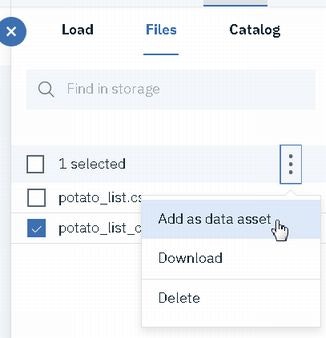
Watson StudioのJupyter NotebookからICOS(IBM Cloud Object Storage)にファイルを出力する方法のメモです。
それ以外のファイルの取り扱いに関しても整理してみました。
具体的には、以下の1から4の操作です。
ICOSへのファイル出力は4の操作です。
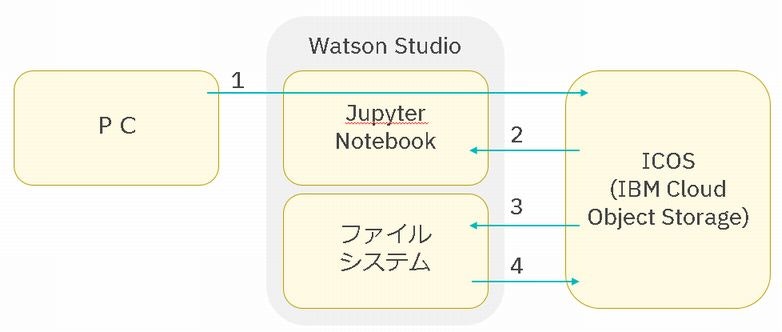
1. PCからICOSへアップロード
Watson Studioを利用している場合は、「Data Assetsへのデータの登録」という操作になりますが、物理的にはファイルはICOSに置かれます。
プロジェクトのAssets画面等で、1010マークをクリックして、アップロードしたいファイルをドラッグドロップするだけです。
(日本語が含まれる場合は、ファイルのエンコードはUTF-8にして下さい)
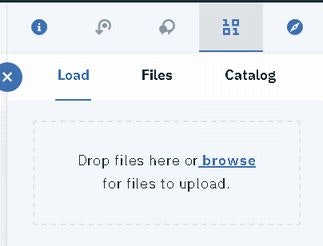
2. ICOSのファイルをJupyter notebookに取り込む
Jupyter Notebookを起動して、1010マークをクリックし、取り込みたいファイルを「Insert pandas DataFrames」してください。
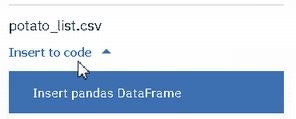
以下のようなコードが自動生成されます。
import types
import pandas as pd
from botocore.client import Config
import ibm_boto3
def __iter__(self): return 0
# @hidden_cell
# The following code accesses a file in your IBM Cloud Object Storage. It includes your credentials.
# You might want to remove those credentials before you share your notebook.
client_ABC = ibm_boto3.client(service_name='s3',
ibm_api_key_id='xxx',
ibm_auth_endpoint="xxx",
config=Config(signature_version='oauth'),
endpoint_url='xxx')
body = client_ABC.get_object(Bucket='xxx',Key='potato_list.csv')['Body']
# add missing __iter__ method, so pandas accepts body as file-like object
if not hasattr(body, "__iter__"): body.__iter__ = types.MethodType( __iter__, body )
df_data_1 = pd.read_csv(body)
df_data_1.head()
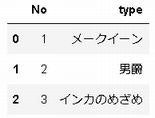
このセルを実行すると、ファイルはPandasのデータフレームに取り込まれて、データフレームの最初の10行が表示されます。
3. ICOSのファイルをファイルシステムに取り込む
以下の1行でできます。
Bucketやkeyの指定は、上記のclient_ABC.get_object の内容をそのままコピーして下さい。
Filenameはファイルシステムに取り込んだときに付けたい任意の名前を指定してください。
client_ABC.download_file(Bucket='xxx',Key='potato_list.csv',Filename='potato_list_copy1.csv')
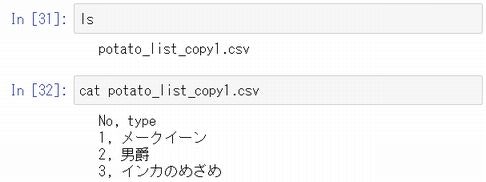
ファイルシステムに保存されたファイルは、以下のように、lsやcatで確認、参照することができます。
4. ファイルシステムのファイルをICOSへアップロードする
ここがこの記事のメインですが、操作は1行だけです。
Filenameはファイルシステムにあるファイルを指定してください。keyはICOS上のファイル名として、任意の名前を指定してください。
client_ABC.upload_file(Filename='potato_list_copy1.csv',Bucket='xxx',Key='potato_list_copy2.csv')
実行しても何も出力はありません。
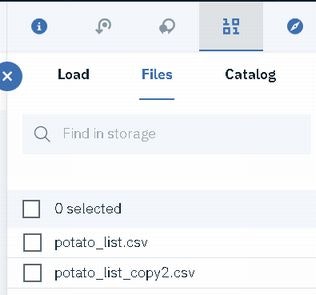
確認するには、プロジェクトのAssetsタブ等を開いて、1010マークのFilesから確認してください。
この時点ではData Assetsとして登録されていませんので、以下のようにすることでData Assetsとして登録することも可能です。