前回の余談(?)にて、異なるビッグデータソリューション間においても、フュージョンを用いて、キーとなるデータの設定を行う事により、透過的に一つのデータソースとして取り扱う事が出来る事をご紹介しました。適材適所・適宜適量でスケールアウトしていくであろう、各種のビッグデータソリューションは、今後さらに進化し、同時に新たなコンセプトやテクノロジーを搭載した、次世代のソリューションも次々と出てくるかもしれません。それぞれの長所を最大限に活かし、色々な意味でハイブリッドなビッグデータ環境に対しても、持続発展可能な高速可視化解析のプラットホームとして、Zoomdata自身も進化を続けているのです。
(1)環境の準備
さて今回は、少し趣向を変えてDrillを使ったZoomdataとの接続検証を行いたいと思います。
実は、このDrill接続用の環境は、モジュール類を”後入れ”をして頂く必要がありますので、まずはZoomdata社の方へご相談ください。
導入は非常に簡単です。例えば、CentOSへ導入する場合は、送られてきた情報を基にsudoでyumコマンドを用いて行い、正常にインストールが行われた事を確認した後に、導入したコネクタのサービスを
sudo systemctl enable xxxxxxxxx-xxx-xxxxxx
(ここで、xxxxxxxxx-xxx-xxxxxxには、導入するコネクタ名が入ります)
