はじめに
従来のバックアップ&リカバリソフトウェアではクライアントとサーバーインスタンスが通信しバックアップ&リカバリを行うのが一般的です。最近ではSSHベースのエージェントレス (Veritas CloudPoint) やバックアップ実行時にインストール、サービス作成、サービス起動を行う非常駐型のエージェントレス (Veeam) 、また、APIを使ったエージェントレス (NetBackup Parallel Streaming Framework) など様々な技法が登場しています。
NetBackup Universal Share
NetBackup 5240、5330、5340シリーズにはユーザーが投入するdumpを重複排除して格納する Universal Share という機能があります。対応エージェントがない製品や別のアプリケーションやユーザーが何らかのイメージを放り込みたい場合などあの会社の"/backup"のようにNFSやCIFSで放り込めばOKという拡張が行われています。この機能拡張はNetBackupアプライアンスだけで提供されており、ソフトウェア版では提供されていません。
ユーザーが実現できること
スペース効率の高いCIFS(SMB)またはNFS共有に直接データを取り込む機能を提供します。 スペース効率は取り込んだデータを既存のNetBackupベースの重複排除プールに直接保存することで実現します。 シェアをマウントするホストに NetBackup ソフトウェアをインストールする必要はありません。 POSIX準拠のファイルシステムを実行し、CIFS または NFS ネットワーク共有をマウントできるオペレーティングシステムは、ユニバーサルシェアにデータを書き込むことができます。 データが NetBackup アプライアンスに取り込まれた場合、データはメディアサーバー重複排除プールに直接書き込まれます。標準のディスクパーティションにデータを書き込み、このデータを重複排除プールに移動する仲介手順は必要ありません。
現在の制限
最初のリリースでは、ユニバーサル共有は単に汎用ディスクターゲットです。 現在、NetBackup との直接統合はありません。 データが NetBackup 重複排除プールに取り込まれたらデータは NetBackup によってカタログ化または検索できません。 共有に配置されたデータは、元のデータの有効なコピーであり、可用性の高いストレージに配置されます。ただし、現時点では、NetBackup はユニバーサル 共有内にあるデータの保持の強制、レプリケーション、または保護を実行できません。 3.2以降のユニバーサルシェアのその後の計画リリースは、これらの欠陥を排除します。(もうじき、解除されます!)
ユニバーサルシェア~その仕組み
NetBackupアプライアンスのユニバーサルシェア機能は、NetBackupアプライアンスとしてネットワーク接続ストレージ(NAS)オプションを提供することでNetBackupアプライアンスを強化します。ユニバーサルシェア内のデータはスペース効率が高く重複排除された状態で冗長性の高いストレージに配置されます。
ユニバーサルシェアに格納されているデータは、メディアサーバーの MSDP の場所に取り込まれた他のすべてのデータと自動的に重複排除されます。 一般的な MSDP ロケーションは広範なデータ型にわたってデータを格納するため、ユニバーサルシェアによって提供される重複排除の効率は非常に高くなる可能性があります。
クライアントサポート
ユニバーサル共有では幅広いクライアントとデータ型がサポートされています。 NFS または CIFS 共有をマウントできるシステムは、任意のPOSIXファイルシステム準拠データをユニバーサルシェアに送信できます。ユニバーサルシェアではNetBackup クライアントをクライアントシステムにインストールする必要はありません。
一般的なベストプラクティス
データの取り込み
