Python3のcsvライブラリを使ってCSVファイルを読み書きする際,一般にはUTF-8(Unicode)が推奨されている模様.
しかしopen関数をそのまま利用した場合,CSVファイルの文字コードがUTF-8だと怒られる場合がある.
僕の環境ではShift-JISが正解で,文字コードを変えたら読んでくれた.
読み込みに使ったコード
CSVファイルの中身を読み取って,1行ずつ表示するだけ.
先頭行が紛らわしいが,ソースコードの文字コードをUTF-8と明示している.
readCSV.py
# -*- coding: utf-8 -*-
import csv
# with文:中の処理が終われば自動でclose処理も行う
with open('book1.csv', 'r') as f:
reader = csv.reader(f)
for row in reader:
print(row)
CSVファイル(Excel2016で作成)
book1.csv
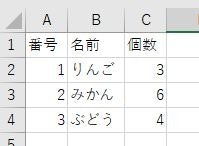
Excel2016でcsvを保存する時,選択する形式がCSV UTF-8(コンマ区切り)だとUnicodeテキストに,CSV(コンマ区切り)だとShift-JISになった.
UTF-8のCSVをPython3で読み込もうとすると怒られる.
UnicodeDecodeError: 'cp932' codec can't decode byte 0xef in position 0: illegal multibyte sequence
逆にShift-JISは読み込める.
['番号', '名前', '個数']
['1', 'りんご', '3']
['2', 'みかん', '6']
['3', 'ぶどう', '4']
文字コードに関する記述
公式には書いてあったが,具体例まで見ないとわかりにくい印象がある.
14.1.5. 使用例
open() が CSV ファイルの読み込みに使われるため、ファイルはデフォルトではシステムのデフォルトエンコーディングでユニコード文字列にデコードされます (locale.getpreferredencoding() を参照)。他のエンコーディングを用いてデコードするには、open の引数 encoding を設定して、以下のようにします:
import csv
with open('some.csv', newline='', encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
print(row)
恐らくこのデフォルトエンコーディングが原因で,僕の環境ではShift-JISだったということだろうか.
ドキュメントの通りにencoding='utf-8'を明示すると,UTF-8のCSVファイルも読んでくれた.