Amazon Bedrock Advent Calendar 2023の4日目の記事です。
日本語だけで画像生成したい
ここ1、2年で、大規模言語モデル(以降、LLM)や画像生成AIなどの生成系AIが急速に発展し、大きな注目を集めています。LLMはチャットUIを使って直感的に操作できるため、多くの人が実際に体験していると思います。
一方で、画像生成AIは英語のプロンプトを書く能力が必要だったり、パラメータ調整が難しかったりするため、日本語話者にとってハードルが高く、なかなか手が出せないのが現状だと思います(補足:ChatGPTの有料プランでは、日本語による画像生成が可能です)。
日本語で直感的に画像生成ができれば、生成系AIの可能性をより多くの人に体験してもらえるはずです。そこで今回は、日本語のみで画像生成を実現するgenerative-ai-use-cases-jpをご紹介します。
※前半は技術色の薄い内容なので、前提知識がなくても読み進めることができます。後半で技術の解説を行います。
generative-ai-use-cases-jpとは
generative-ai-use-cases-jpとはGitHubのaws-samplesとして公開しているOSSのプロジェクトとなります。
こちらのリポジトリは、awsの生成系AIサービスであるAmazon Bedrockを使ったさまざまなユースケースを日本語で試すことができます。「生成系AIで何ができるのかよくわかっていない」「上司から生成系AIを使って何かやれって言われてるけど何をして良いのかわからない」という方に、おすすめのリポジトリです!
こちらのリポジトリは、「チャット」「文章校正」「翻訳」などの生成系AIのよくあるユースケースを気軽に試せることをコンセプトに開発しています。そのユースケースの1つに「画像生成」の機能があります。
このリポジトリで、生成系AIの可能性を体感できると思うので、ぜひデプロイしてみてください!プロンプトのサンプルも多数載せていますので、プロンプトエンジニアリングを学習中の方にもおすすめです!
不具合報告や要望も随時募集していますので、気軽にIssueに投稿をお願いします!
デプロイ方法
こちらのツールは、AWS Cloud Development Kit(以降、CDK)というツールでデプロイを行います。詳しくは、こちらの手順をご覧ください。
画像生成だけを試したい場合は、 RAGを有効化しないことを強くオススメします。RAGで利用するAmazon Kendraが月額810USD課金されるサービスであるためです。RAGを明示的に有効化しなければAmazon Kendraはデプロイされませんので、ご安心ください。