ユニバーサルシェアでは、任意の種類の標準ファイルシステム ベースのデータを取り入れることができます。 ただし、ユニバーサルシェアの最も一般的で推奨されるユース ケースは、データベースまたはアプリケーションデータです。 通常、このデータはファイルサイズが 1 GB 以上で一般的に数千を超えないファイルの数です。
データリテンション
ユニバーサルシェアのデータリテンションは NetBackupでは管理されません。 シェア内のデータの削除はユニバーサルシェア内のファイルを移動または削除するか、共有構成を削除することによって手動で実行する必要があります。 データベースダンプを生成したのと同じユーザー作成スクリプトを使用して、そのデータの保持を管理するのが一般的です。
データ分類
シェア内のデータの分類は、通常、共有内にフォルダ構造を作成し、それらのフォルダに配置されたデータを記述するためにフォルダに名前を付けます。 たとえば、異なる期間のデータは、特定の日、月、またはユーザーが選択した期間にちなんで名付けられた別々のフォルダに配置できます。
ファイルサイズと容量
ユニバーサルシェアは、ファイルの数が比較的少なく、これらのファイルのサイズが 1 GB を超えるデータベースまたはワークロードを保護するように設計されています。 個々のメディアサーバーでホストされているユニバーサルシェアに取り込まれたファイルの合計数が 10,000 を超えないことをお勧めします。次期バージョンではファイル数が10,000を超える場合にも効果的に対応できるように機能拡張予定です。
重複排除スペース管理
ユニバーサルシェアを使用してデータを取り込む場合は注意が必要です。 ユニバーサルシェアを介して取り込まれたデータは、従来のバックアップ・データと同じように管理されません。 従来のバックアップではデータがカタログ化され、データの保存が自動的に適用されます。 期限切れのデータは、重複排除プールから自動的にパージされます。 ユニバーサル共有では、データは NetBackup 内にカタログ化されず自動的にパージされません。 ユニバーサル共有からデータを削除することは手動プロセスです。 ユニバーサル共有データの削除は、ユニバーサル共有を完全に削除するか、各特定の共有からデータを手動で削除することで実行できます。
ユニバーサルシェアの構成
ではユニバーサル共有構成プロセスの概要を説明します。 詳細については NetBackup アプライアンス管理者ガイドを参照してください。
ユニバーサル共有の構成はメインの NetBackup アプライアンス Web ベースの管理コンソールから実行されます。 メインコンソール画面から、[管理] > [ストレージ]を選択します。 ユニバーサルシェアのセクションを下へスクロールします。 以前に設定されたユニバーサルシェアはここに表示されます。[ユニバーサルシェア]テキストを選択してクリックし、[作成]ボタンをクリックします。 共有構成の作成ウィザードが表示されます (下記参照)。 このウィザードで説明する手順に従います。
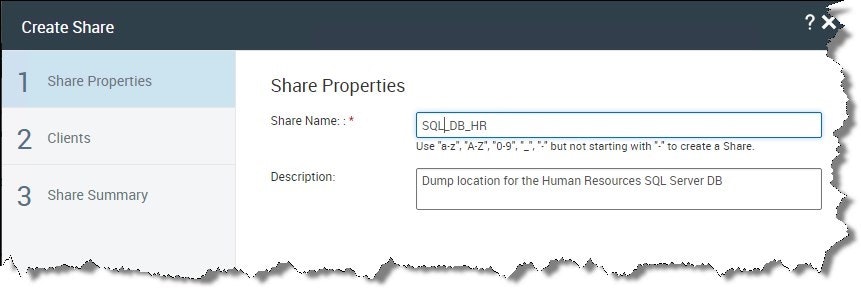
セクション 1 Share Proprieties:この共有の名前は、この特定の共有場所にダンプされるクライアントまたはアプリケーションデータに関連することをお勧めします。 共有にわかりやすい名前を使用すると共有の使用が意図されているのが明らかになります。 NetBackup ポリシーが共有内のデータを保護およびカタログ化するように構成されている場合、復元時に必要なデータの検索が簡略化されます。 たとえば、このセクション (SQL_DB_HR) で説明されている名前の共有は、人事関連のSQL Server DB のダンプ場所として使用され、それに応じて名前が付けられます。 [次へ]ボタンをクリックします。
