はじめに
はじめまして、来年度引っ越しを控えているものです。
「電車が苦手なので通勤先から徒歩圏内がいいな~」
そう思いながら、物件探しをしていたのですが、、、
指定先から物件までの距離を表示する機能が無い!
SUUMOに地図から探す機能はあるのですが、物件の詳細をリストで見れなくて使いづらい。。
コードが恐ろしく汚いですが、お許しを><
ここをこうした方がいい!などご指摘お待ちしております!
※Google Maps Platform を使用するように変更しました。Googleは外部からのスクレイピングは利用規約で禁止しています。私のように迷惑をかけないようお願いいたします。利用規約
また、サーバーに負荷をかける行為のため、利用規約で禁止していないサイトでも節度を持ってやるよう注意しましょう。
本記事では、1分の間隔を取ることとします。
本日のゴール地点
指定した住所から物件まで徒歩x分以内の物件の家賃(管理費共益費込み)、徒歩何分か、物件名、家賃、階数、間取り、専有面積、その物件の賃貸サイト、googlemapのURLを取得すること。

コードの説明などはあまり無いのでご了承ください。
いずれまとめます。
前提
環境
Windows 10 バージョン 20H2
Python 3.7.4
jupyter notebook
必要なライブラリ
pip install beautifulsoup4
pip install selenium
pip install openpyxl
pip install xlwt
Chrome driver のダウンロード
chromeでスクレイピングするために必要になります。
「Chrome driver ダウンロード」で検索すると出てきます。
自身のchrome のバージョンと合っている driver をダウンロードする必要があります。
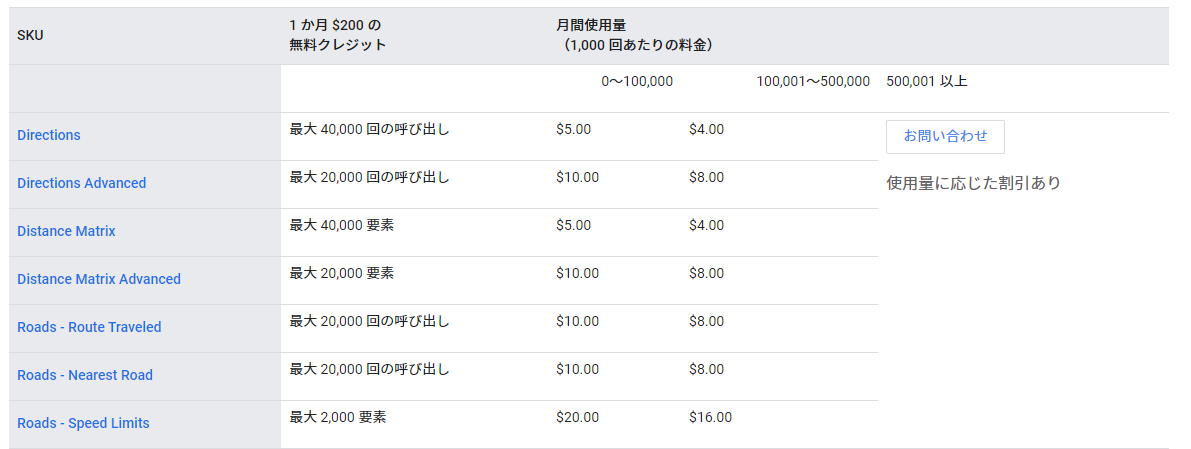
Google Maps Platform
Google Maps Platform のDirections API を用いることで移動時間を計算します。
APIキー取得の方法はこちらの記事に詳しく書いてあります。
https://qiita.com/kngsym2018/items/15f19a88ea37c1cd3646
1か月に40000回までの呼び出しが無料なので、今回の目的は十分果たせそうです。
利用するサイト
今回は賃貸サイトはSUUMOを利用します。
今後、別のサイトも含めてスクレイピングをする予定です。
移動時間は、google map を用いて出します。
想定
勤務地:東京スカイツリー
住みたい場所:墨田区
勤務時間:15分以内
1K
賃料:8万円以下
の物件を探すという想定で、コードを書いていきます。
コード
モジュールのimportと目的設定
まず、必要になるモジュールを import します。
import time
import re
import pandas as pd
import urllib.request, json
import urllib.parse
from bs4 import BeautifulSoup
from selenium import webdriver
次に、目的地と、徒歩何分まで許容するかを定義します。
# 目的地 東京スカイツリー
DESTINATION = '東京都墨田区押上1丁目1−2'
# 徒歩何分まで許容するか
DURATION = 15
SUUMOサイトのスクレイピング
続いてSUUMOのサイトにアクセスします。
# SUUMO スクレイピング
suumo_br = webdriver.Chrome('C:\\Users\\hohgehoge\\chromedriver') # Windowsの方は chromedriver までのパスを通す
# suumo_br = webdriver.Chrome() # Macの方
suumo_br.implicitly_wait(3)
# suumoの物件検索結果のURL
url_suumo = "https://suumo.jp/jj/chintai/ichiran/FR301FC001/?ar=030&bs=040&ta=13&sc=13107&cb=0.0&ct=8.0&co=1&et=9999999&md=02&cn=9999999&mb=0&mt=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&fw2="
suumo_br.get(url_suumo)
