はじめに
RAG(Retrieval-Augmented Generation)は、検索拡張型生成モデルとして、外部の知識ソースを活用することで回答の精度と信頼性を向上させる手法です。
多くの企業や組織で重要な情報がPDF形式で保存されていますが、これらのPDFから抽出したテキスト情報に基づいて回答させたいとき、PDFに表が混在すると、うまく回答できないことがあります。表の構造が失われ、解釈不能なテキストの羅列となってしまうことが要因として挙げられます。
本記事では、PDFからLLMがより解釈しやすい形で情報を抽出し、RAGシステムの精度向上に貢献する方法を探ります。
PDFからMarkdownへの変換
構造化を維持したまま抽出するためにはツールが必要となります。構造化を表現するマークアップはjson, xml, htmlなど考えられますが、Markdownは以下の点で用途に適しています。
- マークアップに必要な文字数が少ないため、チャンクにより多くの情報を含められる
- 人間の目にも直感的に構造がわかりやすいため、デバッグがしやすい
そこで、PDFからマークダウンに変換するサービスやライブラリをいくつか試したところ、pdfplummer が比較的シンプルで要件に合致する出力をすることができたため、この記事ではその実装サンプルを説明します。
pdfplummer について
PDFからテキスト情報に加え、表、画像等も抽出するツールです。Python Libraryで提供されています。 サンプルにて使用しているのは主に以下のメソッドです。
- PDFのロード -
pdfplumber.open(pdf_path) - テキストの読み込み -
Page.extract_text_lines() - 表の読み込み -
Page.extract_tables()
サンプルで使用したPDF
ライブラリをインストールします。
pip install pdfplumber
PDFを Markdownに変換します。 入力は1ファイルですが、Pageごとに1つのMarkdownを出力するようにしています。extract_text_lines() は表部分もテキスト抽出するのでextract_tables()で抽出と重複します。そのため、選択的に重複を省くようにしています。(その処理についてはこちらを参考にしました。extract jointly body paragraphs and the table in the pdf)
import pdfplumber
from operator import itemgetter
import os
def extract_contents(page):
"""PDFページから重複しないテキストおよび表データを抽出する。"""
contents = []
tables = page.find_tables()
# テーブルに含まれないすべてのテキストデータを抽出
non_table_content = page
for table in tables:
non_table_content = non_table_content.outside_bbox(table.bbox)
for line in non_table_content.extract_text_lines():
contents.append({'top': line['top'], 'text': line['text']})
# すべての表データを抽出
for table in tables:
contents.append({'top': table.bbox[1], 'table': table})
# 行を上部位置でソート
contents = sorted(contents, key=itemgetter('top'))
return contents
def sanitize_cell(cell):
"""セルの内容を整理する。"""
if cell is None:
return ""
else:
# すべての種類の空白を削除し、文字列であることを保証
return ' '.join(str(cell).split())
def save_to_markdown(directory, file_prefix, page_number, contents):
"""抽出した内容をMarkdownファイルに保存する。"""
filename = f"{file_prefix}_page_{page_number}.md"
filepath = os.path.join(directory, filename)
if not os.path.exists(directory):
os.makedirs(directory)
