イベントソーシング(ES)って何?
イベントソーシング(以降、ESと呼ぶ)とは、かなり端的にいうとCRUDにおけるU(update; 更新)とD(delete; 削除)を使わないでアプリケーションのステートを管理する手法のことである。
なぜ使わないかというと、データの更新と削除は本質的に「情報を消し去る」操作であり、消し去った情報が後々ビジネス価値のあるものだと気づいたとしても泣き寝入りするしかないからだ。
ESにおいては、データの更新や削除をするかわりにアプリケーションが管理するステートに対してどのような操作が行われたかをappend-onlyのイベントログに記録していき、ある時点でのステートを知りたいときはアプリケーション側でイベントログの内容を元にステートを導き出すという方法を取る。
CRUDとESの比較
例えば、「ユーザーがパスワード変更する」場合、よくあるCRUDパターンでは users テーブルの password_digest カラムの値を新しい値で更新する、といったたぐいの操作をする。
ここで、ビジネス側が次のような仕様変更を提案してきたとする:
ビジネス「セキュリティ向上の一環として、そのユーザーが過去1年以内に使ったパスワードと同じパスワードには変更できないようにしてくれる?」
あなた「いや、パスワード変更するたびに古いの上書きしているから過去に使ったパスワードなんて分からないんですけど……」
こうなると、この仕様変更自体がお流れになるか、あるいは user_password_histories のようなテーブルを作って次回デプロイ後から変更前のパスワードを記録し始める、といった妥協をすることになるだろう。
単にビジネス要件を妥協することになるだけでなく、システム的にも *_histories や *_logs のような後からでっち上げた変なテーブルが増えて、アプリケーション全体の見通しが悪くなるという負債が増えていくことにもなる。
では、イベントソーシングを使ったシステムではどうなっていたか?
実装の手法は色々考えられるが、ここでは「ユーザーのパスワード変更」という操作が発生するたびに user_password_changed_events テーブルにレコードを追加していくという方法を取る:
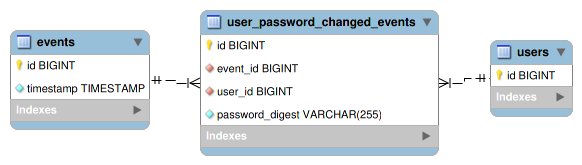
ここで、 events テーブルはアプリケーション内で発生したすべてのイベントを一律に順序付けするための親テーブルで、 users テーブルはユーザーを一意に特定するためのIDを AUTO_INCREMENT の id カラムを使って発番するために存在する。
過去に使ったパスワードのハッシュ値はすべて user_password_changed_events に記録されているので、例えば user_id が 1 のユーザーが過去1年以内に使ったパスワードすべてのハッシュ値は以下のように取得できる:
(本記事ではMySQL 8.0を使用している。)
SELECT upce.password_digest
FROM user_password_changed_events AS upce
INNER JOIN events AS e
ON e.id = upce.event_id
WHERE upce.user_id = 1
AND e.timestamp >= DATE_SUB(NOW(), INTERVAL 1 YEAR)
;
このクエリの結果を元に、アプリケーション側でパスワードの一致を検証し、一致するものがない場合に限り新たに user_password_changed_events にレコードをINSERTすることで、上述の要件を満たすことができる。
この例のように、UPDATEやDELETEなどの情報を消し去る操作を禁止しイベントのみをINSERTしていくことによって、要件追加・変更があっても柔軟に対応できるのがESの利点である。
この user_password_changed_events だけに限っても、ESを使うことによって以下のような要件追加に柔軟に対応できるようになる:
- 直近24時間以内で最大3回までしかパスワードを変更できないようにする
- パスワード再設定時の確認方法の一つとして、過去に一度でも使ったことのあるパスワードを入力すれば再設定を許可する
- 変更済みのパスワードを使ってログインしようとした場合、「このパスワードは3ヶ月前に変更されています」といったメッセージを表示する
