回は一桁最後の番号にしてみました。この辺のバイナリログ設定に関する情報は、既に多くの先人の皆様が情報共有されていますので、詳しい意味等はそれらの情報を参考にしてみてください。
MySQLの文字コードの設定
今回はMySQLに対して日本語データの出し入れを行いますので、念のため文字コードの設定も行っておきます。基本的には以下の3項目に対しての設定が実施されていれば、文字化け等は起きないと思いますので、前述のバイナリログの設定と併せて実施しておきました。
[mysql]
default-character-set=utf8mb4
[mysqld]
character-set-server=utf8mb4
[client]
default-character-set=utf8mb4
SQLクライアントをどうするか・・・
基本的には上流側のデータソース、下流側のターゲット、間を取り持つEqualum、あとはPythonの実行環境があれば検証は実施出来るのですが、今回はGUIベースで環境内のデータを見たり、基本的な環境制御が出来るように、DBeaverというツールを使う事にしました。これはWindows以外にもMac等の環境でも同じように使う事が出来るので便利だろう!というシンプルかつ短絡的な理由によります。(苦笑)
では!検証スタート!!
まずは、上流側に作成したツールが流し込むデータベースをDBeaverで作成します。
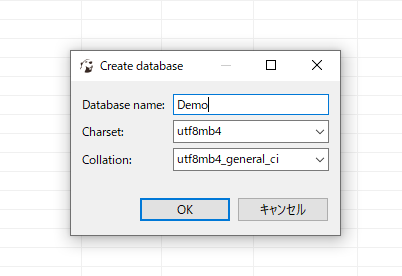
次にこのデータベースに「カラム設定のみ」を自作のPythonツールで行います。

無事にテーブルが出来た様なので、Equalumを起動します。(データソースの設定などに関しては前回ご紹介した通りです)
