はじめに
pythonのPKGを使用して日本株の4本値(始値、終値、高値、安値)と出来高を取得する方法です。イニシャルで全銘柄の任意の日付以降のデータを取得し、ランニング日次で追加します。
目的に合わせて2種類のPKGを使用しています。
- 任意の期間:pandas_datareader.data
- 期間を日付で指定できます。一方、大引け後などはデータ取得に時間が掛かり、エラーも出やすいため、 イニシャルのみ利用します。実行する日は土日祝がおすすめです。
- 日次の更新:yahoo_finance_api2
- 直近の情報を比較的早めに取得できます。任意の期間は設定できないため、例えば5年分のデータを集める際には分割できず一度に5年分を実行する必要があり時間を要します。
2者の差異として、pandas_datareader.dataにはAdj Close(調整済み終値)がありますがyahoo_finance_api2にはありません。このページではAdj Closeは配当落ち日くらいしか使用しないと考え、yahoo_finance_api2ではカラムのみ用意し0で埋めています。
また、いずれも場中や大引け直後等、混雑する時間帯は歯抜けになりやすいです。必ずご自身でもデータの完全性を確認し、自己責任でのご利用をお願いします。
準備
インストール
pipからインストールします。
pip install pandas-datareader
pip install yahoo_finance_api2
コード一覧の取得
JPXサイトからコード一覧を取得し、任意の場所にcsv形式で保存します。新規上場と廃止があるため、都度更新する必要があります。こちらのページを参考にしました。
import requests
import pandas as pd
url = "https://www.jpx.co.jp/markets/statistics-equities/misc/tvdivq0000001vg2-att/data_j.xls"
r = requests.get(url)
with open('data_j.xls', 'wb') as output:
output.write(r.content)
stocklist = pd.read_excel("./data_j.xls")
stocklist.loc[stocklist["市場・商品区分"]=="市場第一部(内国株)",
["コード","銘柄名","33業種コード","33業種区分","規模コード","規模区分"]
]
# ETF等を除く
codes = stocklist[(stocklist['市場・商品区分'] == 'プライム(内国株式)') | (stocklist['市場・商品区分'] == 'スタンダード(内国株式)') | (stocklist['市場・商品区分'] == 'グロース(内国株式)')]
len(codes)
codes.to_csv('jpx_code.csv')
1銘柄でテスト
トヨタ(証券コード:7203)を例にAPIの動作確認をしてみます。
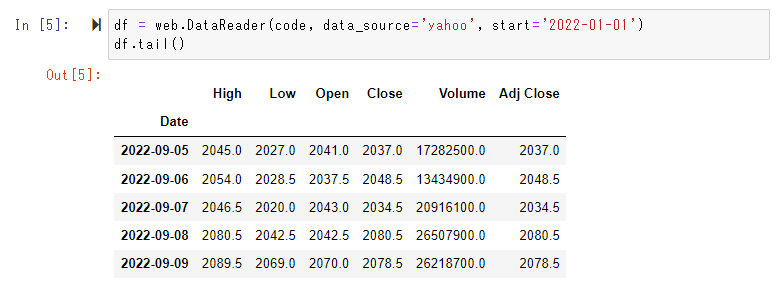
code = '7203.T'
df = web.DataReader(code, data_source='yahoo', start='2022-01-01')
df.tail()
結果はデータフレーム形式で返ります。
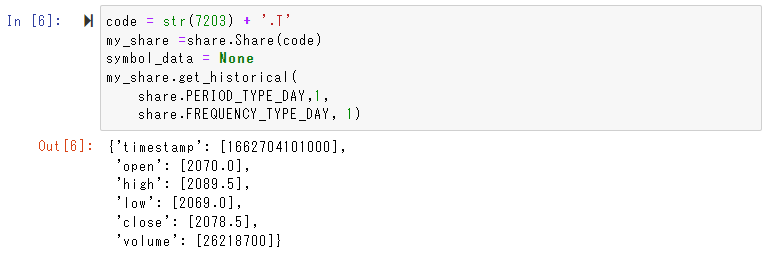
code = '7203.T'
my_share =share.Share(code)
symbol_data = None
my_share.get_historical(
share.PERIOD_TYPE_DAY,1,
share.FREQUENCY_TYPE_DAY, 1)
share.PERIOD_TYPE_DAY, 1で1日分と指定しています。以結果は辞書型で返ります。timestampは協定世界時のため、本番では9時間足して日本標準時に直します。
任意の期間で取得
PKGを準備します。
import pandas_datareader.data as web
import pandas as pd
保存したjpx_code.csvから全銘柄の証券コードリストを作ります。
df_codes = pd.read_csv('jpx_code.csv')
codes_list = df_codes['コード'].astype('int64').tolist()
len(codes_list)
2022年9月時点で3700件程度となっています。
データ取得用の関数を定義します。
def data_read(code, startdate):