time.sleep(5)
print('SUUMO にアクセスしました')
変数 url_suumoには気に入った条件で絞り込みをした後のURLを入力してください。
本記事では、東京都墨田区の1K賃料8万以下の物件で絞り込んでみます。
これで、suumoのサイトが開けました。
次に、このサイトのhtmlを解析し、物件の住所リストを取得します。
soup = BeautifulSoup(suumo_br.page_source, 'html.parser')
# 物件の住所のリスト
addresses = [c.get_text() for c in soup.find_all('li', class_='cassetteitem_detail-col1')]
print(addresses)
出力結果
['東京都墨田区両国2', '東京都墨田区緑4', '東京都墨田区東向島2', '東京都墨田区東向島2', '東京都墨田区八広5', '東京都墨田区緑4', '東京都墨田区千歳3', '東京都墨田区京島1', '東京都墨田区東向島6', '東京都墨田区東向島6', '東京都墨田区立花4', '東京都墨田区東向島5', '東京都墨田区八広6', '東京都墨田区立川4', '東京都墨田区両国2', '東京都墨田区八広2', '東京都墨田区墨田2', '東京都墨田区立花4', '東京都墨田区立花4', '東京都墨田区立花1', '東京都墨田区立花1', '東京都墨田区向島5', '東京都墨田区菊川1', '東京都墨田区東向島6', '東京都墨田区八広5', '東京都墨田区東向島1', '東京都墨田区東向島1', '東京都墨田区文花2', '東京都墨田区向島5', '東京都墨田区八広5']
続いて物件の名称を取得します。
なお、SUUMOの場合、物件の名称の所に駅名とか入ってたりする場合がありますが、今回はスルーです。
# 物件数の確認
properties = soup.find_all('table', class_='cassetteitem_other')
# 建物名を取得
buildings = [c.get_text() for c in soup.find_all('div', class_='cassetteitem_content-title')]
print(buildings)
出力結果
['エクスクルーシブアイディ両国', 'ソアラプラザ錦糸町', 'トウキョウミトストリート', '東武伊勢崎線 曳舟駅 11階建 築16年', 'ドルチェの森', 'カツパレス', '樋口ハイツ', '京成押上線 京成曳舟駅 5階建 築30年', 'グレースフルプレイス', '京成押上線 八広駅 2階建 築8年', 'リリックコート平井橋', 'クレイノボヌールII', 'プロスペリティスカイツリー', 'ライク菊川イースト', 'JR総武線 両国駅 7階建 築12年', 'リガーレ墨田レヴァンテ', '東武伊勢崎線 鐘ヶ淵駅 3階建 新築', '東武亀戸線 東あずま駅 3階建 築13年', 'Rilassante立花', 'ストール ハウス', '東武亀戸線 小村井駅 4階建 築2年', 'リヴシティ向島', 'ボナール', 'モラージュ・ナイン', 'ビーカーサ曳舟', 'ベルフォート', '東武伊勢崎線 曳舟駅 3階建 築3年', 'エル・ヴィエント・アース墨田吾妻', '東武伊勢崎線 曳舟駅 3階建 築6年', '京成押上線 八広駅 3階建 築15年']
1つの物件で複数の賃貸を取り扱っている場合と、1つの物件で単一の賃貸を取り扱っている場合でxpathが異なるので、それを対処するために、1つの物件で取り扱っている賃貸数を取得します。
# サイト内の物件の数をカウントする
properties_num_list = []
for prop in properties:
prop = str(prop)
properties_num_list.append(prop.count('<tbody>'))
print(properties_num_list)
# [1, 12, 8, 8, 1, 2, 3, 1, 3, 3, 1, 1, 5, 4, 1, 4, 1, 1, 1, 1, 1, 5, 1, 1, 1, 2, 2, 3, 2, 1]
Direction API で移動時間を取得
Direction API の設定
endpoint = 'https://maps.googleapis.com/maps/api/directions/json?'