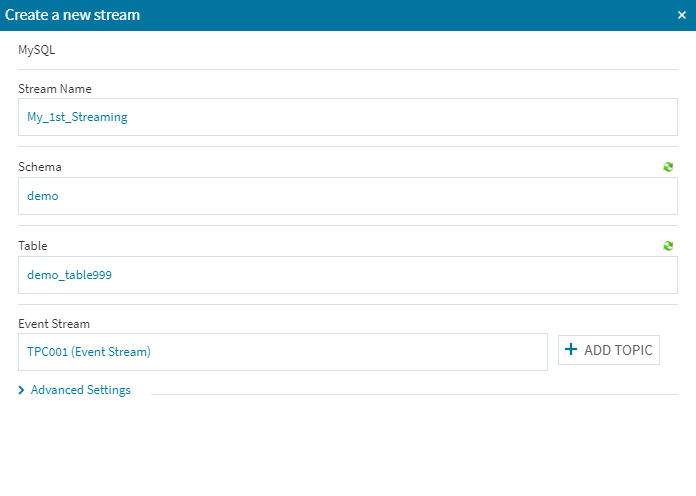
ソース側に必要情報を設定します。
次にこのストリーミング設定を使ったFlowのデザインを行います。ダッシュボード左側の**[Flows management]**を選択します。
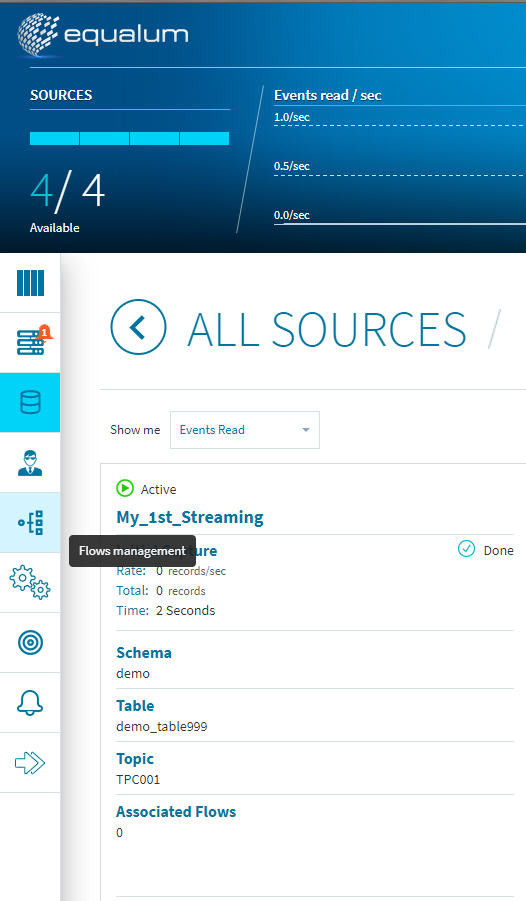
画面の真ん中位にある**[+ADD]**ボタンを選択します。
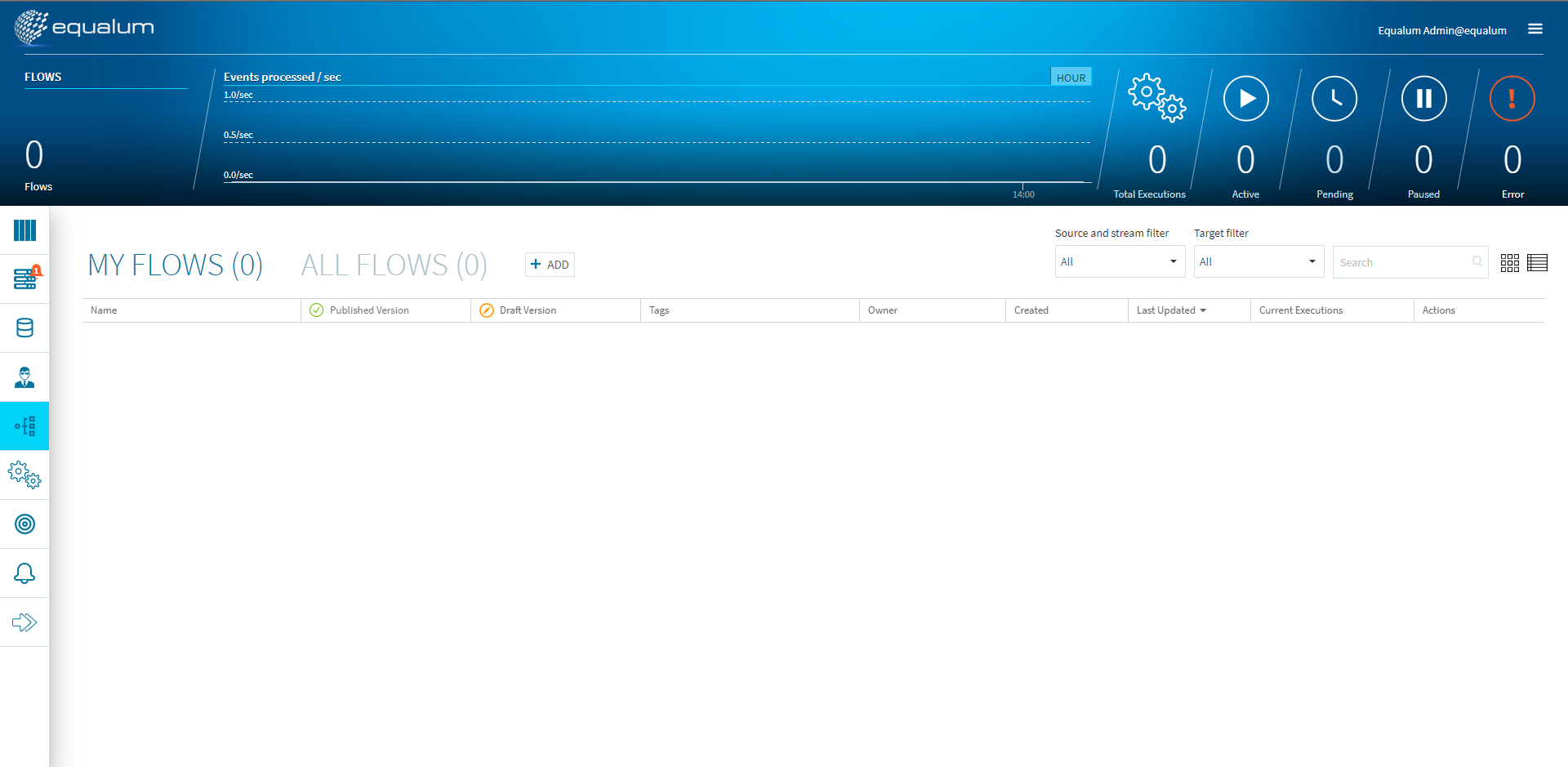
この画面が、GUIベースで各種のFlowをデザインする画面になります。
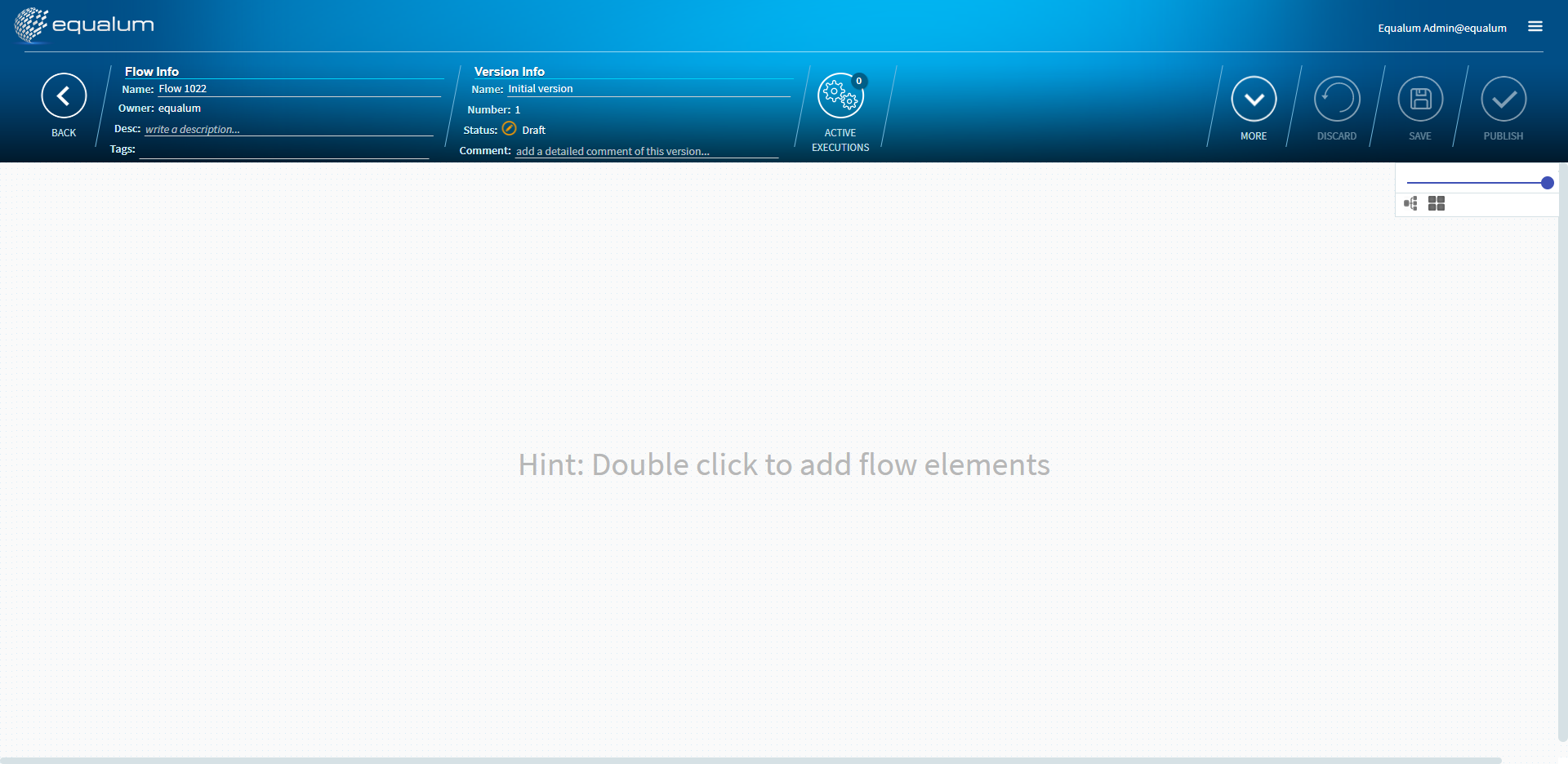
未だ何も設定が有りませんので、画面中央でマウスをダブルクリックします。
ポップアップメニューが出てきますので、左側の**[Source]**を選択します。
通常のストリーミング設定ですので、ここでは**[Event Stream]**を選択します。
先ほど登録したトピックが出てきますので、その項目をクリックして選択します。
画面上にアイコンが出てきます。
今度は先ほどと同様にターゲット側の設定を行います。
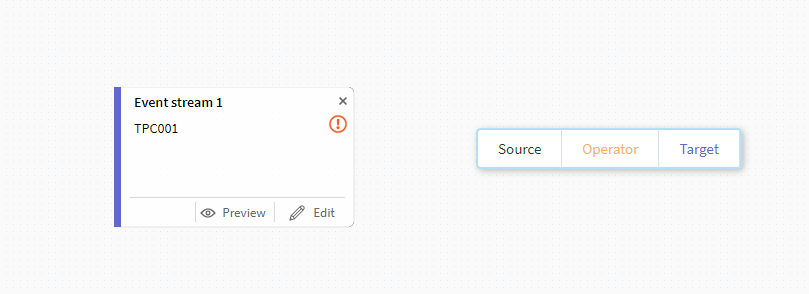
標準装備でHDFSベースのEQUALUMという選択も可能ですが、ここでは以前より検証しているMemSQLを選択します。
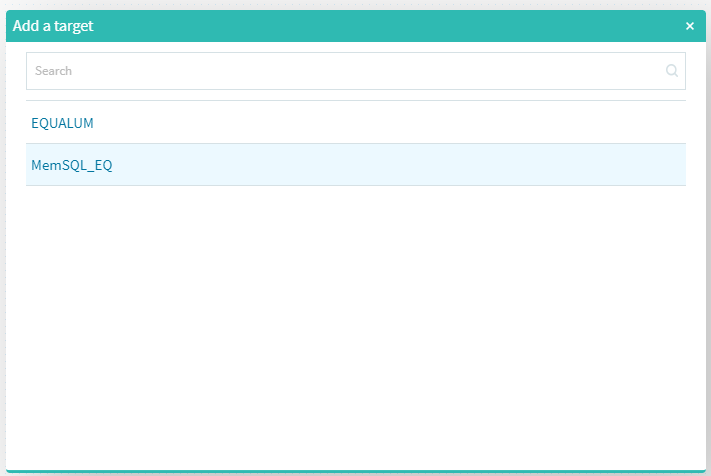
これで、今回の基本的な構成要素が準備できました。

