はじめに
midPoint by OpenStandia Advent Calendar 2019 の20日目は、ちょっとこれまでの記事とは異なる視点で midPoint に対する理解を深めていきたいと思います。具体的には、元祖ワールワイドな OSS の ID 管理プロダクトである OpenIDM(現在は ForgeRock IDM に改名し非 OSS 化![]() )との比較を通じて、midPoint のことを解説できればなと思います。「OpenIDM だとこういう考え方・仕組みだったけど midPoint だとどうなるの…?」というような疑問に対してヒントを伝えられるような内容にしたいと思います。自分も長らく(2013年くらい?)OpenIDM を触っていたこともあり、初めて midPoint を触ったときには慣れた OpenIDM と違ってよくわからん!!という状態でした。同じような境遇の方々に役立てばいいなと思い書かせていただきます!
)との比較を通じて、midPoint のことを解説できればなと思います。「OpenIDM だとこういう考え方・仕組みだったけど midPoint だとどうなるの…?」というような疑問に対してヒントを伝えられるような内容にしたいと思います。自分も長らく(2013年くらい?)OpenIDM を触っていたこともあり、初めて midPoint を触ったときには慣れた OpenIDM と違ってよくわからん!!という状態でした。同じような境遇の方々に役立てばいいなと思い書かせていただきます!
midPoint と OpenIDM のアーキテクチャ比較
まずは、ソフトウェア・アーキテクチャ視点でそれぞれを見てみます。
OpenIDM のアーキテクチャ
OpenIDM はバージョン1までは重厚長大な Java EE アプリケーションとして開発されていましたが、バージョン2にて突如、OSGi フレームワークである Apache Felix を基盤としたアーキテクチャに刷新されました。各機能は OSGi のサービスとして登録されて REST API を提供し、UI は最初は懐かしの Backbone.js、その後 React.js を経て現在は Vue.js という SPA(Single Page Application)として開発され、フロントエンドからCookieに格納された JWT を使って認証して REST API をコールし、サーバサイドは完全にステートレスという、当時としてはモダンなアーキテクチャでした。また、軽量な Servlet コンテナの Jetty を組み込んでおり、Tomcat などのアプリケーションサーバにデプロイすることなく単体で起動するという、当時では目新しいアーキテクチャでもありました。
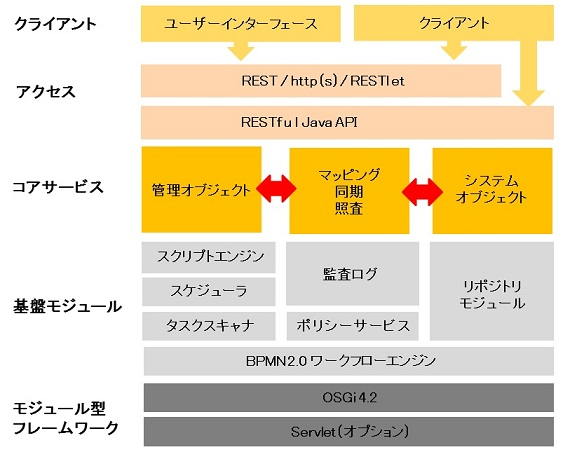
※出所:https://openstandia.jp/oss_info/openidm/index.html
OpenIDM では、IDM 内で管理するユーザーや組織、ロールなどのオブジェクトを管理オブジェクト(Managed Object)と呼び、源泉システムや連携先システムで管理されているオブジェクトをシステムオブジェクト(System Object)と呼びます。それらをマッピングする定義を JSON で記述し、リコンシリエーションなどの同期タスクを実行するとマッピング定義に従いデータが反映される、という作りでした。
また、後継である最新のForgeRock IDM 6.5(2019年12月時点)のアーキテクチャ図をみると、バージョン2からほとんど変更がないことがわかります。UI はフロントエンド技術の流行りに合わせて変えてきているものの、サーバサイドは変わらずで現在も OSGi フレームワークを採用しています。OpenIDM の場合、フロントエンドはユーザーがカスタマイズ開発することが前提となっており、バージョンアップ時に作り直しを想定しているのか、後方互換性を気にせずに積極的にフロントエンド技術を変えてきている印象です![]()
midPoint のアーキテクチャ
