はじめに
SIerで働いてます。周りを見渡すとまだまだオンプレだけのシステムが多いですね。
少し前はクラウドは選択肢にすら入ってきませんでしたが、今はどんなに固いシステムでも必ずクラウドが選択肢に入ってくるようになりました。そして、この1~2年くらいはクラウド、特にAWSを利用したシステムの構築案件が増えてきたなぁと実感しています。
社内の人と話していても、「AWSなにそれ?」とか「AWS安くなるらしいから使おうよ。」という人もさすがに減ってきて、オンプレ脳から徐々にクラウド脳にシフトしていってるのかなと感じます。
この記事は、社内のAWSのイベントでLTで話した内容をベースに書いています。ただSWFについてはマニアックなので避けました。少しでも若手や興味を持っていただいた方の勉強になればと思いまして、その考えに至った背景などをかなり寄り道しながらできるだけやさしく書いてみました。
なぜ自動化するのか?
提案~開発~移行展開を通じて、どのフェーズでもいつも話題になるのがシステムの保守運用です。機器はいつか壊れるし、人が作業すればミスも起こりますので、障害が起きた場合には障害が起きる前の状態に戻す活動をするわけです。
戻す活動をするには、事前にデータのバックアップやOSのイメージを取っておいたり、障害を検知するために継続的にデータを取ったりします。また、そもそも障害が起きてもある程度自動で復旧する仕組みを作ったりもします。
このような活動は、とにかく確実に動くことがポイントになります。毎度確実に動かすには、人の手は介在させずスクリプトなどで自動化させるのは自然な流れですよね。
いつ自動化するのか?
運用開始後に自動化を検討するのは、基本的に1お勧めしません。
また、AWSの場合は自動化できる範囲が広い為、要件定義時にPoC(Proof of Concept)の期間をとっておくとベターです。
では、オンプレミスとAWSの保守運用作業にはどんな違いがあるのでしょうか?
オンプレミスとAWSの保守運用作業の違い
オンプレミスではバックアップや監視、データの取得などを行いますよね。AWSでもオンプレミスと同じ観点があります。
オンプレミス同様、AWSでも必要な運用(例)
- ディスクのバックアップ/遠隔地コピー
- EBSのSnapshotを取得し、世代管理を行う
- EBSのSnapshotを別リージョンにコピー(遠隔にバックアップ)
- OSイメージの取得
- AMIを取得し、世代管理を行う
- コマンドの実行
- DBのオンラインバックアップの実行
- パフォーマンスデータを取得する
一方AWSではサービスに合わせた運用という観点やサービスが従量課金になるためコスト効率を良くするための運用を考える必要が出てきます。
AWSならではの運用(例)
- オートスケーリング・スケールイン時の監視設定
- 未使用期間インスタンスを停止しておくことで利用料金を削減する
- AMI登録解除時にEBS Snapshotを合わせて削除する(自動で削除されないため)
- SESのメトリクスを定期的に取得しCloudWatchメトリクスに追加し監視する
- 利用料金を定期的にメール/Slackに通知する
オンプレミスでは運用は基本的にシェルスクリプト、バッチファイル、powershellなどを使って自動化してきたと思います。AWSではどのように実現するのでしょうか?
AWSで保守運用作業をスクリプト化するには?
AWS上のリソースを参照、更新、削除する処理は全てWEB API化されています。私たちはWEB APIを直接叩く必要はなくcliやSDKを使ってプログラマブルに実現することができます。
SDKはJava、.Net、Node、PHP、Python、Ruby、Go、C++に対応しています。
例えばAWSのcliやSDK for Javaを使ってAMIの取得は以下のように行います。
aws ec2 create-image --instance-id i-1234567890abcdef0 --name "JenkinsServerImage" --description "An AMI for Jenkins"
Future<CreateImageResult> result = client
.createImageAsync(new CreateImageRequest("i-1234567890abcdef0", "JenkinsServerImage"));
これらを、とあるサーバのcronなどに仕込んでおけば定期的に動かすことができそうですね。
どのサーバでスクリプトを動かせば良いのか。
自動化する処理をcliやSDKで書けるのはわかりましたが、どのサーバで動かしたらよいでしょうか?
