はじめに
これは徐々に高度になるリングバッファの話、をRustで試したの精神的続編です。
前回はリングバッファの実装によるパフォーマンスの違いを、x86の2つのCPUで見ました。このパフォーマンス比較はCPU毎の違いを見るという意味でも使えそうなので、JetsonOrinを使ってCPUの実装と最終的な命令の違いでどのような差になるか見ていきます。
三行で
- JetsonOrinのデフォルトではコンパイルオプション付いてない、つけると20%ぐらい改善する
- Rust v1.71.1 :
RUSTFLAGS=-C target-feature=+v8.2a,+a78,+rcpc,+dotprod,+ssbs - GCC v11.x :
-march=armv8.2-a -mtune=cortex-a78ae
- Rust v1.71.1 :
- 特にAtomic命令はRCscからRCpcにすることで大きな効果がある
- コードの最適化は実行するCPUによって違いがあるから、最後は仕様書を見て、ベンチマークを取って確かめるのが良い
本編
前回はIntelとAMDで比較をしました、ふるまいが違う理由を調べたかったのですが、CPU実装の情報がほとんどありません。
一方で、今回使うArmのコアは解説記事(A77)も多く、リファレンスや最適化ガイドを公式が配布しています。そのためベンチマークコードの挙動と、CPU実装の対応付けが取りやすいはずです。
ベンチマーク
RingBufferをベンチマークを使います。計算負荷は非常に軽く、メモリアクセスの順序依存性が強いプログラムです。これで性能が出るというのは大量の計算をさばけるかというよりも、小さなデータの移動のコストや、メモリ順序依存によるキャッシュミスや命令待ちによって大きく時間が変わります。
今回の使用機材はAGX Orin 開発者キットの50Wモード(mode 4 = CPU@1.5GHz)で、opt-level=2です。
Run R0S : 1000000000 ops in 3186 ms 313873 ops/ms
Run R1S : 1000000000 ops in 1244 ms 803858 ops/ms
Run R2S : 1000000000 ops in 11623 ms 86036 ops/ms
Run R2M (0,0): 1000000000 ops in 12500 ms 80000 ops/ms
Run R2M (0,1): 1000000000 ops in 67205 ms 14879 ops/ms
Run R2M (0,4): 1000000000 ops in 174899 ms 5717 ops/ms
Run R3S : 1000000000 ops in 4366 ms 229042 ops/ms
Run R3M (0,0): 1000000000 ops in 7730 ms 129366 ops/ms
Run R3M (0,1): 1000000000 ops in 10523 ms 95029 ops/ms
Run R3M (0,4): 1000000000 ops in 39550 ms 25284 ops/ms
前回のIntelのベンチマークを抜粋すると以下になります。
Run R1S : 1000000000 ops in 679 ms 1472754 ops/ms
Run R2S : 1000000000 ops in 780 ms 1282051 ops/ms
Run R2M (0,1): 1000000000 ops in 4043 ms 247341 ops/ms
Run R3S : 1000000000 ops in 694 ms 1440922 ops/ms
Run R3M (0,1): 1000000000 ops in 672 ms 1488095 ops/ms
このままだと比較しづらいので単位をcycle/itemに変えます。aarchは固定の1.497GHzで、Intelのテストは変動するので平均4.2GHzで動いたものと仮定すると以下のとおりです。
| Benchmark | Intel | A78AE |
|---|---|---|
| Run R1S | 2.8518 | 1.88 |
| Run R2S | 3.276 | 17.36 |
| Run R2M (0,1) | 16.9806 | 100.65 |
| Run R2M (0,4) | - | 271.65 |
| Run R3S | 2.9148 | 6.86 |
| Run R3M (0,1) | 2.8224 | 15.80 |
| Run R3M (0,4) | - | 54.10 |
RingBufferの実装に置いてはArmのほうがPEの充填率が良いのか平均1.8cycleで1loop分の処理が出来ています。これはIntelに対しておよそ70%のサイクルで処理できているのでCPUのクロック数が同じならArmのほうがスループットが良いようです。一方で、メモリ同期が伴うR2,R3の命令はサイクル数にほとんど変化のないIntelに対してArmでは顕著にクロック数が増えています。
AGX Orinは12CPU搭載しています。この内(0,1)と(0,4)の組み合わせをベンチマークを取りましたが、(0,4)のほうが明らかに遅いです。ArmのCPUコア間のメモリ共有はどうなっているのでしょうか?
