はじめに
本記事は エーピーコミュニケーションズ Advent Calendar 2023 3日目の記事です。
以下の記事で、オンプレミスのGPU付マシンにKubernetesクラスターをセットアップし、Azure Arcへ接続する手順を解説しました。
今回はその続きとして、Azure Machine Learing Studioで利用できるようにするところまでを解説します。
設定手順のつづき
Azure Machine Learning拡張機能をインストール
KubernetesクラスターにAzure ML用の拡張機能をインストールします。
Azure ML拡張機能は Azure Relay を利用します。サブスクリプションで有効化しておきましょう。
az provider register --namespace Microsoft.Relay
また、この手順の中で導入される一部のPodで以下のエラーが発生しました。
$ kubectl logs nvidia-device-plugin-daemonset-4gdk6 -n azureml
I1202 09:11:55.130686 1 main.go:154] Starting FS watcher.
E1202 09:11:55.130731 1 main.go:123] failed to create FS watcher: too many open files
これの対策として、あらかじめカーネルパラメータに変更を加えておきましょう。
設定変更前の値は以下です。
sysctl -a | grep "fs.inotify"
fs.inotify.max_queued_events = 16384
fs.inotify.max_user_instances = 128
fs.inotify.max_user_watches = 65536
以下のファイルを作成し、max_user_instances の値を適当に増やします。環境によりもっと増やす必要がある場合もあるでしょうが、今回の環境ではいったん 512 としました。
fs.inotify.max_user_instances = 512
以下コマンドで反映させます。
sudo systemctl restart systemd-sysctl.service
事前準備が終わったら、AzureポータルからAzure Arcのリソースを開き、左メニューから 拡張機能 に進みます。