画像生成を試してみる
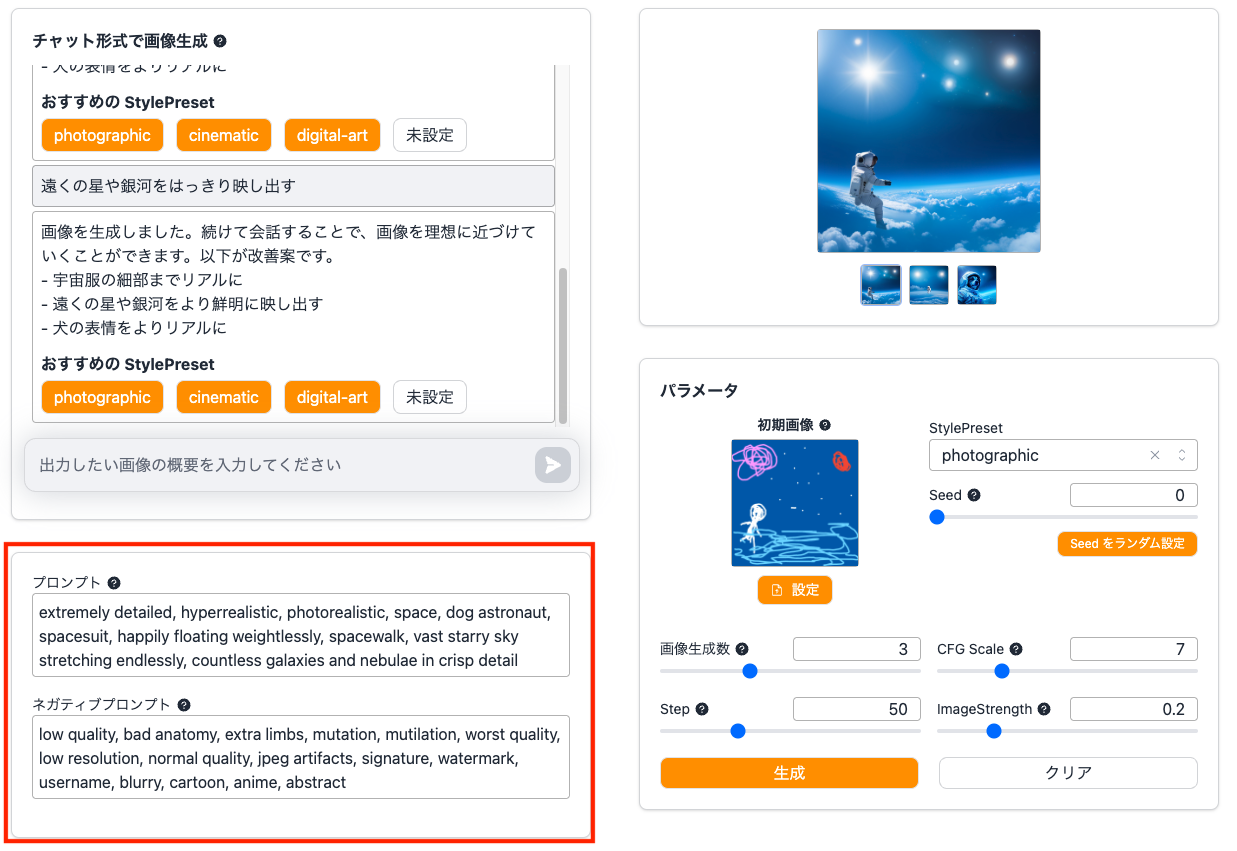
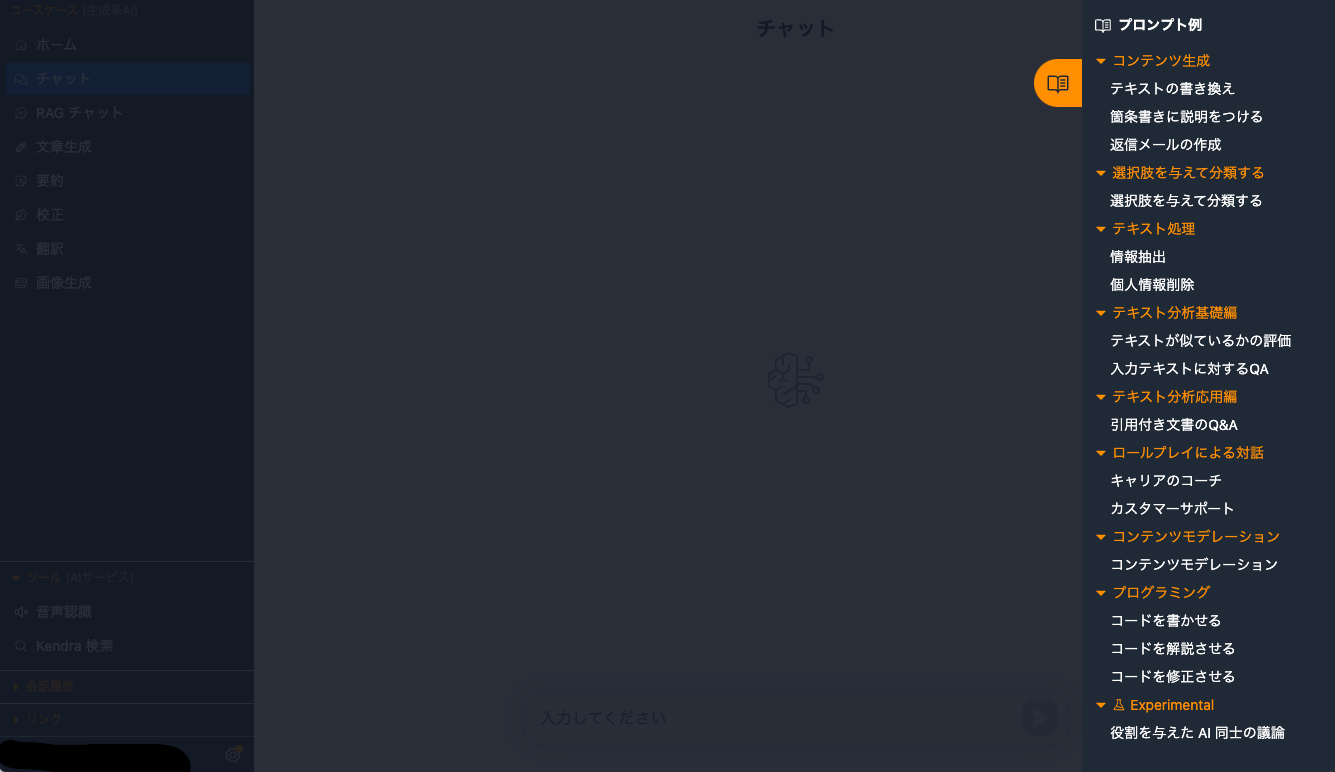
無事にデプロイが完了したら、ブラウザからデプロイしたWebページを開いてください。画面左側のメニューから「画像生成」を選ぶと以下の画面が表示されます。
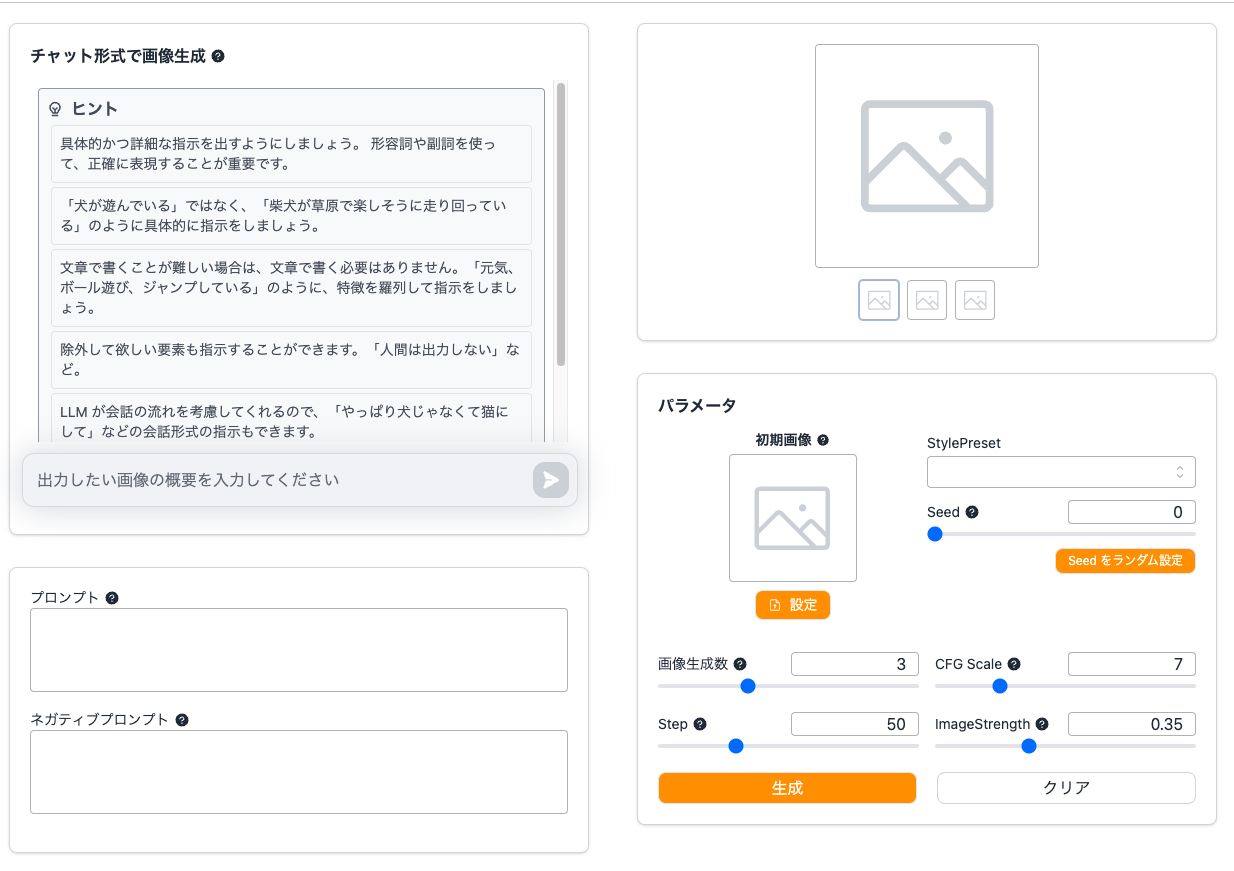
この機能の特徴は、チャット形式で日本語による画像生成が行えることです。画像生成モデルにStable Diffusionを利用していますが、Stable Diffusionの知識は一切必要ありませんのでご安心ください!
それでは、実際に試してみましょう。
難しい設定は一切必要ありません。チャット欄に日本語で生成したい画像の内容を入力するだけで、自動で画像が生成されます。
実際に、チャット欄に「犬が宇宙遊泳を楽しんでいる」と入力してみると、以下のように画像が生成されました!
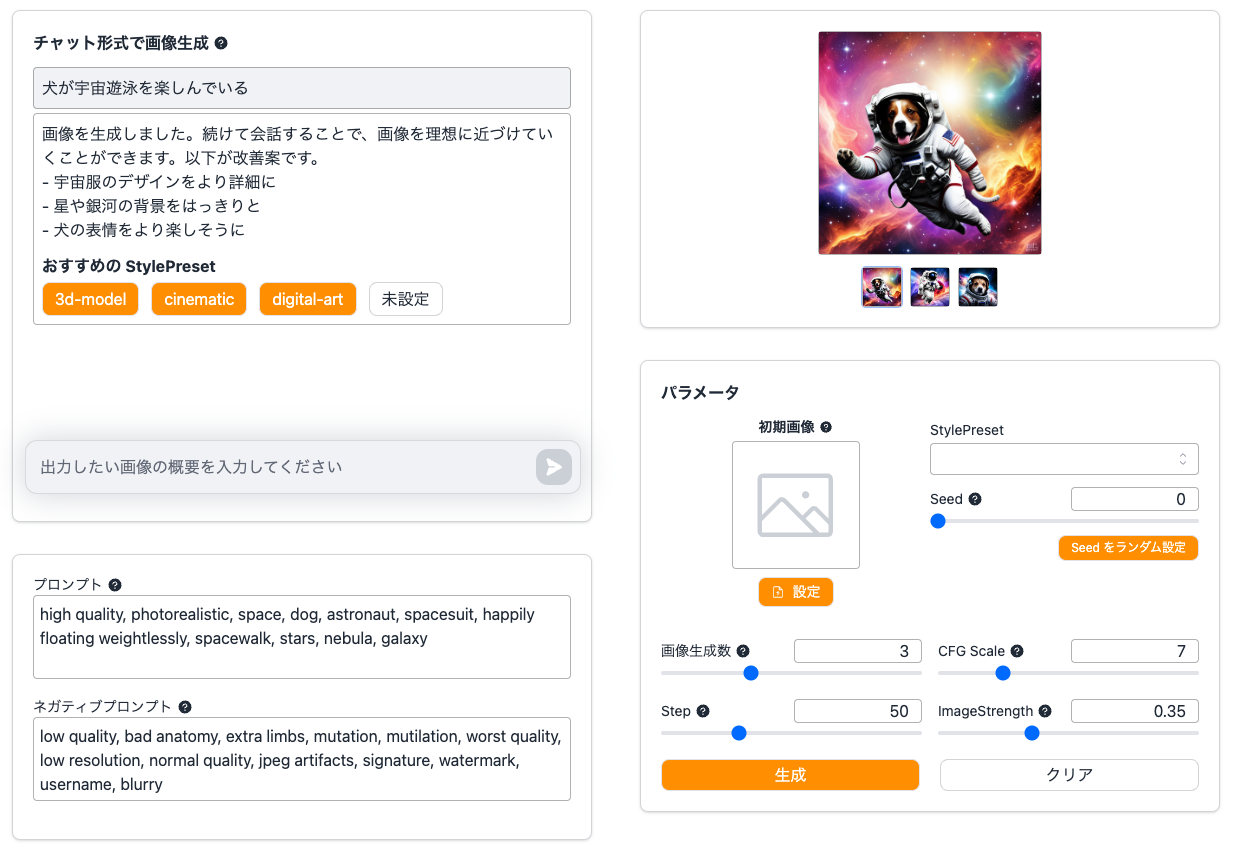
