かくこと
AWS苦手項目の傾向と対策
背景
AWS認定ソリューションアーキテクトアソシエイト(SAA)を2019年10月頭に受験。
本試験は参考書の模擬試験問題と比べてあまりに難しく泣きそうになった。
「野郎、俺も男ぞ」と食らいつきなんとか合格。
合格したはいいが運が良かったじゃねとモヤモヤ。
「シゴト」のための知識(資格)だし苦手な項目は今のうちに潰しておきたい。
分析するぞ!
 一応
一応
やること
- 苦手カテゴリの分析
- 苦手単語/サービスの分析
解析
利用したデータについて
- Amazon AWS 資格取得のための演習問題集(完全無料、オリジナル)
- https://awsjp.com/exam/saa-sap/c/
- ⬆️を100問題くらい解いて正解不正解フラグをつけておいた
- 勝手にお借りします><
インポート
import urllib
from bs4 import BeautifulSoup
import pandas as pd
import seaborn as sns
import collections
from sklearn.feature_extraction.text import CountVectorizer
import janome
from janome.tokenizer import Tokenizer
import warnings
import time
warnings.filterwarnings('ignore')
pd.set_option('display.max_rows', 100)
%matplotlib inline
前準備
データ1.演習問題集
- スクレイピングで取得
lst = []
base_html = "https://awsjp.com/exam/saa-sap/c/exam"
for n in range(114,239,1):
html = base_html + str(n) + '.html'
html = urllib.request.urlopen(html)
print(html)
soup = BeautifulSoup(html, 'html')
flg = 0
q = ''
ctgry = ''
ttl = ''
cnt = ''
for i in soup.find_all('body'):
_ttl = soup.find('h1').string.replace('\r\n', '')
ttl = _ttl
for i in soup.find_all('p'):
i = str(i)
i = i.replace('<p>', '').replace('</p>', '')\
.replace('<b>', '').replace('</b>', '')\
.replace('<br/>', '').replace('\n', '')
if 'カテゴリ' in i:
i = i.split(':')
ctgry = i[1]
i = ''
if i.startswith('問題'):
flg = 1
if '解答と解説を見る' in i:
flg = 0
if flg == 1:
q = q + i
cnt = q
time.sleep(5)
lst.append([n, ttl, ctgry, cnt])
中身
df.head()
n title category content
0 114 スナップショットのAZ間、リージョン間のコピー スナップショット 問題スナップショットのコピーに関する記述として正しいものはどれでしょうか。(三つ選択してくだ...
1 115 Amazon SQS のメッセージが削除されるタイミング Amzzon SQS 問題Amazon SQS 内のメッセージが削除されるタイミングは以下のどれですか。(二つ選択...
2 116 パブリック IP がアサインされない EC2インスタンス IPアドレス 問題停止したEC2インスタンスがあります。ルートデバイスとしてEBSを使用しています。マネー...
3 117 S3のバケット内のファイルを一定期間後に削除する Amazon S3 問題S3にファイルが保存されいます。一か月後に自動的にこのファイルを削除する場合、どの機能を...
