
 まずはじめに
まずはじめに
目的
この記事は、これからgraphqlをはじめる、もしくはgraphql始めたてにおいて知っておくと良さそうな情報(と、そこへのindex)をまとめることを目的に書いています。
想定読者は「これからgraphql始めたい人、始めたばかりの人」です。
その背景として、graphqlベースのAPIがもっと増やすべく、その導入/学習コストがそこまでは高くないことを説明したい、ということがあります。
------8<-------![]() 以下宣伝
以下宣伝 ![]() ------8<-------
------8<-------
なお、 Issus(イシューズ) という個人向けマークダウンノートサービスの中でGraphqlを使う中で得た情報をまとめています。
------8<-------![]() 以上宣伝
以上宣伝 ![]() ------8<-------
------8<-------
概要
Graphqlのコンセプト、特徴、強み、という概念としての話から、
リクエスト/レスポンスの流れ、クエリ、Schema、resolve、型、test、ファイルの取扱、エラー処理、という実装の具体的な内容まで
一通り紹介します。
内容として直すべき点、よりよい情報などがあればぜひ編集リクエストをお願いします ![]()
NOTICE!
- graphql-ruby(かつRails)をベースに話すため他Graphqlライブラリでは当てはまらない話もあるかもしれません
- 途中図に起こすのを諦めて手書きしたメモがあります

- 長いぞ!!!
 Graphqlはなにに役に立つのか?
Graphqlはなにに役に立つのか?
これについては こんぴゅさんがわかりやすくまとめられています。
[GraphQLはRESTの置き換えではない|こんぴゅ|note] (https://note.mu/konpyu/n/nc4fd122644a1)
ここで書かれている、
- APIリクエストを束ねて効率化 = 各所で必要十分なレスポンスを要求できる
- スキーマファースト開発
- マイクロサービスのAPIゲートウェイ
- 裏側のデータソースを複数持てたり、他のRESTapiをcallしたり
に加え、
- request parameters / responseに型をつけられる
- RESTfulAPIの面倒なエンドポイント設計が不要になる
- クライアントがサーバーの開発を待たなくていい
といったメリットもあると思います。
また動画では Learn GraphQL Fundamentals with Fullstack Tutorial が非常にわかりやすくコンセプトをまとめています。
At its core, GraphQL enables declarative data fetching where a client can specify exactly what data it needs from an API. Instead of multiple endpoints that return fixed data structures, a GraphQL server only exposes a single endpoint and responds with precisely the data a client asked for.
ここにあるとおり、apiコールをする箇所がほしいレスポンスを各自定義して、一発のAPIコールでその通りにレスポンスを受け取れるようにするということを強く志向しています。
背景としてモバイルアプリの隆盛によるAPIの多様化、かつほしいレスポンスが頻繁に変わるようになったため、その都度サーバーで対応が必要となると開発のスピードが出せなくなってきたことが挙げられています。
他には GraphQLは何に向いているか - k0kubun's blog も、RESTfulAPIとの冷静な比較をまとめられていて、参考になります。
 setup!
setup!
※ 実際に開発している方はskipしてください
Railsプロジェクトに導入する前提です。
(routesなど登場しますが、sinatraなどの場合は適宜読み替えてください)
gem install
まずはgraphqlと、そのテストクライアント画面を用意してくれるgraphiql-railsを導入します。
gem 'graphql'
group :development do
gem 'graphiql-rails' # graphqlのテスト画面です。後述
end
bundle install
rails generate graphql:install
routesに追記
続いてgraphqlを実行するパスと、テストクライアントのパスを用意します。
if Rails.env.development?
mount GraphiQL::Rails::Engine, at: "/graphiql", graphql_path: "/api/v1/graphql"
end
# 適宜好きなpathに設定してください. 今回のケースでは /api/v1/graphqlをエンドポイントにしています
namespace :api, { format: 'json' } do
namespace :v1 do
post "/graphql", to: "graphql#execute"
end
end
これで、
-
POST /api/v1/graphqlでgraphqlを実行できるように、 -
GET /graphiqlにアクセスすると、grapqhlのテストクライアントにアクセスできるように
なりました。
テストクライアントの様子。

なおEventをid指定で1つ取得するこのクエリをしばらく使い続けます。
意味は「Event.find(id)を取得し、そのidとsubjectを取得する」です。
 Graphqlはどう動くのか
Graphqlはどう動くのか
基本のおさらいなのですでにgraphqlで実装している人はスキップしてください
通信編
 (endpointが `/graphql`になっていますが、適宜環境に合わせて読み替えてください。今回のroutes.rbだと`/api/v1/graphql`)
(endpointが `/graphql`になっていますが、適宜環境に合わせて読み替えてください。今回のroutes.rbだと`/api/v1/graphql`)
大まかな流れは
- クライアントでquery(とvariables)を組み立て、唯一のエンドポイントに対してPOSTでリクエストを投げる
- queryとvariablesの組み立てがクライアント側の主な仕事になります
- データ取得のリクエストであってもPOSTを使います
- それを受け取ったサーバーサイドはquery(とvariables)を解釈してレスポンスを生成
- 予めどのフィールドに対してどういった値を返すかについてschemaとして定めている
- このschemaの実装がサーバー側の主な仕事になります。
です。
Railsにおける実際のログとレスポンスは以下の通り
Started POST "/api/v1/graphql" for ::1 at 2018-07-01 09:22:51 +0900
Processing by Api::V1::GraphqlController#execute as JSON
Parameters:
{
"query"=>"query Event($id:ID = \"\") {\n event {\n id\n subject\n }\n}", # 特殊なGraphql構文をstringで送信
"variables"=>{"id"=>5}, # rocket hashになってる
"operationName"=>"Event", # operationNameはqueryの直後に付けている文字列で、サーバー側でロギングに用いる。省略可能だがあったほうがいい
“graphql"=>{
"query"=>"query Event($id:ID = \"\") {\n event {\n id\n subject\n }\n}",
"variables"=>{"id"=>5},
“operationName"=>"Event"
