静的型付き言語の便利な点の1つとして、パターンマッチに漏れがなく網羅的であることがコンパイル時に検証されることがあります。本稿ではパターンマッチの説明から始め、「スペース」という概念を用いてパターンマッチの網羅性を検査するアルゴリズムの大ざっぱな雰囲気を述べます。また、その試験実装を作ったので公開します。
この記事は 2019年12月の 言語実装アドベントカレンダー の21日目です。
関連リンク
実装は以下のリポジトリにあります:
https://github.com/vain0x/pattern-matching-exhaustivity-checking
以下のページで動作を確認できます:
https://vain0x.github.io/pattern-matching-exhaustivity-checking/index.html
網羅性検査の実装は以下の記事を参考にしました。ただし、本稿の記述はこの論文の主張というより筆者の理解に基づいて書かれているため注意してください。
この論文やスペースという手法のことは以下の記事で知りました。この解説も併読するとよりいっそう分かりよいかもしれません。
網羅性
念のため パターンマッチの網羅性 から軽く説明します。
簡単にいえば 条件分岐の場合分けに漏れがない ことの検査です。
ここにソートの方向を示す SortDirection という列挙定数型があります。昇順・降順の2値です。
enum SortDirection {
Asc,
Desc,
}
SortDirection 型の値に関して場合分けするとき、2通りに分岐すれば十分です。その他のケースにコードが進むことがないことをコンパイラは知っています。この状態の場合分けを「網羅的」といいます。
match sort_direction {
Asc => "昇順",
Desc => "降順",
}
逆に、値が分岐のいずれにも該当しないケースがありうるような場合分けは網羅的ではない (非網羅的である) といいます。例えば次の関数は sort_direction = SortDirection::Desc で呼び出されたときに分岐先がないため、コンパイルエラーになります。仮にエラーなく実行できたとしても、関数が return できる値がなく詰むため、エラーにしておくのは合理的です。
fn sort_direction_to_name(sort_direction: SortDirection) -> &'static str {
match sort_direction {
Asc => "昇順",
// 降順のケースがない
// Desc => "降順",
}
}
また、網羅性検査は複数の値を用いた複合的なオブジェクトに対しても動作します。ここにあるフィールドを昇順または降順にソートするか、あるいはそもそもソートしないか、という状態を表す SortOption 型があります。
enum SortOption {
Sort(SortDirection),
NoSort,
}
パターンマッチを入れ子にすることによって、この型がとる3つの値に関して1回の条件分岐で場合分けできます。ここにも網羅性が効きます。
match sort_option {
Sort(Asc) => "▲",
Sort(Desc) => "▼",
NoSort => "",
}
型
パターンマッチの網羅性を検査する前に、型と型検査が必要です。
本稿では上記のような enum 型 のみ扱うことにします。enum 型がとりうる値の種類 (上記の Asc や Sort のこと) を「コンストラクタ」と呼びます。(補足: ここでは参考にした論文に用語を合わせています。Rust 界隈ではバリアントと呼ぶようです。)
再帰型: Binary
上記の例だけを見ると有限通りの型しか作れないような印象を受けるので とってつけたように 別の例をあげておきます。(なお以下の Binary 型の定義は Rust ではコンパイルできません。これ以降のサンプルコードは、後述する自作言語のものです。)
Binary 型は
enum Bit {
Zero,
One,
}
enum Binary {
Nil,
Cons(Bit, Binary),
}
Cons コンストラクタの値がまた Binary 型であることに注意すると、値を入れ子にすることで任意の長さの2進数を表現できます。
| Binary 型の値 | 2進数 |
|---|---|
Cons(One, Nil) |
1 |
Cons(One, Cons(Zero, Nil)) |
10 |
Cons(One, Cons(One, Cons(Zero, Nil))) |
110 |
パターン
場合分けのケースを記述する項を式とは区別してパターンと呼びます。パターンは2種類あります。
1つ目は上記に書いたような、コンストラクタとその引数を記述したパターンです。
// コンストラクタ のパターン (引数なし)
Asc
// コンストラクタ ( 引数 ) の形式のパターン
Sort(Asc)
もう1つは、どのような式でもマッチする破棄パターンです。(補足: ここでは実装の用語に合わせています。論文に合わせてワイルドカードにした方がよかった……)
_
なお通常の言語ではマッチした値を変数に代入する「変数パターン」がありますが、網羅性検査においては破棄パターンと挙動が変わらないため、省略します。
これらのパターンは組み合わせて使えます。
// 昇順か降順かは問わずソートするとき
Sort(_) => ...
