はじめに
- AWS Datapipelineについて思ったよりWeb上に記事がないので、試してみた結果をまとめてみました。
- 細かいパラメータについてはおいおいまとめていこうと思います。
情報源
んで、結局何ができるのか?
- BlackBeltの資料内ではETLと書かれていますが、AsteriaやDataspiderのようなデータのマッピングツールを兼ね備えているわけではありません。S3からRedshiftにデータをロードしたり、RDSからデータを抽出してS3にエクスポートするなどができます。SQLレベルでの変換は可能ですが、細かい変換や集計に関しては、EMRを使ったりShellを起動してそのなかで呼ばれるプログラム内で実装する必要があります。
- pipelineはそれぞれスケジュール起動することができます(スケジュール起動のタイミングは最短で15分間隔)pipelineではshellの起動ができるので、cronの代わりとして利用する人もいるようです。
- DirectConnectと合わせて使うことで、オンプレミスのデータからデータを抽出しS3に保管したり、Redshiftにインポートすることができます。
- pipeline内の各アクティビティはリランしたり、キャンセルしたりすることができます。
料金
- 料金表 - Amazon Data Pipeilne
- 東京リージョンを例にとると、1日に1回AWS内で流れるアクティビティだと月額$0.5715。これにActivityに紐付いてタスクを動かすEC2インスタンスの起動料金がかかるイメージですね。やっぱり安いですね。。
基本的な流れと要素の説明
- 下記はRDSにあるデータを抽出してS3にエクスポートするPipelineです。
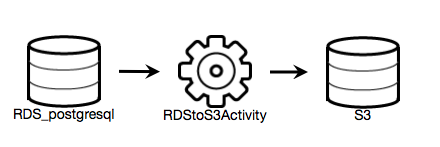
- 左右にあるドラム缶はDataNodeと言われ、データソースを表します。
- 真ん中にある歯車はActivityと言われ処理を行います。処理はEC2やEMRで動かす必要がありますので、ActivityにはEC2やEMRのリソースを紐付ける必要があります。
Activityに紐付くサーバについて
Activityに処理が移ったタイミングでサーバに処理を行わせます。利用するサーバのタイプは大きく3種類あるようです。
1.インスタンスタイプやSubnet、AMI IDを指定して新しくEC2インスタンスを起動する
2.別のアクティビティで起動されたEC2インスタンスを再利用する。
3.オンプレミス(または、任意のEC2インスタンス)
1はPipelineがオンデマンドで起動するので起動するまでの時間が掛かります。
2,3に関しては起動時間が無いのですぐに処理に移ります。
3に関しては後述しますがjdkのバージョン6以上がインストールされている必要があることとDatapipelineのendpointに対して通信を行える必要があります。
DataNodeの種類
- DynamoDBDataNode
- MySqlDataNode
- RedshiftDataNode
- S3DataNode
- SqlDataNode
上の4つはわかりやすいと思いますが、SqlDataNodeだけ2つの活用方法があります。
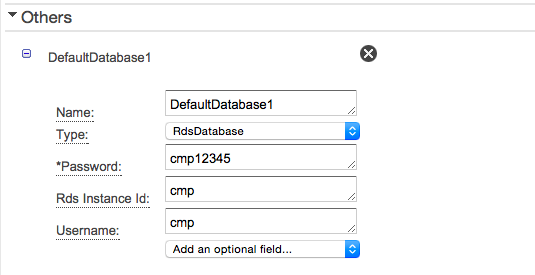
SqlDataNode - RDSに接続する
- RDSに関してはインスタンスIDを設定するだけでRDSのインスタンスが特定されます。