}
}

ではクライアント側からクライアント・サーバーそれぞれの処理を見ていきます。
クライアント編
クライアント側の仕事は
- クエリを組み立て、エンドポイントにリクエストを送る
- レスポンスの中身をみて、エラーがあればエラーハンドリングを行う
- 受け取ったレスポンスのデータを元に描画なり何なりを行う(ここでは省略)
の3つです。まずは1つ目から見ていきます。
クエリを組み立て、エンドポイントにリクエストを送る
Graphqlに送るパラメーターは2つあります。一つがquery、もう一つがqueryに埋め込む値を示すvariablesです。
queryはjsonに見た目にていますが、独自の構文となっていて、大まかに構成を覚える必要があります。
以下のqueryとvariablesを元に構成要素をみてみます。
query Event ($id:ID = 1) {
event {
id
subject
}
}
{ "id": 5 }

こうして組み立てたquery, variablesは、常にPOSTで唯一のエンドポイントにリクエストとして送ります。
これがgraphqlの特徴でもあり、これによりendpointの設計などを考えずに、client側がその場その場でほしいレスポンスを1発のAPIコールで取得できるようになりました。
レスポンスの中身をみて、エラーがあればエラーハンドリングを行う
Graphqlはリクエストに誤りがあったとしても常にstatus codeを200で返します。
(∵ Graphqlは複数クエリを同時に投げることが可能であり、その際にどれか一つだけ失敗したケースをステータスコードとして表現できないため。)
そのかわり、エラーがあった場合はレスポンスにerrorsを含めて返すため、その有無をみてエラーハンドリングを行う必要があります。
jsの擬似コードで処理を追うとこんなイメージです。
import { API } from 'api' // 何らかのhttpリクエストライブラリ
const response = await API.post('/api/v1/graphql', { query: query, variables: variables })
if (response.errors) {
// do error handling
console.log(response.errors)
return
}
const event = response.data.event
// do something with response
ただし、実際には各クライアントに合わせたgraphqlクライアントライブラリを使うことが多いはずです。
クライアントライブラリは、独自構文のqueryとjsonのvariablesを組み立てることをサポートし、レスポンスを元にエラーハンドリングまでしてくれます。
クライアントライブラリは、例えばJavaScriptではFacebookの開発するRelay, ほぼデファクトになりつつあるApolloなどがメジャーです 公式が紹介しているjsのclientライブラリ
iOS, Android向けのクライアントライブラリもあります。
jsにおける擬似コードを示します
$ npm install apollo-boost graphql-tag graphql --save
import ApolloClient = from 'apollo-boost' // 便利なデフォルト設定を加えたapollo client
const client = new ApolloClient({
url: 'api/v1/graphql'
})
import gql from 'graphql-tag'
client.query({
query: gql`
query Event($id:ID!) {
event(id: $id) {
id
subject
}
}
`,
variables: {
id: 1
}
})
.then((response) => {
const event = response.data.event
// do something...
// responseにerrorsがあればthrowしてくれる
}).catch((error) => {
// do something
})
また、jsの場合、各フレームワークに合わせたライブラリがあり、それを合わせて使うことが推奨されています。
例えばVue.jsであれば https://github.com/Akryum/vue-apollo を利用できます。
client側はクライアントによってまた細かく実装が変わるので、また別の記事でVue.jsに関する内容をあげます。
まとめ
クライアント側の仕事は以下の通りです
-
クエリを組み立て、エンドポイントにリクエストを送る
- queryとvariablesを組み立てて
- 単一のエンドポイントにPOSTする
-
レスポンスの中身をみて、エラーがあればエラーハンドリングを行う
- 常に200で返ってくる。エラーがある場合はerrorsがレスポンスにあるのでそれの有無でハンドリングする
- クライントライブラリを用いればquery・variablesの組み立て、エラーハンドリングまで担ってくれる
- あとは受け取ったレスポンスのデータを元に描画なり何なりを行う
サーバー編
サーバー側の仕事は
- 受け取ったquery, variablesを解釈し
- responseを返す
です。
responseを返す部分はシンプルです。
rails generate graphql:install で自動生成されるgraphql_controllerほぼそのままで処理できます
class Api::V1::GraphqlController < Api::V1::BaseController
#
# 省略
#
# POST /api/v1/graphql
def execute
# ensure_hashの実装はこの真下に自動生成されていますが手を入れることは少ないので省略
variables = ensure_hash(params[:variables])
query = params[:query]
# OperationNameはロギングで使う
operation_name = params[:operationName]
# 後述. なくてもいい
context = { current_user: current_user }
# MySchemaは、後述するGraphqlの実体となるclassです。
# executeするとquery, variablesをもとにresponseとなるhashを返します
result = MySchema.execute(
query,
variables: variables,
context: context,
operation_name: operation_name
)
render json: result # hashが返るので、あとは response json: result するだけ。
end
#
# 省略
#
end
受け取ったquery, variablesの解釈を行うのがGraphqlのSchemaです。
サーバーエンジニアの仕事は**「このFieldがきたらこのデータを返す」をSchemaに定義**することです。
この箇所が 2018/05/18 にreleaseされたv1.8.0から大きく変わり、class-basedになりました。
class-basedな実装の詳細は 公式のdocs にかかれています。
とはいえ、webで見つかる記事がその前の記法であることが多いので、この記事ではclass-basedな書き方で書いていきます。
ようやく本記事の本編です。
 Schemaの実装
Schemaの実装
graphqlでできるリクエスト三種類
graphqlにはリクエストのタイプが3種類存在します
-
query
- 参照系 Read
-
mutation
- 更新系 Create Update Delete
- subscription
- websocketのようにクライアントがサーバーをオブザーブする仕組みを提供します
- ちょっとまだ使ったことがないので省略!
