はじめに
Parquet
データ分析用途でParquetというデータ形式が利用されます。これはデータを行ではなく列ベースでカラムで格納することでデータを集計しやすく、列方向に同じ種類のデータが並んでいるので圧縮にも効果があります。
圧縮率が高いということはHadoopをはじめとする分散処理基盤で読み込むデータ量が少なくなるのでそれだけ速度にも影響してきます。
速くなるのか?
こちらの投稿を見ると必ずしも早くなるとは言えないようですね。
https://dev.classmethod.jp/cloud/aws/amazon-athena-using-parquet/
投稿を見るとデータサイズが小さいので、効果があるかないかは正しく言えない気はしましたが、どちらにせよデータの種類、内容やサイズや、投げるクエリによって色々と変わるのでとにかく試してみないと正しいことは言えないようです。
今回のプロジェクトでは約200GBのCSVデータ(UTF-8,LF)を利用してデータのフォーマットを変えたり、EMRのインスタンスタイプを変えたり、クエリエンジンを変えて検証を行いました。
Parquetに関しては、サイズはおおよそ1/10になりました。クエリの性能については他テーブルとのJOINなどを含めて4種類のクエリを投げましたが最高でRAWデータの10倍、最低でも2倍の速度が出ました。
Parquetを使えば性能に必ず効果がでる!とは盲信せず、自分のプロジェクトで利用するデータで実際にPoCすることが必須と言えます。
AWSでParquetはおいしい
Athenaの課金はスキャンされたデータ1TBあたり5USDです(2018年6月時点)
https://aws.amazon.com/jp/athena/pricing/
ということはスキャンされるデータが少なくなるParquet形式というのはかなりお得ですね。