次に上流側のトピックにある三角マークをクリックしてターゲット側までドラッグします。
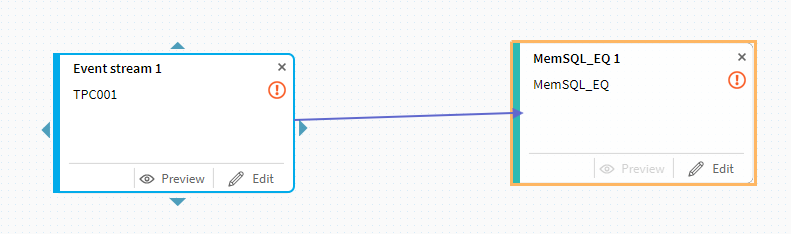
今回の検証では、基本的に途中の処理を省いた「シンプルなストリーミング」を行いますので、その前提でそれぞれの最終的な設定を行って行くことにします。基本的には下流側の**[Edit]ボタン経由での設定・確認作業になりますので、MemSQL側の[Edit]**ボタンをクリックします。
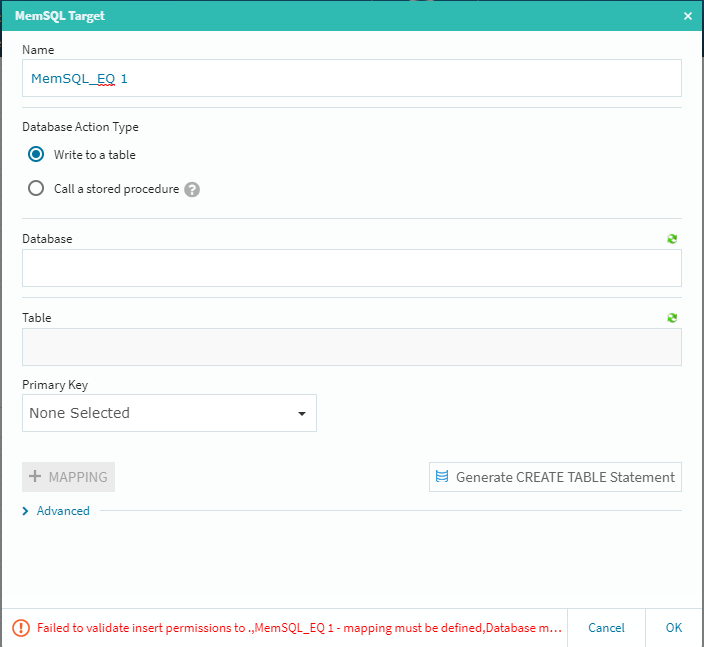
ここでは**[Database]と[Table]を設定する必要がありますが、予め受け側のテーブルを作成していなくても、[Generate CREATE TABLE Statement]ボタン経由で自動的にこの場所からMemSQL上にターゲットテーブルを作成する事が可能です。もちろん、その編集をその場で行ってカスタマイズしたテーブルにする事も可能です(この場合はカラムの選択作業等が追加されます)
今回は、単純な総カラムレプリケーションを行いますので、データベースを選択して[Generate CREATE TABLE Statement]**ボタンを選択します。
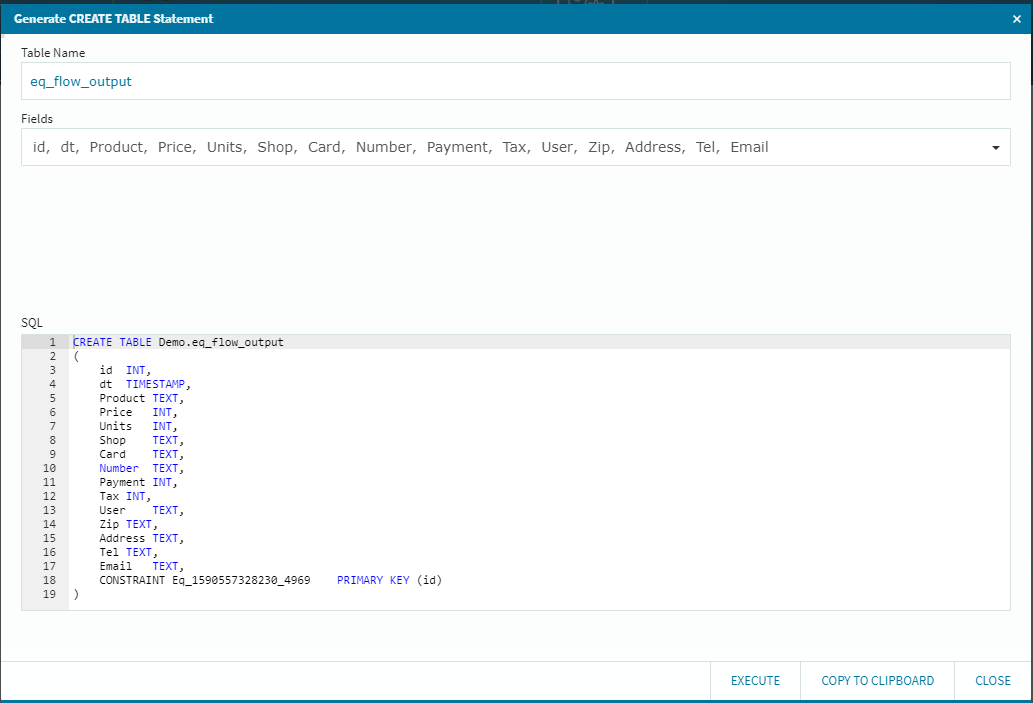
先ほどの連携定義により、上流側のMySQLからカラム情報を引っ張ってきて、ざくっとSQL文を作成しています。(もちろん、このSQLエリアは編集可能ですので、必要に応じて編集を行う事も可能です)また、自動的に**[Table Name]も設定してくれますが、これも任意のテーブル名にする事が可能です。(今回はサクッとそのまま行きます!)