スペース
タイトルに名前があるように、本稿の網羅性検査アルゴリズムにおいて最も重要な概念である スペース を紹介します。
簡単にいうと、型やパターンがとりうる 値の集合 を表現するものと考えてよいです。
集合と同様の 和 (∪) や 差 (\)、包含関係 (⊂) の概念をスペースに実装します。これさえあれば網羅性検査は鮮やかに解決できます。
スペースの包含
初等的な集合の話ですが、部分集合 S から上位集合 T を引くと空集合になります。(S ⊂ T → S \ T = {})
スペースではこの性質を包含関係 (⊂) の「定義」として採用します。
スペースによる網羅性検査
少し話が前後しますが、網羅性検査を終わらせます。以下のようなパターンマッチがあるとします。
match cond {
p1 => ...
p2 => ...
...
pN => >..
}
型検査は通っていて、式 cond とパターン p1, p2, ..., pN はすべて型 t を持つことが分かっています。
- 型 t のスペースを T(t) で表す
- パターン p のスペースを P(p) で表す
とすると、スペースが「値の集合を表現している」ことから、以下が成り立てば網羅的といえることが分かります。(| はスペースの和)
T(t) ⊂ P(p1) | P(p2) | ... | P(pN)
言い換えれば「型 t のどんな値も、パターン p1, p2, ..., pN のいずれかにマッチする」ということです。
前述の包含の定義を使えば、網羅性検査は最終的に、次のスペースが空かどうかの判定できればよいことになります。
(P(p1) | P(p2) | ... | P(pN)) \ T(t)
ということは、残りの作業としては以下ができれば OK です。
- 型からスペースを作る T(t) の実現
- パターンからスペースを作る P(p) の実現
- スペースの和 (|)
- スペースの差 (\)
スペースの表現
スペースを具体的に定義します。スペースは以下の3種類です。
pub(crate) enum Space {
Constructor { name: String, args: Vec<Space> },
Union(Vec<Space>),
Ty(Ty),
}
コンストラクタスペース (Constructor{...}) は、特定のコンストラクタの値からなる集合を表現するためのスペースです。例えば引数なしのコンストラクタスペース K(One) は、コンストラクタ One 自身の値だけを含む集合 { One } に対応します。(ここではオブジェクトを Rust の構文による Constructor{ name: name, args: args } ではなく K(name; args...) のような形式で書きます。)