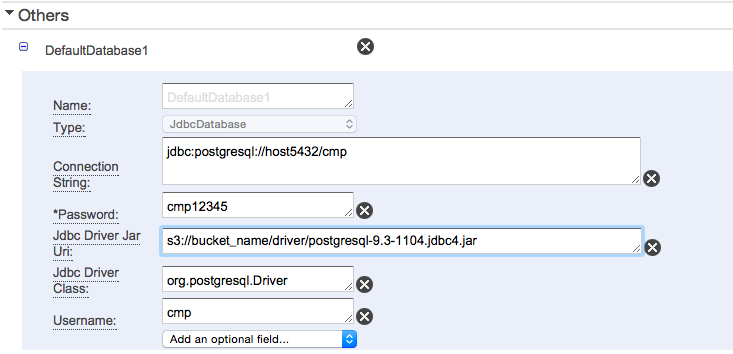
SqlDataNode - RDS以外のDBに接続する
- オンプレミスにあるデータベースや、EC2上に構築されたデータベースは以下のように接続先やjdbcドライバを格納先(S3)を設定することで接続することができます。
Activityの種類
-
以下の操作を行うことができます。
-
CopyActivity
-
EmrActivity
-
HadoopActivity
-
HiveActivity
-
HiveCopyActivity
-
PigActivity
-
RedshiftCopyActivity
-
ShellCommandActivity
-
SqlActivity
-
操作の内容についてはアクティビティを参照してください。
設定方法
ここからは何個かピックアップして操作を見てみようと思います。
EC2やRDSのリソースの設定については省略しています。
RDS → S3
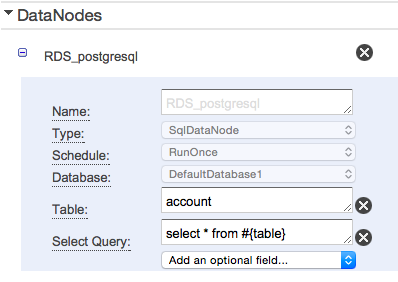
- RDSのデータをS3にコピーしようと思います。
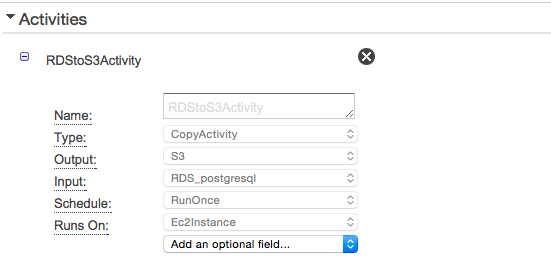
- inputのDataNodeにはRDSを指定して抽出するSQLを設定しています。#{table}と記載することでTableに設定された値をSQLに埋め込むことができます。
- ここでは単一テーブルに対するSelectですが、複数テーブルでも勿論問題ありません。
- output先のS3の定義を行います。
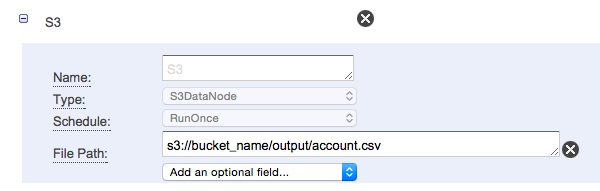
- activityの定義を行います。
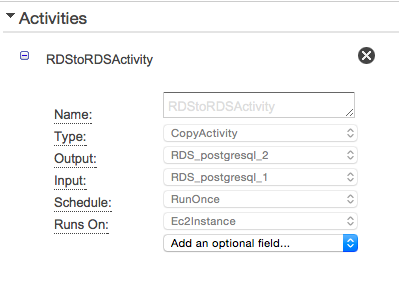
RDS -> RDS
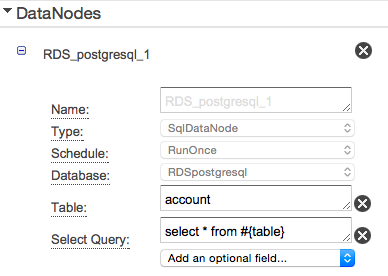
- RDSのあるテーブルのデータを別のテーブルにコピーしてみます。
- ここでは同一のRDS内でコピーしています。
- inputにはRDSを指定します。
- outputにはinsert文を設定します。vaulesには?を入れておくことでinputのリソースで取得できた順にバインドされるようです。
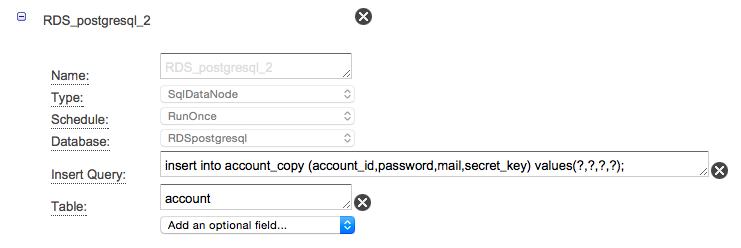
- 最後にActivityです。ここはinputとoutputを指定するだけです。
shellを起動
- ここでは既に起動してあるEC2インスタンスでechoコマンドを打っている例です。
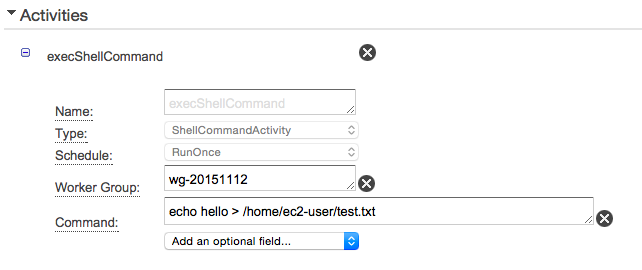
- スケジュールでshellを起動することができるのでcronの代わりに利用する人もいるようですね。
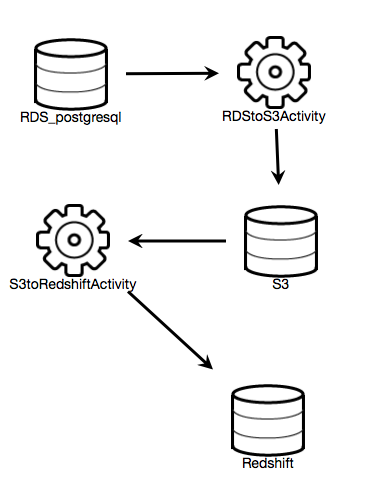
RDS -> S3 -> Redshift
- outputをinputとして複数のActivityを繋ぐことができます。
- RDS -> S3に関しは同様なので省略します。
- S3からRedshiftにデータを入れるときのAcitivityは以下のように定義します。
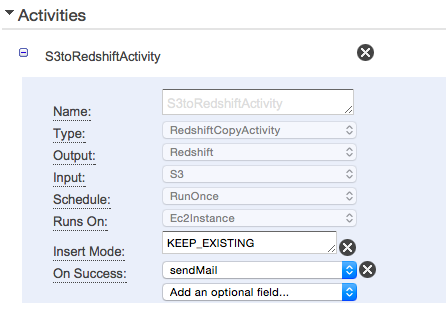
- outputのRedshiftの定義は以下のようにします。ここではaccountテーブルにデータを入れるように設定しています。