問題点1 サービスレベル混ぜるな危険
例えば、踏み台サーバがあるからついでにそのサーバでバックアップなどのスクリプトを動かせばいいんじゃないか。と思うかもしれませんが。これは大きな間違いですね。
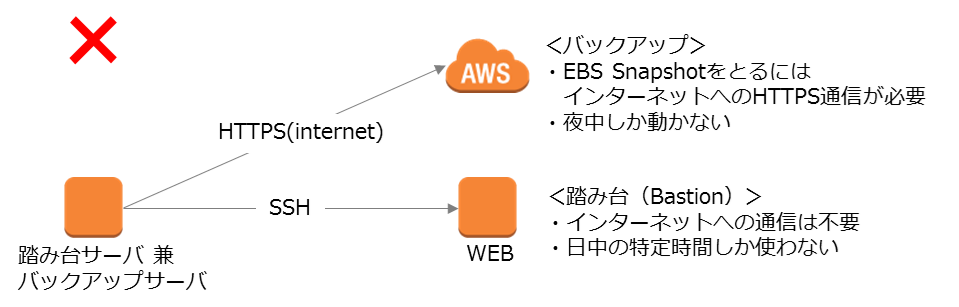
パブリッククラウドにおいて踏み台サーバは唯一インターネットや拠点から直接SSH/RDPがつながるサーバになるはずなので、セキュリティに特に気を配る必要があります。
ポートに制約を設けるのは当たり前ですが、可能であれば使うときだけ踏み台サーバを起動しておくと本当はベストですね。使うときだけ起動すると、オンデマンドインスタンスのコスト削減にも副次的に貢献します。
踏み台サーバにつなげるのは運用作業のタイミングでしょう。また、バックアップ場合、OSのディスクへのI/Oを止めたい場合などがありますので、動かしたいのは運用していない時間帯でしょう。ここにサービスレベルのミスマッチが存在します。
**EC2を止めたいときに止められない。CPU、メモリ、ディスクなどの見積もりが正確にできない。何が入っているかわからないAMIができあがる。など弊害ばかりです。**つまり踏み台サーバに踏み台以外の機能を持たせてはいけないのです。
**「サービスレベル混ぜるな危険(同じサーバに違う性能、可用性が異なる機能を持たせてはいけない。)」**はこの話に限らず、何にでも言える話ですね。
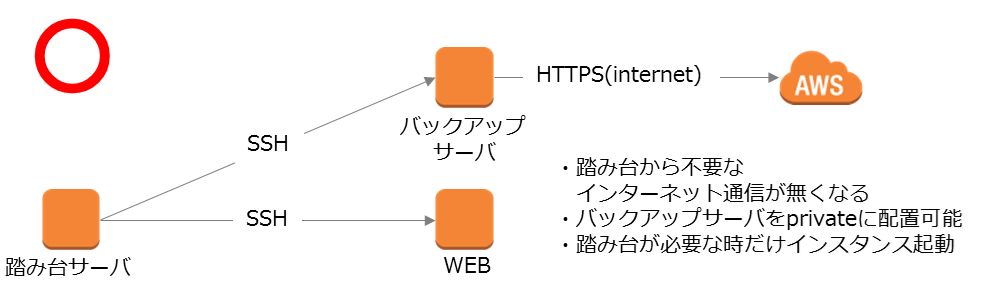
また、コストを気にして1つのサーバにサービスレベルが違う機能を持たせることを検討するかもしれません。これも大きな間違いです。
**役割や、求められるパフォーマンスに合わせたインスタンスタイプを選択することでトータルのコストはほとんど変わらないはずです。**また、役割を分けることでスケールアウトする戦略も立てやすくなるはずです。
問題点2 アクセスキー・シークレットアクセスキーは極力使用しない
問題点1における検討の結果、スクリプトを動かすためのサーバは踏み台サーバなどとは別に構築することにしました。
さて、オンプレミスとAWSのVPCがDirectConnectで繋がっているので、オンプレミス側のサーバを使ってスクリプトを動かそうと思うかもしれません。ここにも問題があります。
cli/SDKを利用するには、アクセスキーとシークレットアクセスキーを利用する必要があります。つまり、AWSのcli/SDKを利用するにはオンプレミス側のサーバでアクセスキーを取り扱う必要があります。
ここで考えてほしいのは、アクセスキーとシークレットアクセスキーは漏えいしてしまうと恐ろしい目にあうということです。いや、ほんとに。
- 反面教師としてお読みください
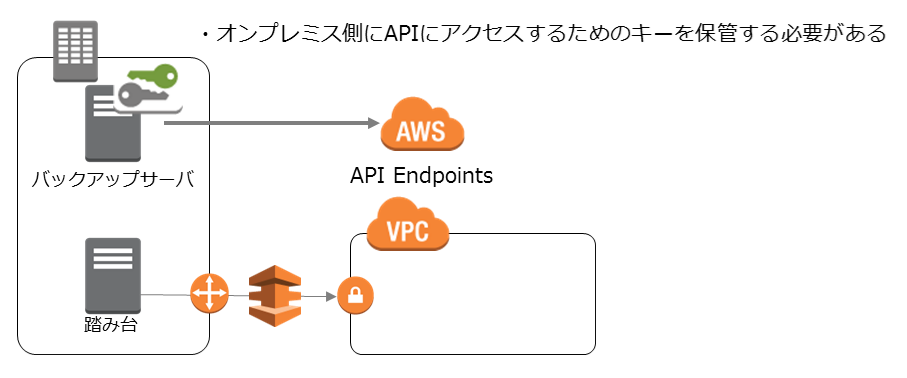
定期的にアクセスキーをローテーションすればいいのでは?と考えるかもしれません。
そもそもキーのローテーションは本質的な解決策ではありませんし、入れ替えの時にコピペなどでミスしてたらスクリプトで行った自動化処理が全部失敗するという逆に恐ろしい目にあうかもしれません。
じゃあ、入れ替えのたびにテストするのか?といわれると、なんのための自動化なのかわからなくなります。
ということで、**「アクセスキーは開発で利用するときは最小限の権限で利用し、本番では極力利用しない。」**がよいと思います。
さて、どうするかというとアクセスキーの代わりにEC2にロールを振ることで実現できます。
ロールが振られたEC2で動くスクリプトはアクセスキーとシークレットアクセスキーをハードコーディングせずに一時的な認証情報を取得して実行することができます。