1/10に圧縮できれば料金1/10ですからね・・・
GlueでParquetに変換してみよう
Parquet形式への変換は以前はEMR上でSparkを動かして変換したりしていたのですが、Glueがリリースされて、Parquet変換プログラムも組み込まれたことにより、ノンコーディングで変換できるようになりました。素晴らしい・・・
ちなみに、ORCという別のフォーマットなどもありますがそちらの変換にも対応しているようです。
今回は約200GBのCSVデータ(UTF-8,LF)をGlueを使ってParquet形式へ変換してみました。
Glueを使うとなんとノンコーディングで変換できます。便利ですね。ということで早速やっていきましょう。
S3へInputデータを配置する
今回はs3a://uzresk-glue-testdata/inputにデータを配置し、outputに出力するようにしました。
200GByteのデータのアップロードはWindowsServerからpowershellを使ってアップロードしました。
AWSマネジメントコンソールからのアップロードは78GBまでですのでお気を付けください。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/user-guide/upload-objects.html
Crawlerの設定
InputとなるデータをTableとして認識させるためにCrawlerの設定を行います。
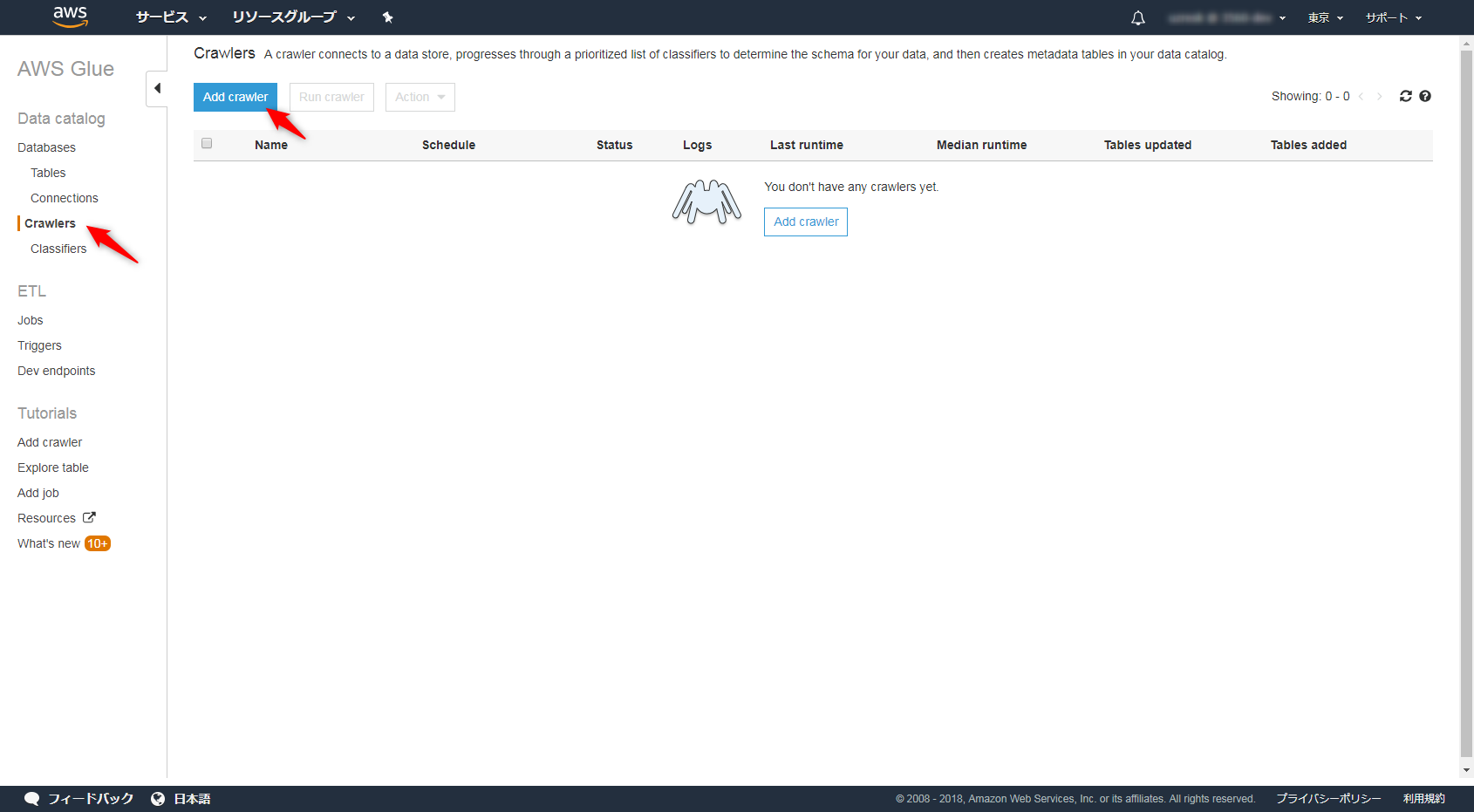
Crawlerの名前を付けます
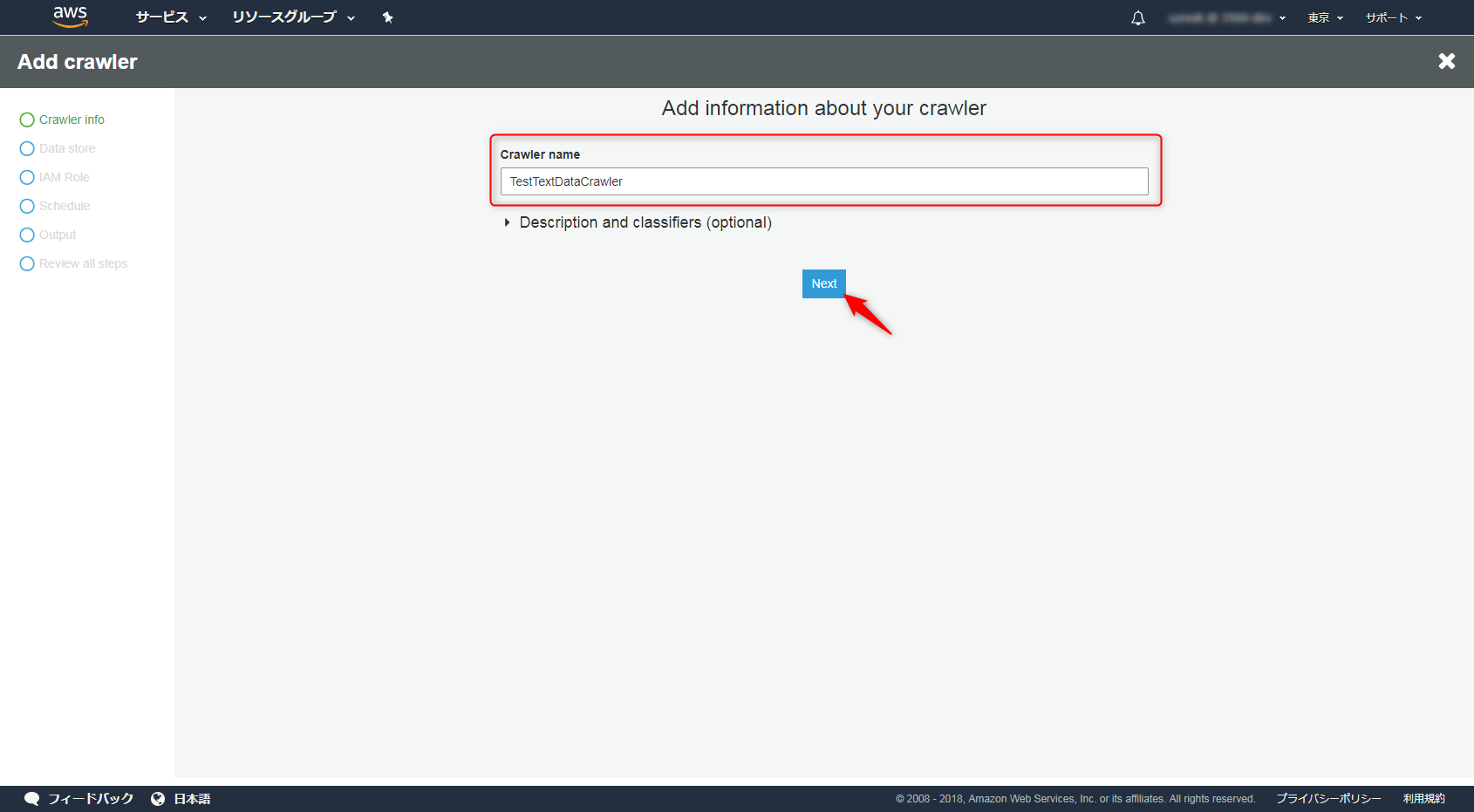
