大学院の課題で下書きしたもの。長くなりすぎたので却下。ここに保管。
カーネルトリック
カーネルトリックは線形に分類できないデータを、特殊な関数に通すことにより超平面上で線形に分類できるようにする手法です。私が最もわかりやすかったGundersen (2019) の解説を紹介します。ユークリッド空間に二重の円として分類されているデータがあります。このうちの一つの点の座標を(x1, y1)とします。このx1とy1を使って (x1^2, y1^2, sqrt{x1*y1}) の3つの数字を生成します。この3つの数字を3次元空間のx, y, z座標としてプロットするとします。これは二次元だったデータをより高次元の3次元空間に写像したことになります。すべての点を変換すると、このように線形分離不可能だったデータが3次元空間ではある平面で分離できるようになります。
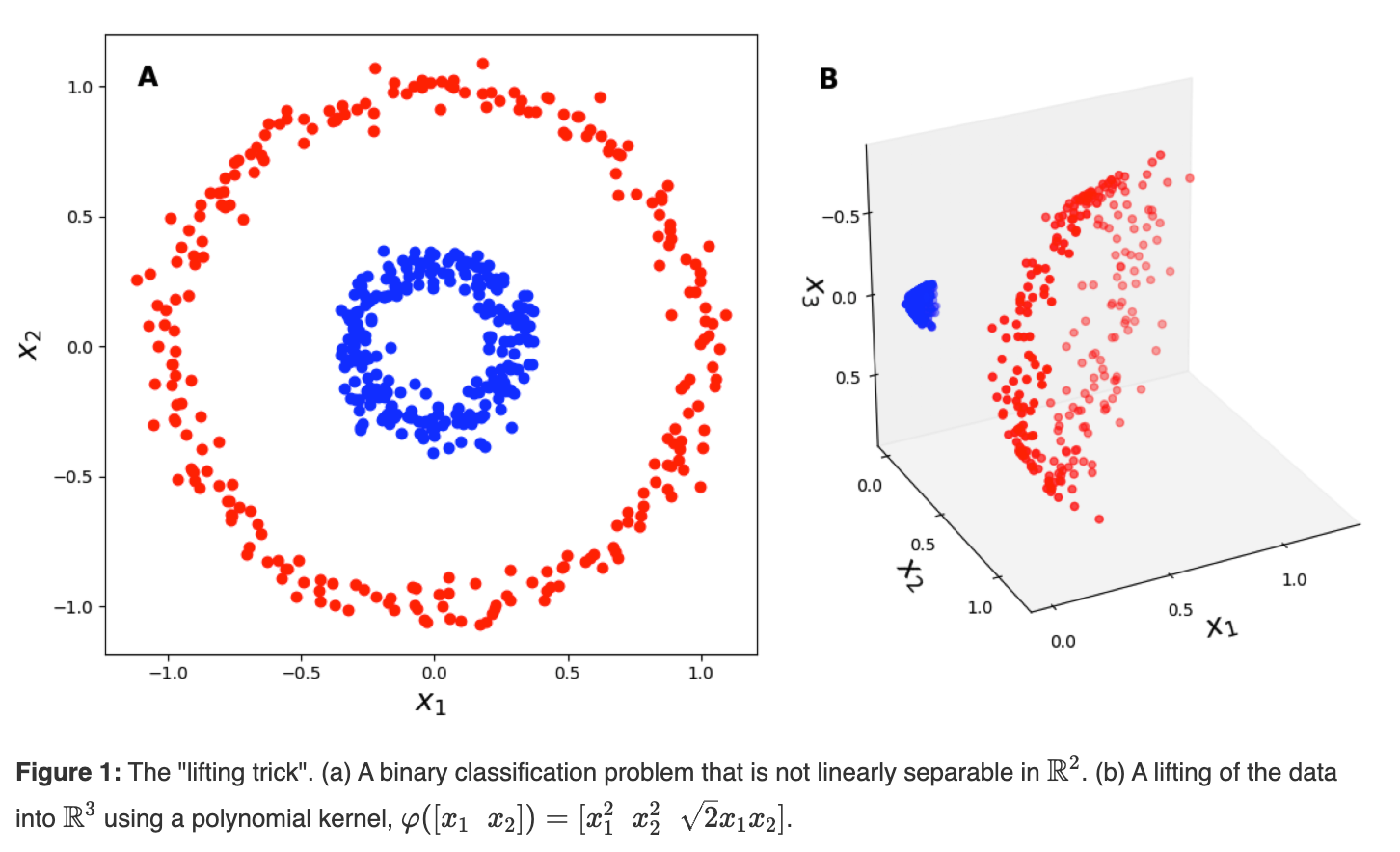
(Gundersen, 2019)
元のデータの時点で赤と青の点は明らかに分類されています。これは各点が赤か青かの「特徴」を持っていると言い換えられます。二次元座標ではそれらの特徴は線形分離不可能でしたが、三次元座標に写像したら線形分離可能になりました。この次元の変換をかっこよく呼ぶと、「データの特徴量を線形分離できるように抽出した」と言えます。言い換えると、カーネル関数は、データの特徴量を高次元空間に写像したとも言えます。カーネルトリックはこのような次元の変換を「暗黙的に」するとされています。ちょっと待って。上の画像は明示的に変換がされているじゃないか。実はこの画像はカーネル関数を視覚的に理解するための例で、実際のカーネル関数は写像に加えてもう一つのステップを含んでいます。そのステップは高次元空間内でのデータ同士の内積を計算するというものです。その目的はカーネル関数にデータの特徴量を抽出させ、データ間の類似度を計算することです。たとえば前述の例では、3次元のある点(x1, y1, z1) をまず原点(0, 0, 0)から移動するベクトルとして仮定します。これによりこのベクトルには距離と方向が生まれます。この(0, 0, 0) から (x1, y1, z1) に向かうベクトルをx1とします。さらに(0, 0, 0) から (x2, y2, z2) に向かうもう一つのベクトルをx2とします。このとき、ベクトルx1とベクトルx2の内積を計算することで、この2つのベクトルがどれだけ似ているかを計算できます。実際のカーネル関数では、3次元空間への写像を経ずに二次元空間にある(x1, y1) と(x2, y2)から直接3次元空間内の内積を計算します。その計算式は以下です。
φ(x)^T φ(y) = x1^2 * x2^2 + y1^2 * y2^2 + 2 * x1 * y1 * x2 * y2
SVMなどの分類器ではこの内積の値により類似度が判定され、分類に与える影響が調整されます。この式は元の次元変換で使った式 (x1^2, y1^2, sqrt(2)x1y1) に非常に似ているように見えます。一見不思議ですが、直接内積を計算したにも関わらず、特徴量を反映したものになるのです。カーネルトリックは特徴量を抽出するステップを飛ばしながらも、内積の計算によって結果的に特徴量を抽出していると言えるでしょう。(さっき私はカーネルトリックが「暗黙的」に写像をすると言いましたが、言い換えると、カーネルトリックの核心は、高次元空間への写像を「明示的に」計算しない点にあるようです。)カーネル関数はこのような特徴から、非線形分類を高次元空間で線形分類するために用いられるようになりました。ここでは座標の物理的な位置を例として用いましたが、実際には甘さと柔らかさの類似度といったように抽象的な特徴量を扱うこともできます。さらに無限次元の空間で類似度を計算することができるため、複雑なデータを分類することができるようになりますCortes & Vapnik, 1995)。
このようなカーネル関数を探す中で、技術者らは有用なカーネルとそうでは無いカーネルを見分けるために、カーネルが持つ性質を調べました。その結果、カーネル関数は正定値対称カーネルと負定値対称カーネルに分類されることがわかりました。それぞれのカーネル関数の特徴を以下に示します。