EC2にロールを付与するタイミングはインスタンスを作る時だけです。結果的に使わなくても良いので、サーバの役割ごとにロール作って、EC2に付与しておいた方がよいでしょう。
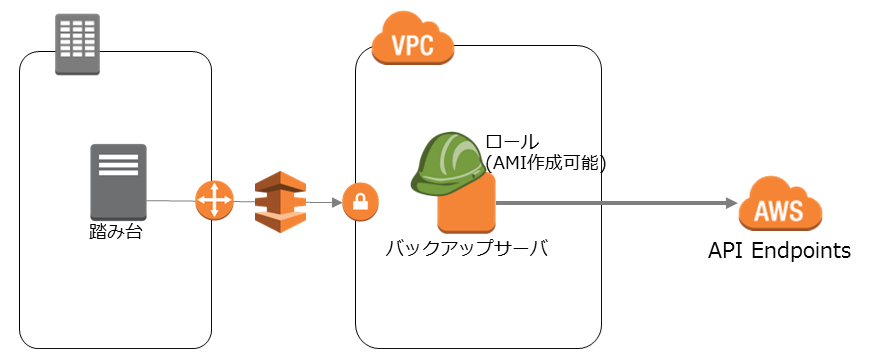
この一時的な認証情報を取得するサービスをAWSではSTS(SecurityTokenService)と呼んでいます。応用範囲も広いので覚えておいて損はありません。
問題点3 ダウンタイムを許容できない
問題点2における検討の結果、スクリプト実行に必要な権限が定義されたロールをEC2に付与し、そのEC2でスクリプトをcronで起動し、バックアップ等の処理を実行することにしました。
これではまだ不十分です。**EC2もただの仮想サーバなのでOSがハングアップすることもあれば、VM自体が動いている物理サーバが故障することもあります。ここで大事なのは、故障のための設計(Design for Failure)**です。
WebServer1台構成で10分程度のダウンタイムが許容されるのであればAutoRecoveryやAutoHealingを設定しておけばよいでしょう。
| 種類 | 説明 |
|---|---|
| AutoRecovery | CloudWatchアラームに付属する機能の一つで、EC2インスタンスが動作しているハードウェアに障害が発生した場合に復旧させることができる機能。IP、インスタンスID、ElasticIPアドレス、ボリュームのマウントなどは維持される。 |
| AutoHealing | AutoScalingのdesired-capacityのminを1、maxを1にすることでいつも1台起動しておくように設定できる。ダウンしてからAMIをベースに起動するまで5分くらい。AMIからインスタンスを作り直すのでPrivateIPなどが変わることや、インスタンス自体をイミュータブルにするか、起動時にCloud-initなどで自動構築しておく必要がある。 |
こうしておけばハード面の故障でもソフト面(プロセスが落ちたとか)の障害でも対応することができます。
ただし、今回はバックアップ処理などを動かすサーバです。cronが動くタイミングでバックアップサーバが落ちてたらバックアップは取得できなくなってしまいます。
ということで、稼働率99%が求められるシステムでも、運用を自動化するためのスクリプトを動かすサーバはダウンタイムが許容されないということになりそうですね。
さてどうしましょう。
サーバを使わない(サーバーレス)という選択肢
ポイントは**「必要なタイミングで処理を動かす」**ことです。
サーバを常に動かしておき、スクリプトを定期的に動かすと可用性について考えなければいけませんが、必要なタイミングで誰かが処理を動かせば可用性についての懸念が消えます。
いわゆるコレオグラフィなアーキテクチャで運用自動化ができればよいわけです。
余談ですがコレオグラフィについてはマイクロサービスアーキテクチャの「4.5.オーケストレーションとコレオグラフィ」を読んでみてください

必要なタイミングで処理を動かすことができるサービスがAWSにはあります。
Lambda
Java、Python、Nodeのいずれかで処理を書いて、デプロイしておくと必要なタイミングでAWSがコンテナにデプロイして実行してくれるサービスです。Lambda単体では起動2できず、イベントがトリガーになって動くサービスとなります。
-
イベントソースの例
- API Gateway
- S3
- Kinesis
- DynamoDB Streams
- Cognito
- SNS
- CloudWatchEvents
-
参考
CloudWatch Events