-
Subscriptions allow GraphQL clients to observe specific events and receive updates from the server when those events occur. This supports live updates, such as websocket pushes. Subscriptions introduce several new concepts:
まずはGraphqlの基本を理解するためにもQueryをみていきます。
 Query編
Query編
graphql-rubyのサーバーサイド全体像
まずはgraphql-rubyでの処理の流れを見ていきます。
- GraphqlController#execute
- MySchema.execute
- (executeの中でみるものとして) Types::QueryTypeの各field
- fieldの値の型を指定
- fieldの値に対応するものをどう取得するかを、resolve処理として記述

「このFieldがきたらこのデータを返す」をSchemaに定義する、とはこの3番目を実装することになります。
fieldの基本的な実装
まずはシンプルな例を見ていきます
ここ に基本的な実装が記載されていますが、class-basedではもう使えない記述もあります
豊富なoptionを渡せるため、正確なoptionは gems/graphql-1.8.1/lib/graphql/schema/field.rb を見たほうが間違いなさそうです。
fieldの実装は
- field(name, type, description, null:) を宣言する
- fieldをresolveさせる
- resolve = fieldが返す値を見つける方法を定める
の2つの手順をふみます。
class Types::QueryType < GraphQL::Schema::Object
# 基本は field(name, type, description, null:)
field :ping, String, '疎通確認', null: false
# Types::QueryTypeではfield名と同名のメソッドを定義し(便宜上これをresolveメソッドと呼びます)、その返り値をfieldが返す値として用いる
# ここではpingのfieldにたいして、'pong'という文字列を返すpingメソッドを定義し、
# これをresolveメソッドとしている
def ping
'pong'
end
end
なお、resolveの方法は複数あり、後で述べます。
typeに指定できる型は**デフォルトで存在する型(String, Int, Float, Boolean, ID(int or stringで整数を指定))**に加え、
たとえばモデルに合わせたようなオリジナルの型を定義できます。
schemaを吐き出す
この段階でgraphqlを叩けますが、そのまえにgraphqlはschemaから自動でapi schemaを吐き出してくれます。先にはきだしておきましょう
$ rails graphql:schema:dump
Schema IDL dumped into ./schema.graphql
Schema JSON dumped into ./schema.json
この状態でテストクライアントにアクセスします
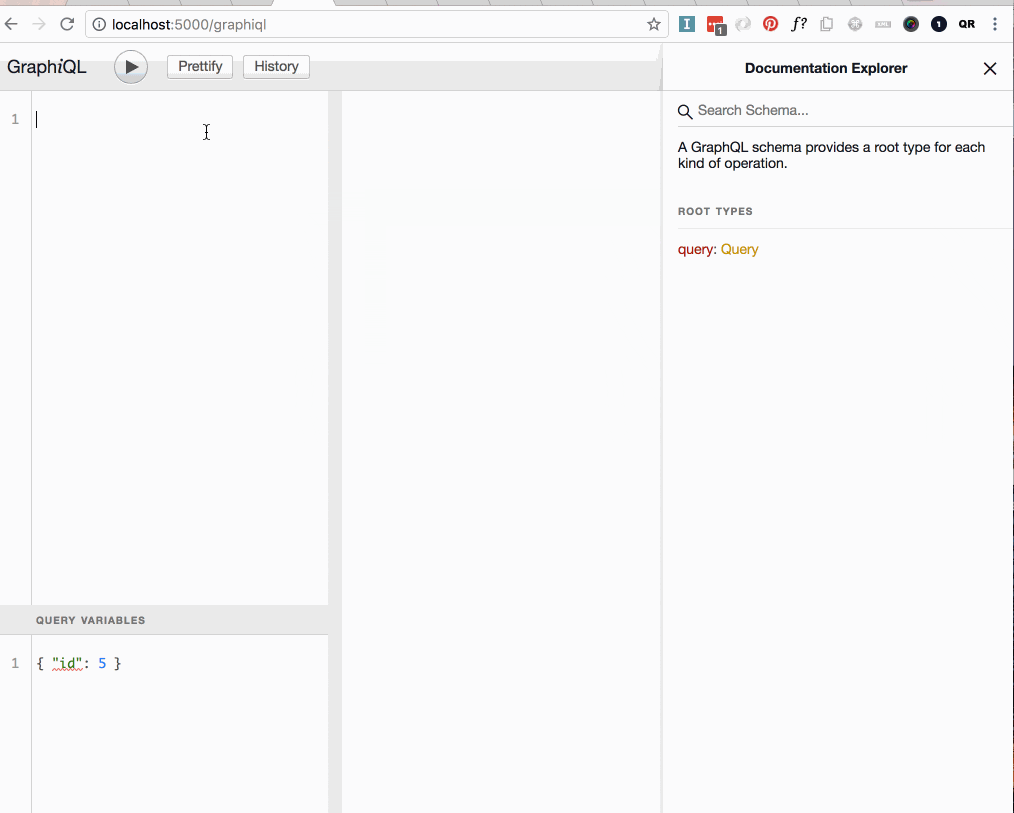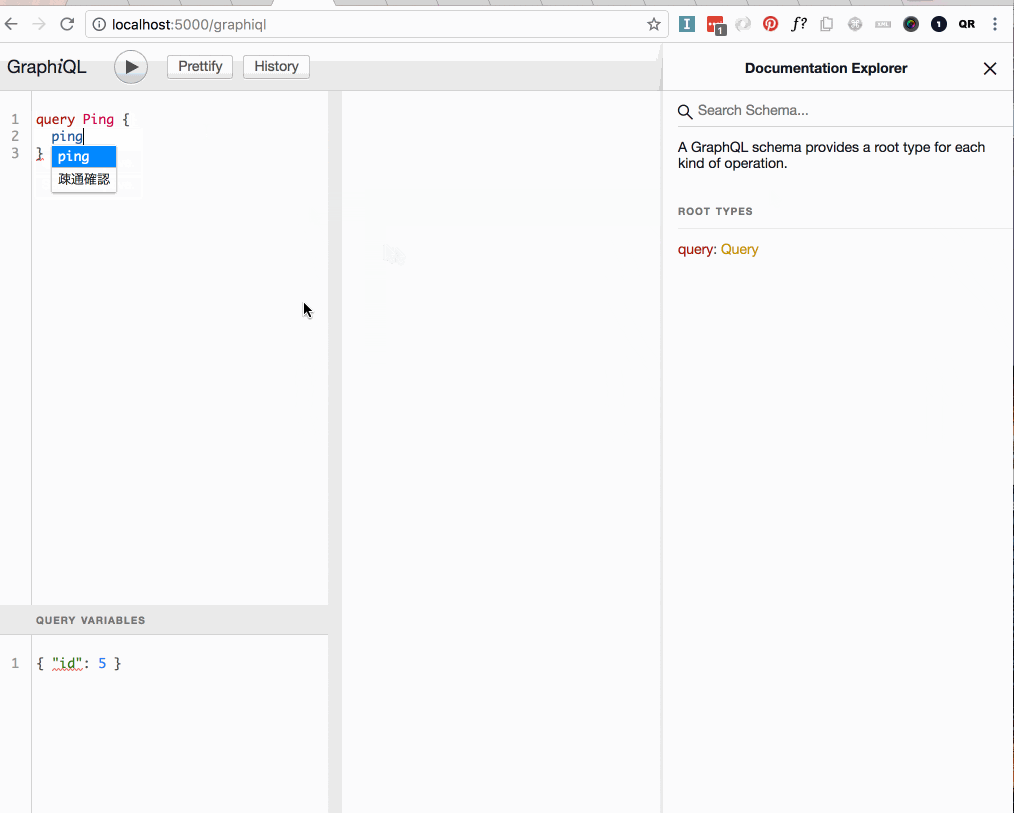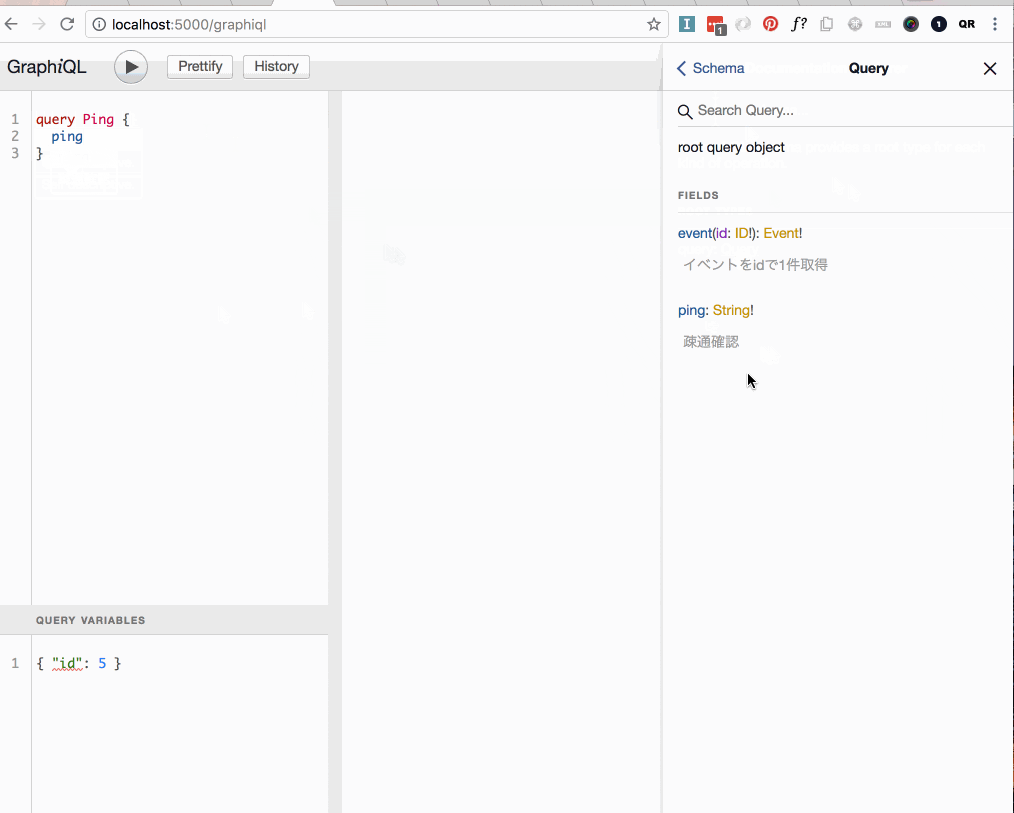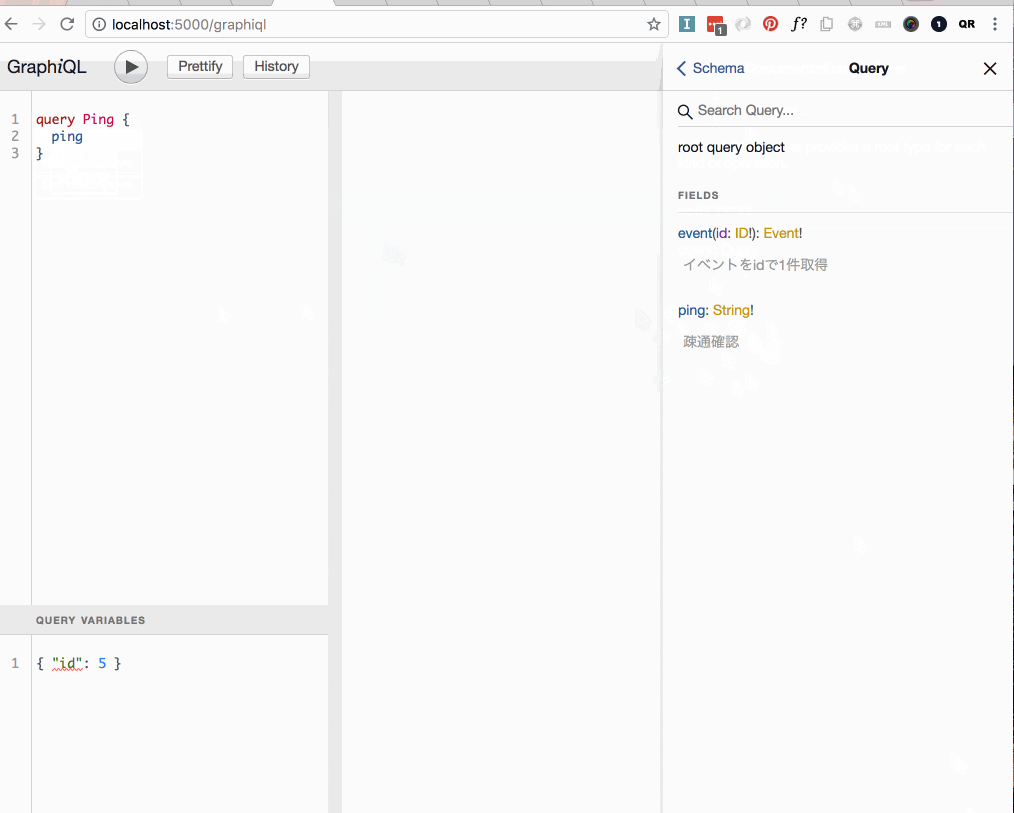
rootのQueryTypeにpingというString型のfieldが生えていることを確認できました。またschemaを吐き出したことで補完やdocsを表示してくれています。
(eventは一旦無視してください)
オリジナルの型を用いるfieldの実装
以下の例では、event fieldを用いた際にEventType型のレスポンスを返します。
またここではfield引数を用いて、渡ってきたidをもとにひいたEventインスタンスを:event fieldに当てはめる(resolve)しています