実は、midPoint は OpenIDM 1系を由来としています。midPoint のコア開発者たちは ForgeRock 社とともに OpenIDM 1系を開発していたメンバーでした。しかしながら、OpenIDM 2 系にて OSGi ベースのアーキテクチャに全面刷新するという決定が ForgeRock 社にて突然なされたため、OpenIDM 1系の開発はストップさせられました。そこで midPoint の開発者たちは、 OpenIDM 1系をベースに独自に OSS の ID 管理ソフトウェアを作る道を選択しました。それが現在の midPoint のベースとなっています。このあたりの開発初期の話はBlogにて開発者により語られていますので、興味がある方は読んでみると良いでしょう(予告なしに突然開発停止させられたなど、ForgeRock 社と当時バチバチしていた様子が語られています![]() )。
)。
当初の midPoint は OpenIDM 1系をベースとしており、SOAP や ESB(Enterprise Service Bus)の採用といった重厚長大なアーキテクチャでした。その後 midPoint 開発者たちは大幅に軽量化を進めて、現在は Spring Boot、Wicket、Hibernate を基本としたアーキテクチャとなっています。Spring Boot のおかげでシングルバイナリ(WAR ファイル)だけで起動する、Web アプリケーションサーバいらずのアーキテクチャになっています(組み込みの Tomcat 上で稼働しています)。また、SOAP ではなく JAX-RS を使った REST API が提供されています。
midPoint の場合は、フロントエンド技術は長らく変わっていないものの、サーバサイド側を積極的に改善して技術スタックを変えてきている印象です。たとえば今年の10月にリリースされたバージョン4.0では、ワークフローエンジンの Activiti を外すという大きな改修が行われました(Activiti は OpenIDM でも利用されている OSS の BPMN 2.0 に対応したワークフローエンジン)。フル実装の BPMN エンジンは ID 管理においてはオーバースペックであり、逆にデメリットが大きいというのが開発者たちの考えのようです。 BPMN が必要になるようなワークフローはおそらく ID 管理だけに収まらない業務フローであり、そういったものは専用のワークフロープロダクトを使うべきだ、と考えているようです。また、Hibernate もパフォーマンスボトルネックになりつつあるので将来的にはやめたいという話を数ヶ月前に開発者から聞きました。最近のマイクロサービスアーキテクチャの流行もあり、IDM・IGA に特化してスリム化していく方向性が感じ取れます。実際に、midPoint をサービスとして扱い REST API でアクセスし、フロントエンドは独自に作り midPoint を統合するというマイクロサービスアーキテクチャで設計しているユーザーも世界にはいます。
採用テクノロジーの比較
以下に、採用テクノロジーをまとめてみました。こうやって見てみると似ている部分と異なる部分がありますね。
| 項目 | midPoint | OpenIDM(ForgeRock IDM) |
|---|---|---|
| アプリケーションサーバ | Spring Boot による組み込み Tomcat | Apache Felix による組み込みJetty |
| DI コンテナ | Spring Framework | Apache Felix(OSGi) |
| ワークフロー | バージョン3.9まではActiviti、4.0以降は独自実装 | Activiti |
| フロントエンド | Apache Wicket、jQuery | Backbone.js → React.js → Vue.js のSPA構成 |
| Web API | Apache CXF(JAX-RS) | Restlet |
| スケジューラー | Quartz | Quartz |
| データベース接続 | Hibernate | 生 JDBC API 利用(ソースが見れた OpenIDM 時代は) |
| マッピング定義などの各種設定記述形式 | XML(YAML、JSON も可能だが主流ではない) | JSON |
| マッピング定義などで利用できるスクリプト言語 | Groovy、Python | JavaScript、Groovy |
| レポーティング | Jasper Reporting を組み込み | - |
JSON vs XML !?