CloudWatchEventsはAWS内で起こるイベントを検知してターゲットを動かすサービスです。Lambdaもターゲットとして動きます。たとえば、インスタンスが起動したタイミングでメール通知する。などが実現できます。
-
検知できるタイミング(例)
- インスタンスが起動・停止、pendingなどの状態
- 特定の時間(スケジュール)
- オートスケール
- API Call(ほとんどのリソース操作に対応)
-
ターゲット(例)
- Lambda Function
- SNS
- SQS
-
参考
具体例
このLambda+CloudWatchを組み合わせるとかなりのことが実現できます。2つくらい例を見ていきましょう。
AMI登録解除時に紐付くEBS Snapshotを削除する
AMI(AmazonMachinImage)にはEBS(ディスク)のSnapshotが紐付いています。ただし、管理コンソールからAMIの登録解除を行っても、EBSのSnapshotは削除されません。
AMIが登録解除になったタイミングでEBS Snapshotを削除できれば消し忘れを防止することができます。こんな感じで実現します。
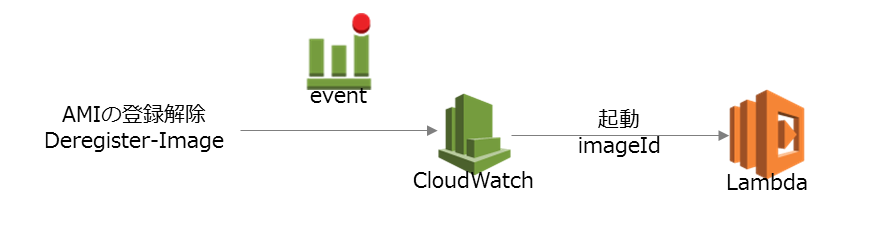
| 手順 | 説明 |
|---|---|
| 1. | AMIの登録解除イベントをCloudWatchEventsが拾う |
| 2. | CloudWatchEventsは削除されたAMIのID(imageId)をjson形式でLambdaに渡す |
| 3. | LambdaではAMIのIDに紐付くEBS Snapshotを削除する。 |
ソースコードはこちらにあります。- DeregisterImageFunction.java
AMIを取得して、世代管理を行う
今度は少し難しくなります。
cronではAMI作成のリクエストを投げて終わりですが、通常のバックアップ処理では世代管理することが求められると思います。
これはこんなアーキテクチャで自動化することができます。
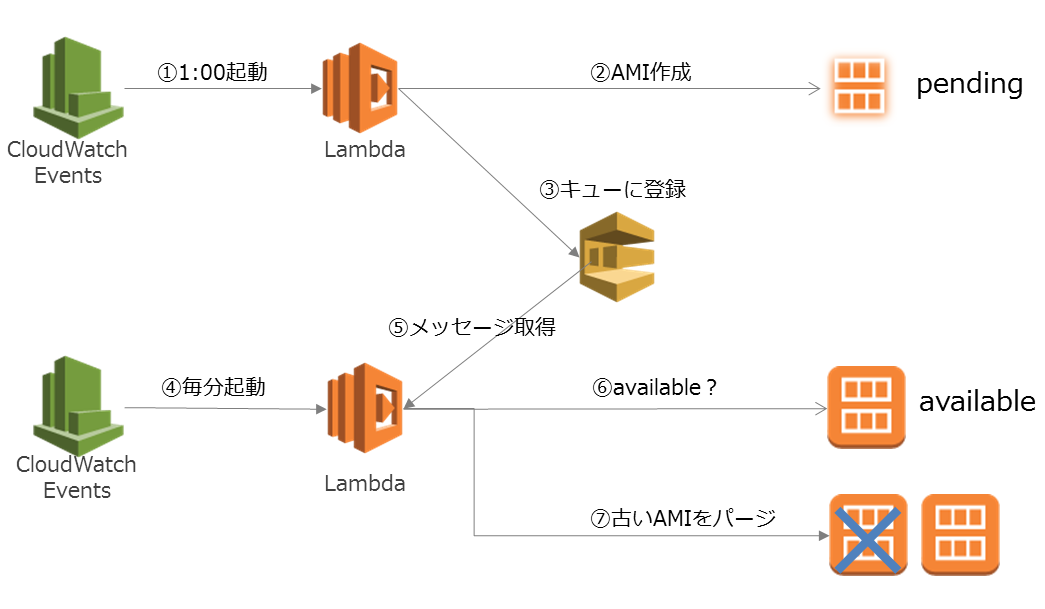
| 手順 | 説明 |
|---|---|
| 1. | CloudWatchEvents Scheduleで毎日1時に起動するように設定しておく |
| 2. | 1時のタイミングでCloudWatchEventsがLambdaを起動する(この時インスタンスIDと世代数を渡す) |
| 3. | LambdaはAMIの作成リクエストを投げるのと同時に、SQSに対して、AMI作成リクエストを投げた旨通知する |
| 4. | CloudWatchEvents経由でLambdaを毎分起動しておく。 |
| 5. | LambdaではSQSにメッセージが入っていないかを確認する |
| 6. | AMIの状態がavailableになっているかの状態を確認する。availableじゃない場合、AMIの作成が完了していないのでSQSにメッセージを戻す。 |
| 7. | AMIの状態がavailableになっている場合、指定された世代数だけ残し古いAMIをパージする。 |
ソースの内容や設定方法に関しては、Github-uzrek/aws-auto-operations-using-lambda/create-imageを参考にしてみてください。
運用をサーバーレスにするメリット
ほとんど無料枠内で収まりますので、とにかく安いです。
安いと何かを犠牲にするものですが、何も犠牲にしていないどころかスケーラブルなのが素晴らしいのです。
ちなみに私が運用しているアカウントだと先月は$2です。無料枠から足がでるのはDynamoDBくらいですね。