class Types::QueryType < GraphQL::Schema::Object
#
# 単体のリソース取得sample
# Types::EventType がオリジナルの型
#
field :event, Types::EventType, null: true do
description 'イベントをidで1件取得' # fieldのdescription引数はブロック内で定義してもOK
#
# 基本 argument(arg_name, arg_type, description, required:)
#
argument :id, ID, 'イベントのID', required: true
end
#
# argumentがあるとき、resolveメソッドは必須キーワード引数としてそれを受け取れる
#
def event(id:)
Event.find(id)
end
end
argumentのdocsは公式の説明もありますが、
gems/graphql-1.8.1/lib/graphql/schema/argument.rbを見るのもおすすめです。
型定義
では続いて独自の型であるEventTypeを実装します。
EventTypeはresolveメソッドでEventモデルのinstanceを返しているので、
Eventモデルのattributesをfieldとして持たせたいところです。
# eventモデル
class CreateEvents < ActiveRecord::Migration[5.2]
def change
create_table :events do |t|
t.references :user, foreign_key: true
t.string :subject, null: false
t.text :body
t.timestamps
end
end
end
class Types::EventType < GraphQL::Schema::Object
# [1] resolveのinference(推論)と、resolveのバリエーション
field :id, ID, null: false
field :subject, String, null: false
field :body, String, null: false
# [2] resolveメソッド内で利用できるhelperメソッド: object, context
field :bodyHtml, String, null: false
# snake_caseであることに注意してください。
# resolveメソッド名を `camelize(:lowder)`した値がfield名のresolveに用いられます
def body_html
object.decorate.body_html
end
# [3] 型の種類にはいくつかある
field :createdAt, ScalarTypes::DateTime, null: false
end
3つのポイントを見ていきます。
[1] resolveのinference(推論)と、resolveのバリエーション
fieldには常にresolve関数が必要というわけではなく、推論してくれる場合があります。
その条件は、
「今扱っている"object"にfield名をメッセージとして送れるのであれば(つまりそのfield名と同名のattribute, methodを持つのであれば)その返り値を利用する」
です。
今扱っているobjectとは、組み立てたクエリの**「一つ上の階層が指す値**のことです。
query Event {
{
event { # eventからみたobjectはrootなのでnil。なおMySchema.executeにoptionを渡すとrootのobjectを指定できる
id
subject # id, subjectからみたobjectはeventに対してresolveした値のこと。
}
}
}
例えば今のケースだと、field :eventでresolveしたEvent.find(id)になります。
Eventモデルはid, subject, bodyをattributeとして持つので、EventTypeのid, subject, bodyにおいては特にresolveする必要がありません
モデルにないfieldを許す場合には