で利用可能にして、最後にOSをリブートすればOKです。
正しくインストールが行われると、見慣れたSourcesページにDrillのアイコンが表示されると思います。
さて、次にDrillが使えるSandboxの導入ですが、MapR社様がホームページ上で公開されていましたので、その環境を使わせて頂く事にします。(以下は執筆時点)
(1)MapR社ホームページへ移動
(2)画面右上にあるTRY MAPRを選択
(3)Download MapRを選択
(4)Download Sandbox with Drillを選択
(5)画面左側にあるGet the sandboxの必要情報を正確に記入
(6)Downloadを選択
登録したメールアドレス宛に、必要な情報が記載されて送られてきますので、それに従ってターゲットのSandboxをダウンロードすればOKです。
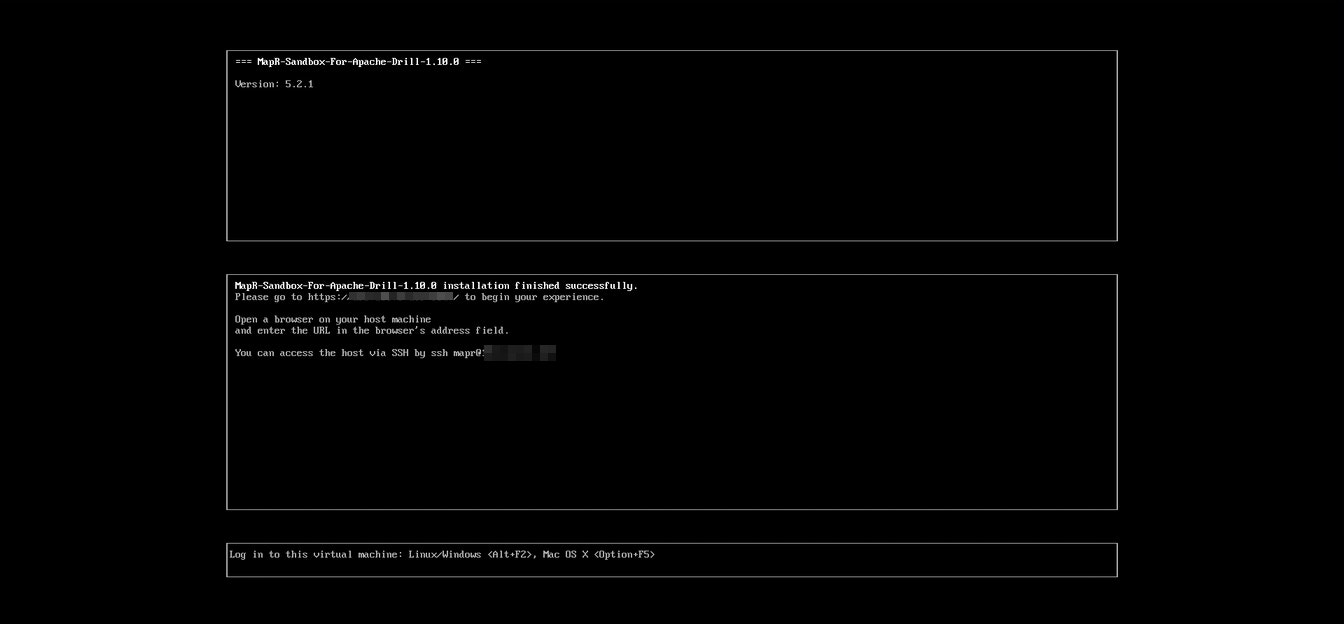
ダウンロード後に、仮想環境へインポートして起動すると、問題が無ければコンソールが起動して利用に必要な情報が表示されると思います。(今回使うのは、Zoomdataとの接続設定に使うIPアドレスになります)
(2)Zoomdataの設定
ここまでくれば、基本的な手順としては今までと同じですので、サクッと接続検証を進めていきます。
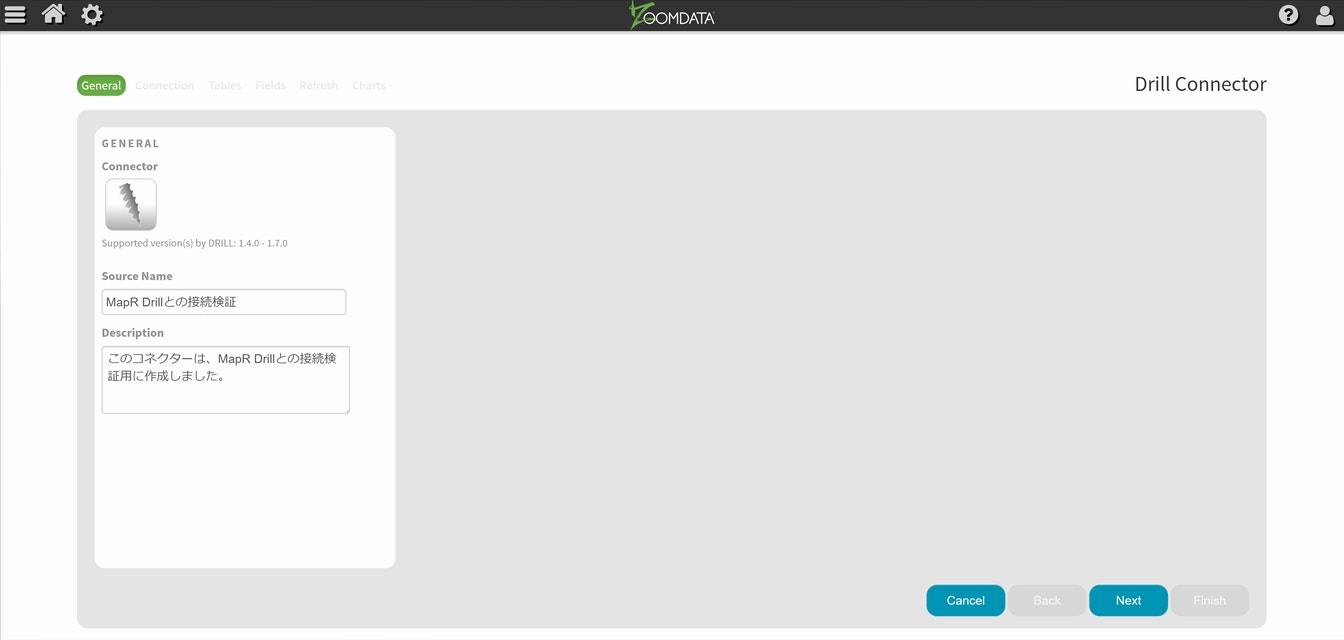