OpenIDM は全体的に JSON 指向のアプリケーションでした。設定も JSON で記述し、JSON の REST API で Web API は提供され、データベースに格納されるデータも JSON データでした(ゆえに、パフォーマンスに難がありました)。
一方、midPoint は JSON を扱えるものの、基本的には XML 指向です。ドキュメントやサンプルで提供される設定例は XML ですし、 REST API もデフォルトは XML でやりとりします。(メディアタイプを指定すれば JSON も利用できます)。XML は古臭いと思われれるかもしれませんが、midPoint としては XML によるスキーマ定義を積極的に活用して生産性・品質を向上させたいという思いがあるようです。
たとえば、IDMで管理する属性をカスタム属性として増やす場合ですが、
- OpenIDM: JSON 設定ファイルにて管理属性名だけを追加
- midPoint: XML スキーマで定義されたタグを利用してカスタム属性を厳密に定義(シングルバリュー/マルチバリュー・型も明記)
と、「OpenIDM はゆるゆる 指向・midPointは キッチリ 指向」という違いがあります。OpenIDM 2系が出た頃はちょうど NoSQL ブームもあってスキーマレスが叫ばれることがありましたが、こと ID 管理においてはそれは違うんじゃないの?という midPoint 開発者達の思いを感じます。このあたりは、midPoint のアーキテクトである Radovan 氏が発表した OpenIDM Design Summit でのプレゼン資料 を読むとよく伝わってきます。この頃はまだ OpenIDM 1系を開発していた時ですが、ベースとなる思想は今の midPoint に引き継がれています。
同期機能の比較
ID管理の重要な機能の一つに、源泉システムや連携先システムとのID同期機能があります。次はこの同期機能にフォーカスして両プロダクトを見ていきます。
OpenIDM が提供している同期機能は大きく3つあります。
- Reconciliation: ターゲットシステムとの間で差分を発見してあるべき姿にデータを反映する同期処理。いわゆる差分同期。
- LiveSync: 源泉システムから変更点情報のみを定期的に短い間隔で取得し、準リアルタイムにデータを ID 管理システム側に反映する同期処理。
- Implicit synchronization: ID 管理システム内のデータが変更されたことを検知して、連携先システムに即座に反映する同期処理。いわゆるリアルタイムプロビジョニング。
一方、midPoint も同様の機能を備えた4つの種類の同期機能があります。最後の Discovery だけが midPoint 特有の同期処理ですね。
- Provisioning Synchronization: OpenIDM でいう Implicit synchronization と同じ。
- Live Synchronization: OpenIDM でいう LiveSync と同じ。
- Reconciliation: OpenIDM でいう Reconciliation と同じ。
- Discovery: 直接関係のないオペレーションから差分を発見して同期を行うタイプの同期処理。
また、同期の詳細設定の中には両プロダクトで同じ概念の設定項目があります。
- Correlation: ID 管理システム内のオブジェクトと、源泉または連携先システムのオブジェクトをリンキングするためのクエリ設定。すでに IDM 内でユーザーが存在する場合にこの仕組を使ってマッチングを行い、IDM内のアカウント ↔ システム内のアカウントのリンクを生成するために利用する。
- Situation と Action: 差分チェック時の結果ステータス(Situation と呼ぶ)とそれに対するアクション定義の設定。
上記のように、同期機能に関しては OpenIDM と同じ機能や言葉がたくさん使われており、もちろん細かい挙動に違いはあるものの、OpenIDM ユーザーにとっては概念理解がしやすいかと思います。
コネクター