Jetson OrinのCPUコア
Jetson OrinシリーズのCPUはArm® Cortex®-A78AEです。Armの解説によると自動運転等に利用可能なようにASIL規格を満たす仕様でSplit-Lock アーキテクチャを採用しているそうです。
ベンチマークに関係するところをざっくりいうと、DynamIQ Clusterの中に最大4つのコアが有り、メモリ、割り込み、電源制御、デバッグなどなどはこのClusterの境界が受けて、内部のCPUは抽象化されて見えているというのが特徴です。
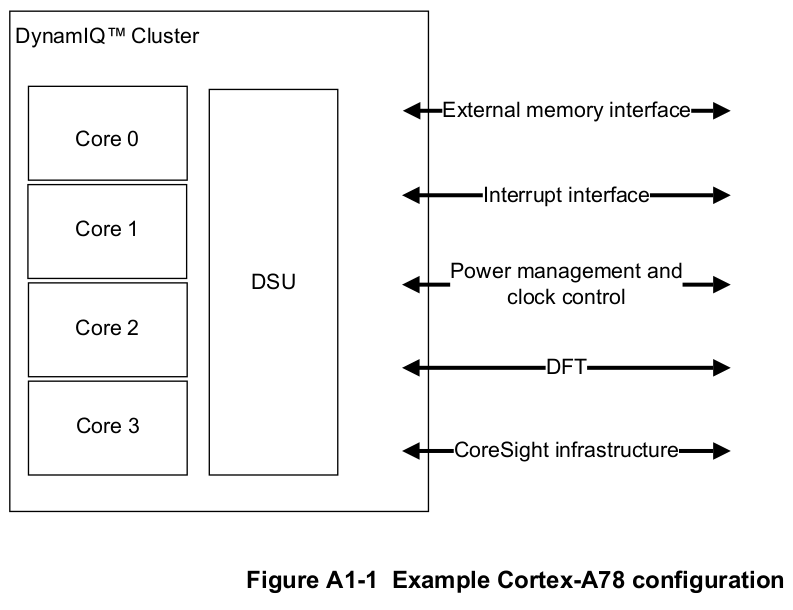
画像引用: Arm® Cortex®-A78 Core Technical Reference Manual Revision: r1p1
A78AEのコア間キャッシュ
CPUコア間のキャッシュの構造はどうなっているかは以下の図のとおりです。
CPU間でのメモリ同期については同じDSU内のCore間はDSUのL3を通じて共有、DSUより外にあるクラスタとはAMBA AXI Coherency Extension(ACE)プロトコルで同期をしています。