- bodyHtmlのようにresolveメソッドをその場に書く
- fieldのキーワード引数として
method:を用いる- field名と異なるメソッドを定義した際にそれを適用させる. あまり使わないかも
- objectにたいしてhashに対するkeyのようにアクセスできれば
hash_key:を用いる- 例えば
hash_key: :bodyするとevent.bodyではなく、event[:body]で値を取得する
- 例えば
- resolverクラスを用いる
- これを使うのは特定の用途に限定したほうが良いと公式docsにあります
こともできます。
基本はrootではresolveメソッドを書く、Objectタイプではmodelに対応するメソッド、アトリビュートを書く、の二択だと思われます。
(あとはobjectをdecoratorインスタンスにしてdecoratorにfieldに対応するメソッドを書くとmodelにview用のロジックが入らず良いかもしれません)
rootでのobject指定は、必要であればMySchema.executeにroot_valueというoptionを渡すことで可能です
current_team = current_user.team
result = MySchema.execute(query, { root_value: current_team })
executeの他のoptionは ここ で確認できます。
[2] resolveメソッド内で利用できるhelper: object, context
resolveメソッドを書く時、その中ではobjectとcontextという名前のhelperメソッドを利用できます。
objectは[1]で説明したとおり、組み立てたクエリの「一つ上の階層が指す値」のことです。(rootの場合はexecuteでroot_valueを指定しない限りnil)
contextは、GraphqlController#executeでexecuteに渡したcontextのことです。
ここにcurrent_userなど、アプリケーション全体で用いる情報を詰めてgraphql内に渡す、というのが想定されている使い方です。
例えば取得したobjectのアクセス権限チェックなどを行います
def event(id:)
ev = Event.find(id)
raise Forbidden, 'このイベントにはアクセスできません' unless context[:current_user].can?(:read, ev)
ev
rescue Forbidden => e
raise GraphQL::ExecutionError, e.message # 後述
end
[3] 型の種類にはいくつかある
ここで実装したEventTypeはObjectという種類の型になります。
ほかにもGraphQLでは
- Scalar 例えば日付など、primitiveなデータ型を定義する
- Enum enumを定義
- Input 入力値を型にして再利用
- Interfaces 文字通り
- Unions 文字通り
- Non-Null !の取扱
など、知っておくと便利な型のタイプや型の記法がいくつかありますが、必要に応じて都度試してみると良いです。
公式docsはこちら
ここではScalarの実装だけサンプルとして挙げておきます
class ScalarTypes::DateTime < GraphQL::Schema::Scalar
description '日付型'
def self.coerce_input(value, _context)
Time.zone.parse(value)
end
def self.coerce_result(value, _context)
I18n.l(value, format: :to_date)
end
end
これでEventTypeに書いたように、 field :createdAt, ScalarTypes::DateTime, null: false が使えるようになりました
エラー処理
Graphqlではエラーが起きた際にはresponseのトップレベルにerrorsというキーを含めてエラー内容を返します。
が、Graphqlが把握しないエラーをrescueできなかった場合、内容に応じたエラーがstatus 400系, 500系で返されます。