Zoomdataにadminで入り、いつものコネクタ設定の画面を呼び出してから、必要事項を設定してNextを選択します。
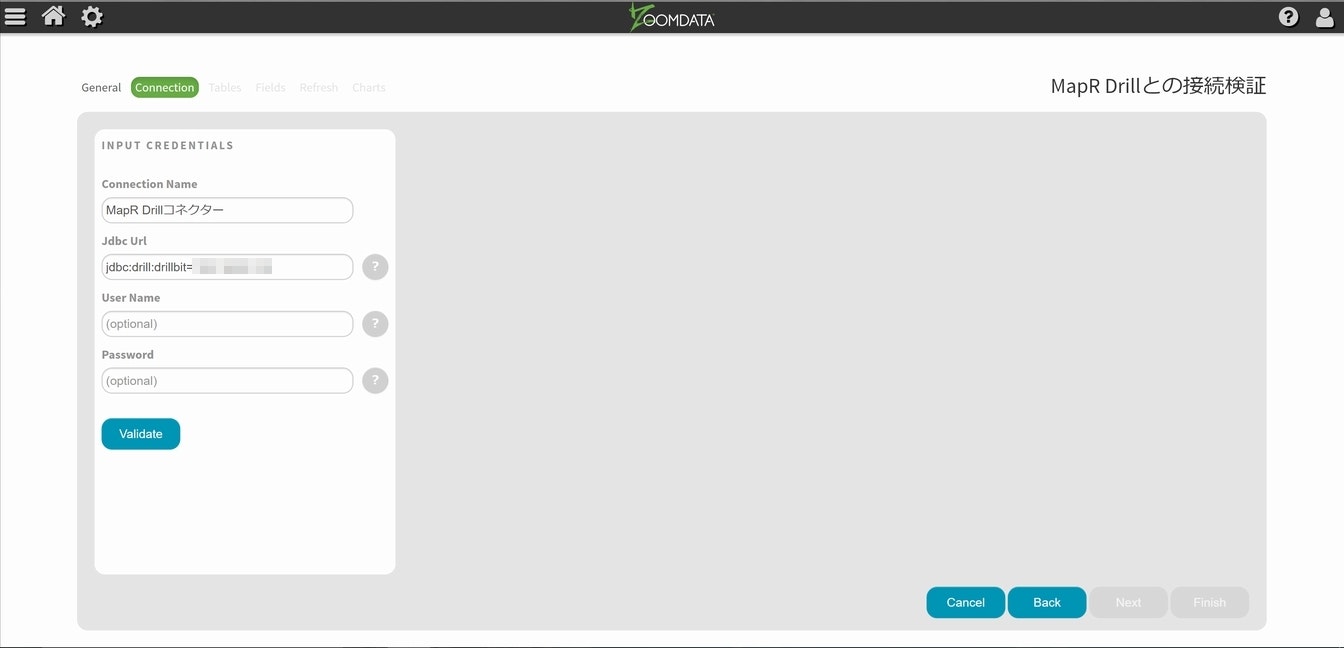
今回Jdbc Urlには以下の通り設定しました。
jdbc:drill:drillbit=XXX.XXX.XXX.XXX
その後、Validateを選択して暫く待つと利用可能なテーブルがリストアップされます。
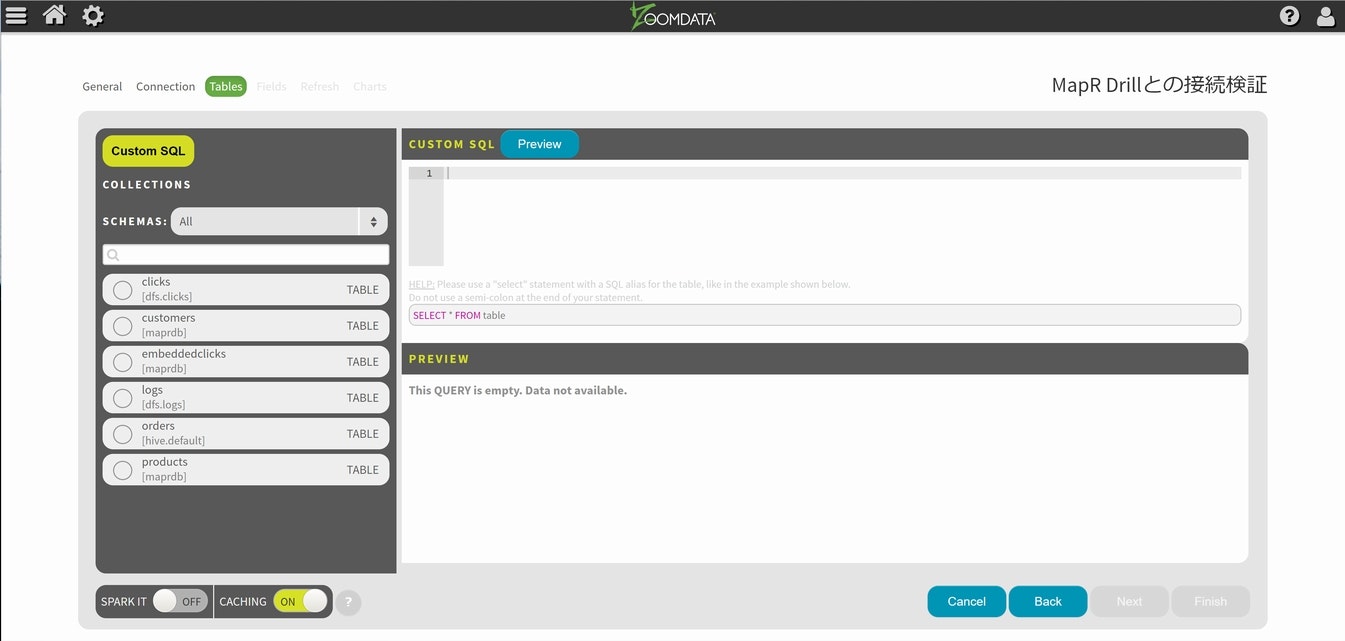
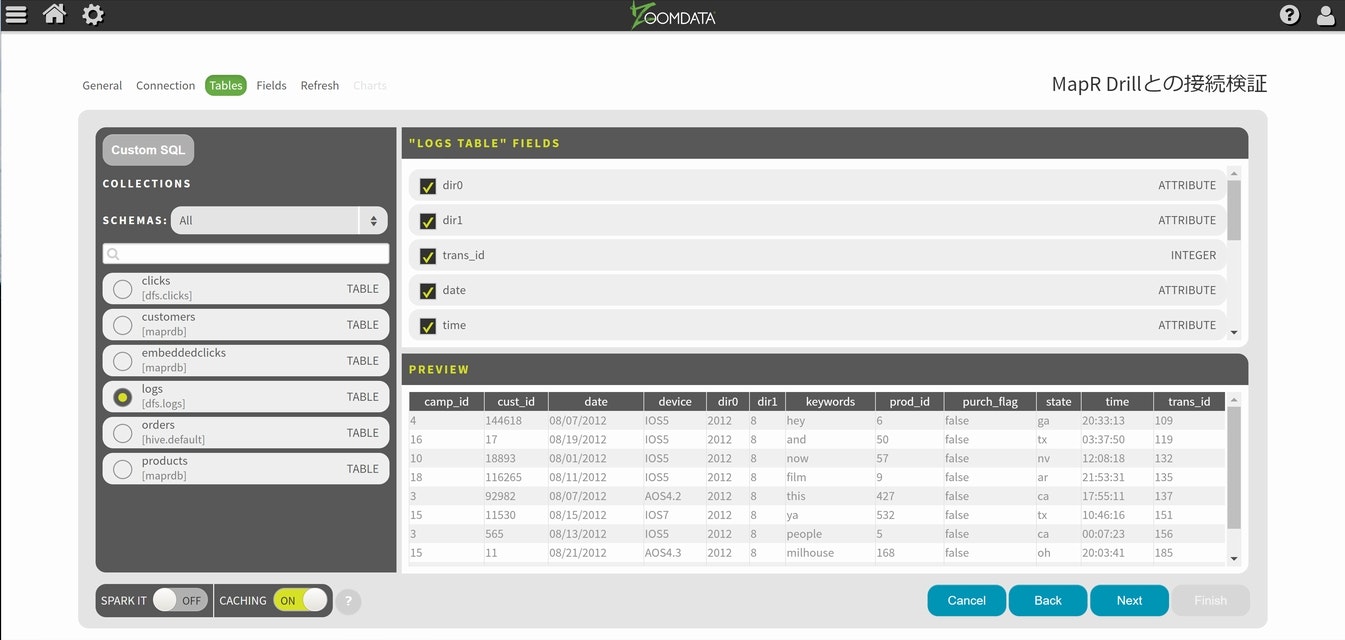
logsが使えそうなので、テーブルを選択してNextに進みます。