次にユニオンスペース (Union{...}) は、そのままユニオン (集合和) を表現します。(スペース1 | スペース2 のように書きます。) 特に、ゼロ個のスペースのユニオンは 空のスペース であり、空集合の表現に使います。
最後に型スペース (Ty{...}) は、型がとりうる値からなる集合を表現します。(前述の通り T(型名) と書きます。)
- 例えば
T(SortDirection)は{ Asc, Desc }を表します。 - 例えば
T(SortOption)は{ Sort(Asc), Sort(Desc), NoSort }を表します。 - 例えば
T(Binary)は{ Nil, Cons(Zero, Nil), Cons(One, Nil), Cons(Zero, Cons(Zero, Nil)), ... }のような無限集合を表しています。
ここで重要なのは コンストラクタも各々型とみなす ことです。例えば Sort 型のコンストラクタ Asc は、Sort 型でもあると同時に、Asc 型でもあると考えます。Asc 型は Sort 型の部分型です (Asc <: Sort と書きます)。
よく見るとコンストラクタの前に struct キーワードをつけたら構造体なわけで、1個の型だと思って支障はないわけです。(とはいえ実際に型として扱うと型システムが変わってしまうので、あくまで「ここでは型とみなす」だけです。)
スペースの構築
スペースの作り方を考えます。
型から作ったスペース T(t) は明らかに型スペースです。
「パターンスペース」はありませんが、パターンからスペースへの再帰関数が簡単に書けます。
- コンストラクタパターンは、コンストラクタスペースに対応します。各引数を再帰的にスペースに変換すればよいです。
- 破棄パターンは、型スペースに対応します。
- 破棄パターンは「何にでも」マッチしますが、型検査が通っている以上、その型の値にしかマッチしません。
そのため、パターン _ の型が t なら、破棄パターンのスペースは型スペース T(t) に一致します。
- 破棄パターンは「何にでも」マッチしますが、型検査が通っている以上、その型の値にしかマッチしません。
スペースの交差
(補足: 実は、元の論文ではスペースの差の定義の一部に「スペースの交差 (共通部分)」を使用していますが、そこは試験実装ではまだ省略しているので、交差の定義も省略します。)
スペースの差
最後にスペースの差 (\) です。集合の差に関する以下のような振る舞いはそのままです。
- 空のスペースから何を引いても空のスペース
-
{} \ x={}
-
- 何から空のスペースを引いても変わらわない
x \ {} = x
- 和から引くときはそれぞれ引いて和を取る
-
(x | y) \ z=(x \ z) | (y \ z)
-
- 和を引くときはそれぞれ引く
-
x \ (y | z)=x \ y \ z
-