4 118 予想できる負荷に対処するための Auto Scaling インスタンス数の設定 Amazon Auto Scaling 問題Auto Scaling に関して、コストを重視する場合インスタンスの初期値の設定で適切
こんな感じ
データ2.演習問題(の回答)
df_qa = pd.read_csv('../data/SAA2.csv')
df_qa.head()
n _問題 _正解 _フラグ
0 238 【問題 238】【SAA】EC2インスタンスのスクリーンショットを取得する 1 NaN
1 237 【問題 237】【SAA】クライアントから Amazon RDS に対してSSL暗号化接続 1 NaN
2 236 【問題 236】【SAA】新規に起動したEC2インスタンスに接続できない原因 1 NaN
3 235 【問題 235】【SAA】AWSサービスにおける Key Value Store 型のストレージ 0 NaN
4 234 【問題 234】【SAA】AWS におけるRPO(Recovery Point Object... 1 NaN
結合
df = pd.merge(df, df_qa, on='n')
これで、説明変数<->目的変数の組ができた。
中身
df.head()
n title category content _問題 _正解 _フラグ
0 114 スナップショットのAZ間、リージョン間のコピー スナップショット 問題スナップショットのコピーに関する記述として正しいものはどれでしょうか。(三つ選択してくだ... 【問題 114】【SAA】スナップショットのAZ間、リージョン間のコピー 1 NaN
1 115 Amazon SQS のメッセージが削除されるタイミング Amzzon SQS 問題Amazon SQS 内のメッセージが削除されるタイミングは以下のどれですか。(二つ選択... 【問題 115】【SAA】Amazon SQS のメッセージが削除されるタイミング 0 NaN
2 116 パブリック IP がアサインされない EC2インスタンス IPアドレス 問題停止したEC2インスタンスがあります。ルートデバイスとしてEBSを使用しています。マネー... 【問題 116】【SAA】パブリック IP がアサインされない EC2インスタンス 0 NaN
3 117 S3のバケット内のファイルを一定期間後に削除する Amazon S3 問題S3にファイルが保存されいます。一か月後に自動的にこのファイルを削除する場合、どの機能を... 【問題 117】【SAA】S3のバケット内のファイルを一定期間後に削除する 1 NaN
4 118 予想できる負荷に対処するための Auto Scaling インスタンス数の設定 Amazon Auto Scaling 問題Auto Scaling に関して、コストを重視する場合インスタンスの初期値の設定で適切... 【問題 118】【SAA】予想できる負荷に対処するための Auto Scaling インスタ... 0 NaN
検証1.苦手カテゴリの分析
カテゴリのリストを作成
ctgry_lst = collections.Counter(df['category'])
ctgry_lst = list(collections.OrderedDict(sorted(ctgry_lst.items(), key=lambda x:-x[1])).keys())
可視化
plt.figure(figsize=(20, 10))
g = sns.countplot(data=df, x='category', hue='_正解', order=ctgry_lst)
