はじめに
今回は、完全無料・利用無制限というローカルLLM開発環境を、VS Code上に構築する方法をご紹介します。
ローカルで動作させるので、プライバシーの面でも安心です。
今回の主役は、LLMモデル実行ツールの「Ollama」と、VS Code拡張機能の「Continue」です。
この記事では、以下の2つの環境それぞれについて、ゼロからセットアップする手順を詳しく解説します。
- Windowsネイティブ環境でのセットアップ
- WSL (Windows Subsystem for Linux) 環境でのセットアップ
実行環境
- OS: Windows 11 Home
- CPU: AMD Ryzen 7 3700X 8-Core Processor 3.60 GHz
- RAM: 32GB
- GPU: GeForce RTX 3070 8GB
- WSL: Ubuntu 24.04.2 LTS
そもそもOllamaとContinueとは?
- Ollama (オラマ): ローカル環境で大規模言語モデル(LLM)を簡単に管理・実行できるオープンソースのツールです。
- Continue: VS CodeとOllamaを繋ぎ、AIと対話するためのインターフェースです。今回はこの拡張機能を通して、AIに指示を出したり、コードを生成させたりします。
Windowsネイティブ環境でのセットアップ
まずは、WSLを使わずにWindows上で直接開発している方向けの手順です。
ステップ1: Ollama for Windows のインストール
ブラウザで Ollama公式サイト にアクセスします。
「Download ↓」ボタンをクリックし、インストーラーをダウンロードします。

ダウンロードしたインストーラーを実行し、画面の指示に従ってインストールを完了させます。完了すると、PCの右下タスクトレイにOllamaのアイコンが表示されます。
ステップ2: モデルのダウンロード
次に、利用するモデルをダウンロードします。今回は「Llama 3 (8B)」を例にします。
Windowsの「コマンドプロンプト」または「PowerShell」を開きます。
以下のコマンドを実行してください。
ollama run llama3:8b
すると、今回使用するモデル(約4.7GB)のダウンロードが始まります。完了すると、successと表示され、ターミナルがチャットモードに切り替わります。これでモデルの準備は完了です。
pulling manifest
pulling 6a0746a1ec1a: 100% ▕██████████████████████████████████████████████████████████▏ 4.7 GB
pulling 4fa551d4f938: 100% ▕██████████████████████████████████████████████████████████▏ 12 KB
pulling 8ab4849b038c: 100% ▕██████████████████████████████████████████████████████████▏ 254 B
pulling 577073ffcc6c: 100% ▕██████████████████████████████████████████████████████████▏ 110 B
pulling 3f8eb4da87fa: 100% ▕██████████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
success
ステップ3: VS Code拡張機能「Continue」のインストール
VS Codeを開き、拡張機能マーケットプレイスで「Continue」を検索し、インストールします。

インストールが完了すると、アクティビティバーにContinueのアイコンが表示されるので

アイコンをクリックすると多くの場合、自動的にWindows上で動作しているOllamaを検出してくれます。
右下のモデル選択リストに、先ほどダウンロードした llama3:8b が表示されていればセットアップ完了です。
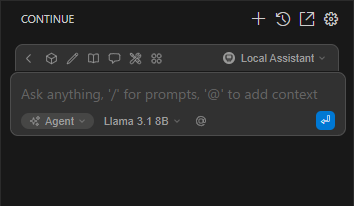
(ここでは 「Llama 3.1 8B」 と表示されています)
WSL環境でのセットアップ
次に、VS CodeをWSLに接続して開発している方向けの手順です。
ステップ1: WSLターミナルを開く
まず、セットアップを行うWSLのターミナルを起動します。(例: スタートメニューから「Ubuntu」を起動)
ステップ2: OllamaをWSL内にインストールする
Windows版とは異なり、コマンド1行でインストールします。
WSLターミナルに、以下のコマンドを貼り付けて実行します。
curl -fsSL https://ollama.com/install.sh | sh
スクリプトが自動でOllamaをセットアップしてくれます。
ステップ3: モデルをWSL内にダウンロードする
WSLターミナルで、以下のコマンドを実行します。
ollama run llama3:8b
WSLのファイルシステム内にモデルがダウンロードされます。
ステップ4: VS Code拡張機能「Continue」をWSL側にインストール
※ここの操作はWindowsネイティブ環境でのセットアップと全く同じ手順です。
【2025年7月23日 追記】筆者の最終的な構成
この記事を執筆するにあたり、私自身も様々なモデルを試した結果、最終的にWSL環境をメインで利用し、さらにAIの応答性能と品質を最大限に高めるため、役割ごとに最適なモデルを使い分けるという構成に落ち着きました。
以下に、その最終的な設定をご紹介します。
ステップ1: 3つの専門モデルをダウンロードする
まず、WSLのターミナルで、それぞれの役割を担当する3つのモデルをダウンロードします。
# チャット・編集用のメインモデル
ollama pull llama3.1:8b
# 自動補完用モデル
ollama pull qwen2.5-coder:1.5b-base
# 埋め込み用モデル
ollama pull nomic-embed-text:latest
ステップ2:役割を定義するconfig.yamlを設定
次に、Continueの設定ファイル(config.yaml)を以下のように編集します。
name: Local Assistant
version: 1.0.0
schema: v1
models:
- name: Llama 3.1 8B
provider: ollama
model: llama3.1:8b
roles:
- chat
- edit
- apply
- name: Qwen2.5-Coder 1.5B
provider: ollama
model: qwen2.5-coder:1.5b-base
roles:
- autocomplete
- name: Nomic Embed
provider: ollama
model: nomic-embed-text:latest
roles:
- embed
context:
- provider: code
- provider: docs
- provider: diff
- provider: terminal
- provider: problems
- provider: folder
- provider: codebase
おわりに
これにてプライバシーも配慮され、利用無制限。尚且つ完全無料のローカルLLM環境が構築できました。
最後までお読みいただき、ありがとうございました!