以下、リレーショナルデータベースを使ってESシステムを構築する際の手法について書いていく。
実践例
ユーザーの作成
上の説明ではユーザーが既に存在する前提で「パスワードの変更イベント」について話したが、ここではそもそもユーザーをどう作成するかについて説明する。
ESにおいてはステートの変化はすべてイベントによって表されるため、以下のような「ユーザー作成イベント」を表す user_created_events テーブルを作成するとする。
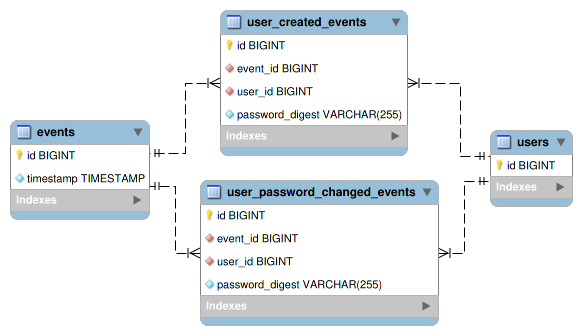
user_created_events にレコードを追加する際は、以下のように同一トランザクション内で users レコードも追加する:
BEGIN;
-- idはAUTO_INCREMENTなので自動で割り当てられる。
INSERT INTO users ()
VALUES ()
;
-- 実際に挿入されたusers.idを保存する。
SET @user_id = LAST_INSERT_ID();
-- idはAUTO_INCREMENT、timestampはDEFAULT CURRENT_TIMESTAMPなので自動で割り当てられる。
INSERT INTO events ()
VALUES ()
;
-- 実際に挿入されたevents.idを保存する。
SET @event_id = LAST_INSERT_ID();
-- password_digestはアプリケーション側で生成したハッシュ値を使う。
INSERT INTO user_created_events (event_id, user_id, password_digest)
VALUES (@event_id, @user_id, '$2a$12$Q9cMue8V0JVetxsmC.s7y.p2Ko1d909KxG33MpSeXJdubDODD3rw6')
;
COMMIT;
ここでは、ユーザー作成時に初期パスワードを設定しなければならないという想定で、 password_digest を user_created_events に持たせている。
スナップショットの導入
ここで、あるユーザーの現時点で有効なパスワードのハッシュ値を取得したい場合を考えてみる。
パスワードの初期値は user_created_events.password_digest で指定され、その後変更されるたびに user_password_changed_events.password_digest として記録されていくため、以下のようなクエリが必要になる:
SELECT password_digest
FROM (
SELECT *
FROM user_password_changed_events upce
WHERE user_id = 1
UNION
SELECT *
FROM user_created_events uce
WHERE user_id = 1
) AS u
ORDER BY event_id DESC
LIMIT 1
;
ログイン時の認証などでは現時点でのパスワードのみが必要なため、そのたびにこのクエリを実行するのは非効率かもしれない。
(もっとも、 EXPLAIN の結果を見る限り大してコストのかかるクエリではないが。)
そこで、クエリの効率化と単純化のため、 users テーブルにも password_digest カラムを追加して常に最新のパスワードのハッシュ値を保持するようにする:
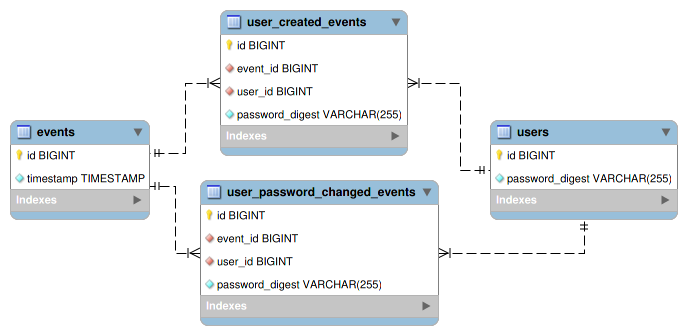
これによって上述のクエリは以下のように簡略化される:
SELECT password_digest
FROM users
WHERE id = 1
;
ESにおいて、このようなある時点におけるステートを記録したものをスナップショットと呼ぶ。
ここでは、 users テーブルに user_id の発番の役割に加えて最新のスナップショットの記録という役割も持たせることとした。
もちろん、ESの醍醐味はイベントの記録さえあれば過去のいかなる時点のステートも復元できるということなので、スナップショットは主にパフォーマンス改善の手法のみとして使われ、そもそも使うべきでないと主張する人もいる。
ただ、リレーショナルデータベースを基盤としたESの場合、最新のステートに対するクエリの簡略化やインデックスを活用することによる高速化を期待できるため、必要に応じて使って良いと思う。