今回使っているサービスの料金・無料枠はそれぞれこんな感じです(2016年12月8日現在)
| サービス | 料金・無料枠 |
|---|---|
| CloudWatch Events | 100万カスタムイベントで$1 |
| Lambda | 利用料金はこちら、1 か月に 1,000,000 件の無料リクエストおよび 400,000 GB-秒のコンピューティング時間は無料 |
| IAM | 無料 |
| SQS | 利用料金はこちら、毎月 AmazonSQS リクエストを 100 万件まで無料 |
| DynamoDB | 利用料金はこちら、25 GB の無料ストレージに加え、最大 25 の書き込み容量ユニットおよび 25 の読み込み容量ユニットのスループット容量(毎月 2 億件のリクエストを十分に処理できるスループット)、および DynamoDB ストリームからの 250 万回の読み込みリクエストを無料 |
導入にむけて
aws-operation-using-lambda
良く利用するものは作ってありますので良ければご利用ください。AMI作成は3AWSアカウントで20台くらい運用している実績があります。
別件で作っていた既存資産があったのでJavaで作っています。JavaはPython、Nodeより立ち上がりが遅いので、ちょっとした処理はPythonを使った方がよいでしょう。逆にグルグル長い時間ぶん回すならJavaがよさそうだなと感じています。
Github-uzresk/aws-auto-operations-using-lambda
| タスク | 説明 |
|---|---|
| Instance Start/Stop | インスタンスの起動・停止を行います。また、インスタンスが所定時間内に起動/停止できたかのチェックを行うことができます。 |
| EBS Snapshot | VolumeIdやタグ名をキーにEBSのSnapshotの取得と世代管理を行います。 |
| Create Image(AMI) | インスタンスIDをキーにAMIの取得と世代管理を行います。 |
| EBS Copy Snapshot | SnapshotIDをキーにEBSのSnapshotのリージョン間コピーとコピーされたSnapshotの世代管理を行います。 |
| DeregisterImage | AMIが登録解除されたタイミングで、AMIに紐付くEBSSnapshotの削除を行います |
| RunCommand | AWS SSMを使ってOSに対して定期的にコマンドの実行を行うことができます。 |
導入の自動化
AWSのサービスをたくさん利用すると、設定がめんどくさいのが難点です。
例えばAMIの作成と世代管理を行うのも、これだけの設定が必要です。
- IAM Roleの作成、ポリシー付与
- LambdaFunctionの作成×2
- DynamoDBのテーブル作成
- CloudWatchEventsの設定×2
- Lambdaへのパーミッションの設定
これももちろん自動構築できるようにしてあります。TerraFormでもできますが、今回記事を書くタイミングでansible2.2.0.03 が出ていましたので使ってみました。
今日現在ansible2.2はepel-testingにも入っていないのでpipでインストールする必要があります。他にもboto、boto3、aws cliをインストールする必要があります。面倒な人はインストール済のDockerImageをDockerhubから取得してを使ってください。
Docker Image uzresk/centos7-ansible-serverspec
こんな流れで使います。