with open(filepath, 'w', encoding='utf-8') as file:
file.write(f'# Page {page_number}\n\n')
for content in contents:
if 'text' in content:
# テキスト内容を段落として書き込む
file.write(f"{content['text']}\n\n")
elif 'table' in content:
table = content['table']
unsanitized_table = table.extract() # 表オブジェクトからデータを抽出
sanitized_table = [[sanitize_cell(cell) for cell in row] for row in unsanitized_table]
# ヘッダーセパレーターを作成
header_separator = '|:--' * len(sanitized_table[0]) + ':|\n'
# テーブルデータをMarkdown形式に変換
for i, row in enumerate(sanitized_table):
md_row = '| ' + ' | '.join(row) + ' |\n'
file.write(md_row)
# 最初の行(ヘッダー行)の後にヘッダーセパレーターを追加
if i == 0:
file.write(header_separator)
# テーブルの後にセパレーターを追加(任意)
file.write('\n---\n\n')
print(f"{page_number} has been written to {filename}")
def process_pdf(pdf_path, output_dir, file_prefix):
"""PDFの各ページを処理して別々のMarkdownファイルに保存する。"""
with pdfplumber.open(pdf_path) as pdf:
for i, page in enumerate(pdf.pages):
lines = extract_contents(page)
save_to_markdown(output_dir, file_prefix, i+1, lines)
# PDFファイルのパス、出力ディレクトリ、ファイルプレフィックスを定義
pdf_path = 'pdfs/iryohi.pdf'
output_dir = 'output'
file_prefix = 'iryohi_md'
# 処理を実行
process_pdf(pdf_path, output_dir, file_prefix)
# Page 5
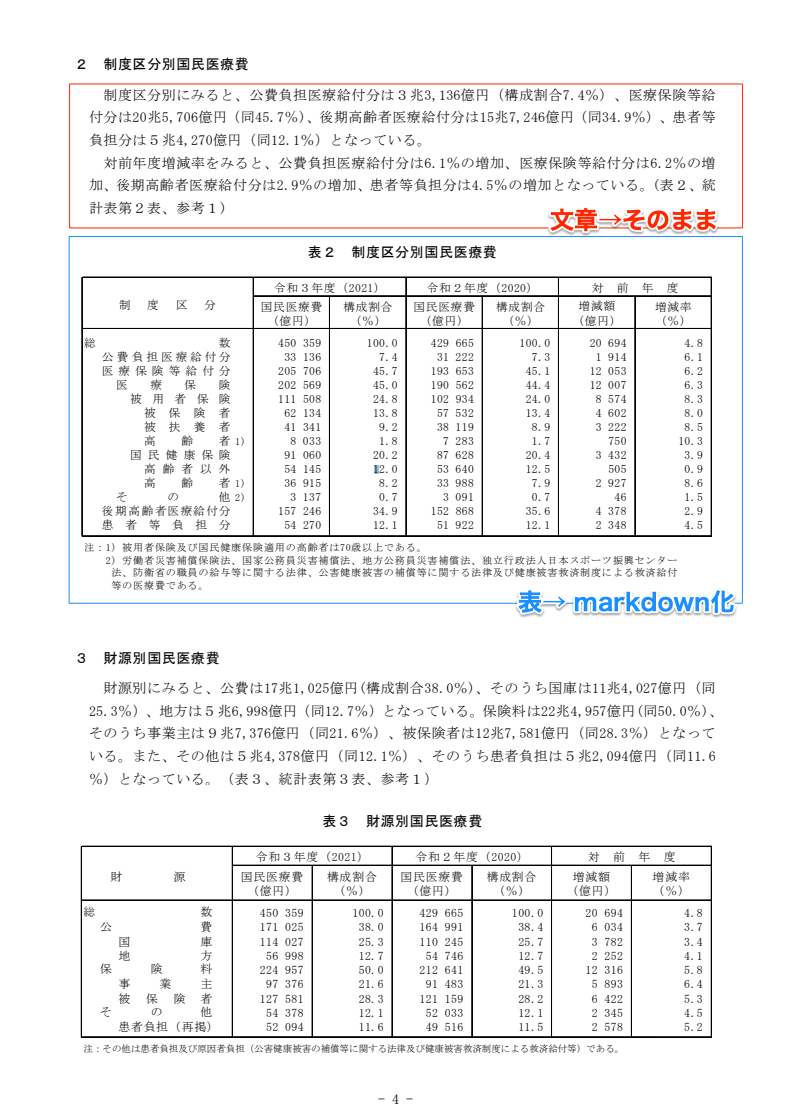
2 制度区分別国民医療費
制度区分別にみると、公費負担医療給付分は3兆3,136億円(構成割合7.4%)、医療保険等給
付分は20兆5,706億円(同45.7%)、後期高齢者医療給付分は15兆7,246億円(同34.9%)、患者等
負担分は5兆4,270億円(同12.1%)となっている。
対前年度増減率をみると、公費負担医療給付分は6.1%の増加、医療保険等給付分は6.2%の増
加、後期高齢者医療給付分は2.9%の増加、患者等負担分は4.5%の増加となっている。(表2、統
計表第2表、参考1)
表2 制度区分別国民医療費
| 制 度 区 分 | 令和3年度(2021) | | 令和2年度(2020) | | 対 前 年 度 | |
|:--|:--|:--|:--|:--|:--|:--:|
| | 国民医療費 (億円) | 構成割合 (%) | 国民医療費 (億円) | 構成割合 (%) | 増減額 (億円) | 増減率 (%) |
| 総 数 公費負担医療給付分 医 療 保 険 等 給 付 分 医 療 保 険 被 用 者 保 険 被 保 険 者 被 扶 養 者 高 齢 者 1) 国 民 健 康 保 険 高 齢 者 以 外 高 齢 者 1) そ の 他 2) 後期高齢者医療給付分 患 者 等 負 担 分 | 450 359 33 136 205 706 202 569 111 508 62 134 41 341 8 033 91 060 54 145 36 915 3 137 157 246 54 270 | 100.0 7.4 45.7 45.0 24.8 13.8 9.2 1.8 20.2 12.0 8.2 0.7 34.9 12.1 | 429 665 31 222 193 653 190 562 102 934 57 532 38 119 7 283 87 628 53 640 33 988 3 091 152 868 51 922 | 100.0 7.3 45.1 44.4 24.0 13.4 8.9 1.7 20.4 12.5 7.9 0.7 35.6 12.1 | 20 694 1 914 12 053 12 007 8 574 4 602 3 222 750 3 432 505 2 927 46 4 378 2 348 | 4.8 6.1 6.2 6.3 8.3 8.0 8.5 10.3 3.9 0.9 8.6 1.5 2.9 4.5 |