さて、このスナップショットの値を常に最新の値に保つためには、 user_created_events と user_password_changed_events を作成する同一のトランザクションで users.password_digest の値を最新の値に更新するようにすればよい。
ESシステムの例としてよく紹介される手法として、イベントの保存とステートへの反映(投影と呼ばれることもある)を非同期化するというものもあるが、この場合メッセージキューやストリームを導入する必要があること、非同期化によって最新のスナップショットの更新がstrongly consistentからeventually consistentに変わることを考慮する必要がある。
以上を元に、スナップショットの更新を含めた「パスワードの変更イベント」について改めてみてみる。
パスワードの変更
パスワードの変更はユーザー作成とは違い既に存在するユーザーのステートを更新するイベントであるため、他のイベントと更新が衝突することを避ける必要がある。
ここでは、MySQLの SELECT ... FOR UPDATE を使って更新対象の users レコードをロックすることで衝突を回避するという方法をとる:
BEGIN;
-- `users` のステートを変更するイベントを作成する際は必ず変更対象の `users` レコードをロックするという決まりとする。
-- この決まりを守りさえすれば、別イベントに割り込まれて不整合なデータを読む心配はなくなる。
SELECT *
FROM users
WHERE id = 1
FOR UPDATE
;
-- イベント発生時のイベントログをクエリし、1年以内に使われたパスワードのハッシュ値を取得する。
SELECT upce.password_digest
FROM user_password_changed_events AS upce
INNER JOIN events AS e
ON e.id = upce.event_id
WHERE upce.user_id = 1
AND e.timestamp >= DATE_SUB(NOW(), INTERVAL 1 YEAR)
;
-- 初期パスワードについても同様のクエリを行う。
SELECT uce.password_digest
FROM user_created_events AS uce
INNER JOIN events AS e
ON e.id = uce.event_id
WHERE uce.user_id = 1
AND e.timestamp >= DATE_SUB(NOW(), INTERVAL 1 YEAR)
;
-- アプリケーションコードでパスワードの重複チェックを行い、重複している場合はここでROLLBACK。
-- idはAUTO_INCREMENT、timestampはDEFAULT CURRENT_TIMESTAMPなので自動で割り当てられる。
INSERT INTO events ()
VALUES ()
;
-- 実際に挿入されたevents.idを保存する。
SET @event_id = LAST_INSERT_ID();
INSERT INTO user_password_changed_events (event_id, user_id, password_digest)
VALUES (@event_id, 1, '$2a$12$9gYmBTDE3cHgVdJ7yXv1T.z6.Dmscp0Q9qqzwEuC5iH.DxLlPa1MO')
;
-- 同一トランザクション内でスナップショットも更新する。
UPDATE users
SET password_digest = '$2a$12$9gYmBTDE3cHgVdJ7yXv1T.z6.Dmscp0Q9qqzwEuC5iH.DxLlPa1MO'
WHERE id = 1
;
COMMIT;
このように、ロックを活用することによってイベントが発生する直前のステートに対するバリデーションを行い、バリデーションに失敗した場合はイベントそのものが発生しなかったことにすることができる。
もちろん、ロックを使う際はお決まりだが、デッドロックの可能性やパフォーマンスへの影響を考慮する必要があることに注意だ。
タイムトラベルクエリ