同期処理において、源泉・連携先システムとの実際の接続処理はコネクターと呼ばれるコンポーネントが担います。これは OpenIDM、midPoint 両方で共通の概念であり、かつ実際のコネクターモジュールのインタフェースも以前は同じで、OpenIDM が採用している OpenICF を midPoint でも採用していました。しかし、現在は OpenICF の前身である Sun Identity Connector Framework(Sun ICF)からフォークして作られた ConnId に対応したコネクターのみに対応しています。ConnId は同じく OSS の ID管理プロダクトである Apache Syncope で採用されているコネクターであり、midPoint は Apache Syncope とコネクターを共有しているということになります。
midPoint は OpenICF に現在は対応していないですが、OpenICF も Sun ICF をフォークしたもののため、コネクターの概念・基本インタフェースは ConnId でも同じです。OpenIDM で得たコネクター周りのノウハウがあればそのまま midPoint でも使えるかと思います。
link と Shadow Object
OpenIDM では IDM 内のオブジェクト(Managed Object)と源泉・連携先のオブジェクト(System Object)の関係を link と呼び、OpenIDM のデータベースに保持していました(IDM 内のオブジェクトの ID と源泉・連携先のオブジェクトの ID の対応付けをレコードとして保存)。link があることで、前述の Situation の判断が細かく制御可能となるという考え方でした(例えば、link がある状態から片方のオブジェクトが見つからなくなった場合、削除されたと判断することができます)。
一方 midPoint では、link の代わりに Shadow Object という概念があります。ここが OpenIDM ユーザーにとっては今までにない概念で困惑するポイントの一つかもしれません。以下のドキュメントで説明されていますが、Shadow Object は源泉・連携先オブジェクトを表すもので、midPoint 内のデータベースに格納されます。Shadow Object は実際のオブジェクトを指し示すリファレンスであり、すべての属性を持つわけではありませんが、対応する源泉・連携先のオブジェクトを特定するための ID などは保持しています。その Shadow Object に対して、Focus オブジェクト(midPoint ではユーザーや組織、ロールを Focus オブジェクトといい、OpenIDM の Managed Object 相当)から参照が張られるとリンク状態、と認識されます。
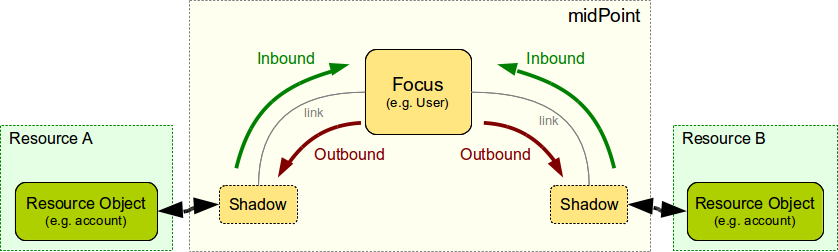
※出所:https://wiki.evolveum.com/display/midPoint/Focus+and+Projections
リンク状態の持ち方は違うものの、Shadow Object は OpenIDM の link +α のデータと考えると良いかもしれません。ただし、一つ大きく違う点として、OpenIDM の方はあくまで Managed Object とリンク関係が結ばれたときにレコードが生成されますが、midPoint のShadow Object はリンク関係がまだ結ばれていない、またはリンクが解消されても存在しうるというところです。midPoint を勉強中に試行錯誤して色々設定変更してデータを入れたり削除したりしていると、Shadow Object が残っていて警告やエラー表示される、というケースに遭遇することがよくあるのですが、Shadow Object は独立して存在しうるという点を覚えておくとよいでしょう。
また、OpenIDM の場合は link を敢えて作らない、という設定も可能でした。例えば、連携先システム側の ID 状態を意識せずに、単に OpenIDM 内のデータを連携先に出力する、ということを行う場合は link は不要な情報でオーバーヘッドにしかなりませんので、ここを省くことをよくやっていました。一方、midPoint においては Shadow Object は常に必須です。ここも大きな違いかと思います。OpenIDM のときのように link は不要なケースを midPoint で実現したい場合は、同期機能は利用せず Bulk actions を用いて実装するとよいでしょう。