右下の[EXECUTE]ボタンを選択して処理の成功を確認後に[CLOSE]**を選択して閉じます。
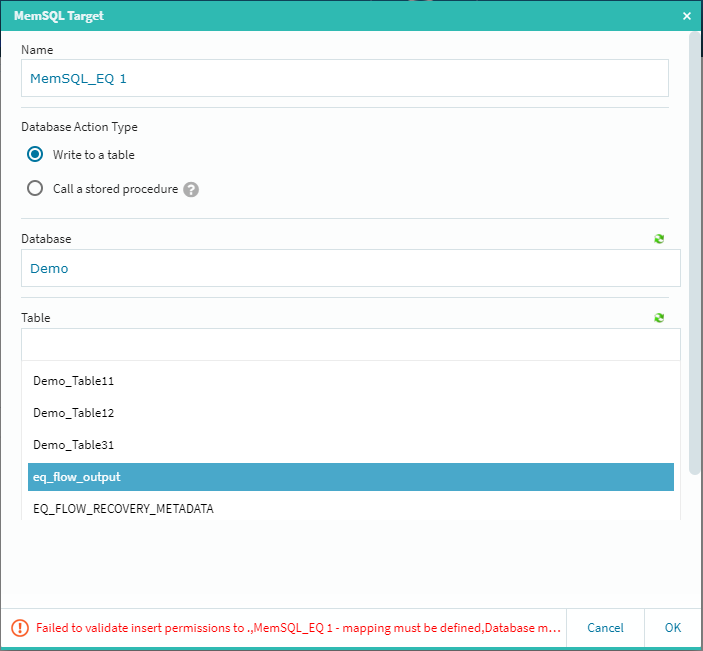
テーブルの選択メニューに先ほどのテーブル名が出てきますので(右上の緑色のアイコンをクリックすると情報が更新されます)そのテーブルを選択します。
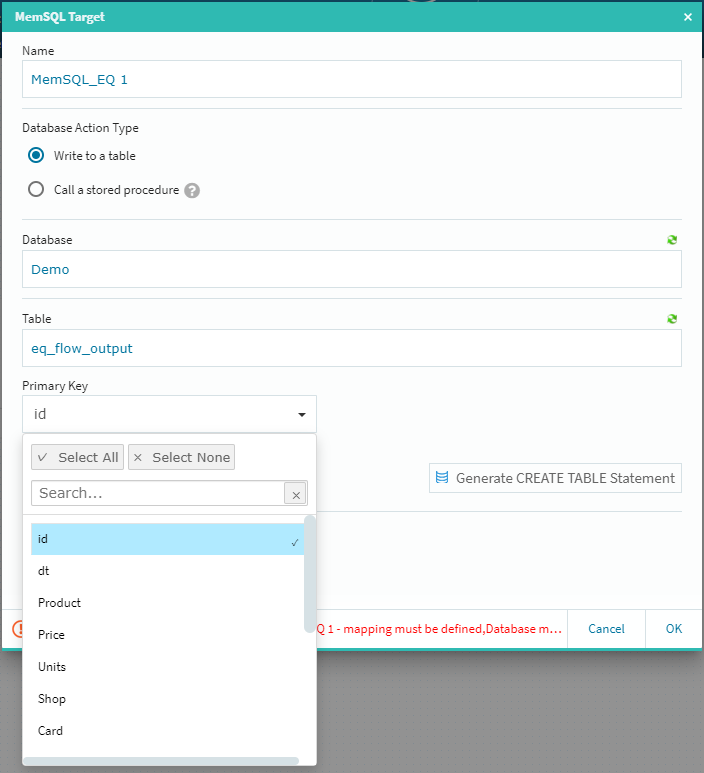
**[Primary Key]のプルダウンからキーを選択し[+MAPPING]**ボタンをクリックします。
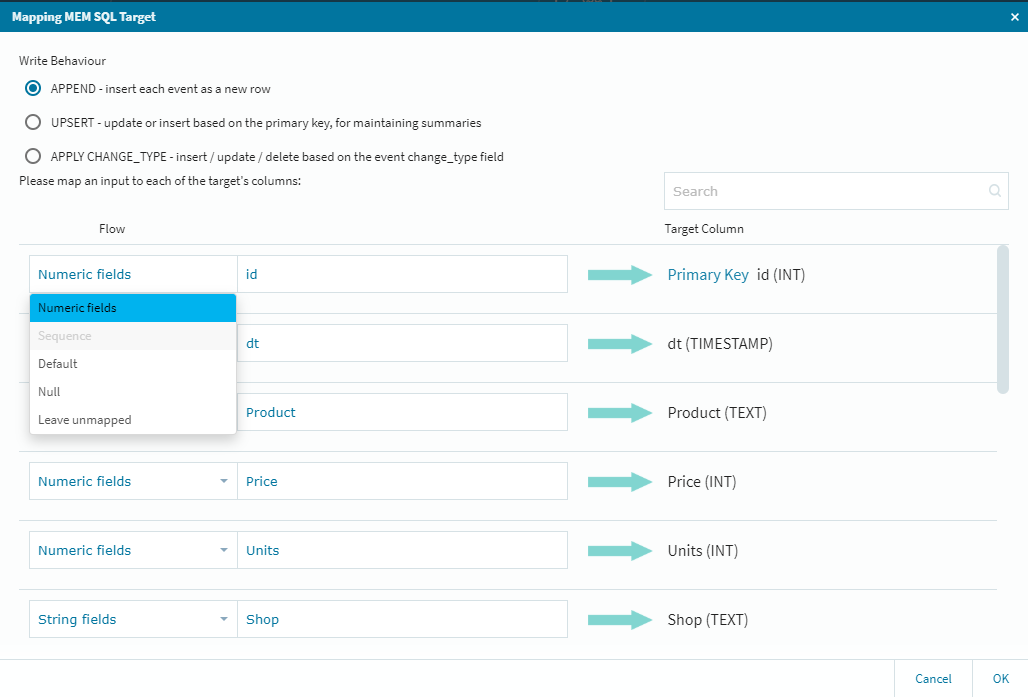
ターゲットに対する細かな調整が必要な場合は、ここで作業を行っておきますが今回はそのまま右下の**[OK]**を選択し、ターゲット側の設定を終了します。
では!ストリーミングしてみます!!!!