ESシステムが本領を発揮するのは、「現時点における最新のステート」ではなく「過去のある時点におけるステート」を知る必要があるときだ。
例えば、日本時間2021年7月4日16時23分15秒時点においてユーザー作成済みかつパスワード未変更のユーザーの一覧を取得したいとする。
(かなり恣意的な条件だが、これ以上例を複雑にしたくないのでお見逃しを。)
この場合、以下のクエリで対象のユーザーすべてのIDを取得することができる:
SET @as_of = CONVERT_TZ('2021-07-04 16:23:15', 'Asia/Tokyo', 'GMT');
SELECT id
FROM users AS u
WHERE EXISTS (
SELECT *
FROM user_created_events AS uce
INNER JOIN events AS e
ON e.id = uce.event_id
WHERE u.id = uce.user_id
AND e.`timestamp` <= @as_of
)
AND NOT EXISTS (
SELECT *
FROM user_password_changed_events AS upce
INNER JOIN events AS e
ON e.id = upce.event_id
WHERE u.id = upce.user_id
AND e.`timestamp` <= @as_of
)
;
過去に起こったイベントをすべて記録しているからこそ、こういった無理難題な要件を押し付けられても大概対応できてしまうのがESの真価である。
その他考察
あえてESの基盤としてリレーショナルデータベースを使う意義
ESのために作られたDBであるEventStoreや、その他NoSQL DBが存在する中、あえてリレーショナルデータベースを使う意義とはなにか?
主に以下の点にあると思う:
- 古くから存在する技術であるため:
- クライアントライブラリは大抵の言語に存在する
- NoSQLと比べて文献やインターネット上の情報が圧倒的に多い
- GUIや視覚化ツールなどのエコシステムが整っている
- SQLは曲がりなりにも規格に基づいているので、どのような挙動が保証されているか明確である
- NoSQLと比較してアドホックにクエリを作れるので、データ探索や緊急度の高いデータ抽出に強い
- イベントログをテーブルに保存することで、イベントログを直接クエリすることができる
- どのクラウドプラットフォームでも大抵リレーショナルデータベースサーバーを提供している
一方で、以下のような欠点があることも事実である:
- NoSQLを使っているというカッコつけができない(重要)
- 一般に、水平方向にスケールしづらいので高可用性を重視する場合NoSQLよりも向いているとは言い難い
マイクロサービスアーキテクチャとの関係性について
マイクロサービスアーキテクチャを導入することと、ESを導入することは個別の問題であって、一緒くたにすべきでない。
とはいうものの、マイクロサービスにおける課題であるサービス間のコミュニケーションやデータの隠蔽を実現するためにES(というよりも、ES + イベントドリブン)が有効であるのは間違いないし、マイクロサービスがESと抱き合わせにされるのもそれが原因かもしれない。
個人的には、ESの価値は未知の要件にも対応できる柔軟性にあり、マイクロサービスによってもたらされる(と謳われる)粗結合、サービス単位でのスケーリング、開発チームの独立性等を必要としない限りあえてマイクロサービスの道を進む必要はないかと思う。
また、「それぞれのマイクロサービスは独自のDBを持たなければならない」という「教義」に従う場合、リレーショナルデータベースを使う利点の多くが無効化されてしまうように思う。
例えば、DBが分離されることで複数サービスをまたぐトランザクションができなくなるので、two-phase commitやsagaなどを使ってアプリケーションレベルでトランザクションを管理することになり、コードの複雑化に繋がる。
また、テーブルのJOINも単一サービス内でしかすることができないため、複数サービスと関連するクエリをする場合、アプリケーションコードでJOINと同等の処理を行う必要が出てくることになる。