同期のマッピング設定の考え方の違い
IDM において、同期のマッピング、つまりIDM 内の情報を源泉・連携先システムとどう対応づけるかの設定は、IDM の中で大部分を占める重要な設定です。このマッピング設定の考え方の違いについて見ていきます。
OpenIDM
OpenIDM では、まず源泉・連携先システムを表す System Object を定義していました。1つのシステムごとに、provisioner-*.json というファイルを作成し、使用するコネクター・属性マッピング(外部システムの物理的な名称と System Object で利用する論理名の対応付け)などを設定します。そして、IDM 内で管理するオブジェクトの種類については managed.json で定義します。その上で、sync.json というファイルに System Object と Managed Object のマッピング情報を定義します。
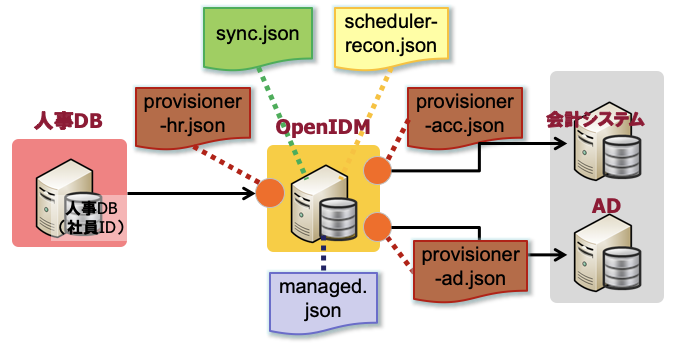
sync.json では source(同期元)と target(同期先)を設定しつつ、この同期における属性マッピング情報を設定します。
OpenIDM では、 「source を源泉システムの System Object / target を Managed Object」とすれば源泉同期になり、「source を Managed Object / target を連携先システムの System Object」とすればプロビジョニングになるという汎用的な設定でした。
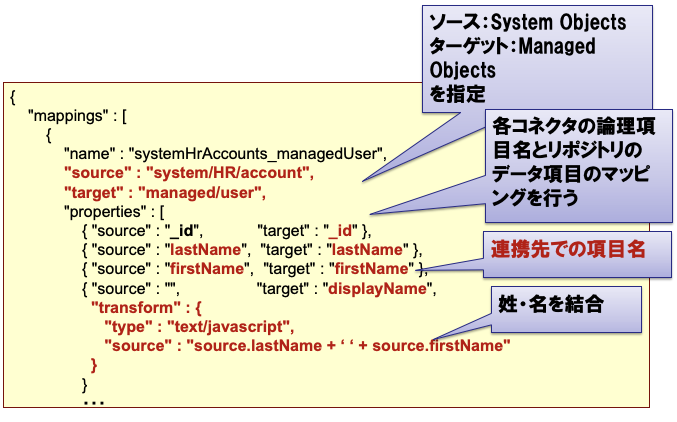
このように、**OpenIDM では「同期用の設定にてまとめてマッピングを定義する」**という考え方でした。
midPoint
一方 midPoint では まず源泉・連携先システムを表す Resource を定義するためのリソース定義を作成します。1つのシステムごとに、管理画面からリソースの作成を行い、使用するコネクター設定を行います。OpenIDM でいう System Object の定義と同様のものですが、大きな違いとして、このリソース定義内にて IDM 内のオブジェクト(Focus Object)とのマッピングを定義します(Resource Schema Handling の定義といいます)。また、OpenIDM とは異なり、外部システムの物理属性名と論理属性名マッピングは行いません。というのも、OpenIDMでは、リソース側でどういう属性を利用するか System Object の定義でスキーマを定義していましたが(そこで物理属性名と論理属性名をマッピングしていた)、midPoint ではこの作業をコネクターが外部システムからスキーマ情報を取得することで自動的に行なってくれるため、自分で定義する必要はないのです。
そして Resource Schema Handling の定義にて、Inbound、Outbound または両方 のマッピングを定義することで、源泉 → IDM 方向の同期、IDM → 連携先への同期、または双方向同期なのかをコントロールしています。
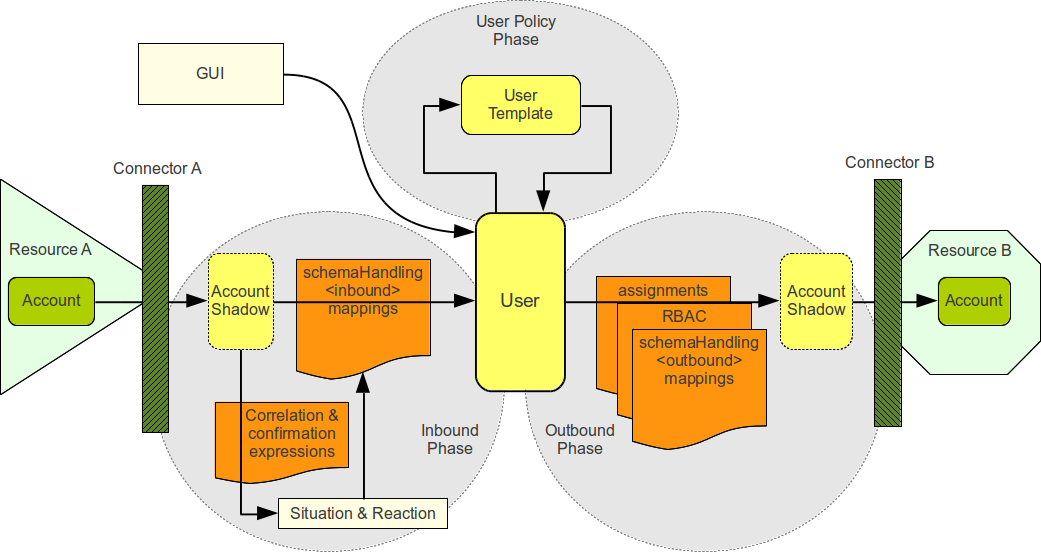
※出所:https://wiki.evolveum.com/display/midPoint/Synchronization+Policies
このように、midPoint では「リソース定義にてそのリソースに関するマッピングを定義する」 という考え方となっています。
さらに、midPoint には OpenIDM にはない Object Template というものがあります(上図だと User Template の部分)。このテンプレート内でもマッピング処理を書くことができます。自オブジェクト内で属性をマッピングすることができ、例えば lastName 属性と firstName 属性を結合して fullName 属性にマッピングする、といった定義ができたり、title 属性が部長の場合は部長ロールを自動的にアサインする、といったことができます。これは OpenIDM にはなかった考え方です。OpenIDM では Managed Object にて Trigger 設定を行うことで、更新処理をフックしてデータを1つのスクリプトで加工して同様のことを実現する必要がありましたが、スクリプトが肥大化してメンテナンスが大変になるという特徴がありました。midPoint だと属性単位にそのような加工処理を定義できるため、メンテナンスしやすくなります。