負定値対称カーネル
先ほど説明したようにカーネル関数はデータ間の類似度を計算する関数です。SVMを例にすると、SVMでは分離境界に近い点がサポートベクトルとして重要な役割を果たします。ある点の分類を行うとき、サポートベクトルとの類似度は重要な指標です。遠くのサポートベクトルに対しては値が小さくなり、近くのサポートベクトルに対しては値が大きくなる関数があれば、SVMはより正確に分類を行うことができます。このカーネル関数の例が負定値対称カーネルに分類されるユークリッド距離カーネルです。
K(x, y) = -||x - y||^2
このカーネル関数は2点間の距離を計算し、その距離の二乗を負にしたものです。このカーネル関数はデータ間の距離が遠いほど値が小さくなり、データ間の距離が近いほど値が大きくなります。最大の値はゼロであり正の値を取ることはありません。このように負の値を取ることが前提となっているカーネルは負定値対称カーネルと呼ばれます(Mohri, 2018)(*なお見分け方のセクションで補足があります)。しかし、ユークリッド距離カーネルは、データ間の距離をそのまま表現するものです。距離が遠いほど値を極端に小さくするため、外れ値に弱くなってしまいます。このような関数はあくまでデータ間の距離を類似度ではなく単純な距離として利用するクラスタリングなどの手法に利用されます。k-meansなどの距離を測るクラスタリング手法の関数を負定値対称カーネルとして理解することも可能でしょう。そのようなカーネルは Dissimilarity Kernel とも呼ばれ、類似度を計算する必要のあるSVMなどの機械学習アルゴリズムには適していません(37steps, 2013)。
正定値対称カーネル
正定値対称カーネルは負定値対称カーネルとは逆に、データ間の距離が近いほど値が大きくなり、データ間の距離が遠いほど値が小さくなる関数です。正定値対称カーネルの例はカーネルトリックの説明で利用した多項式カーネルです。最も有名なガウスカーネル(RBFカーネル)も正定値対称カーネルに分類されます。ベクトル間の内積が大きいほど類似度が高くなります。例えばSVMのガウシアンカーネルでは、近くのデータほど値が高くなります。近いのにラベルが異なるデータほどサポートベクターになりやすくなり、境界面の決定に大きな影響を与えます。類似度はこのように境界面の選定に必要な重要情報となっています(Mohri, 2018)。このようなSVMなどの機械学習アルゴリズムに適した正定値対称カーネルの性質は、マーサーの定理によって理論的な裏付けが与えられています(Mercer, 1909)。マーサーの定理は、特定の条件を満たすカーネル関数がヒルベルト空間における内積として表現できることを保証するものです。ヒルベルト空間とは、内積を計算できるベクトル空間のことで、ベクトルが長さ(ノルム)、角度、距離、直行性などの性質を持っている空間のことです(Hui, 2024)。
見分け方
例えば k(x,y)=1−∣x−y∣ は値が正にも負にもなり得るカーネル関数です。実はカーネル関数の出力だけで対称性を判別することはできず、データセット全体に対してカーネル関数を適用した結果を見る必要があります。最初に紹介した例では、点の集合であるデータをベクトルの集合として理解しました。カーネル関数をそのベクトルの集合全体に適用すると、その出力は行列として見ることができます。このベクトルの集合の内積を集めた行列をグラム行列と呼びます。グラム行列の固有値が全て非負であれば半正定値行列と呼ばれ、正定値対称カーネルとなります。一方、負定値対称カーネルは、グラム行列が条件付き負定値であるという条件を満たします(Haralick, n.d.)。この命名は行列が固有値によってpositive definite, negative definiteなどに分類されることからきています(Johnson, 1970)。ここでいう行列の固有値とは、行列がベクトルをどのように変換するかを表す指標であり、固有ベクトルと共に、行列の性質を理解する上で重要な役割を果たします。例えば物体の変形解析であれば、固有値は「物体がどの方向にどれだけ伸び縮みするか」を表します。類似度の判定であれば、固有値は「データがどのようにどの程度似ているか」を表すことでしょう。内積の求め方はカーネルトリックで用いる関数によって変わります。したがって、カーネル関数が導出したグラム行列の値を見ることで、正定値対称カーネルか負定値対称カーネルかを判定できます。