code2 = str(code) + '.T'
df = web.DataReader(code2, data_source='yahoo', start=startdate)
df['code'] = code
return (df)
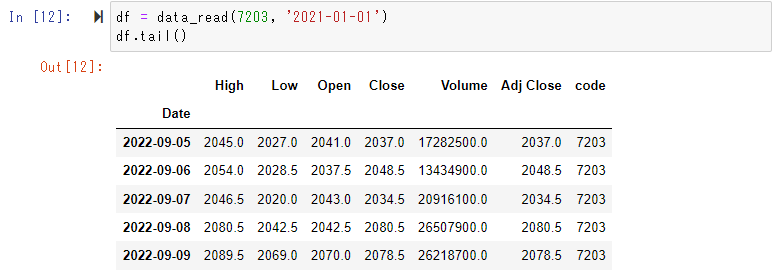
トヨタで確認してみます。
df = data_read(7203)
df.tail()
全銘柄に対して実行します。
期間を今年1月からとし全銘柄で3時間程度で完了しましたが、環境や時間帯によってバラつきがあると思います。筆者は5年分のデータを1年ごとに取得しました。endを設定するときはdf = web.DataReader(code2, data_source='yahoo', start='2016-01-01', end='2016-12-31')と引数を付けます。
%%time
# 取得できなかった銘柄を入れておくリスト。
error_list = []
cols = ['Date', 'High', 'Low', 'Open', 'Close', 'Volume', 'Adj Close', 'code']
df = pd.DataFrame(index=[], columns=cols)
df = df.set_index('Date')
for code in codes_list:
try:
df1 = data_read(code)
df = pd.concat([df, df1], axis = 0)
except:
error_list.append(code)
error_listの中身を確認し、もう一度トライした方がよさそうな場合はfor文をfor code in codes_list:に書き換えてリトライします。
indexの日付や特定日のレコード数=銘柄数で取得状況を確認します。
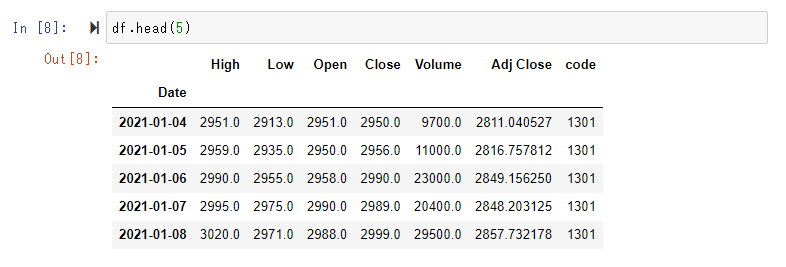
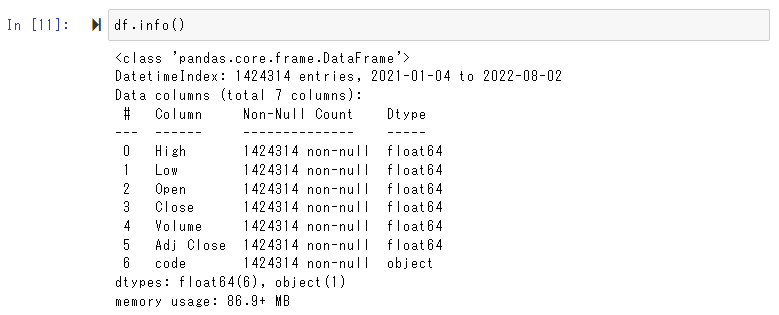
結果を保存します。220802_daily_value.csvのように最新日の日付yymmdd形式で名称を付ける例です。
today = max(df.index)
fname = today.strftime('%y%m%d')
df.to_csv(fname + '_daily_value.csv')
日次で取得
一度過去分を取得すれば、日次はyahoo_finance_api2で追加し最新化できます。
PKGを準備します。
import pandas as pd
import numpy as np
import datetime
import sys
from yahoo_finance_api2 import share
from yahoo_finance_api2.exceptions import YahooFinanceError
任意の期間の場合と同様に全銘柄の証券コードリストを作ります。
df_codes = pd.read_csv('jpx_code.csv')
codes_list = df_codes['コード'].astype('int64').tolist()
len(codes_list)
2022年9月時点で3700件程度となっています。
結果を格納するデータフレームを準備します。
cols = ['datetime', 'open', 'high', 'low', 'close', 'volume', 'code', 'timestamp']
df = pd.DataFrame(index=[], columns=cols)
df = df.set_index('datetime')
df
引数を変える必要がないので関数を用意せず実行している例です。apiのエラーでアクセスできない場合とnullが入ってDFに格納できないエラーの場合があり、前者が多い場合は実行時間をズラした方が良いと考え、tryを区別しています。
また、20分ディレイでデータが生成されますので、大引け後15:20以降に実行する必要があります。筆者の環境では毎日15:30頃に実行して20分程度で完了します。
%%time
# 取得できなかった銘柄を入れておくリスト。
error_list = []
for code in codes_list:
code = str(code) + '.T'
my_share =share.Share(code)
symbol_data = None
try:
symbol_data = my_share.get_historical(
share.PERIOD_TYPE_DAY,0,
