LSP サーバーを作っていくプロジェクトの第2回です。
- 前回: LSP学習記 #1
前回は警告の表示までできるようになりました。しかしこの調子で自明な機能を足し続けても楽しくないので、新しいプログラミング言語を作ります。自作言語処理系とともに LSP サーバーを育てていく予定です。
- 今回のソースコード: curage-lang v0.3.0
構文
クラゲ言語 (curage-lang) の構文は、なるべく解析が楽になるように決めました。そのため、記号ではなくキーワードを多用したり、改行が文の区切りだったりします。
以下のとおりです:
- プログラムは文の並び
- 文は改行区切り
- 文は
let文のみ- 分岐などは後で追加 (予定)
- 式は整数または名前
- 足し算などは後で追加 (予定)
let文の凡例:
let 名前 be 式
プログラムの例:
let x be 1
let y be x
字句解析
ソースコードが文字列のままでは扱いにくいです。そこで、ソースコードを「トークン」のリストに分解します。トークンというのは、単語や数値、記号などのことです。
-
let x be 1→"let", "x", "be", "1"
クラゲ言語では、スペースは重要じゃないのでトークンではないことにします。
一方、改行はトークンにします。「文の終わり」として構文上、重要だからです。実際には、ファイル末尾に改行がないケースに備えて 文の終わり に特殊なトークンを自動挿入するようにします。
字句解析: 実装
ソースコードを行ごとに分解した後、その行を正規表現で分解する、という方針にしました。これは正規表現の exec メソッドを使うと簡単です。 JavaScript の新機能である配列の分割代入と一緒に使うと簡潔に書けます。
{
const source = "let x be 1\nlet y be x\n"
// スペース、整数、名前、あるいは「解釈できない任意の文字」のどれかにマッチ
const tokenRegexp = /( +)|([+-]?[0-9]+\b)|([a-zA-Z0-9_]+\b)|(.)/g
// 行ごとに分解
const lines = source.split(/\r\n|\n/)
for (let line = 0; line < lines.length; line++) {
if (lines[line].trim() === "") continue // 空行は無視
while (true) {
// 次のマッチを探す
const match = tokenRegexp.exec(lines[line])
// マッチしなければ (= 行末に達したら) 終わり
if (!match) break
// 各変数には各グループにマッチした文字列が入る
// どれか1つ以外は undefined
const [__, space, int, name, invalid] = match
if (space) continue // スペースは無視
if (invalid) console.warn("invalid: " + invalid)
if (int) console.log("int: " + int)
if (name) {
if (name === "let" || name === "be") {
console.log(name)
} else {
console.log("name: " + name)
}
}
}
console.log("eol")
}
}
出力:
let
name: x
be
int: 1
eol
let
name: y
be
name: x
eol
- メモ: 解釈できない文字がソースコード上にあった場合に備えて
.にマッチするようにしました。解釈できない文字は次の工程でエラーになります。このパターンがないと、解釈できない文字を見落としてしまいます。
字句解析: 位置情報
前回見たとおり、ソースコードに警告を出すには警告範囲の指定が必要でした。そのため、字句解析する際に、「そのトークンがどの位置にあるか」を記録しておくことにします。
トークンには文字列の他に、種類 (int/name/etc.) と範囲を持たせます。
type TokenType =
| "int" | "name" | "let" | "be" | "eol" | "invalid"
interface Token {
type: TokenType,
value: string,
range: Range,
}
Range は LSP で定義されているインターフェイスです。「何行目何列目」から「何行目何列目」まで、というかたちでテキストの範囲を表します。
// テキスト上の範囲
interface Range {
start: Position,
end: Position,
}
// テキスト上の位置
interface Position {
line: number,
character: number,
}
上記の解析処理を変更して、トークンを console.log するのではなくリスト Token[] にまとめて返すようにしたのが以下です:
構文解析
次に構文解析です。この工程では、トークンのリストを解析して、ソースコードが構文的に正しいかを検査します。構文的に誤りがあったら警告を出します。
クラゲ言語の文法なら、トークンのリストが let 文の繰り返し、つまり「let, 名前, be, 式, 改行」の繰り返しになっていればOK。
逆に let a で文が途切れてたり、 let 3 be 5 のようにトークンの種類がおかしかったらダメ。
重要なのは、 誤っている部分があってもパースを止めない ことです。
- 未完成のミニ言語処理系は構文エラーを検出すると異常終了しがちですが、LSP サーバーには構文エラーをクライアントに報告してほしいので、終了させてはダメです。
- 実用上、ドキュメント内のなるべく多くの構文エラーを一斉に指摘してくれたほうが便利です。
今回は「エラーを見つけたら次の改行までスキップする」ことにします。これで複数の行のエラーを同時に検出できます。
構文解析: 実装
構文解析の実装を考えます。トークンを前から見ていくのでトークンの位置 i を変数として持ちます。
// トークンの位置
let i = 0
// 検出した diagnostic のリスト
const diagnostics: Diagnostic[] = []
トップダウンに見ていくと、構文解析の全体としてはトークンリスト上のループです。
while (i < tokens.length) {
parseLetStatement()
}
let 文をパースする方法は、トークンが文法で指定された順序で現れるかどうか、地道に調べます。
const parseLetStatement = (): void => {
if (tokens[i].type !== "let") {
return warn("Expected 'let'.")