なお、OpenIDM の Trigger 相当のことは midPoint では Hooks という機構で別途提供されています。特定の更新処理をひっかけて加工したいというユースケースの場合は、Object Template では実装しづらいためこちらを使うとよいでしょう。
プロビジョニング対象の考え方の違い
同期機能に関して、最後にプロビジョニング対象の考え方の違いを解説したいと思います。
OpenIDM
基本的に、sync.json で定義された source のオブジェクト一覧がプロビジョニング対象となります。プロビジョニング対象の一覧抽出のクエリ条件や、1オブジェクトあたりの条件チェックで対象は除外できるものの、リコンシリエーションを実行して source をまとめてプロビジョニングする、という考え方になります。
midPoint
midPoint では sync.json のような source と target を指定したプロビジョニングの設定は存在しません。midPoint で管理されるオブジェクト1つ1つに対して、どこのリソースにプロビジョニングさせるかを関連付けさせる必要があります。この関連付けは大きく3つの方法があります。
- ユーザーなどの Focus オブジェクトにリソース(プロジェクション)を直接アサインする
- ユーザーなどの Focus オブジェクトにロールや組織をアサインして間接的にリソースにアサインさせる(ロールにリソースを inducement)
- ユーザーなどの Focus オブジェクトに(後述する)Archetype をアサインして間接的にリソースにアサインさせる(Archetype にリソースを inducement、または Archetype にロールを inducement しつつそのロールにリソースを inducement)
基本的には1の方法は使わず、2か3のロールや組織、Archetype を経由して間接的にアサインする方式が推奨されます(ロール等を起点としてプロビジョニングすることから、Role-based provisioning と呼ばれます)。このあたりは6日目、7日目の記事を参考にしてもらえばと思います。
よって、連携先とのリコンシリエーションタスクを実行する前にまずはリソースへの関連付けを先に行う必要がある点が OpenIDM との大きな違いになります。その関連付けは、ユーザーに該当リソースへのアサインを間接的に行うロール・組織をアサインすることで行いますが、このアサインの仕方は業務要件に応じて考える必要があります。
例えば、LDAPは全ユーザデフォルトでプロビジョニングする、という要件だったとしましょう。この場合、ユーザーにはLDAPリソースが間接的に自動アサインされるように Object Template を活用などすればよいでしょう。デフォルトではなく、特定のユーザーだけ(ある属性を持つユーザーだけ、ある組織に所属しているユーザーだけなど)対象としたい場合も同様に Object Template で自動アサインを制御できます。自動アサインできないようなタイプのリソースへのプロビジョニングを行いたい場合は、ロールの要求機能というセルフサービスによるロールアサインの機構を利用してロールアサインを行うのが midPoint way です。
UI と 提供モデルの比較
次のトピックは UI と提供モデルについてです。ここは両プロダクトでまったく考えが違うところになります。
OpenIDM が提供する UI はかなり簡易的なもので、ForgeRock 社もカスタマイズされることを想定したものと位置づけています。一方、midPoint はカスタマイズ開発は可能なものの、一般利用者にそのまま使ってもらえる UI を目指しています(システム管理者向け画面では現状諦めている部分があります)。