g.set_xticklabels(labels=ctgry_lst, rotation=90)
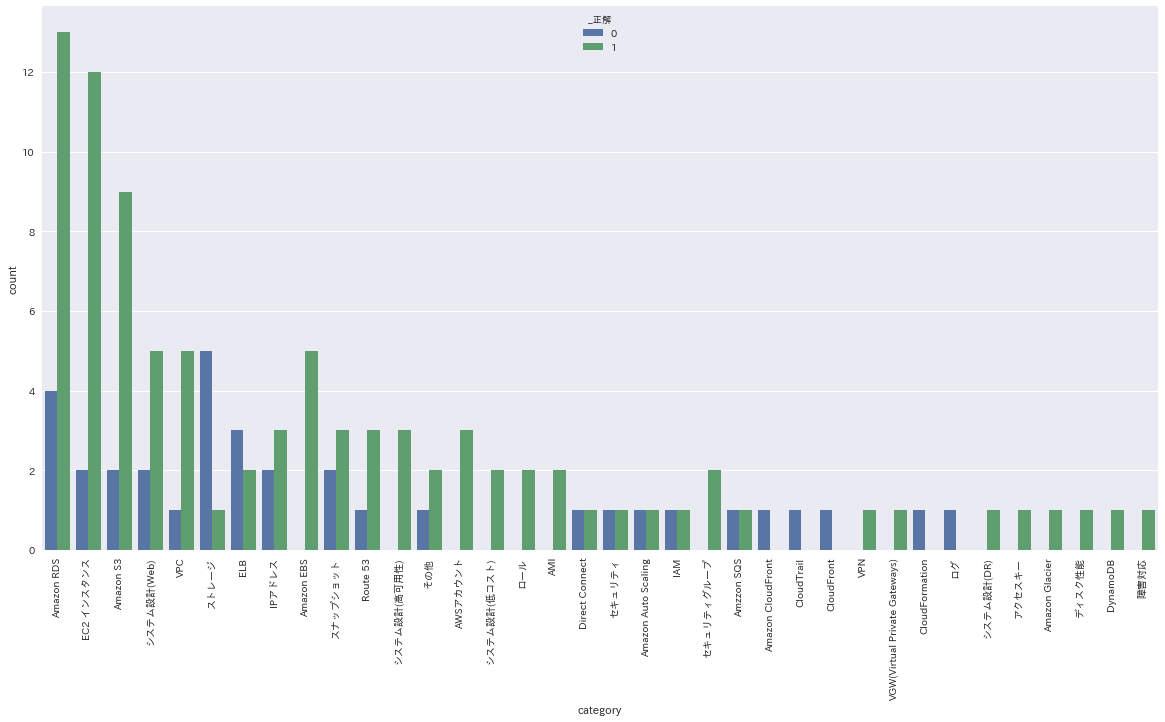
結果&考察
-
得意:EC2、VPC、EBS、IAMまわり(AWSアカウント、ロール)、S3
-
不得意:RDS、ストレージ、ELB、スナップショット
-
単体で勉強しやすいサービスは(おそらく細かいところまで)得意
-
あまり使ったことのないサービス/複合的なサービスは苦手
-
本試験ではELBやALBの問題が多く出題されて困ったことを覚えている
-
「便利なやつ」ではなく、できることや違いをおさえる
-
元々社内外の小さい業務システム系しか触ったことがないからここら辺のイメージがつきづらい
-
ハンズオンが面倒であまり触っていなかったことを改めて反省
-
結果には現れてないが、同じく複合的なサービスであるcloudWatchとかCloudTrailとかに苦手意識をもつのも納得
-
とにかく触らなければ覚えられない
問題文の長さと正解率
なんか最近長い文章読むととにかく目が滑るので検証
df['問題文の長さ'] = df['content'].apply(lambda x: len(x))
可視化
g = sns.kdeplot(df["問題の長さ"][df["_正解"] == 0], color="Red", shade = True)
g = sns.kdeplot(df["問題の長さ"][df["_正解"] == 1], ax =g, color="Blue", shade= True)
g = g.legend(["不正解","正解"])
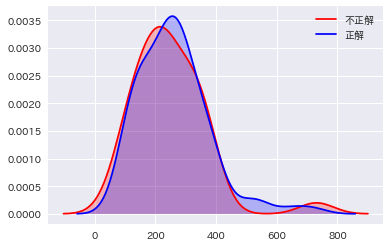
結果&考察
あまり変わらない!
やる気の問題ですね!!
検証2. 苦手単語/サービスの分析
ユーザ辞書追加
janomeは辞書内包型の形態素解析ツールだが
ユーザ辞書を追加してカスタマイズできる
デフォルト辞書だとEC2→EC, 2に分割されてしまいよくない
とはいえ、あまり精緻にすべき解析でもないので適当に
!cat '../data/aws_simple.csv'
EC2,名詞,EC2
S3,名詞,S3
VPC,名詞,VPC
リージョン,名詞,リージョン
Route53,名詞,Route53
Availability Zone,名詞,Availability Zone
cloudtrail,名刺,cloudtrail
わかち書き
udic_type="simpledic"とすると(多分)コンパイルがいらないので便利
t = Tokenizer('../data/aws_simple.csv', udic_type="simpledic", udic_enc="utf8")
df['content_wakachi'] = df['content'].apply(lambda x : " ".join(t.tokenize(x, wakati=True)))
中身
df['content_wakachi'].head() #一部抜粋
0 問題 スナップショット の コピー に関する 記述 として 正しい もの は どれ でしょ ...
1 問題 Amazon SQS 内 の メッセージ が 削除 さ れる タイミング は ...
2 問題 停止 し た EC2 インスタンス が あり ます 。 ルート デバイス として EB...
3 問題 S3 に ファイル が 保存 さ れ い ます 。 一 か月 後 に 自動的 に この...