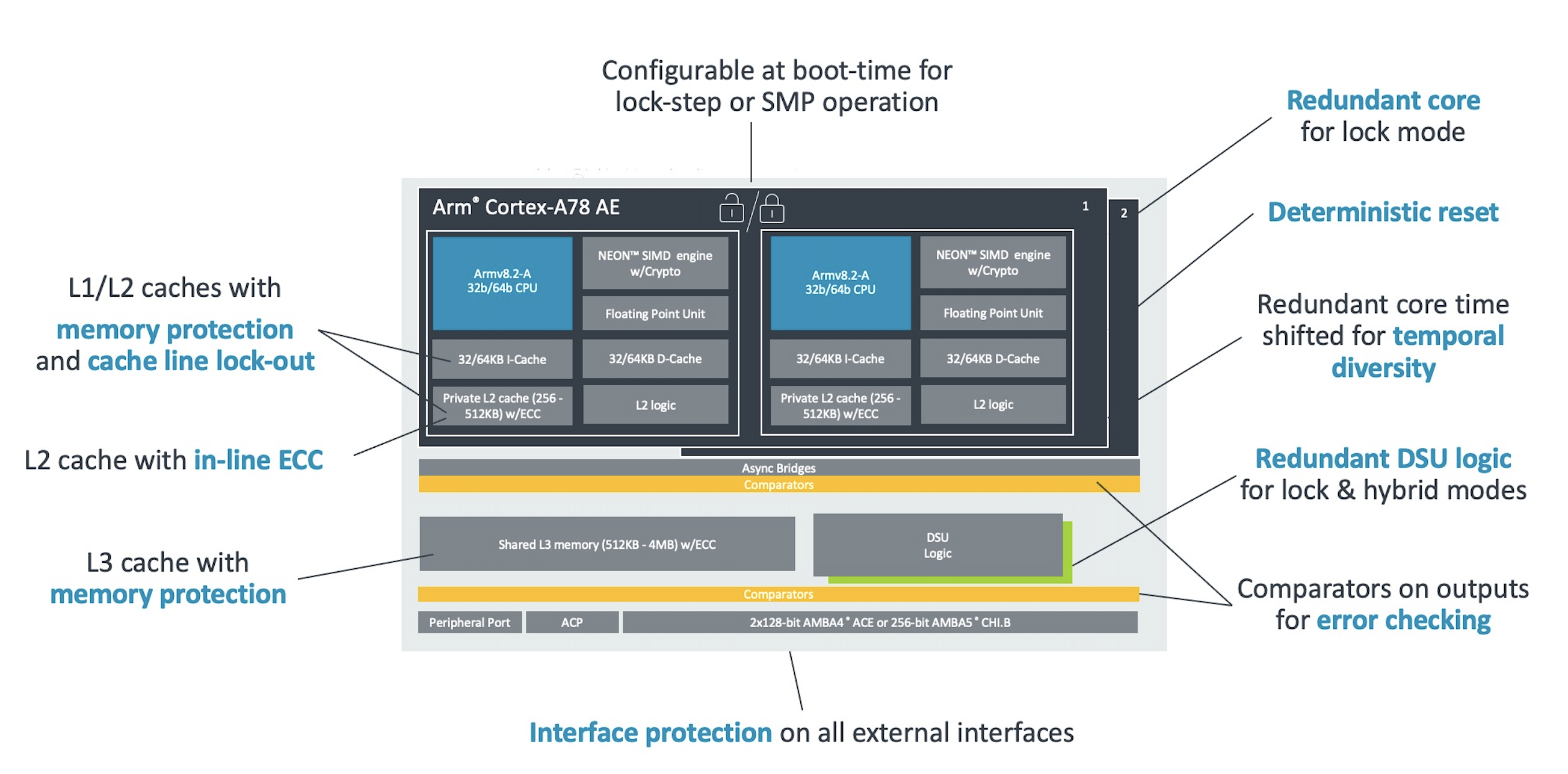
キャッシュレイテンシ
キャッシュ毎の読み出しにかかるレイテンシ一覧はすぐに見つけられなかったのですが、資料の中に出てくるいくつかの数字とベンチマークから推測すると以下のように予想されます。L1については最適化ガイドにあるLOAD命令のレイテンシ期待値4Cycleを採用しました。
- L1(PE cacheと見るのが良さそう): 4cycle
- L2(同一コア内): about 9 cycle
- L3(同一DSU内): about 25 cycle
- L4(DynamIQCluster間): about 100 cycle
CPUコア(0,4)の組み合わせは異なるDSUとのメモリ同期が必要になるためベンチマークでは非常に遅かったようです。このベンチマークではわかりませんが、通信帯域も取られるので高頻度なAtomic操作は同じDSU内のコアに割り当てるのが良さそうです。
さらなる最適化
ところで上記はopt-level = 2の結果です。3や更にバイナリを小さくするオプションもあるためそれらで性能は変化しないのでしょうか?
その他にも今回のバイナリは本当にA78AEに対して最適なバイナリになっているのでしょうか?