また、一般的に ID 管理システムは導入先企業ごとにデータモデルに色が出てくる傾向にあります。データモデルが各企業ごとにバラバラなのに事前にカチっとしたデータモデルなんか提供するのは無理で、ほぼ必須となるユーザーモデルのみ提供しよう、というのが OpenIDM の考え方です。一方、midPoint は異なるアプローチを取っています。彼らの長年の経験から、ID 管理システム内で管理すべきデータモデルは、UserType、OrgType、RoleType、ServiceType の4タイプに集約されて提供されています。しかし現実世界では到底4タイプには収まりません。組織(OrgType)といっても、会社・本部・部・課・チーム・プロジェクトと色々種別があるでしょう。そこで彼らは、サブタイプという概念を作り出し、同じオブジェクトタイプを使いつつもこういった種別を表現可能にすることにしました。そしてこのサブタイプをさらに汎用化し、Archetype(アーキタイプ)という概念がバージョン4.0にて導入されました。さらに、ID のライフサイクル管理(ID の状態遷移管理)を実現できるように、最初からライフサイクルステートという状態ステータスを表す属性や、有効期限の属性が定義されており、ステートの変更や有効期限切れをトリガーとして処理するような仕組みも備えています。このような思想の元、midPoint は多くの ID 管理プロジェクトに適合可能な汎用的なデータモデルを作り上げています。
OpenIDM の方はユーザーモデルのみ(最近のバージョンではロールも)の提供で、それ以外は自分達で設計・定義してカスタマイズしていく必要があり、ここは非常に大きな違いポイントになります。
カスタムエンドポイント追加の比較
OpenIDM は独自の REST API をスクリプト言語で簡単に定義可能な機能を備えていました(Scripting Service)。これは、前述の通り UI が SPA で構成かつカスタマイズを想定したものとなっており、そのカスタマイズのためには合わせてカスタムエンドポイントも作る必要性が高いためでした。
一方、midPoint はスクリプト言語による REST API 拡張の機能は持っておらず、Java で記述する必要があります。ただ、OpenIDM とは異なり UI をがっつり作り込むケースは基本的には避けるべきで、カスタマイズ開発するにしても SPA ではないため、画面開発において REST API 追加が必須ということにはなりません。
IGA 要素機能の比較
Governance を効かせる系の機能は、midPoint が得意としている分野です。OpenIDM はそのような機能はあまりなく、最新の ForgeRock IDM を見てもその傾向は変わらないようです。これは、ForgeRock 社の戦略的に、彼らの IAMリューションのターゲットは EIAM(Enterprise Identity and Access Management)ではなく、CIAM (Customer Identity and Access Management)をターゲットとしているからと考えられます。CIAM 特化の場合、Governance 系の機能はそこまで重要視されないためです。
一方 midPoint では、明言はしていないものの EIAM をメインターゲットとした機能構成になっています。たとえば OpenIDM にはない、以下のような機能を提供しています。
- Reporting: Jasper Reporting によるレポート出力機能を提供。
- Access Certification: アクセス認定、またはキャンペーンとも呼ばれる。いわゆるID棚卸しの機能を提供。
特に Access Certification はユニークな機能かと思います。OSS でここまで実装している他の ID 管理プロダクトは見たことがありませんでした。
おわりに
というわけで今回は趣向を変えて、様々な観点から OpenIDM と比べつつ midPoint を紹介してみました。OpenIDM と midPoint で似ているところ、異なるところをピックアップして紹介させていただきました。本記事が、ここまで読んで頂いた方の midPoint 理解を深めるのに役立ちましたら幸いです![]()
明日は、OpenStandia チームでも midPoint スペシャリストである @sa-nagata より、本記事でも少し触れました Archetype について熱く語ってもらう予定です。ご期待ください!