4 問題 Auto Scaling に関して 、 コスト を 重視 する 場合 インスタ...
5 問題 Amazon EC2 ( Elastic Compute Cloud ...
6 問題 パブリック セグメント 上 に EC2 インスタンス が 10 台 存在 し ます...
bag of words化
単語が何個登場するか、文脈を無視してカウントする
vectorizer = CountVectorizer(stop_words=['問題'])
vectorizer.fit(df['content_wakachi'])
df_bow = pd.DataFrame(vectorizer.transform(df['content_wakachi']).toarray(), columns=vectorizer.get_feature_names())
結合
indexはズレてないはずなのでシンプルに横結合
df = pd.concat([df, df_bow], axis=1)
登場単語リスト(降順)
wrd_lst = df_bow.sum().sort_values(ascending=False)
wrd_lst
する 364
インスタンス 245
ec2 183
ます 177
こと 87
使用 81
az 78
aws 77
amazon 74
可能 73
アクセス 73
- 機械学習/統計モデルを作成するときは、する/ます...とかはストップワードリストに加えてもいいかもしれないが今回はそれ以前の問題なのでそのままにする。
- インスタンス/EC2ってワードが再頻出
- azが続いて多かった。信頼性の高いサービスをどう担保するかがawsの鍵。サービスを横断的に学習した方が良い
- とはいえ、非公式の練習問題サイトだからなんとも言えない
ワードと正解率の関係
lst = []
for w, c in wrd_lst.items():
lst.append([w ,c, round(df[df[w] > 1]['_正解'].mean(), 2)])
df_w = pd.DataFrame(lst, columns=['出現単語', '出現回数', '正解率'])
正解率が低い順にリストアップ
df_w.sort_values('正解率')[0:100]
出現単語 出現回数 正解率
346 受信 4 0.00
197 リソース 7 0.00
500 禁止 2 0.00
373 ipconfig 3 0.00
507 送信 2 0.00
510 レスポンス 2 0.00
519 商品 2 0.00
367 証明 3 0.00
360 スケール 3 0.00
208 multi 7 0.00
380 テスト 3 0.00
211 ペア 6 0.00
344 169 4 0.00
343 リアルタイム 4 0.00
226 ssl 6 0.00
338 振り分け 4 0.00
337 254 4 0.00
335 高速 4 0.00
235 予測 6 0.00
556 案内 2 0.00
237 cloudfront 6 0.00
435 情報 3 0.00
559 経過 2 0.00
98 auto 16 0.00
383 curl 3 0.00
434 meta 3 0.00
145 設置 10 0.00
144 踏み台 10 0.00
467 オンプレミスセンター 2 0.00
422 エンド 3 0.00
168 セグメント 8 0.00
469 ifconfig 2 0.00
133 経由 11 0.00
130 負荷 11 0.00
99 scaling 16 0.00
471 linux 2 0.00
406 rdp 3 0.00
474 latest 2 0.00
476 kenesis 2 0.00
478 ipv 2 0.00
479 オリジン 2 0.00
397 共有 3 0.00
481 アウト 2 0.00
179 cloud 8 0.00
392 コンテンツ 3 0.00
407 分析 3 0.00
240 cloudtrail 6 0.00
437 所属 3 0.00
327 増やす 4 0.00
310 目的 4 0.00
262 タグ 5 0.00
257 ロケーション 5 0.00
256 など 5 0.00
306 キャッシュ 4 0.00
252 初期 5 0.00
251 エッジ 5 0.00
321 リング 4 0.00
247 ローカル 5 0.00
285 プロトコル 5 0.00
265 大きな 5 0.00
326 限定 4 0.00
323 メッセージ 4 0.00
81 パブリック 20 0.20