此処までの簡単な設定で、基本的なストリーミング処理の設定は終了です。あとは登録した内容を**[SAVE]して[PUBLISH]し、データ生成側の準備を確認して[DEPLOY]**すれば高速ストリーミングの準備OKです。
その前に念のために上流側と下流側のデータ格納状況を確認しておきます。
画面の右上にあるボタンで設定を保存して実行可能状態にしておきます。
準備が出来るとボタンの並びが変わります。
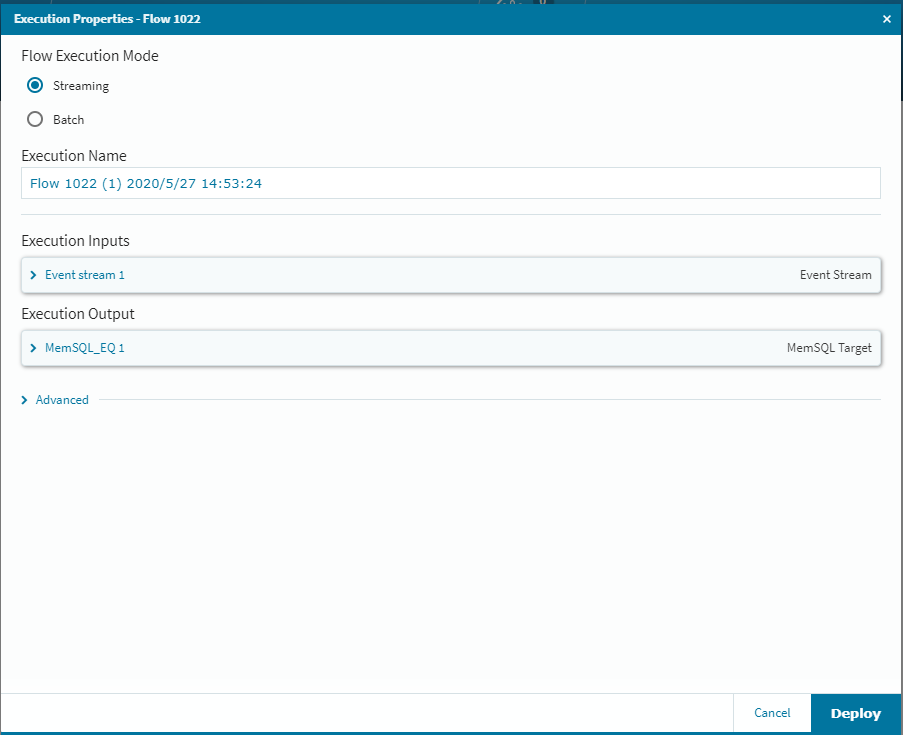
一番右側の**[EXECUTE]を選択し[Deploy]**をクリックすれば、データの流し込み待ち状態になりますので、自動生成ツールを起動してデータを順次上流側のMySQLに書き込んでいきます。今回は300個のデータを自動生成してSleep1の間隔で書き込む設定で検証しました。