現状のtarget-feature
CPUには拡張命令を持つものが有り、Rustの場合はtarget-featureを通してその特定の命令が実行できることをコンパイラに伝えます。現在のtargetに対して利用可能なfeatureはrustc --print target-listで一覧の取得が出来ます。ArmのISAにもバージョンがあり、使える命令が変わり詳細はリファレンスマニュアルの他、実際に実装したメーカーの仕様書を見る必要が有ります。
コンパイル時にどのfeatureが有効になっているのか、一覧を出す方法はわからなかったのですが、stackoverflowに有効なfeatureをprintするマクロへのリンクを記載しているものが有りました。
これをもとに見てみると以下の1つだけのようです。
feature neon
A78AEの仕様書を見ると以下のようにArmv8.2-aの他一部のfeatureが利用可能であることがわかります。
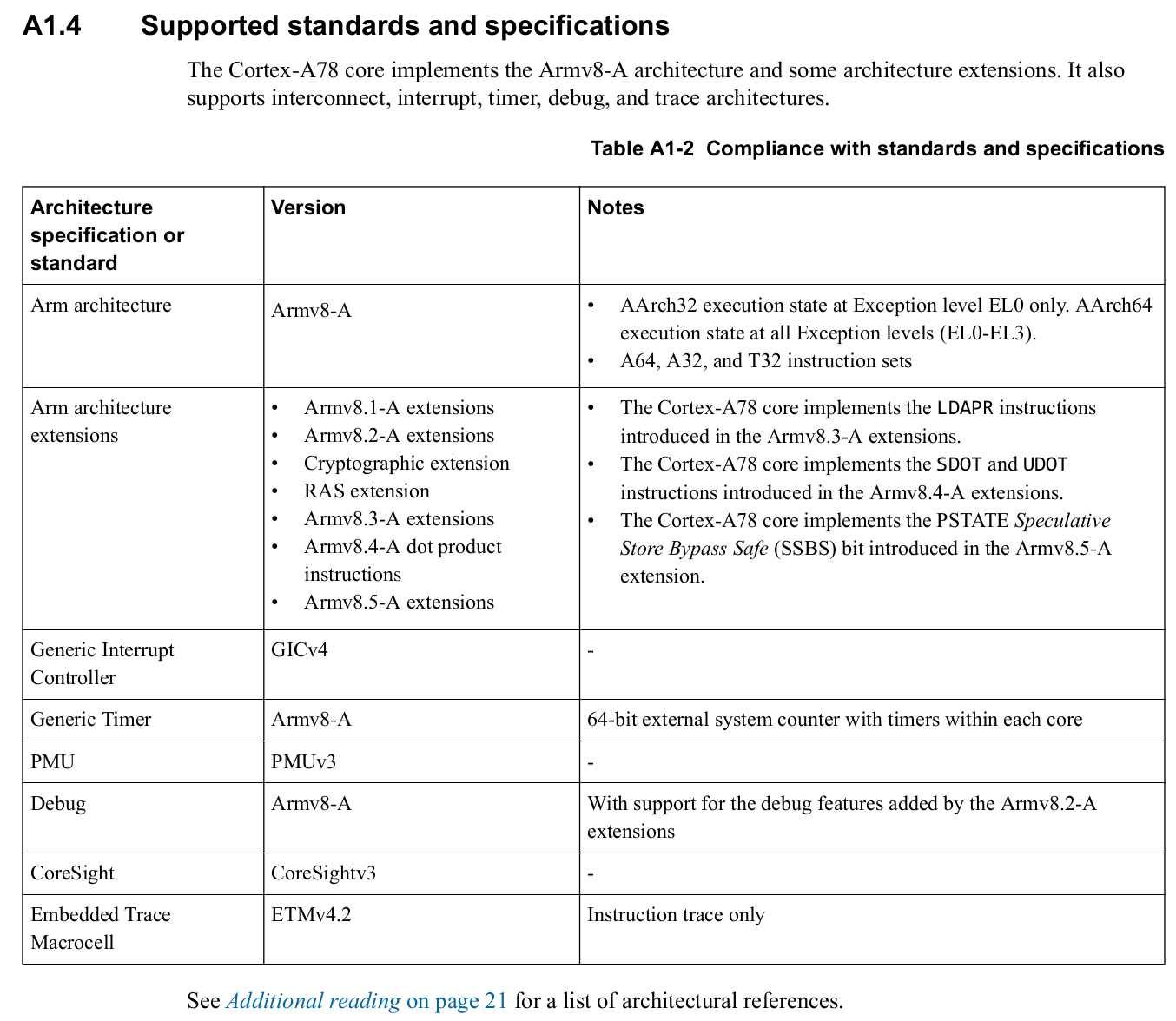
画像引用: Arm® Cortex®-A78 Core Technical Reference Manual Revision: r1p1
GCCやLLVMを観ても最適化オプションとしてCPU名を与えるものがありますが、Rust1.71.1時点ではa78aeの選択肢はありません。
ですが、上記featureは選択可能なリストにあるため個別に設定します。
A78AE向けのtarget feature
最終形が以下です。
RUSTFLAGS=-C target-feature=+v8.2a,+a78,+rcpc,+dotprod,+ssbs
v8.2aは後方互換なのでv8.1aで追加されたfeatureも追加されます。続けてa78自体はfeatureに影響はないもののLLVMのコンパイル時に考慮される項目となるようです。rcpcは特に大きな影響を持ちます。メモリ順序依存命令がRCscからRCpcとなり、ロードに関する順序依存性が緩和されます。dotprodは名前の通り、ssbsはサイドチャネル攻撃に対する対応でパフォーマンスにはマイナス効果です。必要ないなら入れなくても良いと思います。
aes - Enable AES support (FEAT_AES, FEAT_PMULL).