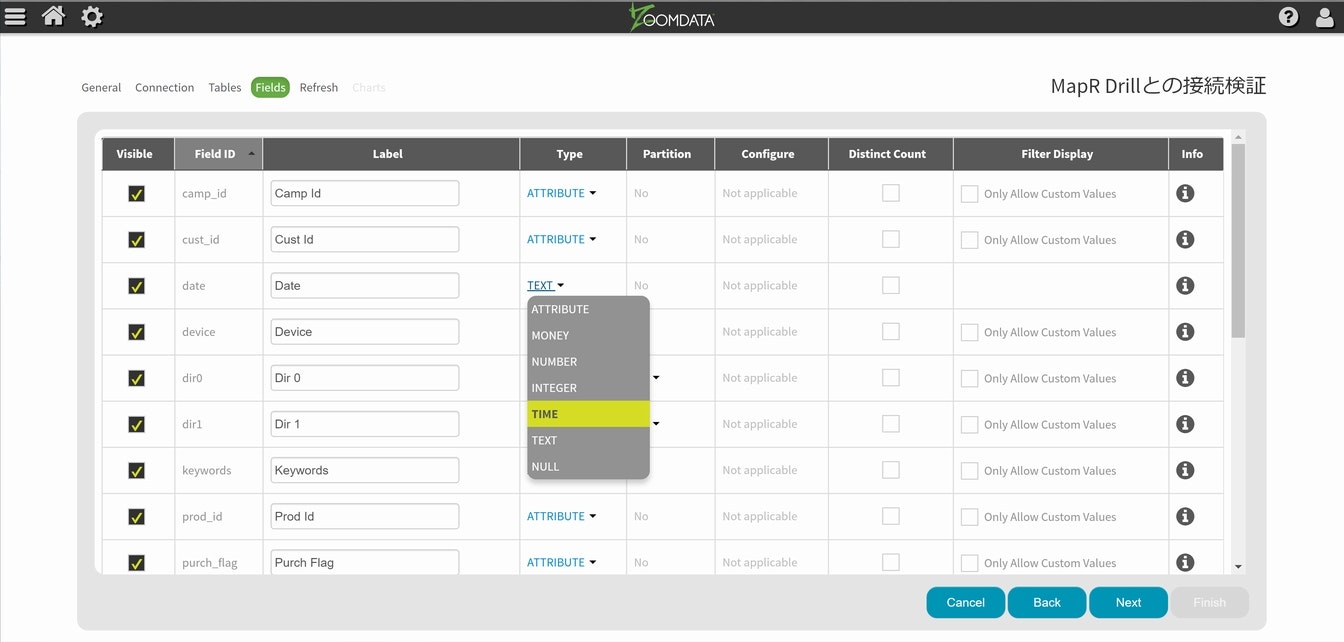
Zoomdataお得意の時間軸との連携については、dateを使って設定を進める事にしますが、表記の仕方が若干異なっているようなので、以前ご紹介したCustom設定を行っておきます。今回はMM/dd/yyyyの形式に合わせてあります。
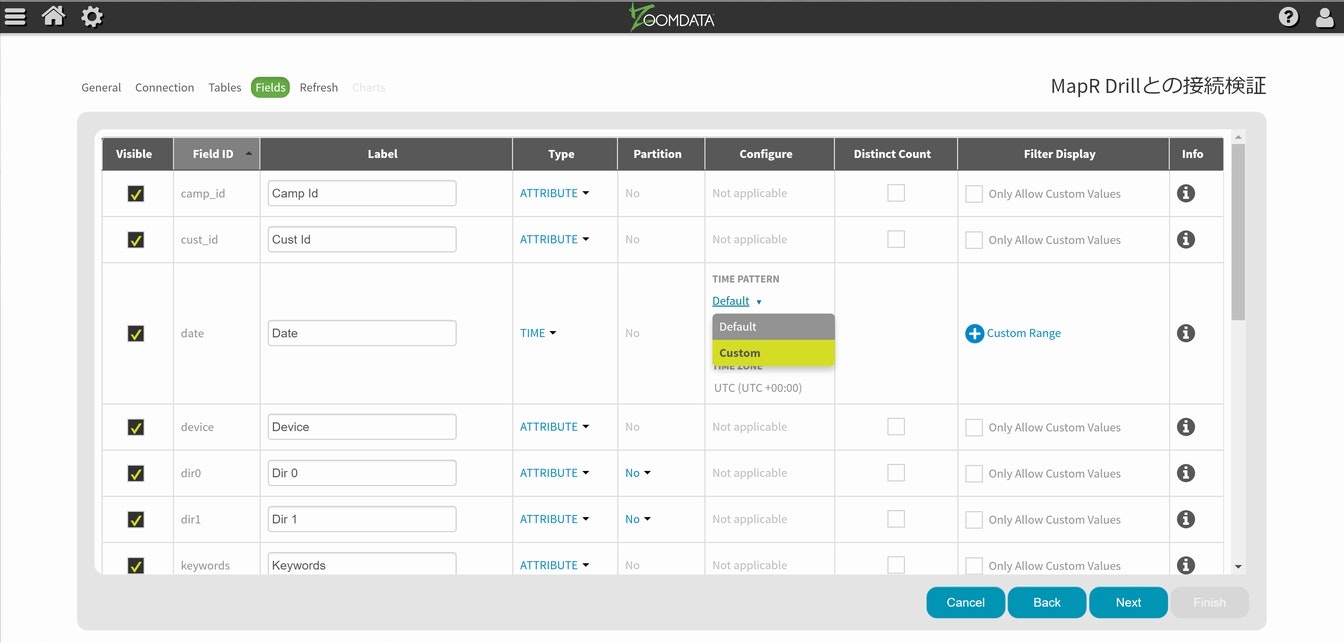
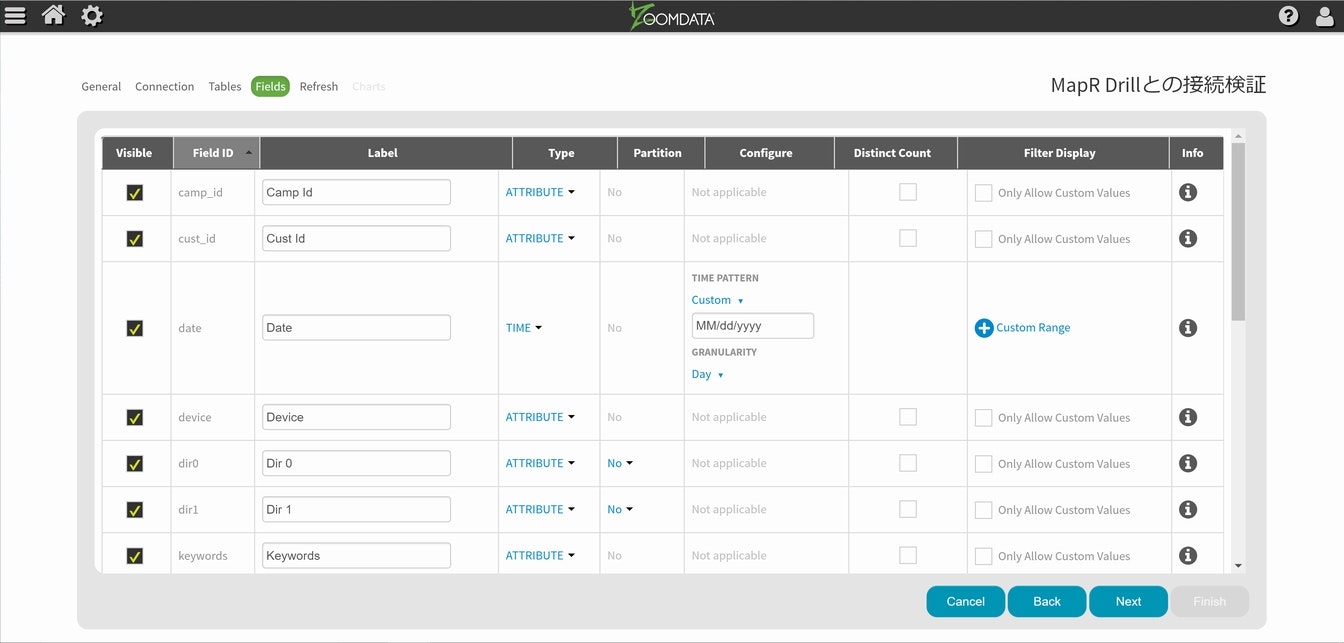
以降は、サクッとNextを選択して一気にFinishまで行ってください。無事に登録が行われれば情報が格納されてユーザレベルから利用する事が出来る様になります。