Conclusion
カーネル関数はデータの特徴量を高次元空間で抽出し、データ間の類似度を計算するために用いられます。正定値対称カーネルはデータ間の類似度を計算するために用いられ、SVMなどの機械学習アルゴリズムに適しています。一方、負定値対称カーネルはデータ間の距離を計算するために用いられ、クラスタリングなどの手法に用いられます。これらの判別はグラム行列の固有値を見ることで行われます。分類問題は適切なカーネル関数を選択することで解決できる可能性が高まるため、カーネル関数の性質を理解することが重要です。
Resources
37steps. (2013). Kernel-induced space versus the dissimilarity space - Pattern Recognition Tools. Retrieved on Feb 24, 2025, from https://37steps.com/2089/kernels-versus-disspace/
Cortes, C., Vapnik, V. Support-vector networks. Mach Learn 20, 273–297 (1995). https://doi.org/10.1007/BF00994018
Gundersen, G. (2019). Implicit Lifting and the Kernel Trick. Retrieved on Feb 24, 2025, from https://gregorygundersen.com/blog/2019/12/10/kernel-trick/
Haralick, R. (n.d.) The Kernel Trick. Retrieved on Feb 24, 2025, from https://www.haralick.org/ML/kernel_trick.pdf
Hui, J. (2024). Vector Space, Normed Space & Hilbert Space (Machine Learning) | by Jonathan Hui | Medium. Retrieved on Feb 24, 2025, from https://jonathan-hui.medium.com/vector-space-normed-space-hilbert-space-machine-learning-b43e5d0ac9d3
Johnson, C. R. (1970). Positive Definite Matrices. The American Mathematical Monthly, 77(3), 259–264. https://doi.org/10.2307/2317709
Mercer, J. (1909). Functions of Positive and Negative Type, and their Connection with the Theory of Integral Equations. Philosophical Transactions of the Royal Society of London. Series A, Containing Papers of a Mathematical or Physical Character, 209, 415–446. http://www.jstor.org/stable/91043
Mohri, M. (2018). Foundations of machine learning, Massachusetts Institute of Technology. https://cs.nyu.edu/~mohri/mlbook/