crc - Enable ARMv8 CRC-32 checksum instructions (FEAT_CRC32).
dpb - Enable v8.2 data Cache Clean to Point of Persistence (FEAT_DPB).
lor - Enables ARM v8.1 Limited Ordering Regions extension (FEAT_LOR).
lse - Enable ARMv8.1 Large System Extension (LSE) atomic instructions (FEAT_LSE).
neon - Enable Advanced SIMD instructions (FEAT_AdvSIMD).
pan - Enables ARM v8.1 Privileged Access-Never extension (FEAT_PAN).
ras - Enable ARMv8 Reliability, Availability and Serviceability Extensions (FEAT_RAS, FEAT_RASv1p1).
rdm - Enable ARMv8.1 Rounding Double Multiply Add/Subtract instructions (FEAT_RDM).
sha2 - Enable SHA1 and SHA256 support (FEAT_SHA1, FEAT_SHA256).
vh - Enables ARM v8.1 Virtual Host extension (FEAT_VHE).
rcpc - Enable support for RCPC extension (FEAT_LRCPC).
dotprod - Enable dot product support (FEAT_DotProd).
ssbs - Enable Speculative Store Bypass Safe bit (FEAT_SSBS, FEAT_SSBS2).
コンパイルオプションの選択肢
このほか性能に影響するのはコンパイルオプションです。前回は最適化レベル2で実験していましたが、3,s,zを選択をした場合にどのように性能が変わるかを見ます。このあたりの手順はまとめてMakefileに書きました。一部の結果だけを出します。
左2つはtarget-feature指定なし、w-で始まる右4つはtarget-feature指定有りです。
| filename | opt-2 | opt-3 | w-opt-2 | w-opt-s | w-opt-z | w-opt3 |
|---|---|---|---|---|---|---|
| Run R0S | 3186 | 3176 | 3212 | 3122 | 5072 | 3132 |
| Run R1S | 1244 | 1260 | 1163 | 1272 | 1373 | 844 |
| Run R2S | 11623 | 11762 | 4116 | 4158 | 3970 | 4088 |
| Run R2M (0,0) | 12500 | 12418 | 7692 | 7715 | 7668 | 7667 |
| Run R2M (0,1) | 67205 | 66964 | 10370 | 10353 | 11927 | 10344 |
| Run R2M (0,4) | 174899 | 181311 | 30220 | 37435 | 106220 | 35944 |
| Run R3S | 4366 | 4296 | 4436 | 4928 | 5010 | 4319 |
| Run R3M (0,0) | 7730 | 7708 | 7707 | 7751 | 7662 | 7747 |
| Run R3M (0,1) | 10523 | 10505 | 10530 | 3095 | 18002 | 10566 |
| Run R3M (0,4) | 39550 | 43383 | 39742 | 73369 | 64940 | 38234 |
| filesize | 629024 | 657696 | 641312 | 583968 | 579872 | 682272 |
注目してほしいところは太字にしました
まずはR1Sのパフォーマンスです。ここはメモリ同期のない素直で負荷の小さな計算のみです。ここは最適化によって実行時間が顕著に短くなりました。この後に示しますが、殆どがレジスタかL1キャッシュへのアクセスでバックエンドのアイドル率が非常に低くなっています。
次にRun R2S以降のw-opt-2です。+rcpcによってSTLRの命令の完了を待つことなく次のLDAPRが行えるためブランチミスの件数自体は変わらないものの、待ち時間がなくなったため、R3のキャッシュライン外しの工夫なしに同等のスループットになっています。
最後に今回のベンチマーク固有の特性と思われますが、Run R3M (0,1)のw-opt-sのスループットが異常に良いです。実際には、わずかにコードを変えたり、別のコアを使うだけでも再現が取れないため、メモリ同期命令のタイミングによって待ち時間が発生しないとかあるのではと疑っています。最適化s,zの平均性能を見ると、基本的には計算パフォーマンスを犠牲にサイズを圧縮しているので、本当に必要なとき以外は指定を避けるのが良いようです。
最適化オプション、target-feature指定の違いをperfで見る
Ringbuffer1
perfからopt2とopt3の違いを観てみます。