ユニオンが消えたので、後はコンストラクタスペースと型スペースの組み合わせを考えます。
コンストラクタと型スペースの差
アルゴリズムとは順番が違いますが、初めにコンストラクタと型スペースの差を考えます。分かりやすいのは、コンストラクタスペース K(...) から、そのコンストラクタを含む型スペース T(t) を引くケースです。コンストラクタ K の値はすべて型 t の値なので、まるごと消えて空のスペースになりますね。
それ以外のケースでは 型スペースの分解 (compose) を使います。型 t の値は、「型 t のいずれかのコンストラクタの値」であるといえるので、型スペース T(t) はコンストラクタスペースのユニオンで書けます。例えば、
// 再掲
enum SortDirection {
Asc,
Desc,
}
enum SortOption {
Sort(SortDirection),
NoSort,
}
-
T(SortDirection)=T(Asc) | T(Desc)-
T(Asc)=K(Asc) -
T(Desc)=K(Desc)
-
-
T(SortOption)=T(Sort) | T(NoSort)-
T(Sort)=K(Sort; T(SortDirection))(*) -
T(NoSort)=K(NoSort)
-
のような感じです。(*) にあるように、分解してできたコンストラクタスペースの引数部分には、引数型の型スペースが来るように分解します。もし「最後まで」分解しようとすると、Binary 型のような再帰的な型で破綻するからです。
このように分解してユニオンの処理をすると、以下の「コンストラクタスペース同士の差」になり、差の計算を進められます。
型スペース同士の差
型スペース同士の差では、分かりやすいのは部分型 s の型スペースから上位型 t の型スペースを引くケースです (s <: t)。型 s の値はすべて型 t の値なので、まるごと消えて空のスペースになりますね。
それ以外のケースでは、やはり型スペースの分解です。
コンストラクタスペース同士の差
コンストラクタスペース同士の差では、まず両者のコンストラクタが異なるときは値の集合に重なりがないので、明らかに何も起きません。
両者のコンストラクタが一致するとします。引かれる方 (左) のコンストラクタスペースの引数を x1, ..., xN, 引く方 (右) のコンストラクタスペースの引数を y1, ..., yN とします。(型検査から、引数の個数は一致します。)
コンストラクタが一致するスペースの差は、論文では3つのケースを定めています。ただし、前の2つは基本的に3つ目のケースの「効率がいいバージョン」です。
- x1, ..., xN がいずれも y1, ..., yN の部分スペースの場合
- 3つ目のケースに当てはめて考えると分かりますが、空のスペースになります。