api_key = 'hogehoge' # 取得したキーを入れる
google_map_url = 'https://www.google.co.jp/maps/dir/'
# Google maps api のwalking, driving, bicycling, transit, の中から移動手段を選択できます。
mode = 'walking'
# 時間を分に変換する関数
def time_conversion(travel_time):
minute = re.search('\d*分', travel_time)
hour = re.search('\d*時間', travel_time)
day = re.search('\d*日', travel_time)
if minute:
minute = int(re.search('\d*', minute.group()).group())
else: minute = 0
if hour:
hour = int(re.search('\d*', hour.group()).group()) * 60
else: hour = 0
if day:
day = int(re.search('\d*', day.group()).group()) * 60 * 24
else: day = 0
convert_travel_time = minute + hour + day
return convert_travel_time
先ほど取得した住所リストから、スカイツリーまでの移動時間を取得します。ブラウザが自動で操作され、ジャンジャン移動時間を取得しています。
travel_times = []
map_url = []
for i, address in enumerate(addresses):
nav_request = 'language=ja&origin={}&destination={}&mode={}&key={}'.format(address,DESTINATION, mode, api_key)
nav_request = urllib.parse.quote_plus(nav_request, safe='=&')
request = endpoint + nav_request
response = urllib.request.urlopen(request).read()
directions = json.loads(response)
travel_time = directions['routes'][0]['legs'][0]['duration']['text']
convert_travel_time = time_conversion(travel_time)
travel_times.append(convert_travel_time)
# google map の url を保存
map_url.append(google_map_url + address + '/' + DESTINATION)
print('徒歩時間:', travel_time)
BeautifulSoupで必要な物件情報を取得
必要な物件情報を得るためにpathを設定します。
# 物件のurl
# 一つの建物に対して複数の賃貸がある場合
path_1 = '//*[@id="js-bukkenList"]/ul['
path_2 = ']/li['
path_3 = ']/div/div[2]/table/tbody['
path_4 = ']/tr/td[9]/a'
# 1つの賃貸に対して単一の物件しかない場合
path_mono_1 = '//*[@id="js-bukkenList"]/ul['
path_mono_2 = ']/li['
path_mono_3 = ']/div/div[2]/table/tbody/tr/td[9]/a'
# 階数
# 一つの建物に対して複数の賃貸がある場合
path_floor = ']/tr/td[3]'
# 1つの賃貸に対して単一の物件しかない場合
path_mono_floor = ']/div/div[2]/table/tbody[1]/tr/td[3]'
# 賃料
# 一つの建物に対して複数の賃貸がある場合
path_rent = ']/tr/td[4]/ul/li[1]/span/span'
# 1つの賃貸に対して単一の物件しかない場合
path_mono_rent = ']/div/div[2]/table/tbody/tr/td[4]/ul/li[1]/span/span'
# 管理費
# 一つの建物に対して複数の賃貸がある場合
path_fee = ']/tr/td[4]/ul/li[2]/span'
# 1つの賃貸に対して単一の物件しかない場合
path_mono_fee = ']/div/div[2]/table/tbody[1]/tr/td[4]/ul/li[2]/span'
# 間取り
# 一つの建物に対して複数の賃貸がある場合
path_plan = ']/tr/td[6]/ul/li[1]/span'
# 1つの賃貸に対して単一の物件しかない場合
path_mono_plan = ']/div/div[2]/table/tbody[1]/tr/td[6]/ul/li[1]/span'
# 専有面積
# 一つの建物に対して複数の賃貸がある場合
path_area = ']/tr/td[6]/ul/li[2]/span'
# 1つの賃貸に対して単一の物件しかない場合
path_mono_area = ']/div/div[2]/table/tbody[1]/tr/td[6]/ul/li[2]/span'
賃料と管理費を合算する関数を書きます。
# 賃料と管理費を合算する関数
def calc_rent(rent, fee):
str_rent = rent.replace('万円', '')
float_rent = float(str_rent) * 10000
str_fee = fee.replace('円', '')
float_fee = float(str_fee)
return float_rent + float_fee