実際に生成された画像
| 1枚目 | 2枚目 | 3枚目 |
|---|---|---|
 |
 |
 |
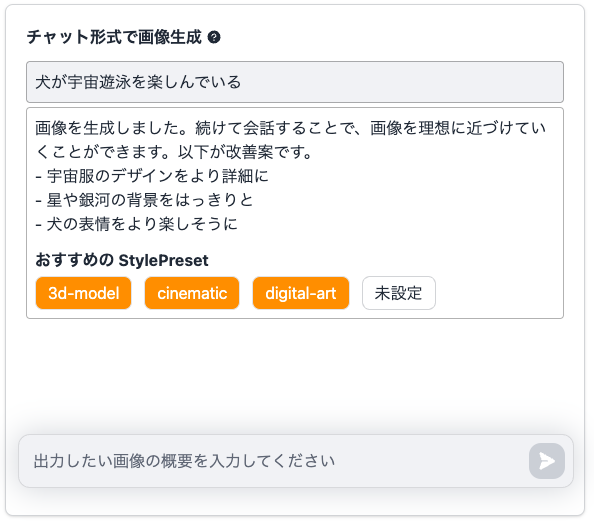
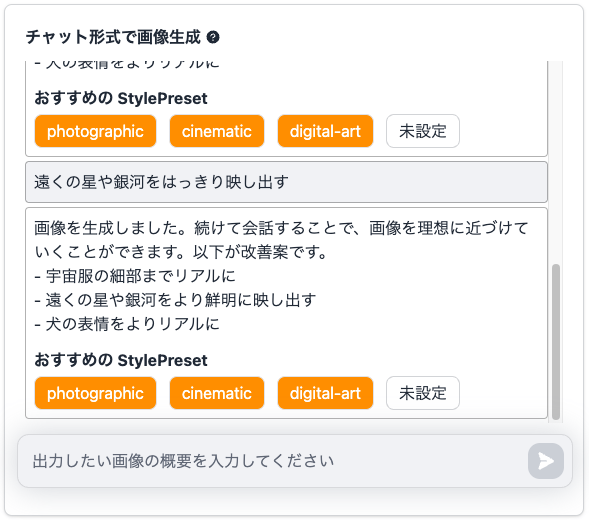
画像生成が終わると、以下の様にチャット欄に画像の改善案と、おすすめのStylePresetが提案されます。改善案を提案してくれるので、初心者でも簡単に画像の改善に取り組むことができます!
では、おすすめのStylePresetで提案された「cinematic」を選んで、映画風の画像にしてみることにします。
「cinematic」で生成された画像
| 1枚目 | 2枚目 | 3枚目 |
|---|---|---|
 |
 |
 |
ちょっと映画風になった様な気がしますね!
次は、チャットを利用して「もっとリアルに」「背景の宇宙を広く」するように指示を出してみます。
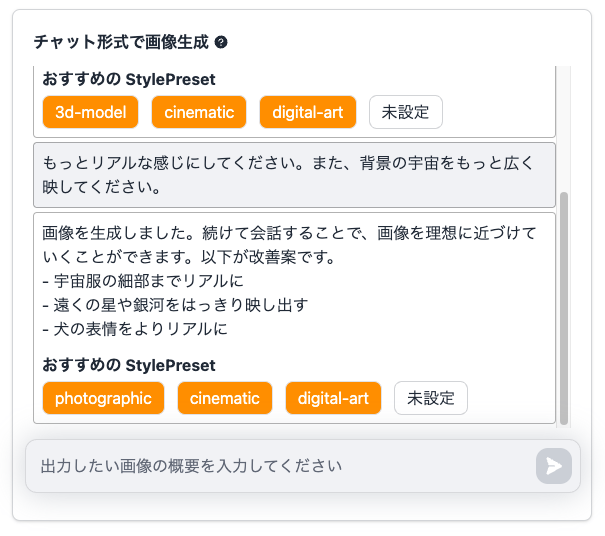
実際に生成された画像
| 1枚目 | 2枚目 | 3枚目 |
|---|---|---|
 |
 |
 |
立体感が増して、細部がよりリアルに描画された感じがしますね!