データソースにはS3にあるinputデータを指定しましょう。(選択式なので特に迷わないと思います)
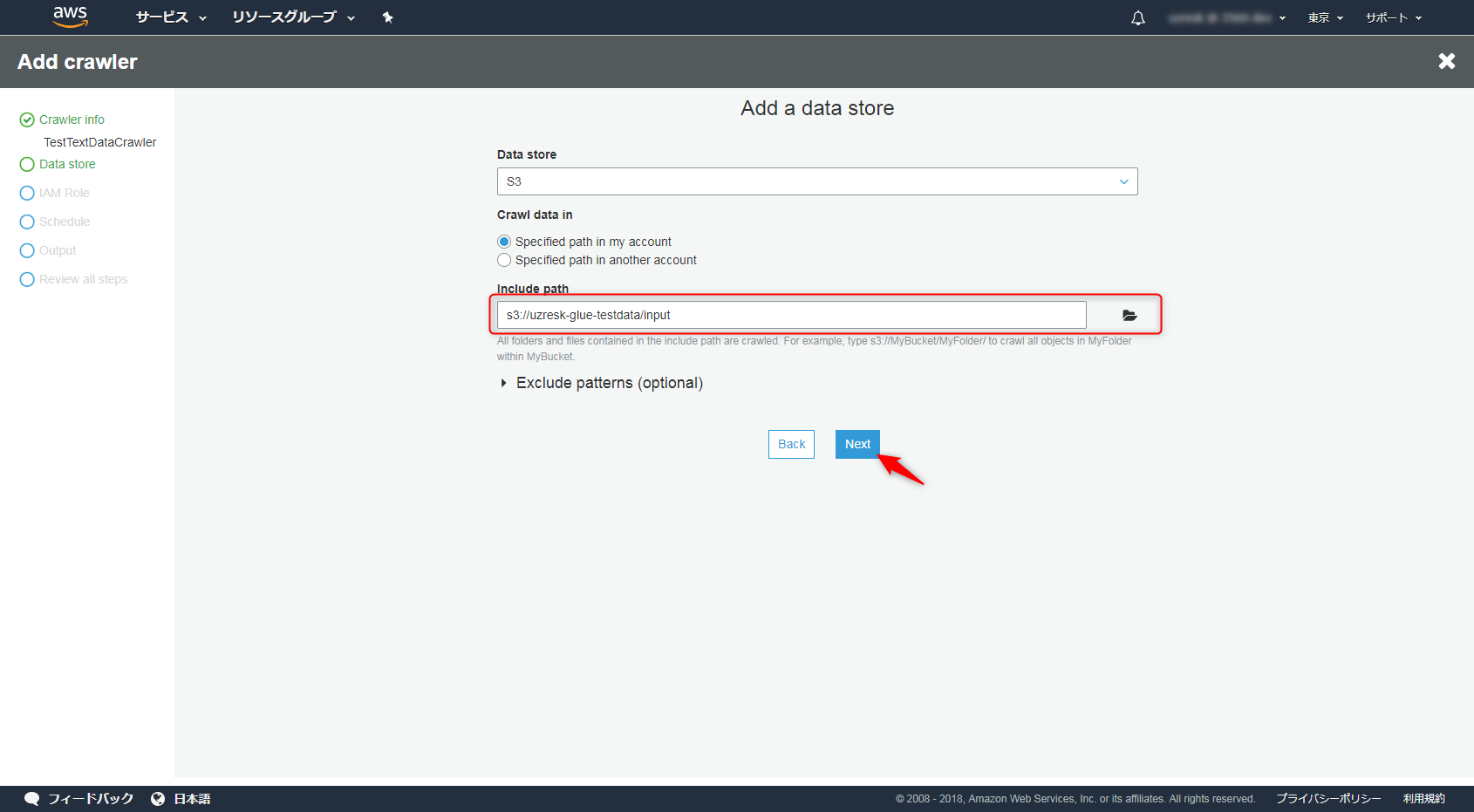
初回はGlueに紐付けられるロールが無いので、IAMロールを新規で作りましょう。
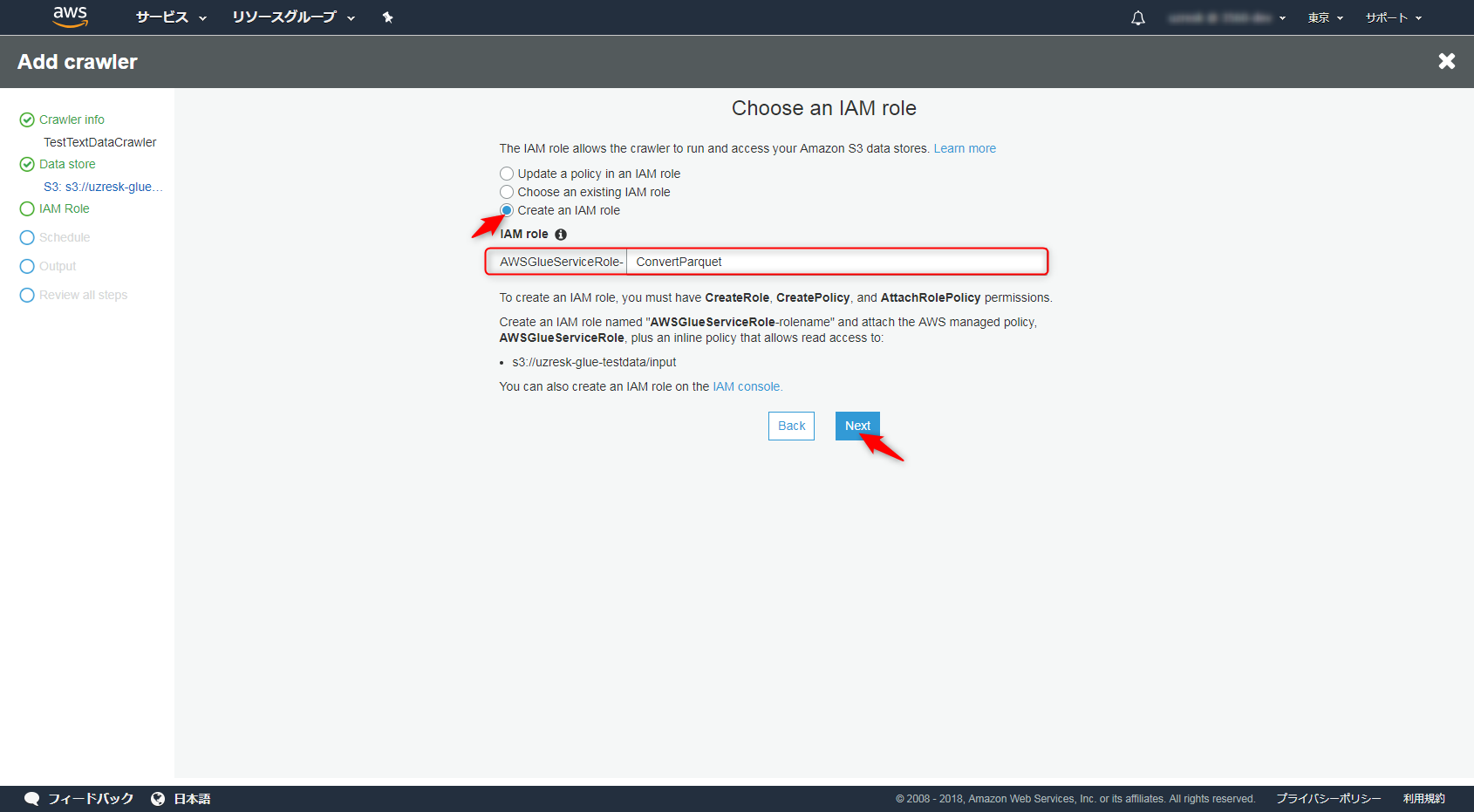
「Run on demand」「Hourly」「Daily」「Choose days」「Weekly」「Monthly」などから選べますのでもしデータが入ってくる期間が定期的ならスケジュールしてあげても良いですね。
今回は「Run on demand」を選びました。
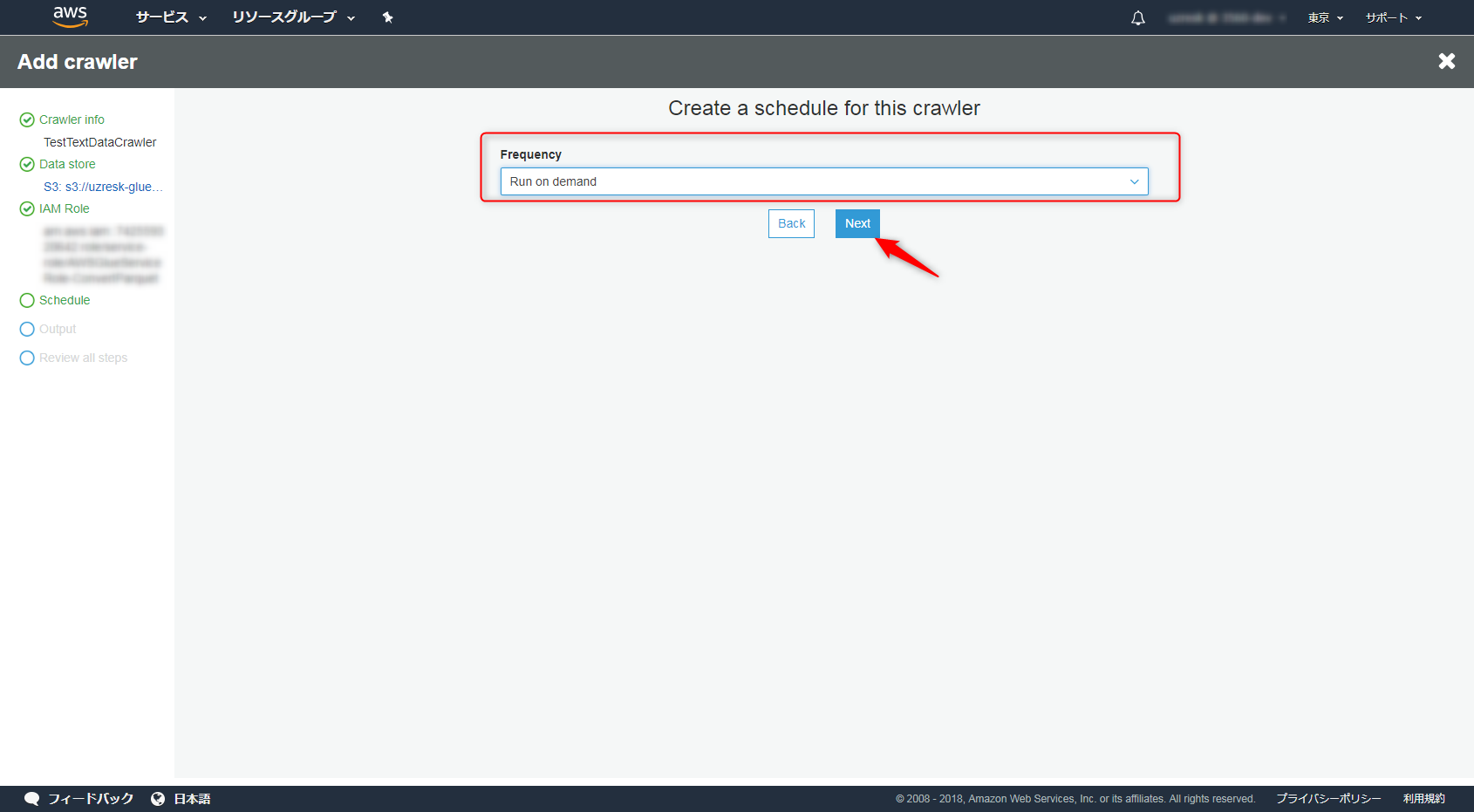
データベースはなければ作成し、inputデータに対応するテーブル名を決めておきましょう。
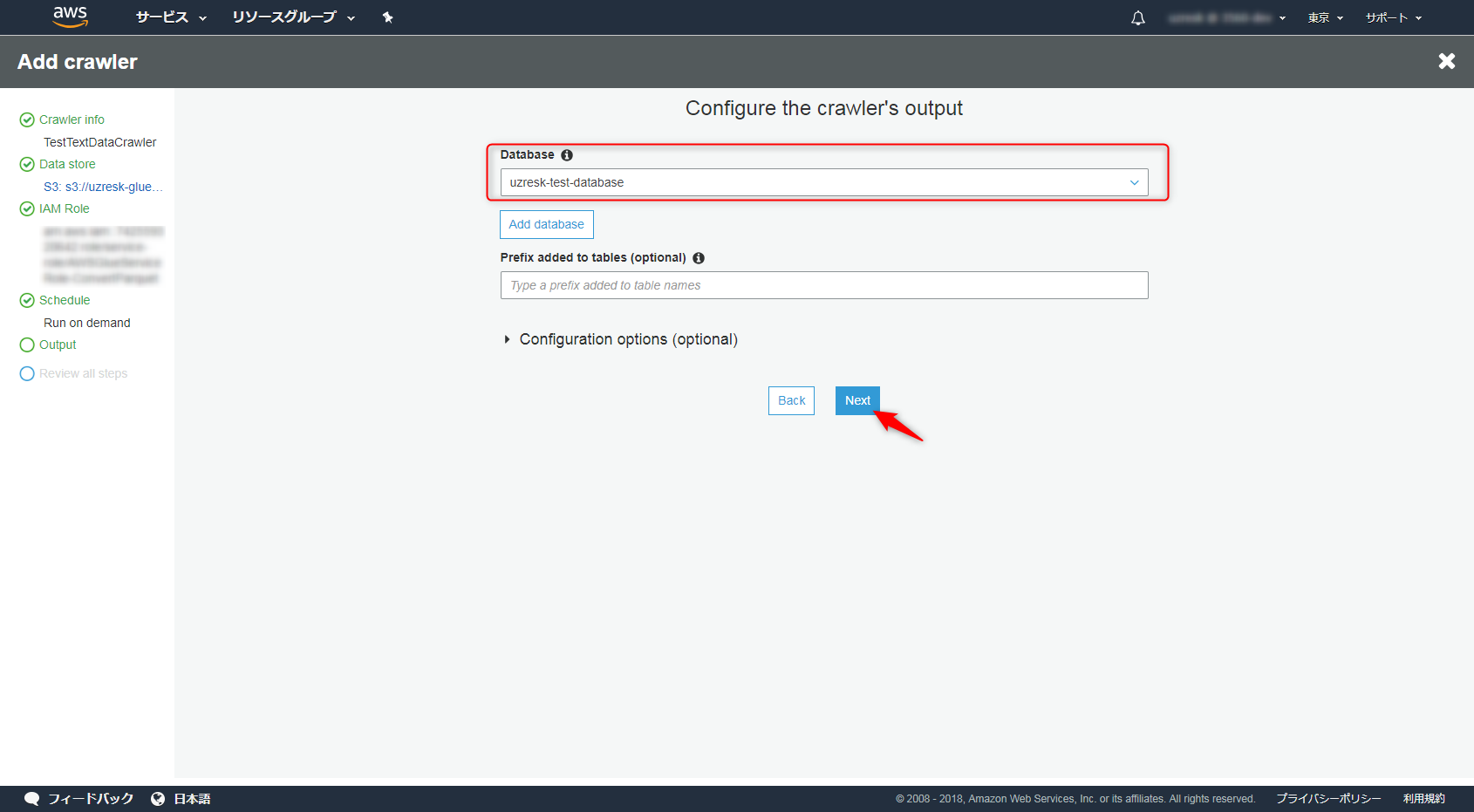