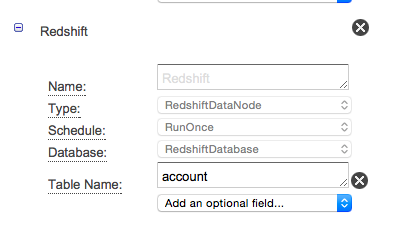
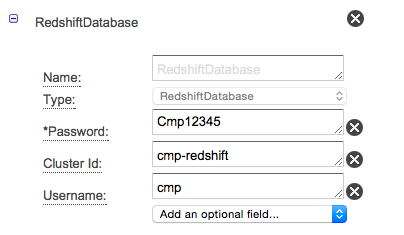
- RedshiftDatabaseの設定(ClusterのIDだけ入れれば繋がります)
通知について
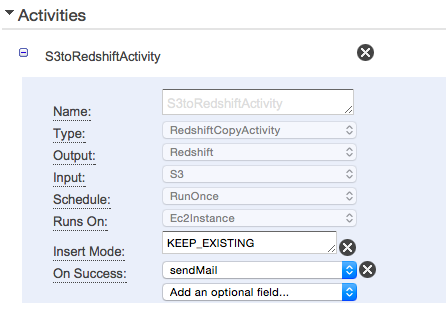
- SNSのEndpointを設定しておくことで成功時・失敗時にメールを送ることが出来ます。
- 成功時にメールを送るにはActivityのFieldにOn Successを追加し、sendMailを選択します。
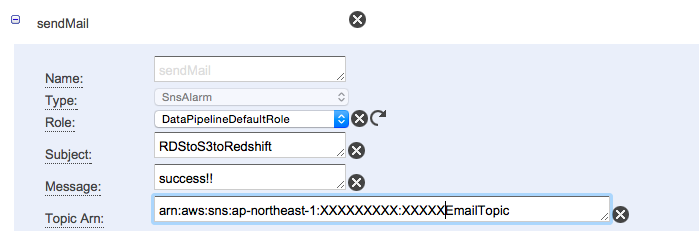
- SNSのTopicの設定を行った後、OthersタブでsendMailの設定を行います。
既に存在するサーバでActivityを動かす方法(オンプレミスで動作させる)
- Java6以上をインストールします。
- TaskRunnerをダウンロードしてサーバに配置します。
- datapipelineに繋げるための情報を作成します。access-idとprivate-keyはIAMの画面からアクセスキーとシークレットアクセスキーを発行して記載してください。
credentials.json
{
"access-id":"xxxxx",
"private-key":"xxxxx",
"endpoint":"https://datapipeline.ap-northeast-1.amazonaws.com",
"region":"ap-northeast-1",
"log-uri":"s3://bucket_name/logs/"
}
- 起動してみます。
- workerGroupに設定されたIDでDatapipeline上のタスクをポーリングします。workerGroupは好きな文字列で結構です。
[ec2-user@ip-10-0-0-48 ~]$ java -jar TaskRunner-1.0.jar --config ./credentials.json --workerGroup=wg-20151112
log4j:WARN No appenders could be found for logger (amazonaws.datapipeline.objects.PluginModule).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Starting log pusher...
Log Pusher Started. Region: ap-northeast-1, LogUri: s3://uzresk-datapipeline/logs/
Initializing drivers...
Starting task runner...
- Activityの設定で上記のworkerGroupを設定してあげます。
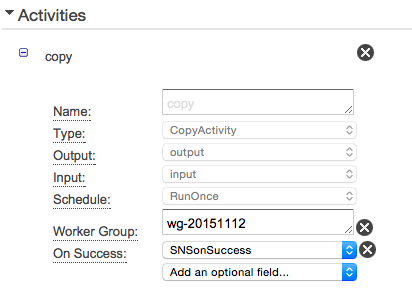
- 上記のように設定することでpipelineは、workerGroupで設定されたIDで動き、TaskRunnerはWorkGroupで設定されたタスクが存在すれば処理を行うようになります。
最後に
- 単純ですが、単純だからこそ組み合わせて効果でそうなサービスだなぁという感じ。導入のハードルも比較的低いんじゃないかなーと思うんですがあまり実績ないんですかね。。