マイクロサービスの粒度がDDDにおけるbounded contextのような大きめの粒度であれば大抵のトランザクションやJOINはサービス内で自己完結できるので問題ないだろうが、aggregateごとにサービスを作るなどの極端なことをする場合はリレーショナルデータベースの強みを活かしきれない結果となりそうだ。
「どうしてもマイクロサービスにしたい」というこだわりや「マイクロサービス化しないとSLAが満たせない」といった具体的な要件がなければ、モノリシックに作るのが良いと思う。
イベントの種類ごとにテーブルを作らず、1テーブルのみで管理する手法について
本記事ではイベントの種類ごとにテーブルを作成する手法をとっているが、代替案としてすべてのイベントを events テーブルに保存し、 payload などのJSONカラムにイベントの詳細を格納する手法もある。
むしろこちらの手法のほうが、リレーショナルデータベースを使ってESを構築する例としてよく挙げられるように思う。
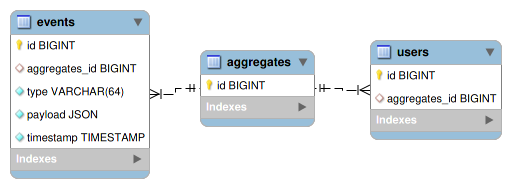
ここで、 events.type はイベント名である。また、eventsとその対象となるaggregateを紐付けるために aggregates テーブルで一意なIDを発番することとしている。
この手法の利点としては、イベントがスキーマレスのJSONに保存されるのでNoSQLを使っている雰囲気を出せる(重要)ことと、新規イベントの追加・既存イベントの変更のたびにスキーママイグレーションをする手間が省けるといったところだろうか?
「スキーママイグレーションが面倒」という欠点はあるものの、イベントの種類ごとにテーブルを作る手法には以下のような利点もある:
- ER図を見ればあるaggregateに対してどのようなイベントが存在するかが一目瞭然であり、ER図が一種のドキュメンテーションとして機能する
- マイグレーションスクリプトが現在に至るまでのビジネス要件やドメイン知識の変化の記録として機能する
- イベントの種類に特化したインデックスを作れるので、イベントログを直接クエリする場合の最適化がしやすい
- イベントの種類に特化した外部参照キーを作れるので、複数のaggregateのステートを一度に変化させるイベントの定義ができる
- クライアントライブラリの機能次第ではNoSQLよりも型セーフにイベントを扱える
RailsやLaravelのようにデータベースマイグレーションの管理コストが低いフレームワークを使っているのであれば、イベントの種類ごとにテーブルを作成する価値は十分にあると思う。
「ESはソフトウェアアーキテクチャではない」
ESの啓蒙家であるGreg Young曰く、ESはソフトウェアアーキテクチャではないためアプリケーション全体に適用するべきではなく、ビジネスクリティカルな部分はES、残りはCRUDといった選択的な適用が必要という。
この主張の背景には「ESはCRUDよりも複雑」という前提があるように思うが、ESの複雑さの多くはマイクロサービスアーキテクチャやeventual consistencyの採用(イベントログへの書き込みとステートへの投影の非同期化)、イベントのストリーミングといったESの本質ではない(がESと抱き合わせにされがちな)部分に起因すると思う。
その点、この記事で紹介したようなリレーショナルデータベースを基盤としたESであれば、CRUDベースのシステムとさほど複雑さは変わらないと思う。
むしろ、データ更新がすべてUPDATEという貧弱な語彙で片付けられがちなCRUDと比較して、ESでは更新の種類ごとにドメイン用語をふんだんに使ったイベントを定義する傾向があるため、よりドメイン知識を反映しやすいアプリケーションに繋がるのではないかと思う。
もちろん、ビジネス要件によってはそもそもESを採用すること自体が困難な場合もある。
例えば、ユーザーが退会した場合にそのユーザーに関するすべての個人情報を削除しなければならないという要件がある場合、愚直なESの実装ではイベントログを直接更新・削除する必要があり、append-onlyなイベントログというESの土台を壊すことになってしまう。
(個人情報は暗号化した状態で保存しておき、削除が必要になったら復号用の鍵を破棄するという手法もあるが、この場合個人情報を使ったクエリが不可能になる。)
こういったレアケースにおいてはESを使わないという選択肢を持つべきだが、その他の場合においてはESを採用することによって後出しの要件追加・変更にも柔軟に対応できるようになるため、積極的に使っていいように思う。