まずはOpt2のperfから
499,033,218 cache-references:u (39.84%)
42,812 cache-misses:u # 0.009 % of all cache refs (39.83%)
1,760,769,152 cycles:u (46.52%)
5,117,334,380 instructions:u # 2.90 insn per cycle
# 0.16 stalled cycles per insn (42.10%)
516,288 branch-misses:u (46.52%)
5,113,992,587 inst_retired:u (46.52%)
499,474,311 l1d_cache:u (46.68%)
0 l1d_cache_lmiss_rd:u (46.79%)
31,251,813 l2d_cache:u (46.79%)
3,796 l2d_cache_lmiss_rd:u (40.11%)
7,209,992 l3d_cache:u (40.11%)
3,614 l3d_cache_lmiss_rd:u (40.11%)
500,355,420 mem_access:u (39.95%)
2,032,498 stalled-cycles-frontend:u # 0.12% frontend cycles idle (34.72%)
822,658,449 stalled-cycles-backend:u # 46.63% backend cycles idle (34.72%)
続いてopt3
505,464,758 cache-references:u (38.08%)
25,465 cache-misses:u # 0.005 % of all cache refs (38.71%)
1,234,075,312 cycles:u (45.63%)
6,230,990,996 instructions:u # 5.05 insn per cycle
# 0.05 stalled cycles per insn (46.26%)
1,022,548 branch-misses:u (46.89%)
6,189,362,457 inst_retired:u (47.52%)
493,656,662 l1d_cache:u (48.15%)
0 l1d_cache_lmiss_rd:u (48.49%)
31,043,045 l2d_cache:u (48.48%)
4,729 l2d_cache_lmiss_rd:u (41.15%)
5,215,670 l3d_cache:u (40.52%)
7,724 l3d_cache_lmiss_rd:u (39.89%)
505,998,903 mem_access:u (39.26%)
4,333,485 stalled-cycles-frontend:u # 0.35% frontend cycles idle (38.63%)
313,439,605 stalled-cycles-backend:u # 25.40% backend cycles idle (38.00%)
最適化レベルを上げることによって、実行されるオペレーション数字帯は増えるものの計算にかかったサイクル自体は減っています。insn per cycleは5.05となっており、バックエンドのuOPSを最も効率よく埋めるための命令を構築しているのだと思われます。同時に動かすプログラム次第ではopt2のほうが最終的な実行効率が良くなる可能性もありそうです。
RingBuffer2(RCsc)実装
続いて+rcpcがない場合のperfです。キャッシュミス率が高いほか、バックエンドの利用効率も悪いです。メモリアクセスが多いので、データが届かずにバックエンドがストールしていると言えそうです。
6,013,511,689 cache-references:u (39.88%)
31,337,849 cache-misses:u # 0.521 % of all cache refs (39.88%)
17,373,609,617 cycles:u (46.56%)
13,756,171,280 instructions:u # 0.79 insn per cycle
# 0.99 stalled cycles per insn (41.19%)
519,428 branch-misses:u (46.65%)
13,757,059,908 inst_retired:u (46.70%)
6,014,911,820 l1d_cache:u (46.74%)
72,685 l1d_cache_lmiss_rd:u (46.76%)
62,699,422 l2d_cache:u (46.76%)
749,572 l2d_cache_lmiss_rd:u (40.08%)
61,892,434 l3d_cache:u (40.08%)
28,171,313 l3d_cache_lmiss_rd:u (40.03%)
6,014,325,413 mem_access:u (39.90%)
5,369,901 stalled-cycles-frontend:u # 0.03% frontend cycles idle (35.18%)
13,601,113,967 stalled-cycles-backend:u # 78.33% backend cycles idle (35.18%)
RingBuffer2(RCpc)実装