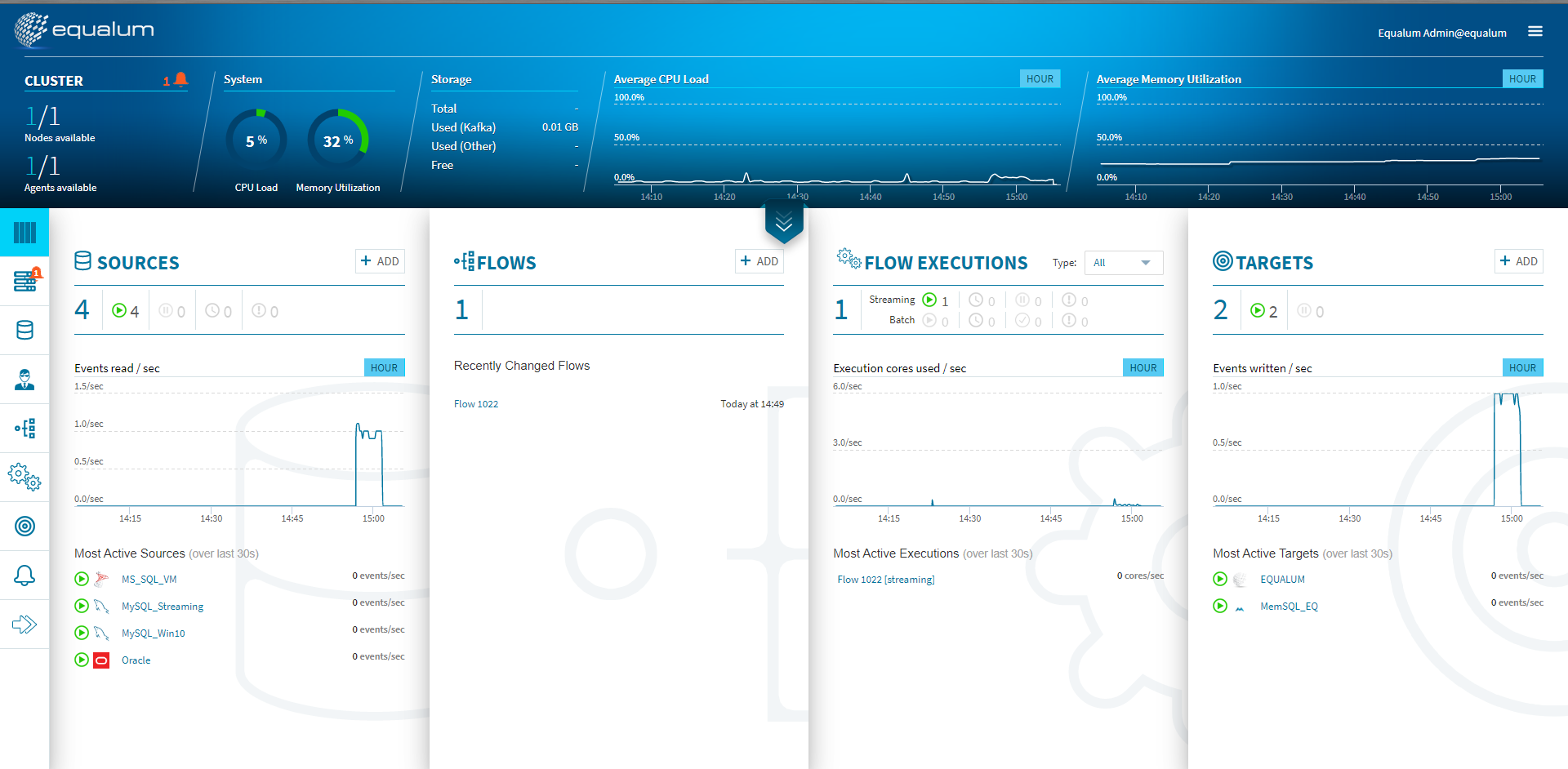
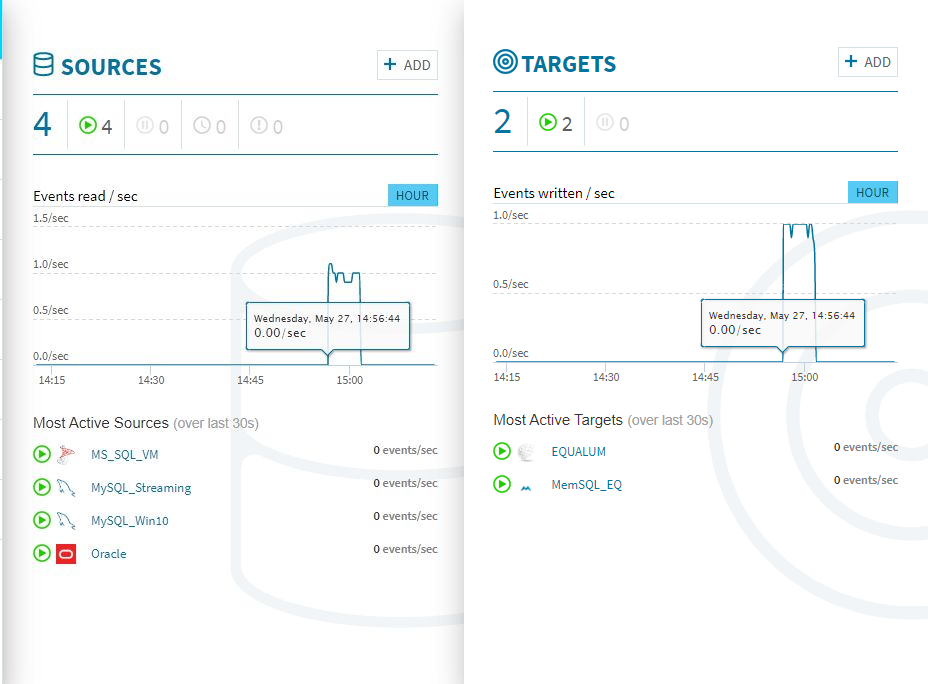
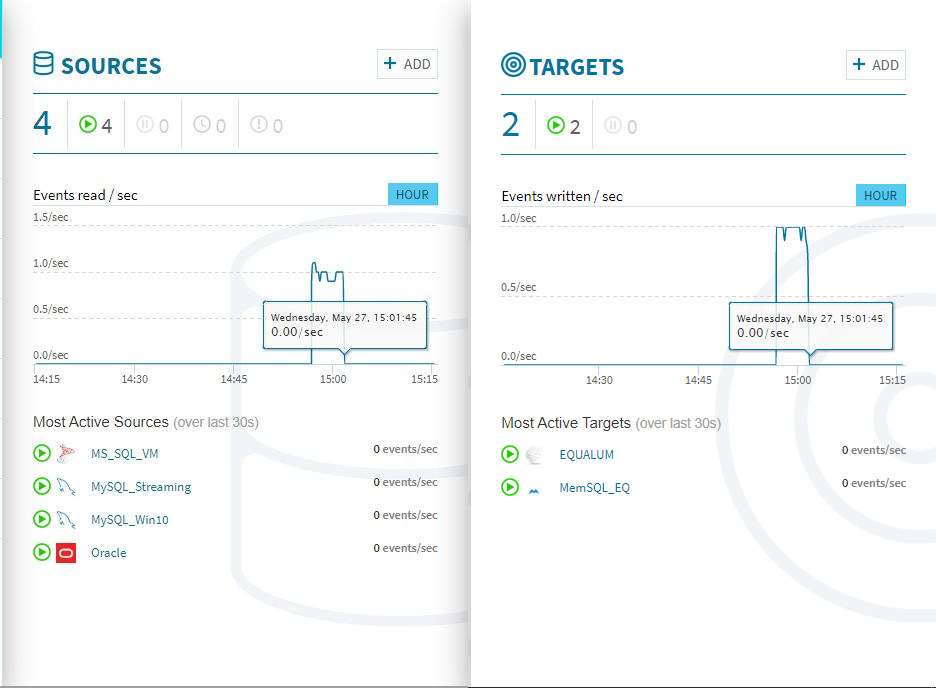
検証開始後、上流の**[SOURCE]側のモニターグラフと、ほぼ同時に[TARGETS]**側のモニターグラフに変化が現れました。CPUやメモリの使用量も増えている事が確認できます。
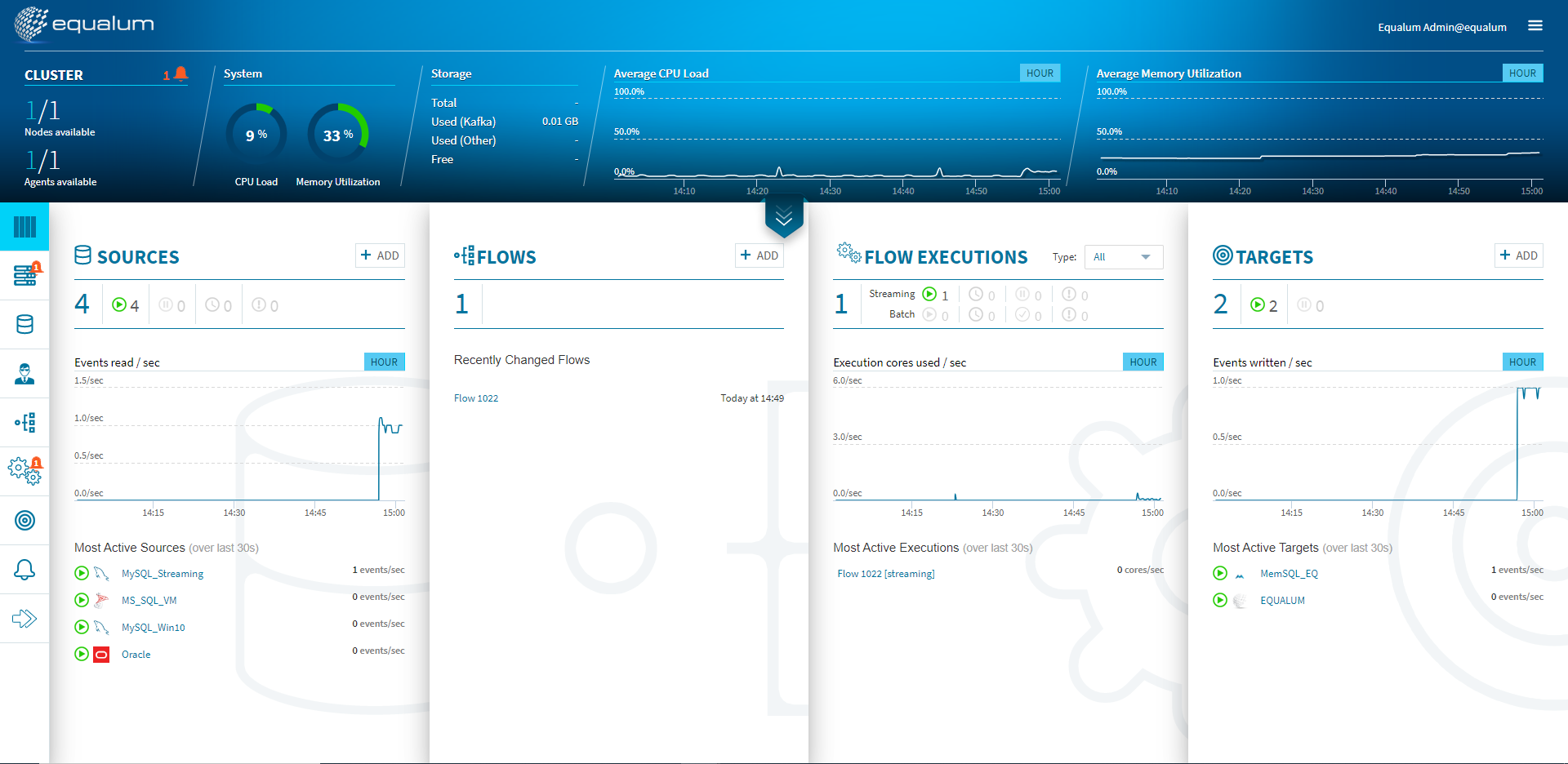
300個のストリーミング処理があっという間に終わってしまいました。
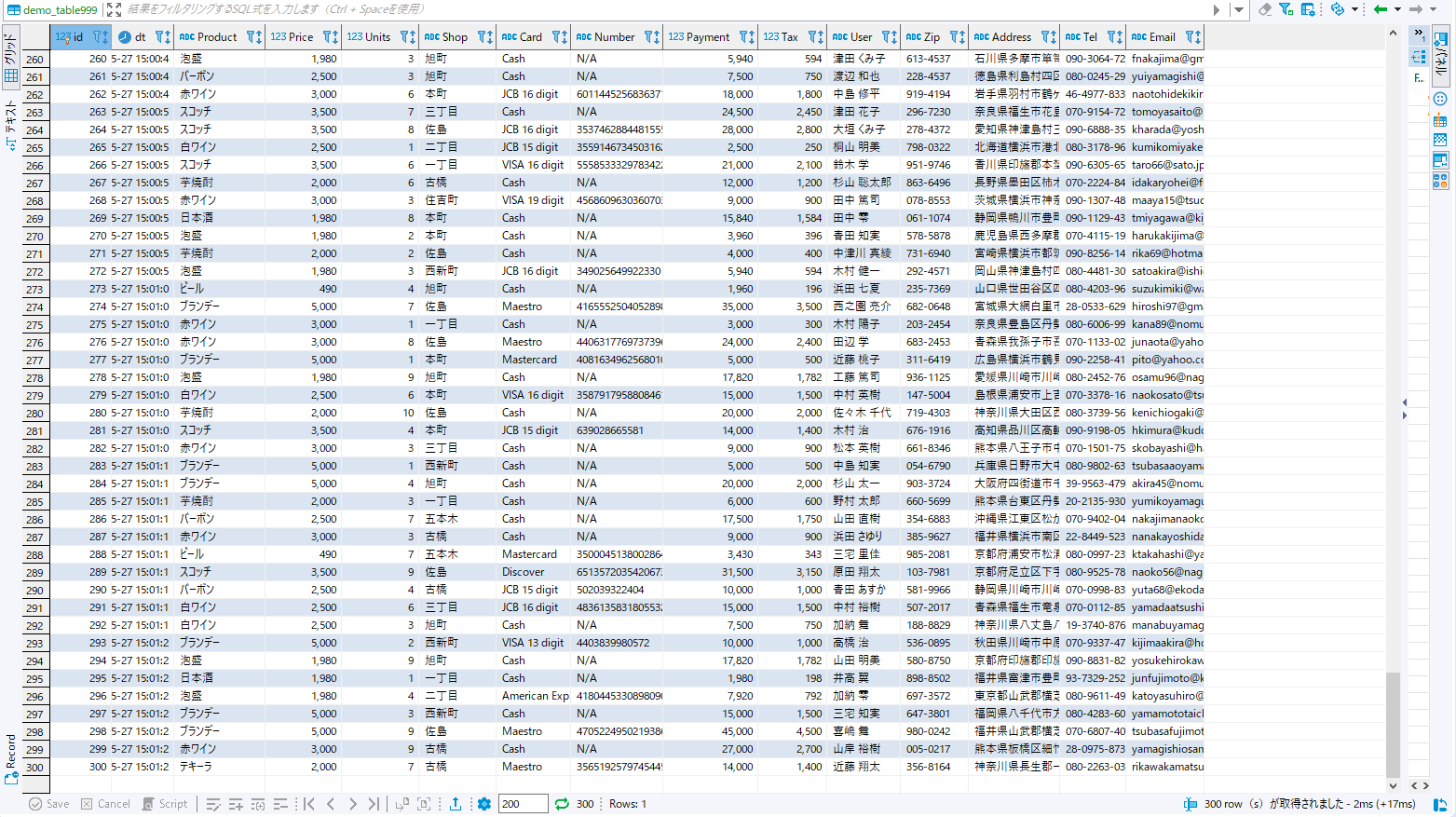
念のためデータの格納状況をDBeaverで見てみます。まずは上流側のMySQLに格納されたデータを確認・・・
次にMemSQL側を確認・・・