内容を確認してFinishを選択します。
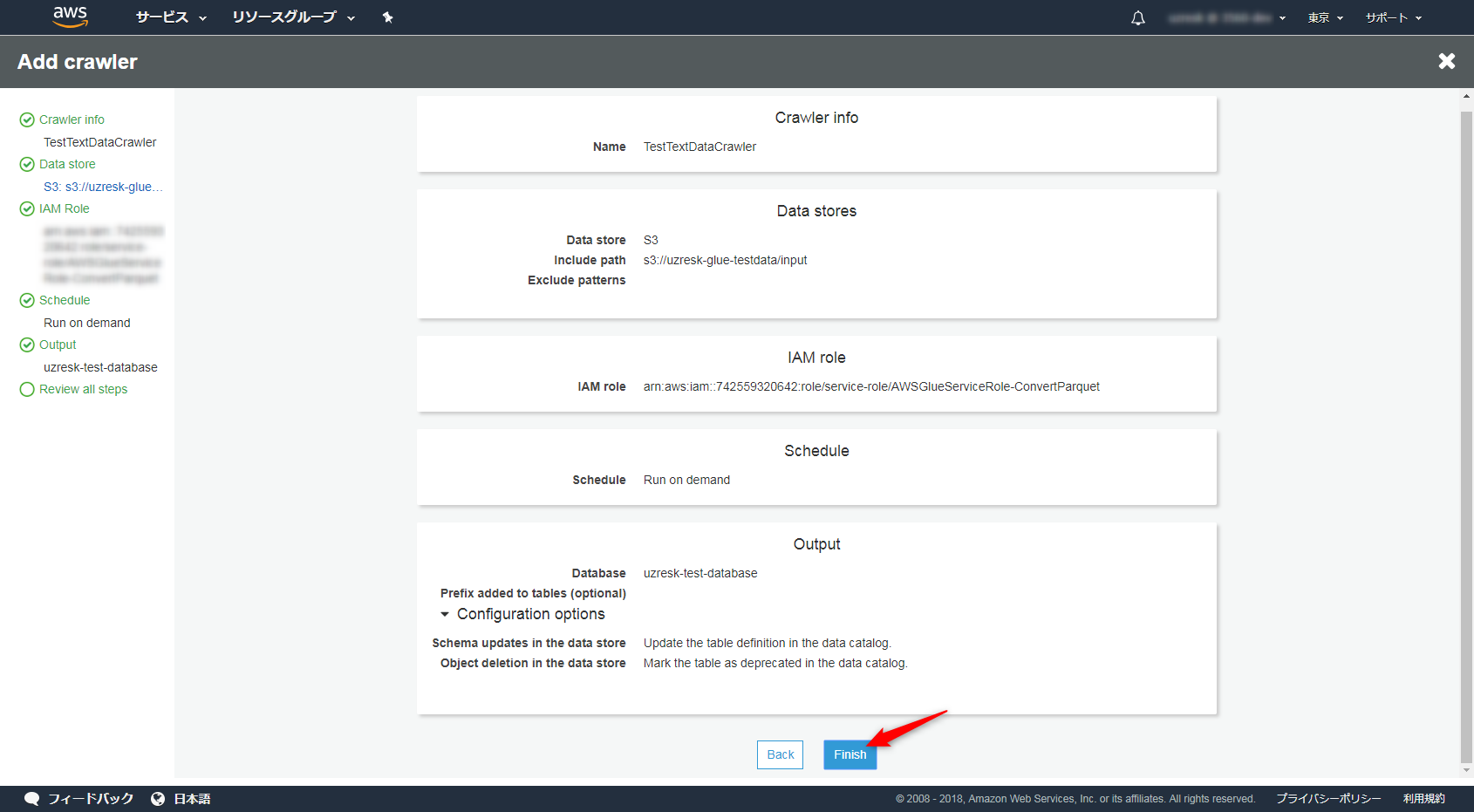
作成したCrawlerを選択して、「Run Crawler」を選択するとCrawlerが起動します。
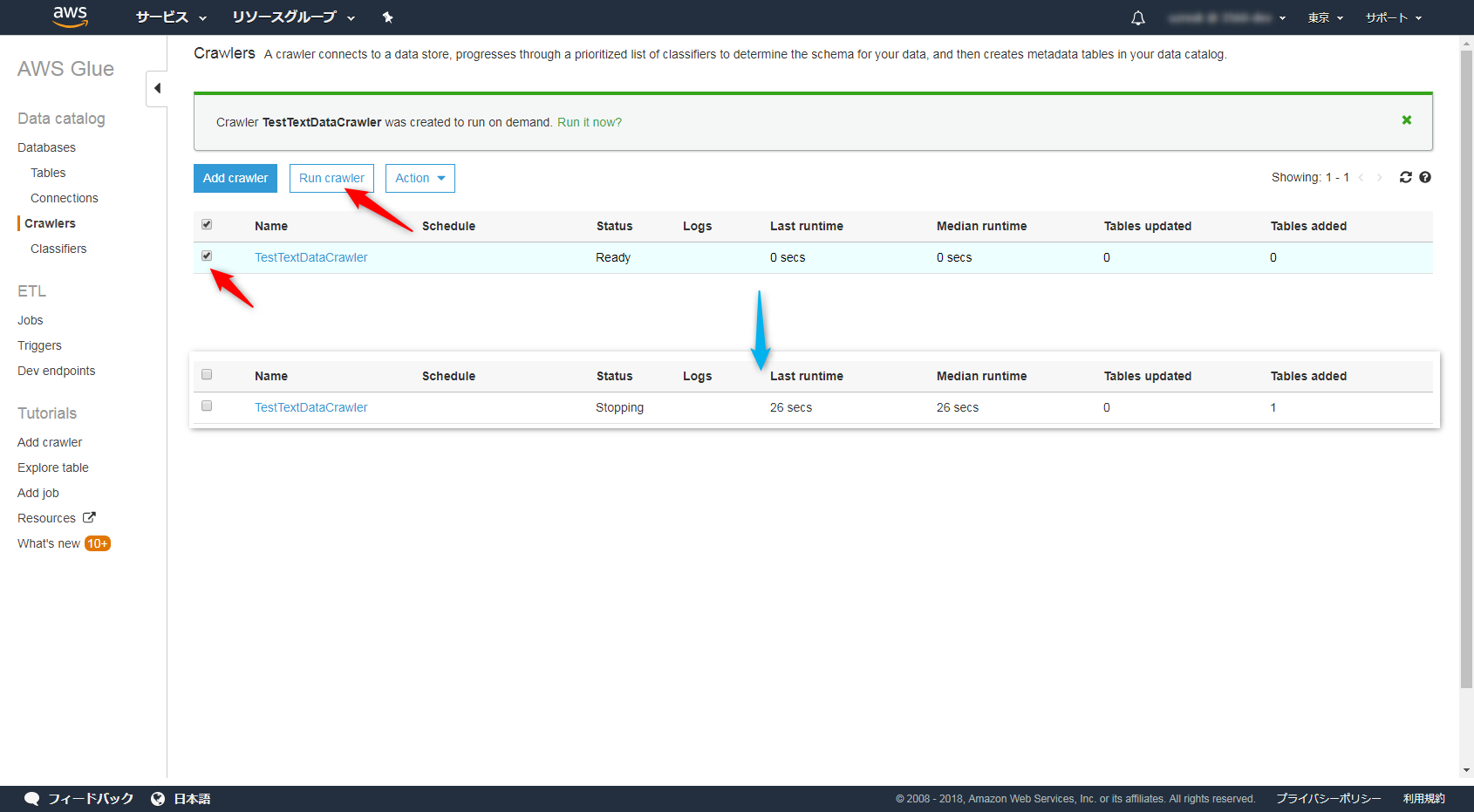
数十秒待つと指定されたテーブルができているはずです。
IAMの設定
Parquet形式に変換するためのJOBで先ほど作ったIAMロールを利用します。
IAMロールにS3へのアクセスを設定してください。今回はFullAccessを設定していますがリソースを縛るなど適切に設定してください。
GlueのJOB設定
Glueの画面を開いて「ETL」→「Add job」を選択します。名前は適当につけましょう。
DataSourceは先ほどCrawlerで作ったテーブルを選択します。