ただ、背景の宇宙があまり強調されていないので、提案された「遠くの星や銀河をはっきり映し出す」をそのままチャットで指示してみます。
実際に生成された画像
| 1枚目 | 2枚目 | 3枚目 |
|---|---|---|
 |
 |
 |
背景が少しだけ詳細に描かれましたが、正直そんなに変わっていないですね。
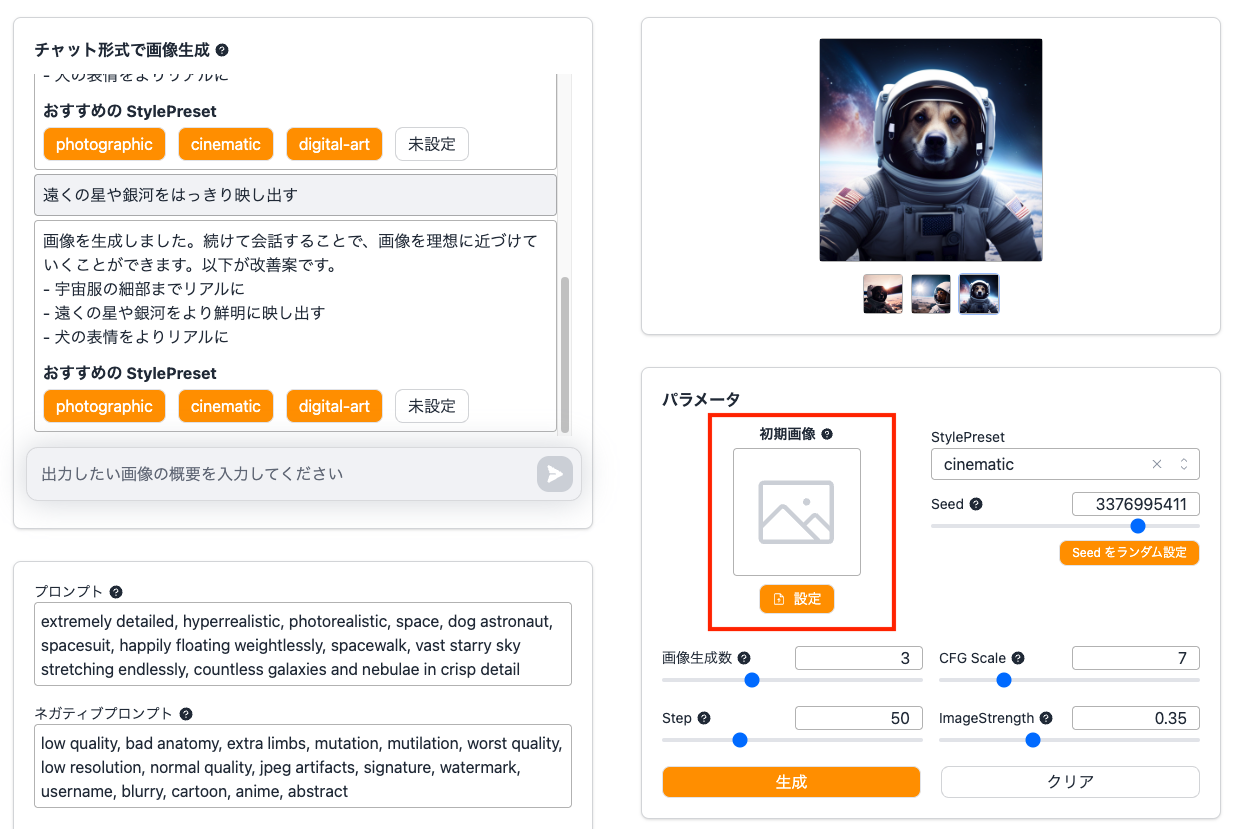
次は「初期画像」を使って、具体的な構図を指示してみようと思います。この初期画像とは、画像を生成する際の初期状態の画像のことです。こちらを指定することで、初期画像に似た画像を生成することができます。
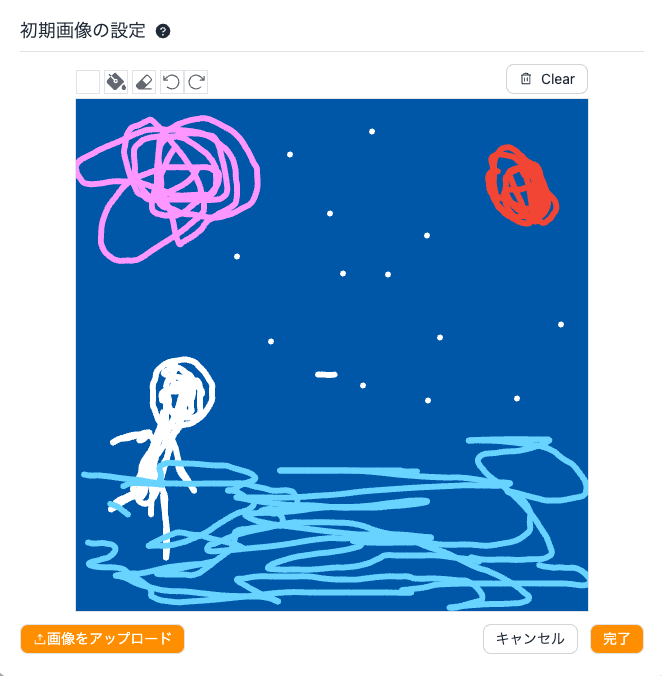
このリポジトリでは、手書きで初期画像を設定することが可能です。
こちらの機能では、「手書き」「手元の画像をアップロード」「手元の画像をアップロードしてさらに手書きする」という3パターンの使い方ができます。今回は絵心が無いながらも頑張って手書きしてみました!
では、実際にこちらの絵を元に生成してみましょう!