- x1, ..., xN のいずれかが y1, ..., yN と直交する場合
- (補足: これは試験実装ではまだ実装してません! x1, ..., xN のいずれかが空のスペースの場合に結果も空のスペースになる、という部分だけです。)
- 以下の通り。
例えば Binary 型の場合分けで Cons(Zero, Nil) のケースを書いたとします。このとき残るケースとしてありうるのは、Cons(b, bs) の「b が Zero でない」または「bs が Nil でない」ケースのどちらかです。
すなわちスペース K(Cons; b, bs) から スペース K(Cons; Zero, Nil) を引くと、
K(Cons; b - Zero, bs) | K(Cons; b, bs - Nil)
というユニオンになるはずです。これを一般化すると定義の通りです。
K(k; x1 - y1, x2 , ..., xN )
| K(k; x1 , x2 - y2, ..., xN )
...
| K(k; x1 , x2 , ..., xN - yN)
網羅されていないパターンの例示
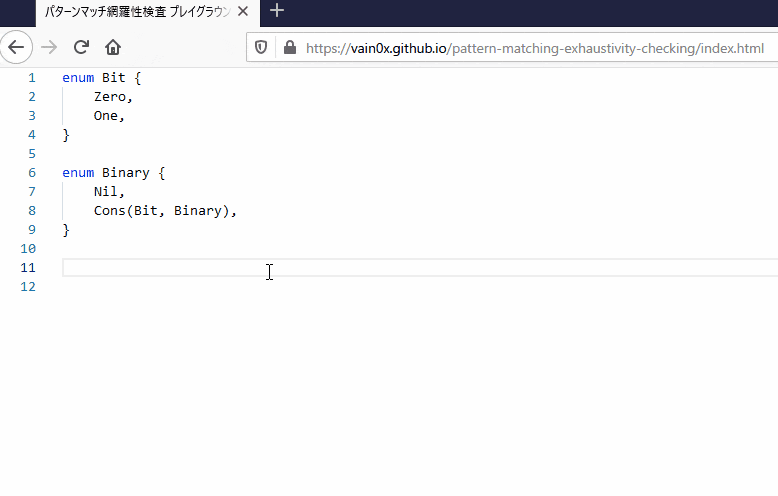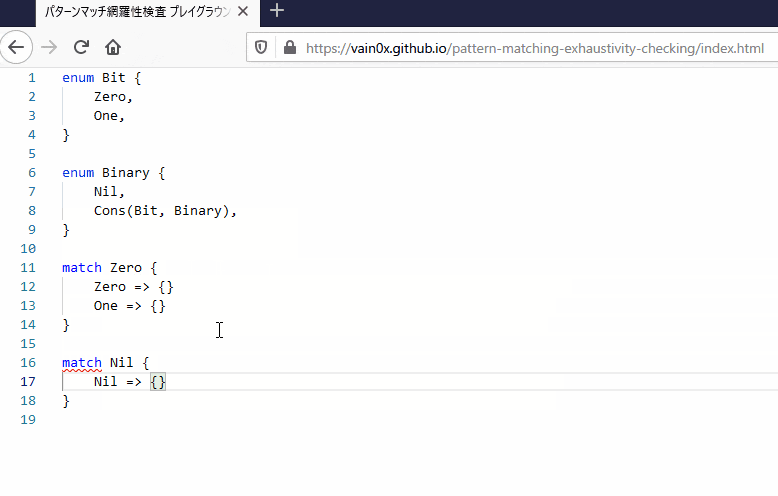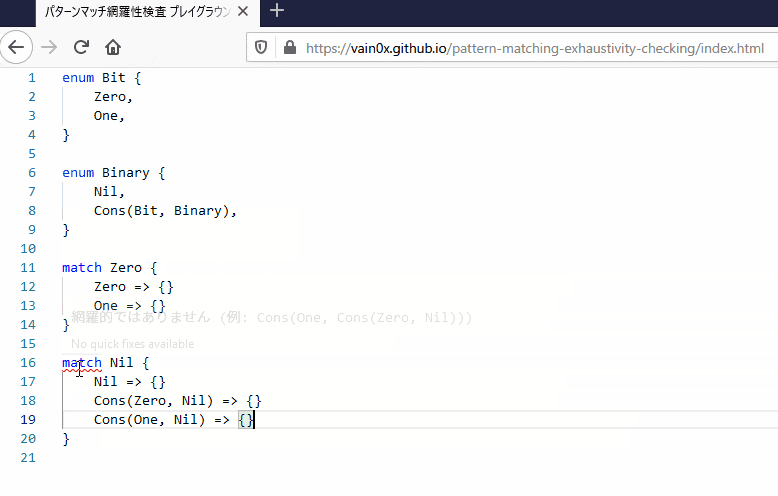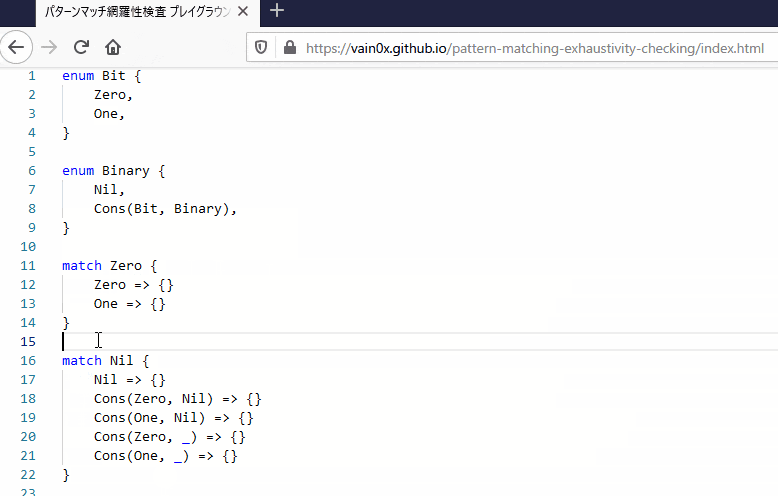
以上でパターンマッチの網羅性の検査ができることが分かりましたが、賢いコンパイラは網羅されていないパターンマッチに対して具体的に「このような値がどのパターンにもマッチしません」という具体例を挙げてきます。これも上記のアルゴリズムを使えば簡単にできて、型のスペースからパターンのスペースを引いて残ったスペースを基にパターンを1つ構築してやればよいです。
冗長なパターンの警告
パターンマッチに同じ分岐が複数含まれていると、基本的にはどちらかしか使われておらず、デッドコードとなってしまいます。賢いコンパイラはこれに警告を出してくれます。これもスペースを使うとできて、「前方のパターンからなるスペース」が後方のパターンのスペースを包含していたら冗長といえます。つまり、パターンマッチのパターン p1, p2, ..., pN に関して、
P(pK) ⊂ P(p1) | ... | P(p(K-1))
となるとき、pK は冗長です。
拡張性
本稿では話を絞るため enum 型のパターンマッチのみ取り上げました。実のところ、これだけならスペースを使わなくてもできます。スペースのよいところは拡張性で、型に部分型があったり、範囲パターンやスライスパターンなどの特殊なパターンにも対応可能なはずです。(注: とはいえまだ実装できてないんですが……)
終わりに
というわけで以上です。何らかの参考になったら幸いです。