graphqlのクライアント側ではこれらのステータスで返ってくることを想定しないため、rescue処理を必ず行う必要があります。
そのため、
- Graphqlが拾えるエラーにする
- Graphqlが拾えないエラーがでても必ずrescueする仕組みをもうける
の二点を行います
[1] Graphqlが拾えるエラーにする
先程のエラー処理をもう一度見ます。
def event(id:)
ev = Event.find(id)
raise Forbidden, 'このイベントにはアクセスできません' unless context[:current_user].can?(:read, ev)
ev
rescue Forbidden => e
raise GraphQL::ExecutionError, e.message
end
ここで使われている、Graphql::ExecutionError を用いることで、発生したエラーをerrorsキーにおさめてstatus 200で返すことができます。
またこのエラーに対して渡してエラーメッセージはerrorsのmessageに格納されます。
以下のように Graphql::ExecutionError を継承したエラーを用いるのがよりエラー情報がわかりやすく適切です
class GraphQL::Forbidden < GraphQL::ExecutionError
def initialize
super('このイベントにはアクセスできません')
end
#
# 以下のようにraiseすることで、errorsキーに{ code: 'SOME_ERROR_CODE' }を追加し、クライアント側でエラー種別を判別しやすくできます
# raise GraphQL::ExecutionError.new(message, { extensions: { code: 'SOME_ERROR_CODE' } })
#
# to_hをoverrideすることで、このextensionsを常に返すようにできます。
#
def to_h
super.merge({ "extensions" => {"code" => Graphql::"FORBIDDEN"} })
end
end
これで以下のように書き換えられます
def event(id:)
ev = Event.find(id)
raise GraphQL::Forbidden unless context[:current_user].can?(:read, ev)
ev
end
[2] Graphqlが拾えないエラーがでても必ずrescueする仕組みをもうける
このようにエラーがでうる箇所ではGraphql::ExecutionError、もしくはそのサブクラスを用いることでクライアントに正しくエラー情報を渡すことができます
が、全ての箇所でエラーが起きる箇所を把握することは難しく、セーフティネットとなる箇所が必要です。
その実装はMySchemaで行えます。
class GraphQL::BadRequest < GraphQL::ExecutionError; end
class GraphQL::NotFound < GraphQL::ExecutionError; end
class MySchema < GraphQL::Schema
#
# 起きたエラーを全て拾う
#
rescue_from(Exception) do |error|
case error
when ActiveRecord::RecordInvalid
GraphQL::BadRequest.new 'リクエストが正しくありません'
when ActiveRecord::RecordNotFound
GraphQL::NotFound.new '見つかりません'
else
GraphQL::ExecutionError.new '原因不明のエラーが発生しました'
end
end
query(Types::QueryType)
mutation(Types::MutationType)
end
エラーに関してはこちらに記述がありますが、
あまり詳しくは書いてないので、gems/graphql-1.8.1/lib/graphql/schema.rb を読むことになります
複数リソースの取得・ページネーション
Eventを1ページあたりN個取得するようなページネーションを提供したい時も、Graphqlでは簡単に実装できます.
