概要
プログラミングを始めて半年の初心者ですが、機械学習(ランダムフォレスト)の勉強のため、こちらの記事を参考に勉強しました。
https://www.codexa.net/kaggle-mercari-price-suggestion-challenge/
基本的な流れはこの通りやってれば問題なくできるのですが、コード入力で「これって何の意味があるねん?」と思った部分をいろいろ調べてメモしました。
Pandasでのデータ読み込みで速攻つまずいた
タイトルの通りです。
ダウンロードしたファイルはとりあえずデスクトップに置きましたが、pandasでファイルが見つかりませんて・・・
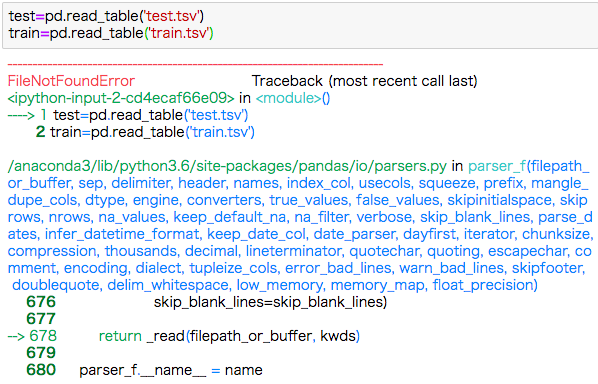
どうやらファイルの在り処を指定してやらなければならないみたい。
詳しい記事はこちらで書いてます。
今後はosをインポートして、まずはフォルダ移動します。
import os
os.chdir('Users/自分の名前/desktop')
Kaggleメルカリのデータ確認
チュートリアルではデータタイプを指定して読み込んでいましたが、まずはそのまま読み込んでみます。
ちなみにダウンロードして解凍したtrain.tsvファイル及びtest.tsvファイルをデスクトップに置きましたが、そのままファイル名を指定しただけではpandasで読み込みできませんでした。
tsvファイルからPandas DataFrameへの読み込みについては、次の記事を参考してください。
https://qiita.com/w5966qzh/items/07d73c8b1b281f8a89af
# tsvファイルからPandas DataFrameへ読み込み
train = pd.read_csv('train.tsv', delimiter='\t')
train.head()でどんなデータが入っているか確認してみます。
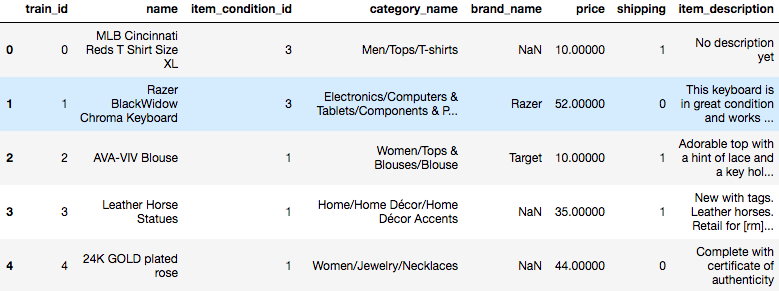
train_idは1から順にデータの個数だけidが振られている、
nameは商品名、
item_condition_idは多分悪い〜良いの5段階くらいが数値として入っている、
category_nameは商品分類が(おそらく被りあり)、
brand_nameはRazerやTargetといった名称(これも多分被りあり)、
priceは商品価格(最小10ドルから最大は1000ドルくらい?)、
shippingは1か0(配送費が出品者or落札者で0or1)、
item_descriptionは何か情報がいろいろ(空欄もあり)
といったところでしょうか。
データの個数を確認してみます。
train.shape
(1482535, 8)
およそ15万件のデータが記載されてるんですね。その割に要素は8種類(うち1つはtrain_idなのでデータとしては役にたたなさそう)
さて、データのタイプ(整数か、文字列か)なども確認してみます。
train.dtypes

train_idは1~1482535件まであるからint64で良いとして、item_condition_idやshippingはint64は多すぎ。
priceが小数まであるのは、ドルなのでセントまであるからか
チュートリアルではread.csvでdelimiterに'/t'を指定しているが、read_tableでもできる気がする
low_memoryについては、例えば1つの整数の列データの中に文字列といった他の型が紛れ込んでいないことがわかっているときはlow_memory=Falseにすることによってpandasが一旦全部のファイルを読み込んで型を推測する必要がなくなるらしい。
納得できたところで、チュートリアル通りにデータを読み込んでみる。
# データタイプを指定
types_dict_train = {'train_id':'int64', 'item_condition_id':'int8', 'price':'float64', 'shipping':'int8'}
types_dict_test = {'test_id':'int64', 'item_condition_id':'int8', 'shipping':'int8'}
# tsvファイルからPandas DataFrameへ読み込み
train = pd.read_csv('train.tsv', delimiter='\t', low_memory=True, dtype=types_dict_train)
test = pd.read_csv('test.tsv', delimiter='\t', low_memory=True, dtype=types_dict_test)
| データ型(dtype) | 型コード | 説明 |
|---|---|---|
| int8 | i1 | 符号あり8ビット整数型 |
| uint8 | u1 | 符号なし8ビット整数型 |
| float16 | f2 | 半精度浮動小数点型(符号部1ビット、指数部5ビット、仮数部10ビット |
| float32 | f4 | 単精度浮動小数点型(符号部1ビット、指数部8ビット、仮数部23ビット |
| complex64 | c8 | 複素数(実部・虚部がそれぞれfloat32 |
| bool | ? | ブール型(True or False) |
| object | 0 | Pythonオブジェクト型 |
データ統計量の確認
def display_all(df):
with pd.option_context("display.max_rows", 1000):
with pd.option_context("display.max_columns", 1000):
display(df)
# trainの基本統計量を表示
display_all(train.describe(include='all').transpose())
Pandas公式によると
with option_context('display.max_rows', 10, 'display.max_columns', 5):
で表示する行および列を指定できるそうです。(デフォルトでは5列まで)
データタイプをカテゴリ型に変換
カテゴリ型って何やねん、て思って調べました。
機械学習させる以上、文字列はそのままでは使えず数字に置き換える必要があります。
例えば、宝石は1、オフィス運搬品は2、ヴィンテージバッグは3・・・といった具合にです。
で、例えば宝石の取引がid=23, 97, 100であった場合は、これらのcategory_nameは同じ数字を割り振ってやる必要があります。
こういった場合に、同じ文字列データを同じ番号に変換するための前処理が、カテゴリ型に変換というわけです。
test_idのような被りのないデータの場合は、100個データがあったら値も100通りとなります(これをユニークな値といいます)
数字への変換は、trainとtestで同じデータは同じ数値を割り振ってやる必要があるので、次のステップでいったんtrainとtestを結合させた後で数字に変換します。
Kaggleメルカリ データ事前処理
ここのステップは、比較的丁寧に説明されているのでチュートリアルを読むとわかります。