実際に生成された画像
| 1枚目 | 2枚目 | 3枚目 |
|---|---|---|
 |
 |
 |
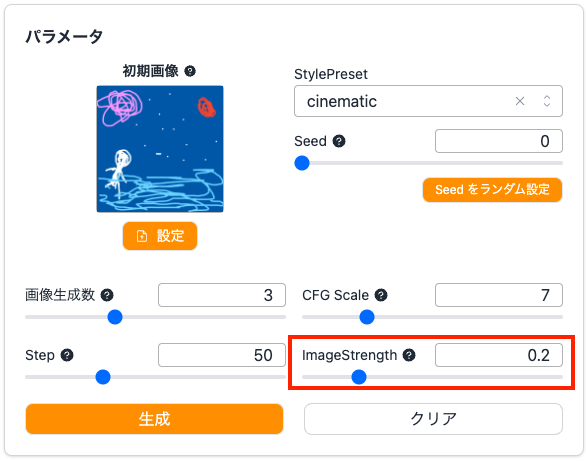
手書きの画像にそっくりな画像が生成されました!ただ、手書きで雑に書いた絵を元に忠実に画像生成されても困ることもあります。パラメータを調整して初期画像の影響を小さくしてみます。
「ImageStrength」の値を小さくすればするほど、初期画像とは異なる画像を生成する様になります。今回は「0.2」を設定してみます。
実際に生成された画像
| 1枚目 | 2枚目 | 3枚目 |
|---|---|---|
 |
 |
 |
このようにチャットや各種パラメータの設定で、直感的に画像の生成と改善を行なっていくことができます!興味を持った方は、ぜひデプロイして使ってみてください!
応用的な使い方
StableDiffusionの知識がある方は、直接プロンプトを触って改善したい場合もあると思います。
こちらの機能では、画像生成に利用しているプロンプトとネガティブプロンプトを自由に修正して、画像を生成することが可能です。
日本語である程度のプロンプトを出力して、それをベースにプロンプトを自分で直接改善していくという使い方もできますので、既にStableDiffusinoの扱いに慣れている方も、ぜひ使ってみてください!
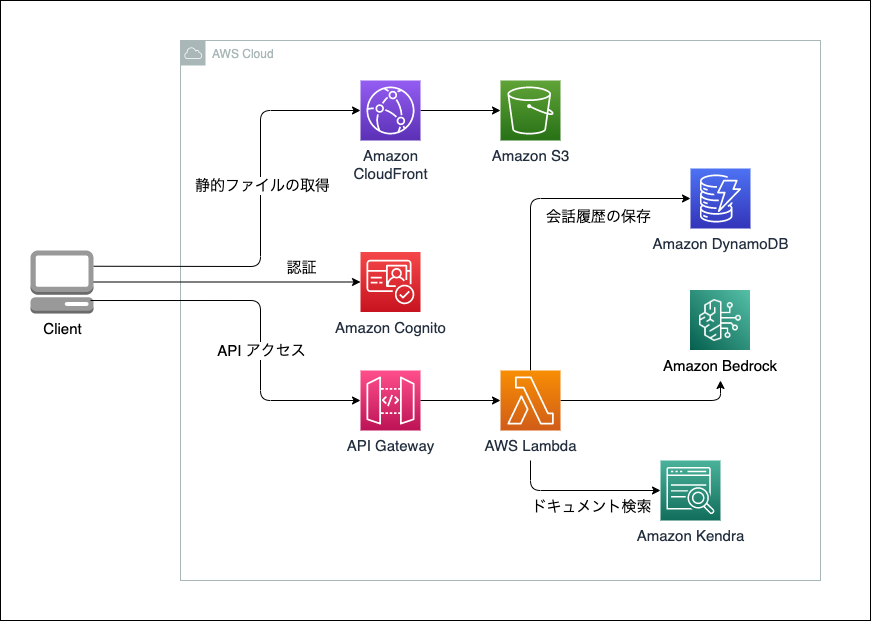
技術の解説
このアセットは以下のアーキテクチャで実装されており、マネージドサービスを利用したサーバレスのアーキテクチャとなっています。
今回は、画像生成部分に絞って解説していきます。
画像生成は、以下の流れで実行しています。
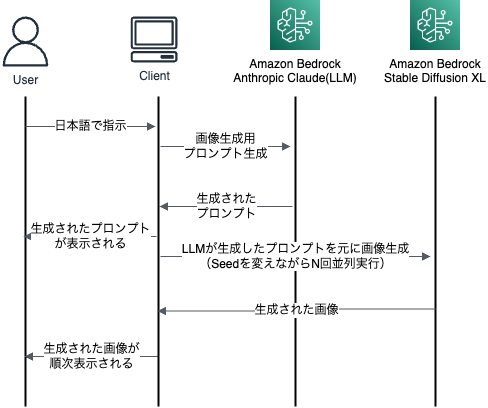
画像生成用プロンプト生成
画像生成用のプロンプトを生成するために、LLM(今回だと Anthropic Claude v2)を利用しています。
チャット形式でやり取りを行なっており、会話の流れを考慮したプロンプト生成を実現しています。
例えば、「犬と人間が公園で遊んでいる」画像を出力し、やっぱり人間は表示したくないなと思ったら、「人間を出力しないでください」と指示することで、人間だけ画像に出力しないということが可能になります。
実際に、LLMで推論するプロンプトを見てみましょう。
あなたはStable Diffusionのプロンプトを生成するAIアシスタントです。
<step></step>の手順でStableDiffusionのプロンプトを生成してください。
<step>
* <rules></rules> を理解してください。ルールは必ず守ってください。例外はありません。
* ユーザは生成して欲しい画像の要件をチャットで指示します。チャットのやり取りを全て理解してください。
* チャットのやり取りから、生成して欲しい画像の特徴を正しく認識してください。
* 画像生成において重要な要素をから順にプロンプトに出力してください。ルールで指定された文言以外は一切出力してはいけません。例外はありません。
</step>
<rules>
* プロンプトは <output-format></output-format> の通りに、JSON形式で出力してください。JSON以外の文字列は一切出力しないでください。JSONの前にも後にも出力禁止です。
* JSON形式以外の文言を出力することは一切禁止されています。挨拶、雑談、ルールの説明など一切禁止です。
* 出力するプロンプトがない場合は、promptとnegativePromptを空文字にして、commentにその理由を記載してください。
* プロンプトは単語単位で、カンマ区切りで出力してください。長文で出力しないでください。プロンプトは必ず英語で出力してください。
* プロンプトには以下の要素を含めてください。
* 画像のクオリティ、被写体の情報、衣装・ヘアスタイル・表情・アクセサリーなどの情報、画風に関する情報、背景に関する情報、構図に関する情報、ライティングやフィルタに関する情報
* 画像に含めたくない要素については、negativePromptとして出力してください。なお、negativePromptは必ず出力してください。
* フィルタリング対象になる不適切な要素は出力しないでください。
* comment は <comment-rules></comment-rules> の通りに出力してください。
* recommendedStylePreset は <recommended-style-preset-rules></recommended-style-preset-rules> の通りに出力してください。
</rules>
<comment-rules>
* 必ず「画像を生成しました。続けて会話することで、画像を理想に近づけていくことができます。以下が改善案です。」という文言を先頭に記載してください。
* 箇条書きで3つ画像の改善案を提案してください。
* 改行は\\nを出力してください。
</comment-rules>
<recommended-style-preset-rules>
* 生成した画像と相性の良いと思われるStylePresetを3つ提案してください。必ず配列で設定してください。
* StylePresetは、以下の種類があります。必ず以下のものを提案してください。
* 3d-model,analog-film,anime,cinematic,comic-book,digital-art,enhance,fantasy-art,isometric,line-art,low-poly,modeling-compound,neon-punk,origami,photographic,pixel-art,tile-texture
</recommended-style-preset-rules>
<output-format>
{
prompt: string,
negativePrompt: string,
comment: string
recommendedStylePreset: string[]
}
</output-format>
プロンプトの冒頭で、「Stable Diffusionのプロンプトを生成する」役割であることを認識させています。
プロンプトの生成手順を明確に指示しており、LLMの判断で勝手にプロンプトを生成しない様にしています。また、JSON形式で出力する様に指示をしており、そのJSONの項目にそれぞれ何を設定すべきかどうかというのもルールで細かく定義しています。正確性が求められる処理の場合は、ルールを細かく、かつ明確に定めることで、LLMが自由に創作しない様にする必要があります。ルールが曖昧だと、LLMが自由に創作して自分の意図した動きをしてくれないことがあるので、注意してください。