share.FREQUENCY_TYPE_DAY, 1)
df1 = pd.DataFrame(symbol_data)
try:
df1['datetime'] = pd.to_datetime(df1.timestamp, unit = 'ms') + datetime.timedelta(hours = 9)
df1['code'] = code
df1.set_index('datetime', inplace = True)
df = pd.concat([df, df1], axis = 0)
except:
error_list.append(code)
except YahooFinanceError as e:
print(e.message)
print(code)
error_list.append(code)
任意の期間と同様error_listの中身を確認し、もう一度トライした方がよさそうな場合はfor文をfor code in codes_list:に書き換えてリトライします。
結果を保存します。220802_daily_value_tmp.csvのように最新日の日付yymmdd形式で名称を付ける例です。1日のみのデータなので、_tmpと付けて累計期間のファイルと区別しています。
today = max(df.index)
fname = today.strftime('%y%m%d')
df.to_csv(fname + '_daily_value_yahoo_tmp.csv')
日次データを任意の期間に追加する
任意の期間を取得したファイルをインポートします。
import glob
import os
# 最新のファイルをインポート
list_of_files = glob.glob('*_daily_value.csv') # * means all if need specific format then *.csv
latest_file = max(list_of_files, key=os.path.getctime)
print(latest_file)
df1 = pd.read_csv(latest_file, index_col = 0)
# codeをint型に変換
df1['code'] = df1['code'].astype('int64').tolist()
# indexをtimestamp型に変換
df1.index = pd.to_datetime(df1.index)
df1.tail()
日次のデータは取得時の続きで、dfに格納されています。ここではわかりやすいようにdf2にコピーしています。
df2 = df.copy()
# APIを叩く際に.Tをつけているので除去
df2['code'] = df2['code'].str.strip('.T')
df2['code'] = df2['code'].astype('int64').tolist()
df2.index = pd.to_datetime(df2.index).date
df2.tail()
2者のデータ形式を揃えます。日次(yahoo_finance_api2)のデータにはAdj Closeがないので0埋めし、カラム名を揃えます。
df2['AdjClose'] = 0
df2 = df2[['high', 'low', 'open', 'close', 'volume', 'AdjClose', 'code']]
# カラム名の先頭文字を大文字に変換
df2.rename(columns = str.title, inplace = True)
df2.rename(columns = {'Adjclose':'Adj Close', 'Code':'code'}, inplace = True)
df2.tail()
結合します。
df = pd.concat([df1, df2], axis = 0)
df.index = pd.to_datetime(df.index).date
df.sort_index(inplace = True)
df.info()
API呼び出し時になぜか重複して行が入っていることがあるので一意にします。
print(df.duplicated().sum()) # 重複のレコード数
df = df[~df.duplicated()]
df.info()
indexの期間やレコード数で結合されたことを確認します。
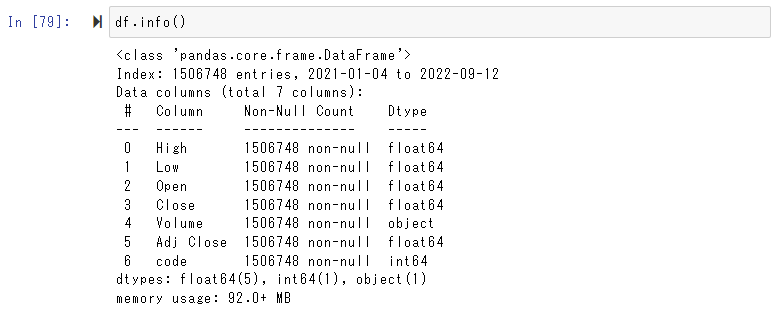
保存します。
today = max(df.index)
fname = today.strftime('%y%m%d')
df.to_csv(fname + '_daily_value.csv')