命令数やキャッシュへのアクセス数はRCscとほとんど変わりません。しかしこちらは同期ロード命令が同期ストアを待たずに途切れずに実行されるため実際にかかるサイクル数は短くなっています。
6,016,034,644 cache-references:u (39.90%)
31,327,462 cache-misses:u # 0.521 % of all cache refs (40.03%)
6,064,666,054 cycles:u (46.79%)
13,744,255,642 instructions:u # 2.27 insn per cycle
# 0.22 stalled cycles per insn (41.47%)
526,838 branch-misses:u (41.47%)
13,741,736,372 inst_retired:u (46.97%)
6,013,460,106 l1d_cache:u (46.97%)
73,516 l1d_cache_lmiss_rd:u (46.84%)
62,720,317 l2d_cache:u (46.71%)
517,215 l2d_cache_lmiss_rd:u (39.82%)
62,156,210 l3d_cache:u (39.78%)
26,619,628 l3d_cache_lmiss_rd:u (39.78%)
6,023,377,429 mem_access:u (39.77%)
11,428,618 stalled-cycles-frontend:u # 0.19% frontend cycles idle (35.12%)
3,028,143,880 stalled-cycles-backend:u # 49.97% backend cycles idle (35.12%)
アセンブリ命令比較
+rcpcでアセンブリがどう違うかをcargo asmで見てみます。
ベンチマークのコードはcargo asmでうまく指定できないため、別途切り出したコードです。名前が多少違いますが基本的に生成されるものは同じはずです。
以下の通り、read_idxの読み出しと書き出しに同期命令ldar, stlrが使われています。
RCpcのコードを見ると他の命令に変化はなくldaprに置き換わっているだけというのがわかります。
RingBuffer2(RCsc)::enqueue
<ringbuf::r2::Buffer as ringbuf::helper::RingBufTrait<usize>>::enqueue:
add x9, x0, #32 ; read_idx位置
ldr x8, [x0, #24] ; write_idx 読み出し
ldar x9, [x9] ; read_idx同期読み出し
ldr x10, [x0, #8] ; capacity読み出し
add x9, x10, x9 ; write + cap位置
cmp x9, x8
b.ls .LBB12_2
ldr x10, [x0, #16] ; capacity読み出し
add x12, x8, #1 ; cap計算
add x13, x0, #24 ; write_idx更新
ldr x11, [x0] ; buf位置
sub x10, x10, #1 ;
and x10, x10, x8 ; pos計算
str x1, [x11, x10, lsl, #3] ; buf書き出し
stlr x12, [x13] ; write_idx書き出し
.LBB12_2:
cmp x9, x8
cset w0, hi ; cap無し時
ret
RingBuffer2(RCpc)::enqueue
<ringbuf::r2::Buffer as ringbuf::helper::RingBufTrait<usize>>::enqueue:
add x9, x0, #32
ldr x8, [x0, #24]
ldapr x9, [x9] ; RCpc命令
ldr x10, [x0, #8]
add x9, x10, x9
cmp x9, x8
b.ls .LBB12_2
ldr x10, [x0, #16]
add x12, x8, #1
add x13, x0, #24
ldr x11, [x0]
sub x10, x10, #1
and x10, x10, x8
str x1, [x11, x10, lsl, #3]
stlr x12, [x13]
.LBB12_2:
cmp x9, x8
cset w0, hi
ret
まとめ
RingBufferのコードとベンチマークを通してJetsonOrinのCPUの構造とその性能の特性を見てきました。今回のようなシンプルな操作の場合最適化オプションや命令の一つ一つの待ち時間が顕著にベンチマークに影響してくるのがわかりました。特にアトミック変数はCPUの実装と使える命令によってコード実装の有効性が変わってくるため、実際に使うプラットフォームでのベンチマークはとても大切です。
x86の場合は特に気にしなくても自然とtarget-featureをつけてくれるのですが、Armではバリエーションが多いためか明示的に指定しないとgenericなバイナリが作られます。性能が重要な場合はtarget-featureの設定をお忘れなく。またGCCにも同様のオプションがありますが-mtune=cortex-a78aeが指定できるのはGCC11.xとなります。L4T35.xはUbuntu20でGCC9.xでこのオプションが指定できません。自前でコンパイルするか、Jetpack6でUbuntu22ベースとなってバージョンが上がるのを待つのが良さそうです。
これらのコードはGitHubに置いてあります。