データの出力先はS3をソースにした新たなテーブルを作成します。Formatには「Parquet」を選択します。
ここで選択されたFormatに合わせてPythonやScalaのスクリプトが自動で設定されます。
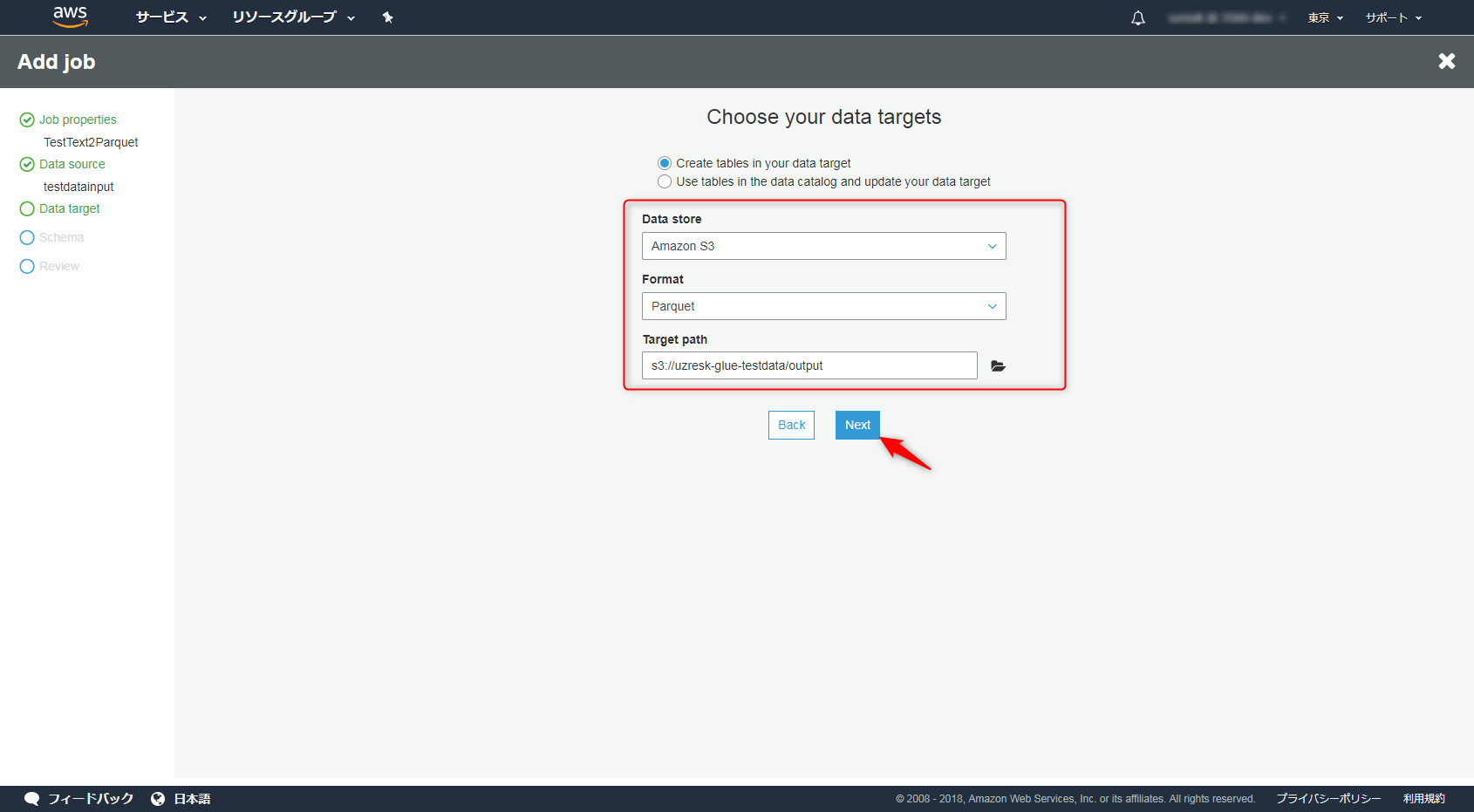
特に変換はしないのでそのままNextを押下します。
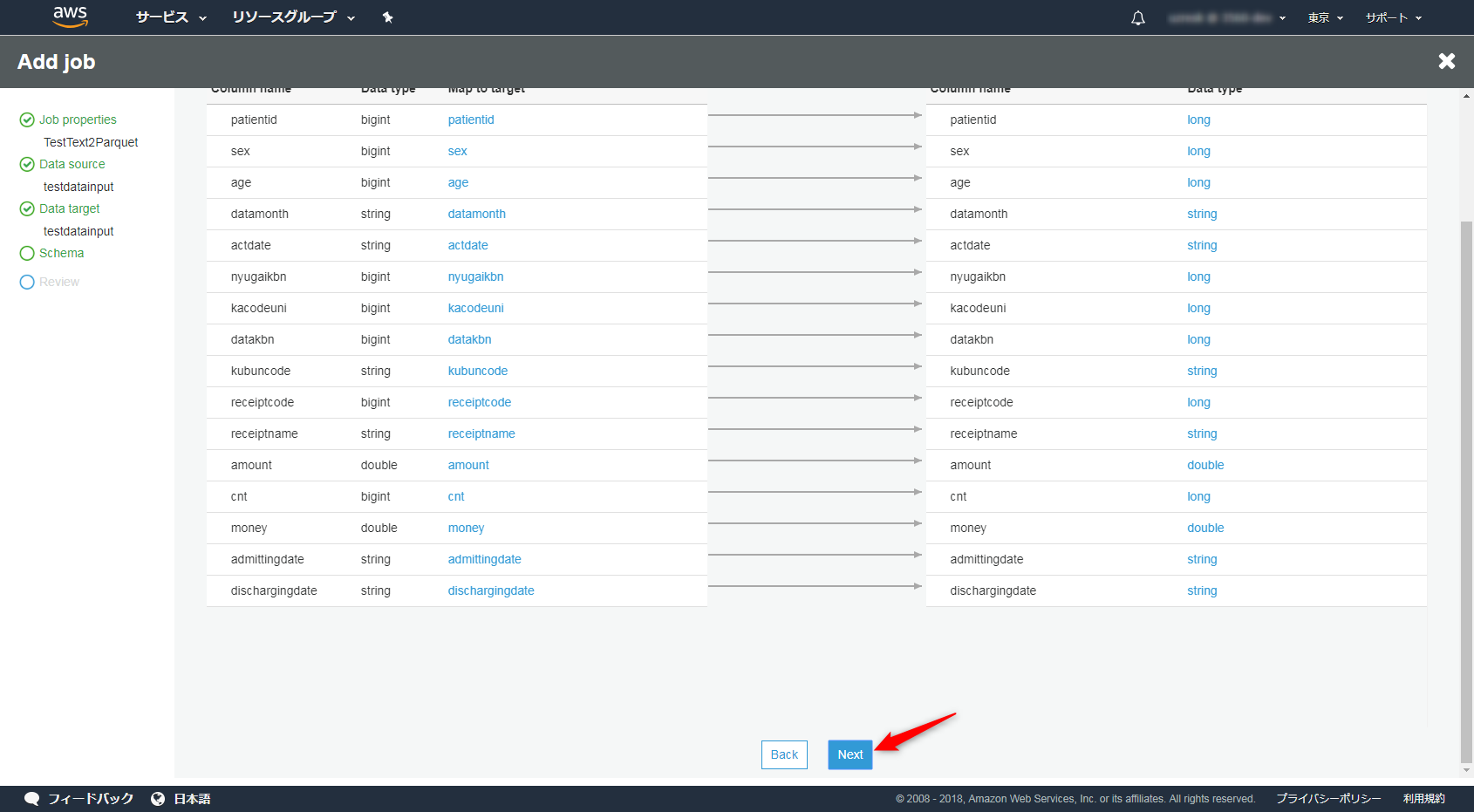
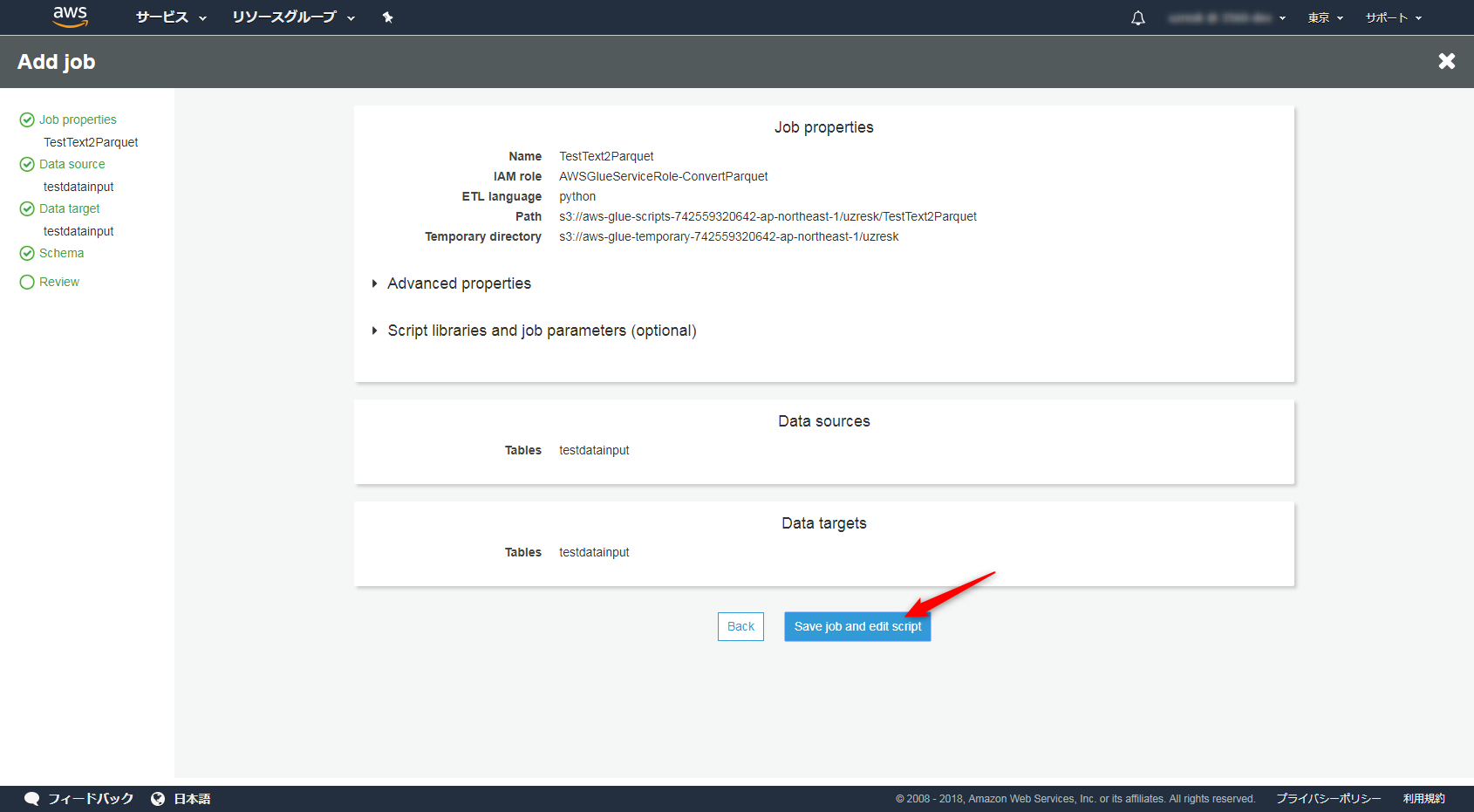
内容を確認して保存しましょう。
画面が切り替わります。赤枠の部分にはGlueが設定してくれた自動スクリプトが記載されているはずです。
「Run Job」を選択することで実行できます。
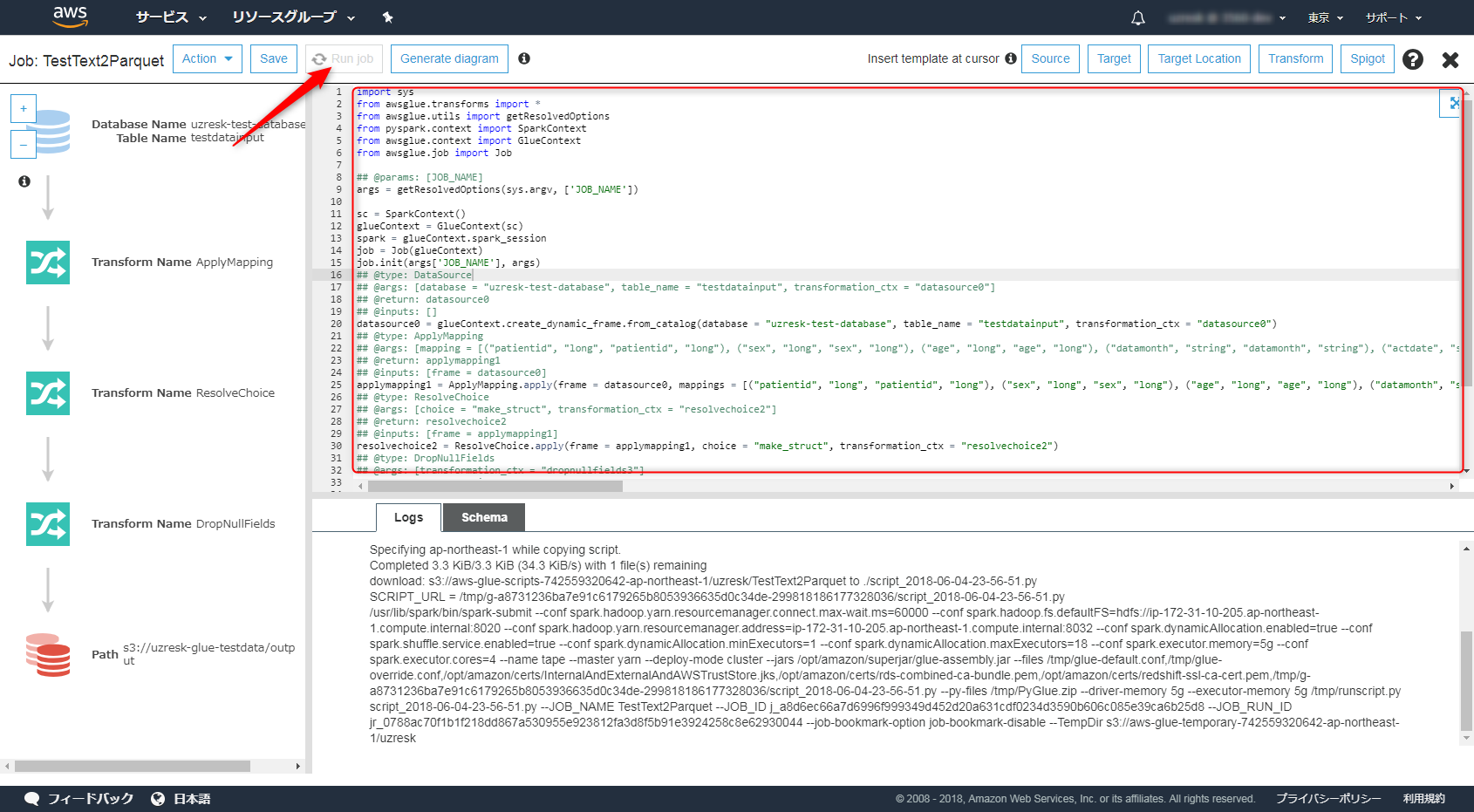