LLMがこなすタスクのルールを細かく定義するためには、プロンプトを書く人がそのタスクに詳しい必要があります。今回、私が全くStable Diffusionの知識がなかったため、「Stable Diffusion prompt: a definitive guide」と「【初心者向け】Stable Diffusionのプロンプトガイド!!!」という記事でStable Diffusionについて勉強させていただきました。
LLMは与えられたタスク(今回だとStable Diffusionのプロンプト生成)をこなす以外にも、「LLMから提案させる」ということも可能です。今回は、画像の改善案とおすすめのStylePresetを提案してもらう様にしました。アイデア次第では、もっと色々な提案ができる様になると思いますので、アイデアをお持ちの方はぜひ改造して遊んでみてください!
補足: ルールなどの条件をXMLタグで指定していますが、これはClaudeがプロンプト内のXMLタグを認識できるように作られているためです(参考1, 参考2)。
少し話が脱線しますが、こちらのアセットには、プロンプトサンプル集があり、実際にプロンプトを試すことができます。
チャット機能の右端にあるアイコンをクリックすることでプロンプト一覧が表示され、実際にチャット機能でそのプロンプトを試すことができます。ぜひ、こちらも触ってみてください!
LLMの推論処理
Stable Diffusionのプロンプトを生成する推論処理は、Amazon BedrockのInvokeModelWithResponseStream APIを利用したストリーミング処理を行っています。
今回ストリーミング処理を利用した意図は以下の通りです。
- このアセットの他の機能と合わせるため
- チャット機能などはUXを向上させるためにストリーミング処理が非常に重要です。
-
API Gatewayが30秒でタイムアウトするため
- API Gatewayを利用した同期処理だと30秒でタイムアウトするため、場合によってタイムアウトして処理が失敗することがあります。
ストリーミング処理は以下の通り、AWS LambdaのStreaming Responseの機能を利用して実装しています。
import { Handler } from 'aws-lambda';
import { PredictRequest } from 'generative-ai-use-cases-jp';
import api from './utils/api';
declare global {
namespace awslambda {
function streamifyResponse(
f: (
event: PredictRequest,
responseStream: NodeJS.WritableStream
) => Promise<void>
): Handler;
}
}
export const handler = awslambda.streamifyResponse(
async (event, responseStream) => {
for await (const token of api.invokeStream(event.messages)) {
responseStream.write(token);
}
responseStream.end();
}
);
invokeStream: async function* (messages) {
const command = new InvokeModelWithResponseStreamCommand({
modelId: process.env.MODEL_NAME,
body: JSON.stringify({
prompt: generatePrompt(messages),
...PARAMS,
}),
contentType: 'application/json',
});
const res = await client.send(command);
if (!res.body) {
return;
}
for await (const streamChunk of res.body) {
if (!streamChunk.chunk?.bytes) {
break;
}
const body = JSON.parse(
new TextDecoder('utf-8').decode(streamChunk.chunk?.bytes)
);
if (body.completion) {
yield body.completion;
}
if (body.stop_reason) {
break;
}
}
},
API GatewayがStreaming Responseに対応していないため、フロントエンドのReactから直接Lambdaを実行する作りとなっています。
「フロントエンドから直接Lambdaを実行して安全なの?」と思う方もいらっしゃると思います。こちらは、CognitoのIdentityPoolを利用した認可機能を使って安全性を担保しています。
以下のようにCDKのコードで、IdentityPoolで認証済みユーザのみに実行権限を付与しています(別途、IdentityPoolとUserPoolを関連づけています)。
const predictStreamFunction = new NodejsFunction(this, 'PredictStream', {
runtime: Runtime.NODEJS_18_X,
entry: './lambda/predictStream.ts',
timeout: Duration.minutes(15),
environment: {
MODEL_TYPE: modelType,
MODEL_REGION: modelRegion,
MODEL_NAME: modelName,
PROMPT_TEMPLATE: promptTemplate,
},
bundling: {
nodeModules: [
'@aws-sdk/client-bedrock-runtime',
// デフォルトの client-sagemaker-runtime のバージョンは StreamingResponse に
// 対応していないため package.json に記載のバージョンを Bundle する
'@aws-sdk/client-sagemaker-runtime',
],
},
});
predictStreamFunction.grantInvoke(idPool.authenticatedRole);
フロントエンドからは、@aws-sdk/client-lambdaを利用して、Lambdaを直接実行します。
SDKを利用することで、自動でIdentityPoolで認可処理が行われて、安全にLambdaを実行します。
predictStream: async function* (req: PredictRequest) {
const region = import.meta.env.VITE_APP_REGION;
const userPoolId = import.meta.env.VITE_APP_USER_POOL_ID;
