手前味噌エントリです。
ethOSで複数のGPUを駆使していると困った事がよく起きてました。
- 2〜3日ほど連続稼動しているとGPUがサボりだす(サボってても1枚あたり35Wほど電気を食べるため、無視はできない)
- autorestart という設定項目が local.conf 等にあるのだけど、機能しているところをまだみたことがない
- Web上( {rig-unique-address}.ethosdistro.com ) でリグの稼働状況を確認できるのですが、
情報の PULL はあっても PUSH がないという状態

つまり、 自発的に情報を取りに行かないとわからないのは困る、何かあったらあちらから通知を送ってほしいし、適切に対処してほしい という状況です。
よろしい、ならば自動化だ
という事で、作ったのがこちら https://github.com/uupaa/tools-ethos
- node.js + ESModules
- 数分に1度、ethOSの稼働状況やGPUの稼働状況を監視する
- GPU がサボりだしたら Slackに通知して、OSをリブートする
- /etc/rc.local に追加しておけば OS起動時に自動的に起動して監視を行う
- 問題発生時の挙動を事前にテスト可能
といった機能があります。
Slack に来る通知はこのようになります。
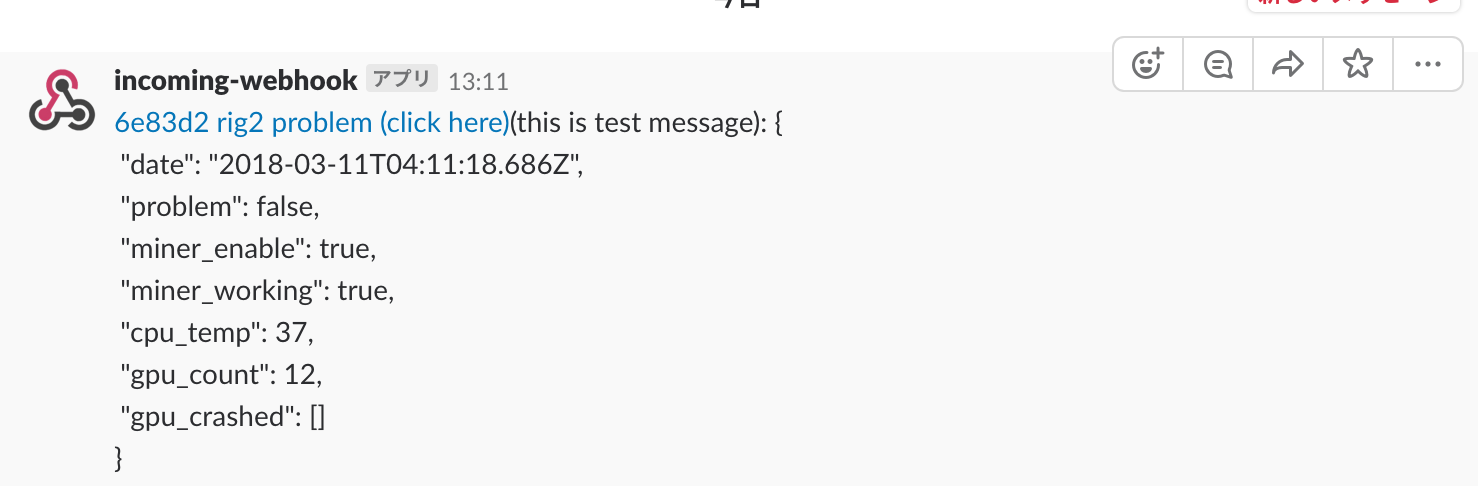
ethOS version 1.2.9 で動作を確認していますが、
おそらく version 1.3.0 以上でも動作すると思います(だめそうだったらコメントいただけると)