むしろ予めカーソルベースのページネーション実装が組み込まれており、コストをかけずにほぼクエリだけで実現することができます。
公式docs に説明があります。
大まかにやることとして、
- サーバー側でconnectionを使う
- クライアント側でconnectionに合わせたクエリを立てる/connectionに合わせてレスポンスを処理する
です。
サーバー側
ページネーションをもつfieldの定義は至って簡単です
# 型の指定として、EventTypeを複数返す型として、Types::EventType.connection_typeを指定します
# NOTE! class-based api以前はfieldの代わりにconnectionを用いましたがもう使いません。
field :events, Types::EventType.connection_type, null: false do
description 'イベント一覧をpaginationで取得します'
argument :query, String, required: false # イベントを検索する文字列
end
def events(query: nil)
Event.search({
subject_or_body_cont: query
}).result.order(created_at: :desc)
end
これだけでカーソルベースのページネーションが手に入ります
クライアント側
まずはクエリを組み立てます。
query Events(
$lastEndCursor: String = "",
$offset: Int = 0,
$query: String = ""
) {
# first, afterがgraphqlによって与えられるfield引数です
# first 該当の範囲で頭から何件取得するか
# after 指定したcursor以後を取得対象とする
# (queryは独自に追加したfield引数。あれば、それを元にsubject, bodyを検索します)
events(first: 5, after: $lastEndCursor, query: $query) {
# connectionが提供するページネーション情報
pageInfo {
hasPreviousPage
hasNextPage
endCursor
startCursor
}
# connectionはアイテムのリストをedgesでラップする
edges {
cursor # 現在位置を示す。afterにわたす
node { # 一つ一つのobjectをnodeとして示す
id
subject
body
}
}
}
}
このクエリで返却されるjsonです。
{
"data": {
"events": {
"pageInfo": {
"hasNextPage": true,
"hasPreviousPage": false,
"startCursor": "Mw==",
"endCursor": "Nw=="
},
"edges": [
{
"cursor": "Mw==",
"node": {
"id": "12",
"subject": "test"
}
},
{
"cursor": "NA==",
"node": {
"id": "11",
"subject": "asdfasdf"
}
},
{
"cursor": "NQ==",
"node": {
"id": "10",
"subject": "asdfadsf"
}
},
{
"cursor": "Ng==",
"node": {
"id": "9",
"subject": "asdfasdf"
}
},
{
"cursor": "Nw==",
"node": {
"id": "8",
"subject": "ほげ"
}
}
]
}
}
}
レスポンスをみて分かる通り、edges, nodeというキーが挟まれています。
ここからほしい情報を抽出する処理をクライアント側では行う必要があり、その際にはedges, nodeなどのgraphqlに固有のコードがクライアントに現れます。
graphqlとやり取りをする層を設けるか、潔くgraphqlをコードベース全体で受け入れるかを判断してください。
なおこんな感じのレスポンス取り回しになるはず(擬似コード)
const response = await API.post('/graphql', query, variables)
// edgesからevent(node)を取り出す必要がある
// この処理がAPIコールする各所に散らばるのはちょっと嫌。
this.store.events = response.data.events.edges.map(item => item.node)
 Mutation
Mutation
Mutationも実装の流れはQueryとほぼ同じです。
サーバー側
class MySchema < GraphQL::Schema
query(Types::QueryType)
mutation(Types::MutationType) # <= ADD
end
# Mutationのrootです. 継承するのはGraphQL::Schema::Objectなので、通常のObjectタイプの型ですね
class Types::MutationType < GraphQL::Schema::Object
# fieldのmutationキーワード引数にmutation処理を渡します
field :updateEvent, mutation: Mutations::UpdateEvent
end
ココまでの実装はQueryとほとんど代わりません。
実際のmutation処理ですが、これもqueryと大きくは変わらず、唯一異なるのがresolveというメソッドを定義し、そこで処理を書く点です。
class Mutations::UpdateEvent < GraphQL::Schema::Mutation
null false
argument :id, ID, required: true
argument :subject, String, required: false
argument :body, String, required: false
# 公式のサンプルでは、mutationのresponseは { object, errors } を返していました
# トップレベルのerror
field :event, Types::EventType, null: false
field :errors, [String], null: false
# 引数にargumentが入ってくるのはqueryと同じ挙動
def resolve(id:, subject: nil, body: nil)
event = Event.find(id)
event.subject = subject if subject
event.body = body if body
if event.save
{ event: event, errors: [] }
else
{
event: event,
errors: event.errors.full_messages
}
end
end
# こういう書き方でもいいかも 後述
# def resolve(id:, subject: nil, body: nil)
# event = Event.find(id)
# event.subject = subject if subject
# event.body = body if body
# event.valid? && event.save!
# rescue ActiveRecord::InvalidRecord => e
# # topレベルにエラーの種類、エラーの追加フィールドにバリデーションエラーを含めて返す
# raise GraphQL:ExecutionError.new('invalid parameter', extensions: { additional_messages: event.errors.full_messages })
# end
end
クライアント側
クライアント側は変わらず、queryとvariablesを組み立てて送るだけです。
なお、Mutation処理であっても、送るパラメーター名はクエリです。
変わってくるところとして、update, saveに失敗した場合、エラーの内容がトップレベルではない箇所に入ってくることを意識する必要があります
mutation UpdateEvent($id:ID!, $subject:String = null, $body: String = null) {
updateEvent(id: $id, subject: $subject, body: $body) {
event {
id
subject
body
}
errors
}
}
variables
{ "id": 5, "subject": "11111111" }
レスポンス
{
"data": {
"updateEvent": {
"event": {
"id": "5",
"subject": "11111111",
"body": "asfasdf"
},
"errors": [] // エラーがあった場合ここに入ってくる
}
}
}
save ではなく、 save! をもちいてエラーを起こし、errorsのextensionsで event.errors.full_messages を返す方法もありかなとおもい調査中です
 懸念
懸念
此処から先はGraphqlの懸念点をざっくりとあげて一つ一つ見ていきます.
- テスト
- N+1問題
- ファイルアップロード
テスト
requestテストのようなE2Eテストを行わず、よりlowerなテストとするようにと 公式docs にかかれています。
The easiest way to test behavior of a GraphQL schema is to extract behavior into separate objects and test those objects in isolation. For Rails, you don’t test your models by running controller tests, right? Similarly, you can test “lower-level” parts of the system on their own without running end-to-end tests.