const idPoolId = import.meta.env.VITE_APP_IDENTITY_POOL_ID;
const cognito = new CognitoIdentityClient({ region });
const providerName = `cognito-idp.${region}.amazonaws.com/${userPoolId}`;
const lambda = new LambdaClient({
region,
credentials: fromCognitoIdentityPool({
client: cognito,
identityPoolId: idPoolId,
logins: {
[providerName]: (await Auth.currentSession())
.getIdToken()
.getJwtToken(),
},
}),
});
const res = await lambda.send(
new InvokeWithResponseStreamCommand({
FunctionName: import.meta.env.VITE_APP_PREDICT_STREAM_FUNCTION_ARN,
Payload: JSON.stringify(req),
})
);
const events = res.EventStream!;
for await (const event of events) {
if (event.PayloadChunk) {
yield new TextDecoder('utf-8').decode(event.PayloadChunk.Payload);
}
if (event.InvokeComplete) {
break;
}
}
},
画像生成処理
LLMが生成した画像生成用のプロンプトを実際にStable Diffusionに設定して画像生成を行います。
Amazon BedrockのInvokeModel APIを実行して、画像を生成しています。
Amazon Bedrockで扱う画像(初期画像(init_image)や生成された画像)はBASE64でエンコードされていること前提となります。画像に関する処理は、必要に応じてエンコード/デコードします。
generateImage: async (params) => {
// 現状 StableDiffusion のみの対応です。
// パラメータは以下を参照
// https://platform.stability.ai/docs/api-reference#tag/v1generation/operation/textToImage
const command = new InvokeModelCommand({
modelId: process.env.IMAGE_GEN_MODEL_NAME,
body: JSON.stringify({
text_prompts: params.textPrompt,
cfg_scale: params.cfgScale,
style_preset: params.stylePreset,
seed: params.seed,
steps: params.step,
init_image: params.initImage,
image_strength: params.imageStrength,
}),
contentType: 'application/json',
});
const res = await client.send(command);
const body = JSON.parse(Buffer.from(res.body).toString('utf-8'));
if (body.result !== 'success') {
throw new Error('Failed to invoke model');
}
return body.artifacts[0].base64;
},
このアセットでは、複数枚同時に画像生成することができます。seedを変えることで、同じパラメータでも異なる画像を生成できます。フロントエンドの処理で、ランダムにseedを設定しながら画像生成のリクエストを行なっています。また、Promiseを利用することで、非同期の並列処理を実現しています。
const generateImage = useCallback(
async (_prompt: string, _negativePrompt: string, _stylePreset?: string) => {
clearImage();
setGenerating(true);
const promises = new Array(imageSample).fill('').map((_, idx) => {
let _seed = seed[idx];
if (_seed < 0) {
const rand = generateRandomSeed();
setSeed(rand, idx);
_seed = rand;
}
return generate({
textPrompt: [
{
text: _prompt,
weight: 1,
},
{
text: _negativePrompt,
weight: -1,
},
],
cfgScale,
seed: _seed,
step,
stylePreset: _stylePreset ?? stylePreset,
initImage: initImageBase64,
imageStrength: imageStrength,
})
.then((res) => {
setImage(idx, res);
})
.catch((e: AxiosError<{ message: string }>) => {
console.log(e);
setImageError(idx, e.response?.data.message ?? e.message);
});
});
await Promise.all(promises).finally(() => {
setGenerating(false);
});
},
[
cfgScale,
clearImage,
generate,
generateRandomSeed,
imageSample,
imageStrength,
initImageBase64,
seed,
setImage,
setImageError,
setSeed,
step,
stylePreset,
]
);
最後に
ぜひ、みなさんもgenerative-ai-use-cases-jpを利用して、画像生成を楽しんでみてください!
こちらのアセット以外にも、チャット機能に特化したbedrock-claude-chatと、ドキュメント検索に特化したsimple-lex-kendra-jpというAmazon Bedrockを活用するアセットがあるので、ぜひこちらも使ってみてください!