続いて、pathをもとに欲しい情報を取得してデータフレームにします。
(コード汚くてごめんなさい><)
df = pd.DataFrame(columns=['建物名', '通勤時間', '家賃', '階数', '間取り', '専有面積', 'map', 'url'])
i, j = 1, 1
for prop_info in zip(travel_times, properties_num_list, buildings, map_url):
if prop_info[0] > DURATION:
# 許容徒歩時間より長い場合、continue
print('Out of Duration')
j += 1
if j % 6 == 0:
i += 1
j = 1
continue
if prop_info[1] == 1:
# url
path = path_mono_1 + str(i) + path_mono_2 + str(j) + path_mono_3
prop_url = suumo_br.find_element_by_xpath(path).get_attribute('href')
# 階数
path = path_mono_1 + str(i) + path_mono_2 + str(j) + path_mono_floor
prop_floor = suumo_br.find_element_by_xpath(path).text
# 家賃
path = path_mono_1 + str(i) + path_mono_2 + str(j) + path_mono_rent
temp_rent = suumo_br.find_element_by_xpath(path).text
# 管理費
path = path_mono_1 + str(i) + path_mono_2 + str(j) + path_mono_fee
temp_fee = suumo_br.find_element_by_xpath(path).text
# 間取り
path = path_mono_1 + str(i) + path_mono_2 + str(j) + path_mono_plan
prop_plan = suumo_br.find_element_by_xpath(path).text
# 専有面積
path = path_mono_1 + str(i) + path_mono_2 + str(j) + path_mono_area
prop_area = suumo_br.find_element_by_xpath(path).text
prop_rent = calc_rent(temp_rent, temp_fee)
print(prop_url)
df = df.append({'建物名': prop_info[2], '通勤時間': prop_info[0], '家賃': prop_rent, '階数': prop_floor, '間取り': prop_plan, '専有面積': prop_area, 'map': prop_info[3], 'url': prop_url}, ignore_index=True)
else:
for k in range(1, prop_info[1] + 1):
path = path_1 + str(i) + path_2 + str(j) + path_3 + str(k) + path_4
prop_url = suumo_br.find_element_by_xpath(path).get_attribute('href')
# 階数
path = path_1 + str(i) + path_2 + str(j) + path_3 + str(k) + path_floor
prop_floor = suumo_br.find_element_by_xpath(path).text
# 家賃
path = path_1 + str(i) + path_2 + str(j) + path_3 + str(k) + path_rent
temp_rent = suumo_br.find_element_by_xpath(path).text
# 管理費
path = path_1 + str(i) + path_2 + str(j) + path_3 + str(k) + path_fee
temp_fee = suumo_br.find_element_by_xpath(path).text
# 間取り
path = path_1 + str(i) + path_2 + str(j) + path_3 + str(k) + path_plan
prop_plan = suumo_br.find_element_by_xpath(path).text
# 専有面積
path = path_1 + str(i) + path_2 + str(j) + path_3 + str(k) + path_area
prop_area = suumo_br.find_element_by_xpath(path).text
prop_rent = calc_rent(temp_rent, temp_fee)
print(prop_url)
df = df.append({'建物名': prop_info[2], '通勤時間': prop_info[0], '家賃': prop_rent, '階数': prop_floor, '間取り': prop_plan, '専有面積': prop_area, 'map': prop_info[3], 'url': prop_url}, ignore_index=True)
j += 1
if j % 6 == 0:
i += 1
j = 1
中身を確認してみます。
df.head()

excelファイルへ
最後にエクセルファイルにして終了です。
df.to_excel('sample.xlsx', encoding='utf_8_sig', index=False)
今後の課題
現状1ページしか読み込んでいないので、全ページを読み込むように改良します。
また、別の賃貸サイトのスクレイピングも行います。
他にも役に立ちそうな機能や物件情報があれば教えて頂けると幸いです。