62 service 23 0.25
67 設計 22 0.33
117 パブリックサブネット 13 0.33
45 elb 31 0.33
109 管理 14 0.33
108 有効 14 0.33
72 ログ 21 0.33
34 もの 38 0.33
8 amazon 74 0.38
68 ポリシー 22 0.40
44 vpc 32 0.40
79 行う 20 0.40
218 ごと 6 0.50
169 windows 8 0.50
102 storage 15 0.50
191 http 7 0.50
126 による 11 0.50
161 プライベートサブネット 9 0.50
111 ホスト 14 0.50
255 テーブル 5 0.50
180 raid 8 0.50
270 data 5 0.50
115 サーバ 13 0.50
41 として 35 0.50
122 暗号 12 0.50
160 balancer 9 0.50
156 load 9 0.50
234 サイズ 6 0.50
58 ため 25 0.50
76 機能 21 0.50
152 とき 9 0.50
78 配置 20 0.50
30 elastic 40 0.50
322 最大 4 0.50
199 なら 7 0.50
83 simple 20 0.50
268 固定 5 0.50
結果&考察
- SSLとかipconfigとか暗号とかセキュリティ/ネットワークの基本的なことが分かってないっぽい
- さっきVPCは得意と言ったが、そうでもなかった(出現回数32,正解率0.4)
- VPCのサービスそのもの説明は出来るが、なんかのアーキテクチャにおけるVPCの使われ方に関してはダメなんだろうだ
- エッジとかオリジンとかクラウド的?の言葉もダメダメ
- やっぱりcloudtrailの問題は全然ダメだ(出現回数6,正解率0.0)
- auto, scalingの問題もキツイようだ
- よく受かったなこれで。
出現回数が多い順にリストアップ
df_w.sort_values('出現回数', ascending=False)[0:100]
出現単語 出現回数 正解率
0 する 364 0.79
1 インスタンス 245 0.78
2 ec2 183 0.72
3 ます 177 0.76
4 こと 87 0.76
5 使用 81 0.62
6 az 78 0.92
7 aws 77 0.60
8 amazon 74 0.38
9 可能 73 0.88
10 アクセス 73 0.60
11 取得 69 0.67
12 ない 69 0.69
13 です 67 0.86
14 ip 65 0.79
15 場合 63 0.86
16 から 61 0.71
17 スナップショット 60 0.77
19 アドレス 52 0.67
18 れる 52 0.92
20 設定 51 0.64
21 システム 48 0.82
22 必要 47 1.00
23 いる 47 0.75
24 s3 46 0.67
25 接続 44 0.88
26 ebs 42 0.75
27 でしょ 42 NaN
28 どの 41 1.00
29 ファイル 41 0.89
30 elastic 40 0.50
31 この 40 0.89
33 により 39 0.67
32 正しい 39 0.60
34 もの 38 0.33
35 選択 38 1.00
36 ユーザ 38 0.75
37 でき 38 0.86
38 ある 37 0.67
39 アカウント 35 1.00
40 ください 35 1.00
41 として 35 0.50
42 停止 34 0.71
43 あり 33 0.88
44 vpc 32 0.40
45 elb 31 0.33
46 どれ 31 NaN
49 iam 29 0.86
48 web 29 0.62
47 リージョン 29 0.80
50 セキュリティ 28 1.00
51 データ 27 1.00
52 rds 26 0.75
53 作成 26 1.00
54 バックアップ 26 0.86
55 まし 25 1.00
56 削除 25 0.57
57 よう 25 NaN
58 ため 25 0.50
59 起動 25 1.00
60 キー 24 1.00
63 バケット 23 0.60
64 構築 23 0.60
65 ロール 23 1.00
62 service 23 0.25
61 グループ 23 0.83
66 あなた 22 1.00
67 設計 22 0.33
68 ポリシー 22 0.40
69 ami 22 1.00
74 確認 21 1.00
77 許可 21 0.83
76 機能 21 0.50
75 アタッチ 21 1.00