セクション 2 Client:ここでは共有に対してトランスポート プロトコルとアクセス許可が選択されます。 NFS 共有と CIFS 共有の両方がサポートされます。 このシェアをダンプ場所として使用する場合は、必ず[読み取り/書き込み]オプションを選択してください。 [クライアントの追加]をクリックします。ハイパーリンクを使用して、このシェアをマウントするクライアントに名前を付けます。
セクション 3 共有の概要:シェアの作成に選択したオプションを確認します。 選択内容を確認したら、シェアの構成を完了できます。[共有の作成]ボタンをクリックします。これでユニバーサル共有が構成され、使用できるようになりました。
ユニバーサルシェア~データのカタログ化と保護
ユニバーサルシェアに最初に取り込まれるデータは、ユニバーサルシェアをホストしているアプライアンスのメディアサーバーにある MSDPに存在します。 ユニバーサルシェアにあるデータは MSDP に保存されますが、NetBackup カタログには参照されず、リテンションは有効になりません。 このため、ユニバーサルシェアのコンテンツはNetBackupから検索できず、従来の NetBackup バックアップ アーカイブおよび復元 (BAR) インターフェイスを使用して復元することはできません。 これらはエンハンスメントを予定していますが、このセクションでは、ユニバーサル共有でデータのポイントインタイムバックアップを作成するためのオプションについて説明します。
ユニバーサル共有でデータを保護するには単純なファイルシステムポリシーを作成できます。 他の標準ファイルシステムバックアップポリシーと同様にこのポリシーは、ユニバーサルシェアが構成されているアプライアンスに存在する標準ファイルシステムデータを保護するように設計されています。 複数のアプライアンスがユニバーサルシェアで構成されている場合、各アプライアンスはそのアプライアンスのユニバーサルシェアを保護するように設計された個別のポリシーで構成されます。
このポリシーで保護されているすべてのデータはユニバーサルシェアをホストしているメディア サーバーのホスト名を持つ NetBackup カタログで参照されることに注意してください。 次の手順ではユニバーサルシェアデータを簡単に見つけて復元できるようにNetBackup ポリシーを構成するための提案を提供します。
ユニバーサルシェアの保護ポリシーの作成
このセクションではユニバーサル共有を作成する簡単なプロセスを示し、その共有内のデータをバックアップおよびカタログ化する単純な NetBackupファイルシステムポリシーを構成します。
ここでは既にユニバーサルシェアが構成されていると仮定します。 これはNetBackup アプライアンス Web コンソールから確認できます。アプライアンスの管理画面から次のようにナビゲートします。
[管理] > [ストレージ] > [ユニバーサル共有]
保護するシェアをクリックします。 この例では、この共有の名前は "SQL_DB16" これで共有の詳細が表示されます。 この例では、下記の内容が表示されます。
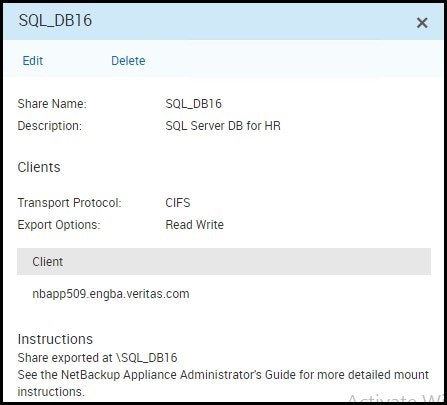
ユニバーサルシェアが作成され、その名前がわかっていることを確認しました。 この情報を使用してシェア内のデータを保持およびカタログする NetBackup ポリシーを作成できます。このポリシーの作成は標準の Linux ファイルシステムバックアップポリシーの作成とまったく同じです。構成手順の概要は次のとおりです。
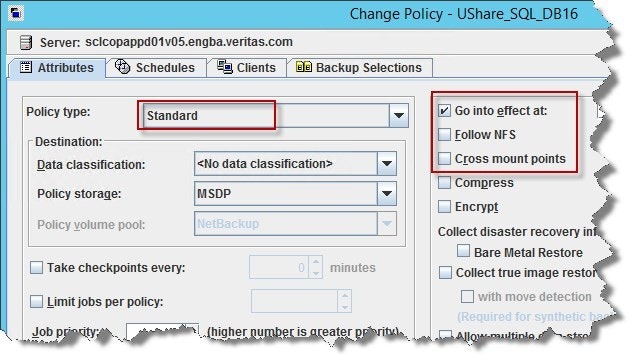
1)属性[Attribute]:を入力してポリシーを作成
保護されるデータはユニバーサル共有をホストするLinuxベースの NetBackup アプライアンスメディアサーバーにローカルであるため、スタンダードポリシーが使用されます。保護されるデータはメディアサーバーに対してローカルなため、「NFS をフォローする」または「クロスマウントポイント」オプションを選択する必要はありません。