1 ansibleの環境一式を入手し、コンテナに接続する
docker run -it --name tmp uzresk/centos7-ansible-serverspec:ansible-v2.2.0.0-1 /bin/bash --login
2 アクセスキー・シークレットアクセスキーの設定をする。
3 deploy用スクリプトを取得
wget https://github.com/uzresk/aws-auto-operations-using-lambda/releases/download/0.0.1/deploy-playbook.zip
4 ansibleのvarsに設定を行う
5 実行する
ansible-playbook create-image/main.yml
詳しくはGithub-uzrek/aws-auto-operations-using-lambda/deploy-playbookをどうぞ。
まとめ
安心して運用できる基盤を用意して、年末年始は家族とゆっくり過ごしましょう。
- サービスレベルは混ぜてはいけない。
- アクセスキーは開発では最小限の権限で利用し、本番では極力利用しない。
- 運用自動化するときはまずサーバーレスにできないかを考える。
パターン、アンチパターンはこのほかにもたくさんあります。
ストックが伸びて気が向いたら、続編をお届けしたいと思います。
あとがき
Lambdaをきっかけに広がるコレオグラフィなアーキテクチャ
Lambdaなどは無敵ではないのですが、アプリな人でもインフラな人でもちょっと使えるようになっておくと、思考の幅が広がりますので押さえておいて損はないと思います。
先日のre:InventではLambda自体の機能強化やLambdaを使った新サービスが発表されました。たとえばStep Functionを使えばワークフローをサーバレスに実行することができます。(SWFではワーカーをサーバーレスにはできなかった)
CloudWatchEventsは続々とイベントソースが増えています。つい先日もEBS SnapshotにCloudWatchEventが追加されました。
今後もCloudWatch Eventsに対応するサービスはますます増えてくるでしょう。今はAPIがコールされたことの検知がメインになっていますが、APIコール後にリソースの状態が変わってくるものがあります。リソースの状態を検知できると先ほど出したアーキテクチャもよりシンプルになるはずです。楽しみですね。
日々運用のちょっとした作業はLambdaと相性が良い気がしていて、使いこなせると癖になりますよ。
是非一度手を染めてみてください。
-
「基本的に」と書いたのはAWSなどはテクノロジーの進化が激しく、自動化できなかったことができるようになったり、複雑に自動化していた仕組みが簡単にできるようになったりするからです。
自動化の範囲によりますが、保守運用のプロセスやサービスレベルの見直しも発生しますし、完成したシステムに手を入れるので導入時に事故が起きる危険性があるため、お客様を納得させる大きなメリットがないとチャレンジしにくくなります。
要件定義時に自動化する範囲を決め、そのコスト・期間を見積もっておく必要があります。
IPAが出している非機能要求グレードにも「障害復旧自動化の範囲」「保守作業自動化の範囲」などが定義されており、あらかじめ計画し、合意すべきだというのは納得できる話です。 ↩ -
実際にはマネージメントコンソールや、SDKからは実行可能 ↩
-
ちなみにAnsible2.2からはAWS関連のアップデートが大量に入っていて、実装前は使えそうな印象を持ちましたがもう少しcliの力を借りる必要がありそうな印象を持ちました。 ↩