(3)接続検証とダッシュボード作成
実際の接続検証と基本的な流れは、これまでのご紹介と同じになりますので、詳細をご説明する事は省かせて頂きますが、いくつかのデータに対して可視化チャートを設定し、いつもの如く”なんちゃってダッシュボード”を作成してみました。
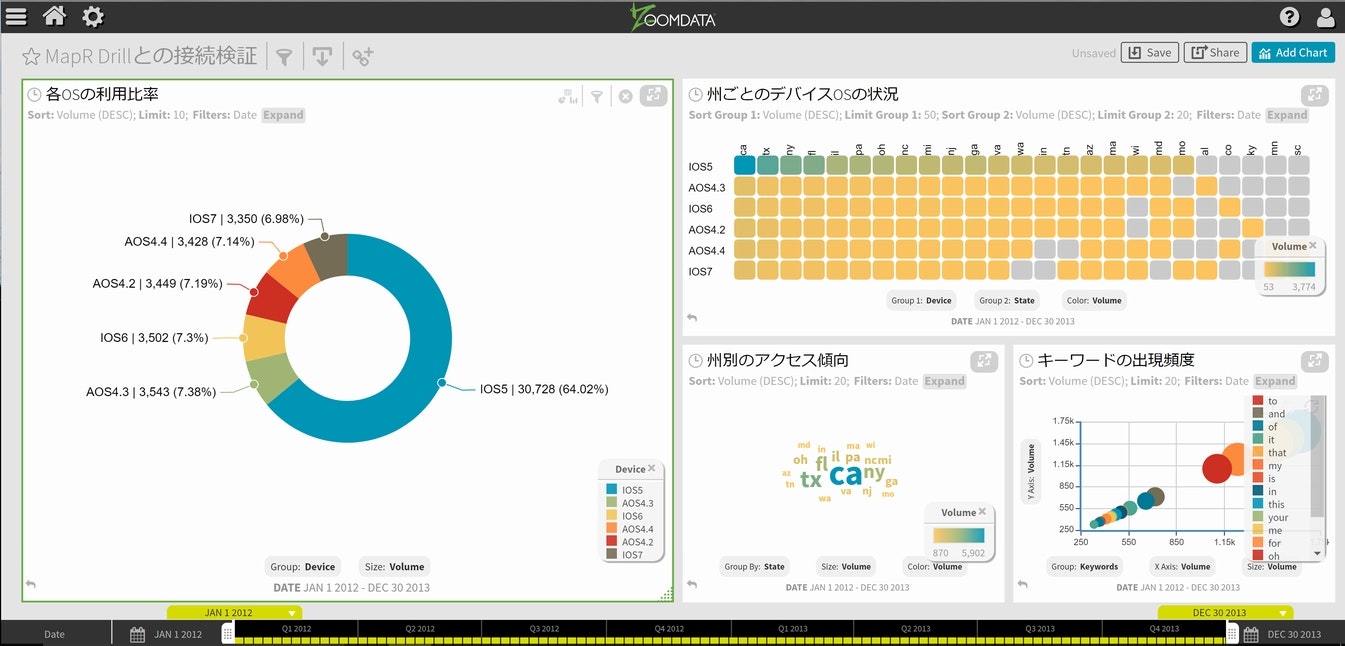
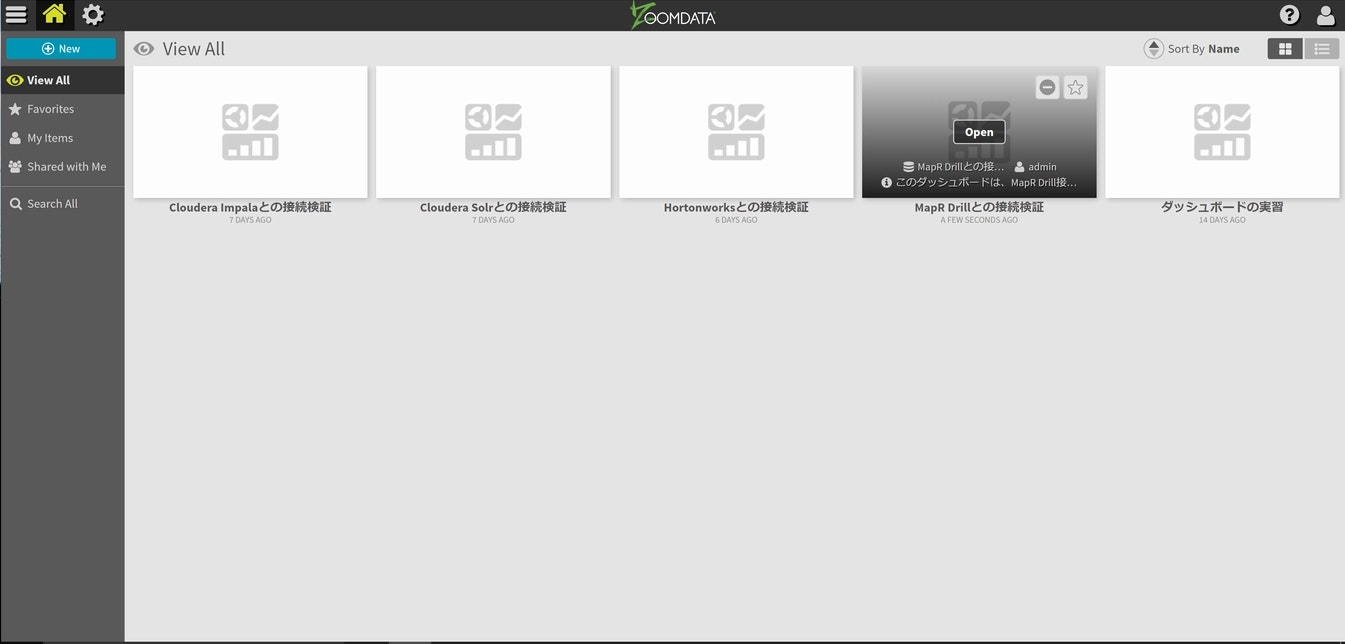
以降の検証でも再利用出来る様に、今回のダッシュボードを保存しておきます。
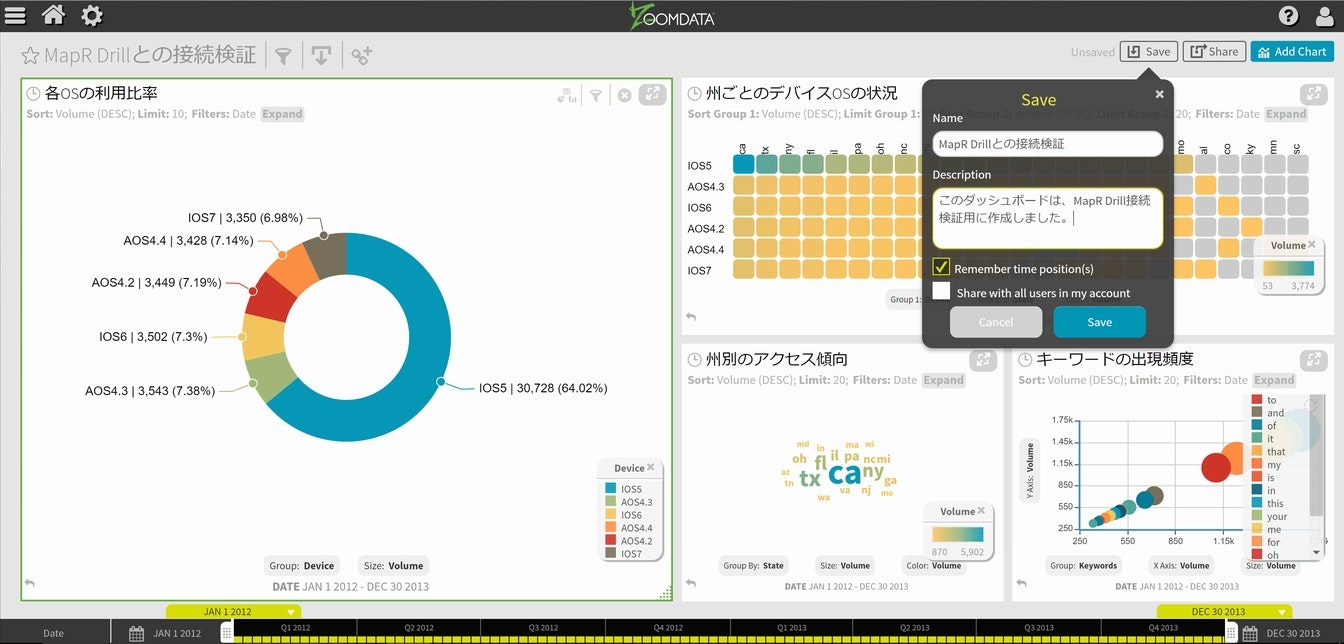
今回もサクッと保存できました。
(4)今回のまとめ
今回は、Drillというインターフェース経由でのビッグデータ連携を検証してみました。Drill以外にも、接続方式が幾つか後付けで導入できますので、こんな接続って?・・・というご相談は、遠慮なくZoomdata社の方へお送りください。(日本法人も活動を始めていますので、日本語でのご相談も可能です)
次回は、既存のデータストアとして一般的に利用されている、SQL系のデータベースとの連携に関する解説を予定しています。
(5)謝辞
今回の記事作成に関し、ビッグデータソースのエンジンとして、MapR社様が公開されているSandboxを活用させて頂きました。この場をお借りして厚く御礼申し上げます。