2)スケジュール[Schedule]:このポリシーは任意のバックアップ ウィンドウに対してスケジュールできますが、スケジュールがユニバーサル 共有にデータをアクティブに配置している操作と一致しないことをお勧めします。 FULL スケジュールと INCR スケジュールの両方がサポートされています。
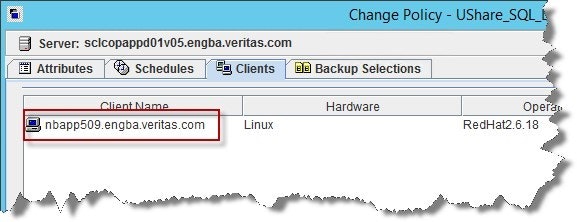
3)クライアント[Client]:この構成では、「クライアント」という用語は、NetBackupメディアサーバー自体を指します。 データはメディアサーバーのハードマウントを介してバックアップされます。
4)バックアップの選択[Backup Selection]:「バックアップ選択リスト」にリストされているマウントポイントはすべて、以下に示すように/mnt/vpfs マウント ポイントに基づきます。VpFS ベースのデータのディレクトリ構造は、次のように定義されます。
/mnt/vpfs/<最初の4 文字の共有名>/<フルネームの共有>
このリストに配置されるすべてのバックアップの選択は、この構造に基づいているか、バックアップされるデータが特定のユニバーサル共有に関連付けられていない必要があります。
次の図では3つの個別のユニバーサルシェアが単一のNetBackup ポリシーで保護されている例を示しています。 必要に応じて3つの個別のNetBackup ポリシー (共有ごとに1つのポリシー) を必要に応じて構成できます。 個別のポリシーを使用すると、共有ごとに異なる保護要件 (保存期間、SLP ターゲットなど) を有効にできます。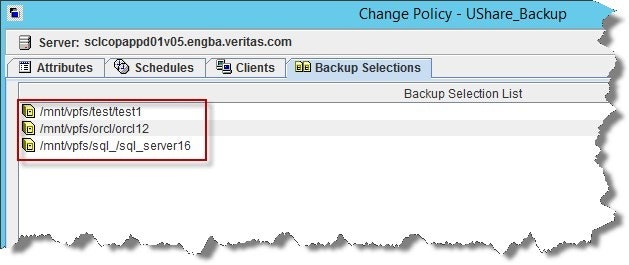
その他のポリシー構成に関する推奨事項
推奨される共有とポリシーの命名規則:NetBackupカタログ内のすべてのデータはユニバーサルシェアをホストするメディアサーバーのホスト名に参照されるため、保護されたユニバーサル共有データを簡単に検出して復元できるように保護されたユニバーサルシェアのデータを正しく参照する方法がいくつかあります。 これらのメソッドには次のものがあります。
ユニバーサル共有に分り易い名前を付ける
共有名を分り易く付けることにより、バックアップされたデータを検索して検出する機能が強化されます。 たとえば、共有名は、ユニバーサル 共有をマウントするシステムのホスト名に基づいて指定できます。 共有の名前を拡張して、保護されるデータの名前を含めることができます。 たとえばユニバーサル共有には次の名前が付けられています。
hrprod16_orcldb12
この例では、ユニバーサル共有をマウントするシステムのホスト名は "hrprod16" で共有内のデータは "orcldb12" という名前の Oracle インスタンスに関連付けられています。 共有にわかりやすい名前を使用すると特定の共有に合わせて正しいデータを検索するプロセスが簡略化されます。
NetBackup ポリシーの名前
分り易い名前の別の例としては特定のホストにちなんで名付けられた NetBackup ポリシーの作成や、ユニバーサルシェアによってそのホスト上で保護されているデータの作成が含まれます。 前と同様、ポリシーの分り易い名前付けは、復元が必要な場合にデータ検出プロセスを簡素化します。
おわりに
ちょっと長かったですが、いかがでしたでしょうか。例えば NetBackup のプリスクリプトと組み合わせて使用することで使い方の幅が広がりますね!例えばインメモリDBのRedisのダンプを作って放り込むなど、、色々とありそうです!次回はFAQをお送りします!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。
ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。