- schema内に(たとえばresolveメソッドなど)メソッドをあまり書かずにモデルに寄せること
- (そうしておけば)schemaは殆どの場合modelのmethod, attributeを取得するため、そのテストをちゃんと書くこと
とのことです。
E2Eテストをどうしてもする場合は、graphql_controllerが薄いので、MySchema.executeをテストします。
describe '#execute' do
subject {
MySchema.execute(
query,
{
context: context,
variables: variables
}
)
}
let(:context) { {} }
let(:variables) { {} }
describe 'get event by id' do
context 'when Event.find(id) exists' do
let(:query) {
%|
query Event ($id:ID!) {
event(id: $id) {
id
subject
}
}
|
}
let(:variables) { {id: 1} }
it 'returns event with id, subject' do
#
expect(subject).have_key(:id)
expect(subject).have_key(:subject)
end
end
end
end
従来のrequest specよりもさらに高速になりそうな予感がしています(未計測)
N+1問題
Graphqlではクエリの組み立てが自由自在のため、N+1が起こりやすいという問題があります。
例えば、
query Events {
events {
edges {
id
subject
user { # ここ!
id
}
}
}
}
このようなクエリを叩くとevent一つ一つにたいして都度userを問い合わせてしまうことになります。
この解決策として、sqlクエリをトラバースする中で、リレーション先のid(他のカラムも使える)を溜め込みます。
そしてためたidsを使って一括でクエリを叩くための仕組みを graphql-batch が提供しています(Shopify製)
setup
gem 'graphql-batch'
bundle install
class MySchema < GraphQL::Schema
query(Types::QueryType)
mutation(Types::MutationType)
use(GraphQL::Batch) # 読み込み
end
簡単に実装をみてみる
gem公式のexampleが動くので、それをそのまま使います
https://github.com/Shopify/graphql-batch/blob/master/examples/record_loader.rb
# eventはuser_idをもち、belongs_to :user であるとします
class Types::EventType < GraphQL::Schema::Object
field :id, ID, null: false
field :subject, String, null: false
field :body, String, null: false
field :bodyHtml, String, null: false
def body_html
object.decorate.body_html
end
field :createdAt, ScalarTypes::DateTime, null: false
#
# UserTypeは別途定義したとします。本来eventにuserメッセージを送れるのでなにもせずともresolveできますが、
# それを用いず、graphql-batchを用いたresolveをします
#
field :user, Types::UserType, null: false
#
# resolveではuserインスタンスを返さず、一旦Promiseを返し、sql問い合わせを保留します
# Promiseの詳細は https://github.com/lgierth/promise.rb にあります
#
def user
# Loaders::RecordLoader.new(User, User.primary_key).load(object.user_id)と同じ
Loaders::RecordLoader.for(User).load(object.user_id)
end
end
class Loaders::RecordLoader < GraphQL::Batch::Loader
#
# @param [ActiveRecord::Base] model
# !@param [String] column
#
def initialize(model, column: model.primary_key)
@model = model
@column = column.to_s
@column_type = model.type_for_attribute(@column)
end
#
# loadするたびにあとで検索に用いるkey(通常id)をためこみ、Promiseを返す
#
# @param [Any] key ... 通常はid
# @return [Promise]
#
def load(key)
super @column_type.cast(key)
end
#
# 貯めたkeys(ids)を元に一括でレコードを取得 query(keys)のかしょ
# Promiseとしていた箇所をfulfill = 完了し、実際のレコードを返す
#
def perform(keys)
query(keys).each do |record|
# value: idの値。
value = @column_type.cast(record.public_send(@column))
# 溜め込んだPromiseのうち、key = 1のpromiseに対してrecordを割り当ててPromiseを完了 = fulfillする
# 同じidをkeyにもつPromiseが複数あっても、一括でfulfillされる
fulfill(value, record)
end
# 残っているkeyに対するPromiseはrecordが見つからなかったことを意味するので
keys.each { |key| fulfill(key, nil) unless fulfilled?(key) }
end
private
def query(keys)
scope = @model
scope.where(@column => keys)
end
end
今回はevent側にuser_idが存在する、belongs_toタイプのLoaderでした。他にhas_manyのLoaderもexampleとしてあがっているので、そちらも参考にするとN+1は解決できます
参考記事
http://blog.agile.esm.co.jp/entry/2017/06/16/113248
http://blog.kymmt.com/entry/graphql-batch-examples
ファイルの取扱い
Fileを送信するようなMutationを書くにはひと手間必要ですが、実際に書くと特にはまることなくうごきます
apollo + rails(graphqlサーバー)でファイルをアップロードするmutationを作る方法 - Qiita
apollo-clientを使いさえすれば問題なくファイルアップロードも実現できます
 最後に
最後に
リクエスト/レスポンスの流れ、クエリ、Schema、resolve、型、test、ファイルの取扱、エラー処理、
大体これくらいを知っておくと一通りの開発はできるようになるはず!
まだexecuteのoptionやMySchemaのconfig、cache、、モニタリングなど説明していない点もありますが、それはおいおい見ていくことになると思います。
あとは困ったら http://graphql-ruby.org/guides をひたすら眺めるのが吉です。
また、graphql-rubyの実装はそこまで厚くないので、(そして公式docsが部分部分古かったりする)実装を覗いてみることもおすすめです。
できればこの記事をきっかけにGraphqlユーザーが増えることを祈っています!!!
(もし気に入ってくださった方がいらっしゃれば投げ銭お待ちしています!!)

 他参考になる記事リンク
他参考になる記事リンク
- GraphQL Coding Style Guide | bitjourney Kibela
- Scrapbox
- GraphQLは何に向いているか - k0kubun's blog
- 世のフロントエンドエンジニアにApollo Clientを布教したい - Qiita
- RailsでGraphQL APIを作る時に悩んだ5つのこと | スペースマーケットブログ
- GraphQL | Issus(イシューズ)