72 ログ 21 0.33
73 ストレージ 21 0.57
71 インターネット 21 0.67
70 ボリューム 21 0.75
81 パブリック 20 0.20
83 simple 20 0.50
82 db 20 1.00
78 配置 20 0.50
80 利用 20 0.80
79 行う 20 0.40
84 二つ 19 1.00
85 store 19 0.67
86 データベース 19 1.00
87 実現 18 0.75
88 稼働 18 1.00
89 発生 18 1.00
94 dynamodb 17 1.00
97 変更 17 1.00
95 一番 17 1.00
96 アプリケーション 17 1.00
93 できる 17 0.75
92 サービス 17 0.50
90 コスト 17 1.00
91 ませ 17 0.67
98 auto 16 0.00
99 scaling 16 0.00
- 出現回数が多い単語(サービス)の方が考察の精度は高くなる(はず)
- s3,アドレス,アクセス,削除とかが結構あやしい(<0.7)
- s3においたオブジェクトをどう運用していくかみたいな問題が弱いんだろうな
- dynamoDBが得意すぎる(出現回数17,正答率1.00)
- NoSQLみたいなフニョフニュしているサービスが好きなんでしょうね(意味不明)
- ログの正答率が低い(出現回数21,正解率0.33)
「ログ」が出現する問題(一部)
df[df['ログ'] >= 1]['content'][42]
'問題Glaierへ保存するのに適したファイルは何でしょうか。(正しいものを三つ選択してください)\r\u3000ア. 法令で5年間の保管が義務付けられているシステムログ。\u3000イ. 変換が完了した動画の元のRAWデータ。\u3000ウ. 変換が完了した動画の変換後のデータ。\u3000エ. 全世界のユーザにWebで公開する動画。\u3000オ. めったにアクセスしないが事件発生時のみに確認する防犯カメラの動画。\u3000カ. 稼働中の仮想マシンが使用する仮想ディスク。\u3000キ. 仮想通貨のトランザクションデータ。\u3000ク. ビッグデータとして収集したリアルタイム解析用データ。'
df[df['ログ'] >= 1]['content'][56]
'問題EC2インスタンスでWebサーバを構築しています。ELB (Elastic Load Balancer)により振り分けを行っています。Webサーバに対するアクセスログを5分ごとに取得しようと思います。このログはトラフィック分析に使用します。どの機能を使用するとよいでしょうか。\r\u3000ア. AWS CloudTrail を有効化する\u3000イ. ELB のアクセスログを有効化する\u3000ウ. ELB で振り分けが行われる EC2インスタンスの OS ログを有効化する\u3000エ. CloudWatch で ELB のメトリックを有効化する'
df[df['ログ'] >= 1]['content'][79]
'問題CloudTraiの特徴として正しいものをすべて選択してくさい。\r\u3000ア. 全てのリージョンでCloudTrailを有効にすることが可能である。\u3000イ. リージョンごとにCloudTrailを有効にすることが可能である。\u3000ウ. EC2インスタンスごとにCloudTrailを有効にすることが可能である。\u3000エ. ログは集めてS3にアップロードすることが可能である。\u3000オ. デフォルトで有効化されている。'
- システムログ/監査の項を見て見ぬ振りしないこと
まとめ
- SAAなめてた
- 直感と分析結果は殆ど一致
- 無駄じゃね?その時間勉強してた方が良いんじゃね?
- 結局、分析も最後の最後で直感/先入観が入るのでよくわからん。
- ほかの人に説明して納得してもらう必要ないし要らないかもしれん
- ただ間違えた問題をクイックに抽出できることは重要で、これやっとくとそれが実現できる
- 分析自体は重要ではなく勉強PDCAの「システム」化が重要なのかな??
- innovateでソリューションアーキテクトプロフェッショナルのセッション視聴してるが難しい
- 苦手な部分は明確になったので、まずは埋めていきたい。
- 多分今度は英語での学習になるので色々工夫してこう
覚書
- 試験直前に良いサイト見つけたりしたので情報収集ちゃんとやる
- 計画的に勉強する
- 本試験は非公式サイト/参考書の模擬試験より難しいこと意識
- 時間はかかるけど一通りサービスに触る(出来なかったこともあるので)
- 楽しいサービスなので色々と楽しむ