Glueの画面に戻り、JOBを選択すると画面下部に進行状況が表示されているはずです。
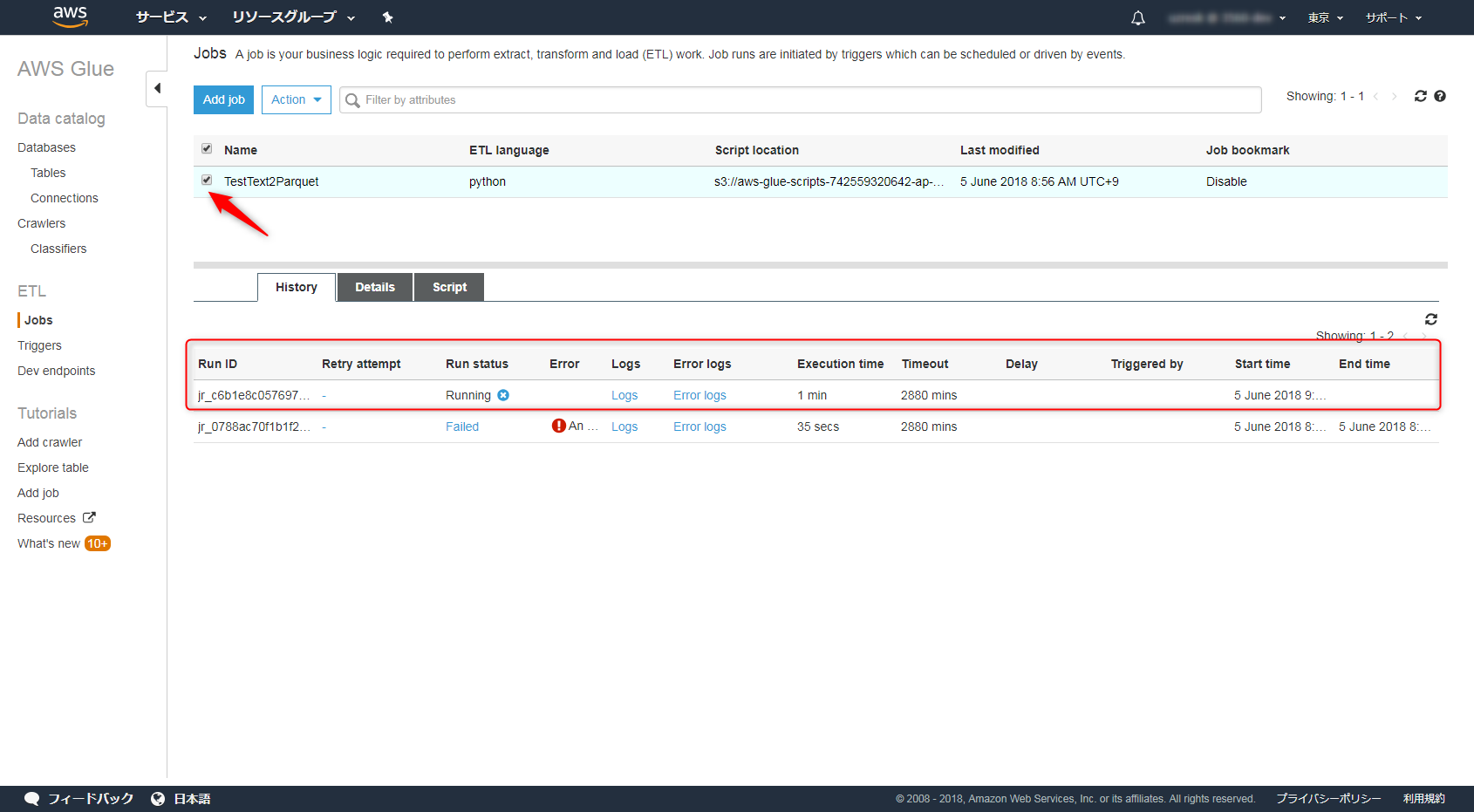
待つこと30分ほどでParquetへの変換ができました。素晴らしい。
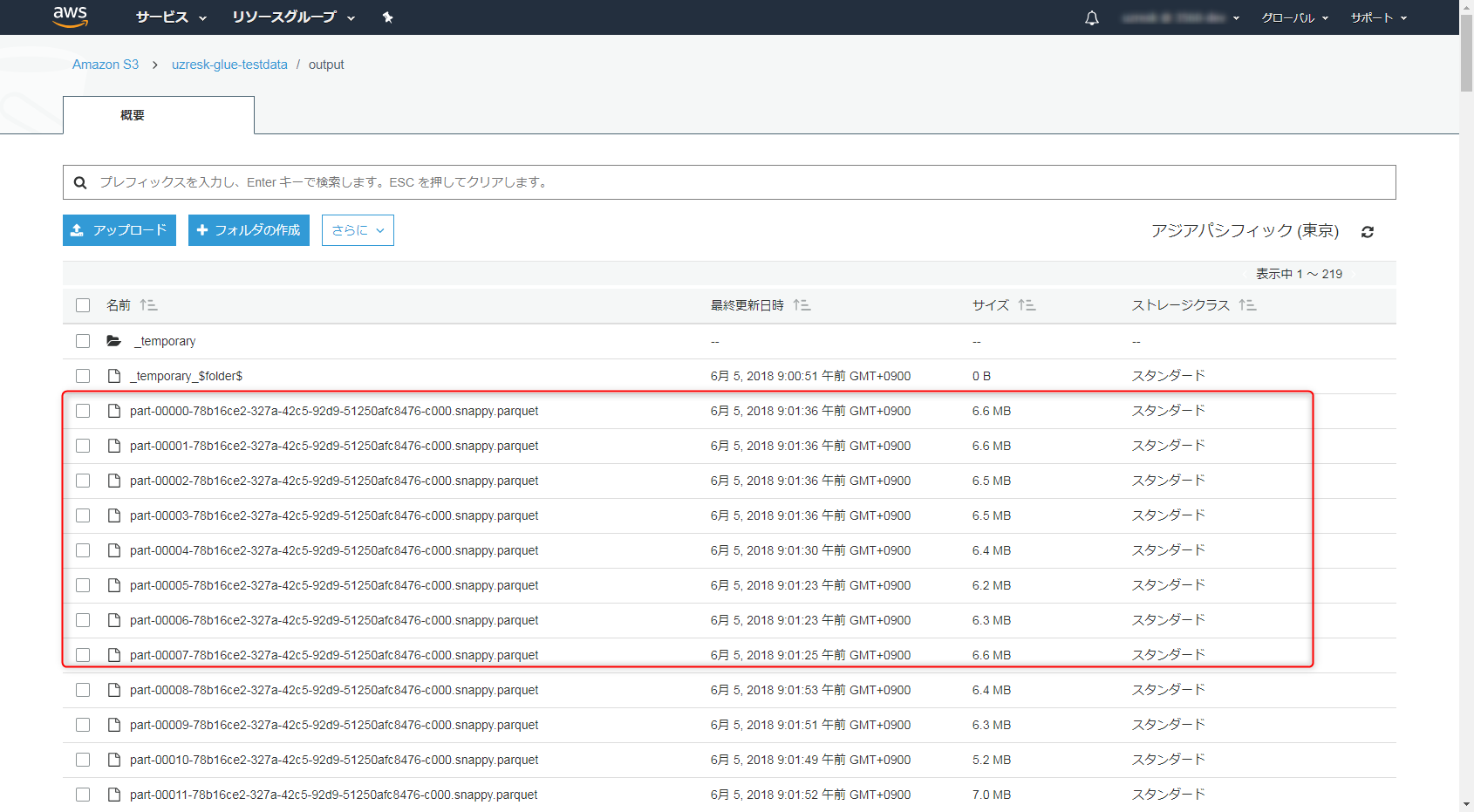
おためし
折角なのでAthenaで試してみましょう。
先ほどoutputに出力されたparquet形式のデータに対してCrawlerの設定を行いテーブルを作りましょう。(同じ手順なので省略)
AthenaはHueというWebインタフェースベースを改造したものをベースにしており、バックエンドはPrestoというクエリエンジンが利用されています。
今回のデータでカウント処理してみたところTEXTデータで18秒、Parquet形式では8秒という結果がでました。