---
注:1) 被用者保険及び国民健康保険適用の高齢者は70歳以上である。
セルの中にある複数行の数値が連結されて出力されてしまいました。 さすがにこれではLLMで解釈は難しそうです。
パラメータを一部変更してみました。
tables = page.find_tables(table_settings={"horizontal_strategy": "text"})
{horizontal_strategy:text} とした場合、単語の top の線を仮想的なセルの境界線と見なす、つまりセル内の1行ごとにセルを分割します。
# Page 5
2 制度区分別国民医療費
制度区分別にみると、公費負担医療給付分は3兆3,136億円(構成割合7.4%)、医療保険等給
付分は20兆5,706億円(同45.7%)、後期高齢者医療給付分は15兆7,246億円(同34.9%)、患者等
負担分は5兆4,270億円(同12.1%)となっている。
対前年度増減率をみると、公費負担医療給付分は6.1%の増加、医療保険等給付分は6.2%の増
加、後期高齢者医療給付分は2.9%の増加、患者等負担分は4.5%の増加となっている。(表2、統
計表第2表、参考1)
表2 制度区分別国民医療費
| | 令和3年度(2021) | | 令和2年度(2020) | | 対 前 年 度 | |
|:--|:--|:--|:--|:--|:--|:--:|
| | | | | | | |
| 制 度 区 分 | 国民医療費 | 構成割合 | 国民医療費 | 構成割合 | 増減額 | 増減率 |
| | (億円) | (%) | (億円) | (%) | (億円) | (%) |
| | | | | | | |
| 総 数 | 450 359 | 100.0 | 429 665 | 100.0 | 20 694 | 4.8 |
| 公費負担医療給付分 | 33 136 | 7.4 | 31 222 | 7.3 | 1 914 | 6.1 |
| 医 療 保 険 等 給 付 分 | 205 706 | 45.7 | 193 653 | 45.1 | 12 053 | 6.2 |
| 医 療 保 険 | 202 569 | 45.0 | 190 562 | 44.4 | 12 007 | 6.3 |
| 被 用 者 保 険 | 111 508 | 24.8 | 102 934 | 24.0 | 8 574 | 8.3 |
| 被 保 険 者 | 62 134 | 13.8 | 57 532 | 13.4 | 4 602 | 8.0 |
| 被 扶 養 者 | 41 341 | 9.2 | 38 119 | 8.9 | 3 222 | 8.5 |
| 高 齢 者 1) | 8 033 | 1.8 | 7 283 | 1.7 | 750 | 10.3 |
| 国 民 健 康 保 険 | 91 060 | 20.2 | 87 628 | 20.4 | 3 432 | 3.9 |
| 高 齢 者 以 外 | 54 145 | 12.0 | 53 640 | 12.5 | 505 | 0.9 |
| 高 齢 者 1) | 36 915 | 8.2 | 33 988 | 7.9 | 2 927 | 8.6 |
| そ の 他 2) | 3 137 | 0.7 | 3 091 | 0.7 | 46 | 1.5 |
| 後期高齢者医療給付分 | 157 246 | 34.9 | 152 868 | 35.6 | 4 378 | 2.9 |
| 患 者 等 負 担 分 | 54 270 | 12.1 | 51 922 | 12.1 | 2 348 | 4.5 |
---
注:1) 被用者保険及び国民健康保険適用の高齢者は70歳以上である。
こちらはより構造化情報が維持されていて、LLMでも解釈できそうです。
まとめ
表を含むPDFデータであっても、pdfplummer 等で前処理を行ってLLMが解釈しやすいフォーマットに変換することができました。
しかしながら、1つのツールであらゆるPDFを最適化することは現実的に難しそうです。 RAG運用を考えるとツールの対応すべき範囲は線引きし、元データのPDFの作成方法自体を見直する必要がありそうです。