}
i++
if (tokens[i].type !== "name") {
return warn("Expected a name.")
}
i++
if (tokens[i].type !== "be") {
return warn("Expected 'be'.")
}
i++
if (!tryParseExpression()) {
return warn("Expected an expression.")
}
if (tokens[i].type !== "eol") {
return warn("Expected an end of line.")
}
i++
}
式の解析は、いまは簡単です。トークンが整数か名前ならOK。
- 足し算や掛け算を式として認めると複雑になります。
const isAtomicExpression = (token: Token) => {
return token.type === "int" || token.type === "name"
}
const tryParseExpression = (): boolean => {
if (!isAtomicExpression(tokens[i])) {
return false
}
i++
return true
}
誤りを見つけたときは、前述の通り行を読み飛ばします。行を読み飛ばして警告を出す関数 warn を使っています。
const warn = (message: string) => {
const { range } = skipLine()
diagnostics.push({
severity: DiagnosticSeverity.Warning,
message,
range,
})
}
行の読み飛ばしの処理がややこしいですが、トークンのリストの区間を考えます。区間の末尾が改行になるかトークンのリストの末尾に達するまで、区間を広げていくイメージです。最後に区間の末尾 (改行の次) にジャンプします。
const skipLine = (): { range: Range } => {
// 区間の開始点
const l = i
if (l >= tokens.length) {
return { range: tokens[tokens.length - 1].range }
}
// 区間の終わり (r 番目は含まないので r-1 番目が最後のトークン)
let r = l + 1
while (r < tokens.length && tokens[r - 1].type !== "eol") {
r++
}
assert.ok(l < r && (r >= tokens.length || tokens[r - 1].type === "eol"))
const range = {
start: tokens[l].range.start,
end: tokens[r - 1].range.end,
}
i = r
return { range }
}
区間のイメージはこんな感じ (カッコが区間を表す):
let a [ 2 eol ]
^ Expected 'be'
let ..
これで構文解析ができました。
前回作った検証処理をこの構文解析で差し替えれば、クラゲ言語の LSP サーバーができます。
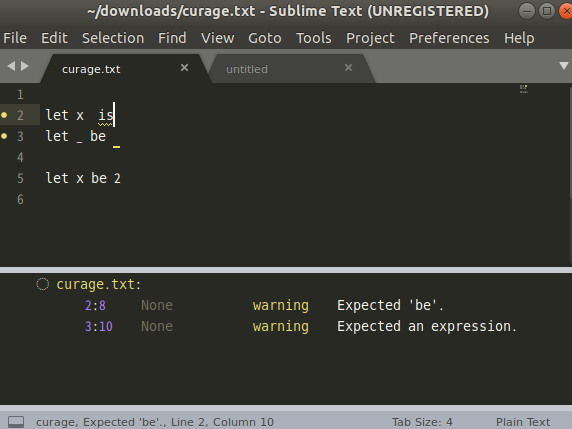
動作確認
Sublime Text 3 での動作例です:
まとめと次回
今回のポイントは以下の3点でした。
-
execと分割代入は便利 - 位置情報は必須
- エラーからの復帰は重要
次はソースコードの振る舞いに踏み込んだ静的解析を行い、シンボル参照のハイライトができるようにします。