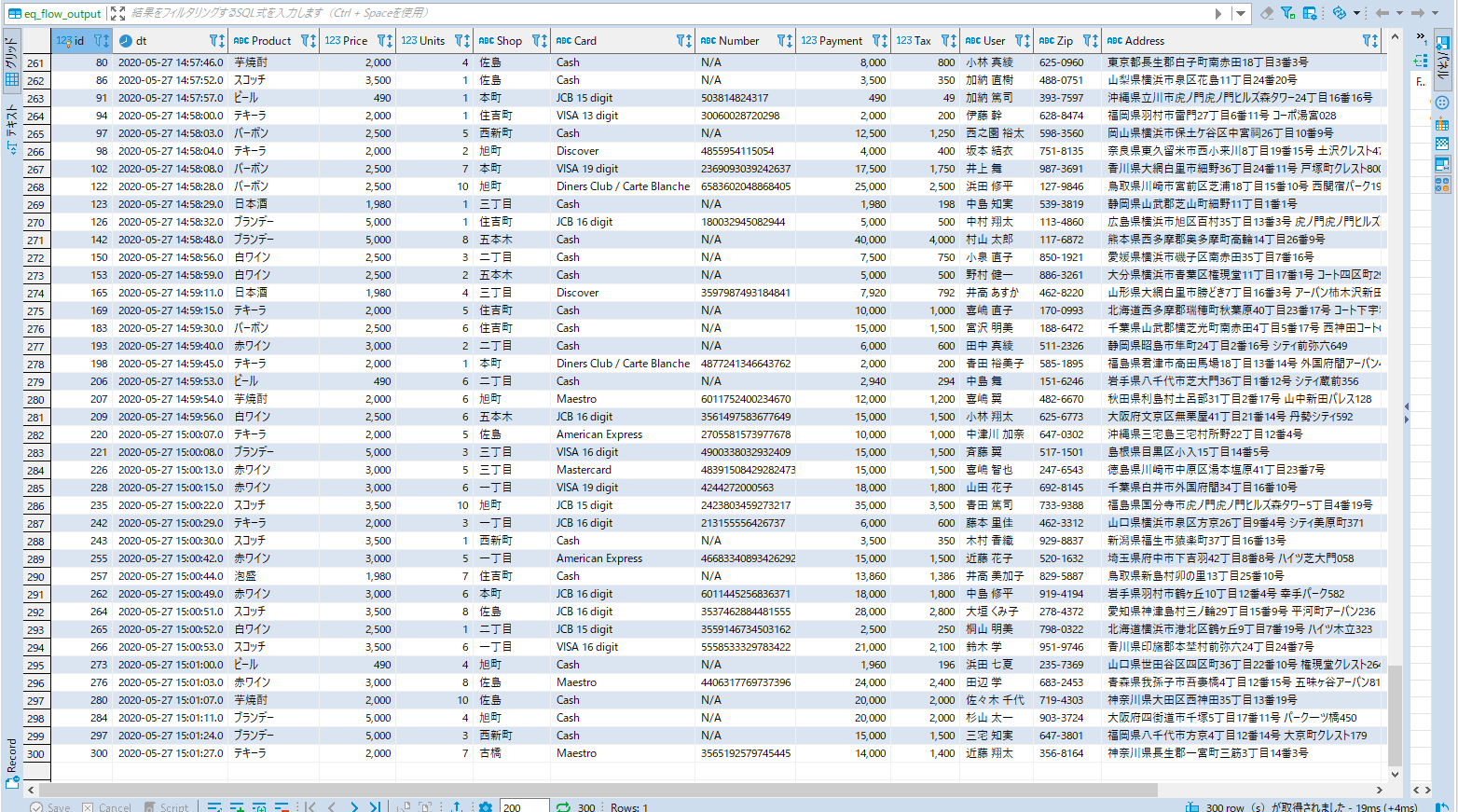
無事に入っている様です。
ちなみに、Equalum側の処理時間を見ると上流側にデータが格納されたタイミングと同タイム(実際にはコンマ以下の時間は異なると思いますが)でターゲット側の処理がスタートし、MySQL側への処理が終わったタイミングでMemSQL側の処理も終了していました。
今回のまとめ
今回は、前回に引き続いて基本的なストリーミング処理に関する実際の検証を行ってみました。形式的には単純なフルコピーのレプリケーション実験になりますが、デスクトップPC上でも非常に高速に上流側の変化を捉えて、即時下流側のターゲットに反映させる事が可能だという処理能力の高さを確認する事が出来ました。
また、これらの高性能を非常に簡単にプログラムレスの環境で実現する事ができるので、データの利活用領域において(従来のIT的な領域ではなく)データ周りを得意とされるユーザ層が、セルフで色々と問題解決の為の試行や各種の(ML/AI/BI等)データをフルドライブできるツールになる可能性が有ると同時に、現実的に散在するサイロ化された多くのデータの壁を取り払い、下流のマイニング層に対する可能性を大きく広げるソリューションになり得ると感じました。
次回以降では、今回のシンプル・ストリーミングをバージョンアップさせて、間に**[Operator]**を設定する条件で追試してみようと思います。
速さの為の速さ
これは、使い勝手を向上させると同時に**「変化に強いデータ・ドリブン環境」**を実現する上で非常に重要なポイントになる事を明確に示しているという事なのかもしれません。
謝辞
本検証は、Equalum社の特別の許可を得て実施しています。この貴重な機会を設定して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。