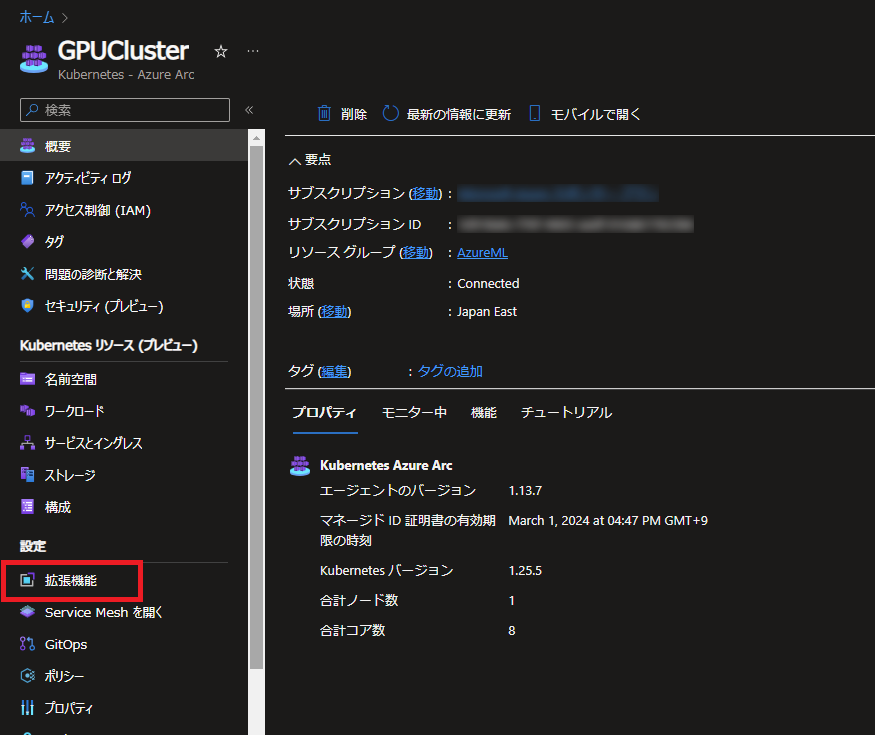
拡張機能の追加メニューで、一覧の中から Azure Machine Learning extention をクリックします。
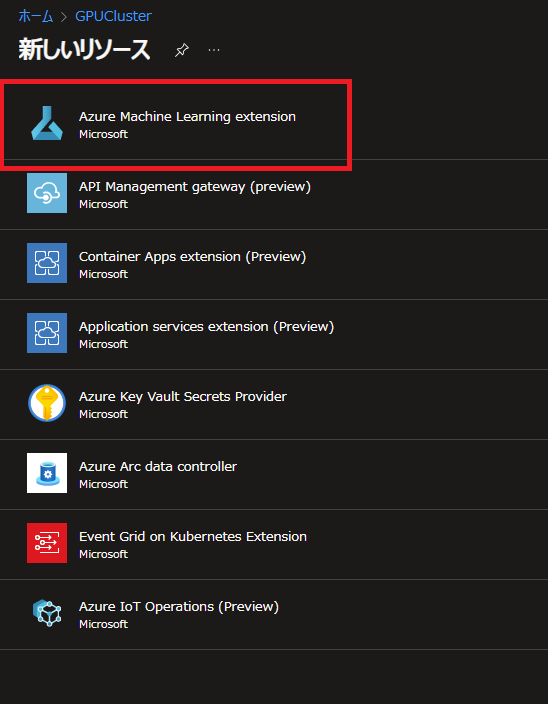
リソースの作成画面で情報を入力していきます。
Kubernetesクラスターを選択し、拡張機能の管理上の名前を入力します。ここでは azuremlextention としました。
Auto upgrade はお好みで選びましょう。ここでは有効にしています。
ワークロードを稼働させるノードを限定させたいときはNode Selector欄に条件を入力します。今回は単一ノードのKubernetesクラスターのため未入力で進めます。
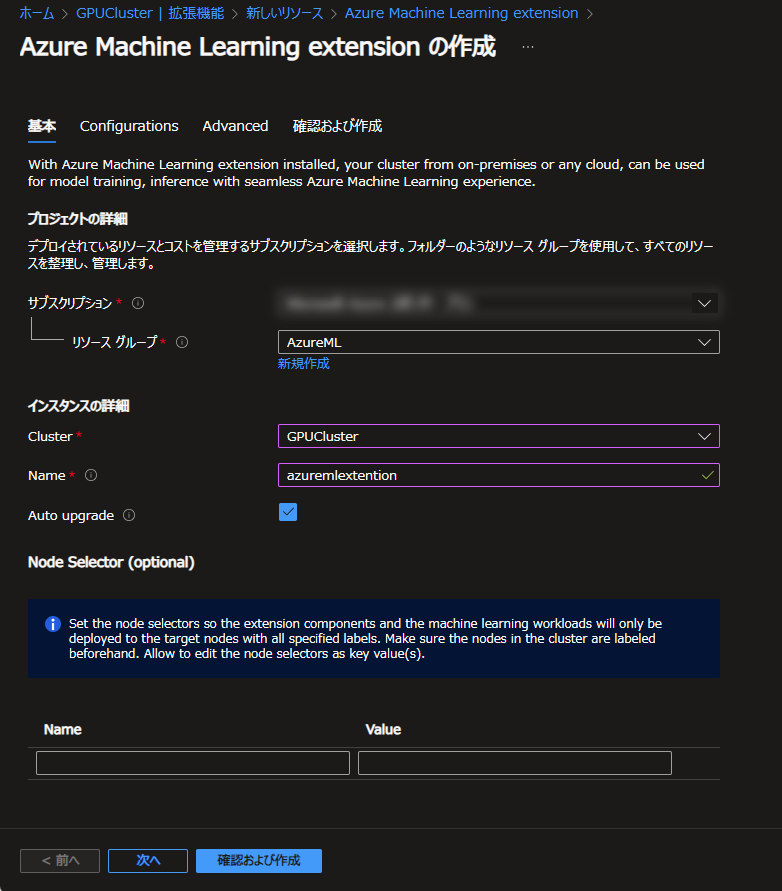
次の Configuration のタブでは、クラスターのAzure MLでの利用用途を設定します。モデルのトレーニングに利用するか、推論モデルをデプロイするエンドポイントとして利用するか、あるいはその両方です。
今回はトレーニング・推論モデルの両方にチェックをつけました。推論モデルのデプロイ先として利用する場合はKubernetes Serviceの設定も必要となります。
今回はお手軽に Node port Allow HTTP communication を選択することで、Load balancerサービスのための設定とSSL/TLS証明書の設定を省略します。
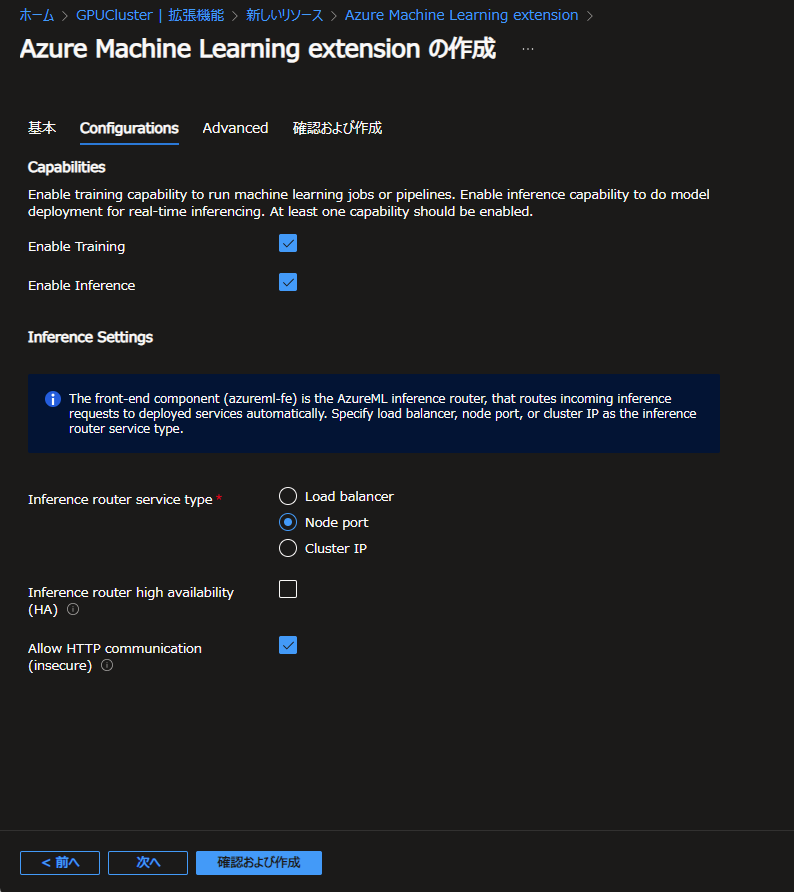
次の Advanced タブでは追加導入するプラグインなどを設定します。
それぞれ個別に手動インストールしていればここでの導入は省略可能ですが、今回は何も導入していないためここで必要なものをインストールしていきましょう。
一番最後の DCGM exporter のみ、ここでインストールすると OOMKilled でPodが起動しませんでした。必要に応じて手動でインストールすることとし、ここではそれ以外の3つをインストールします。DCGM exporterはGPUの利用状態のメトリックを取得するためのものです。導入しなくても使用そのものには影響ありません。
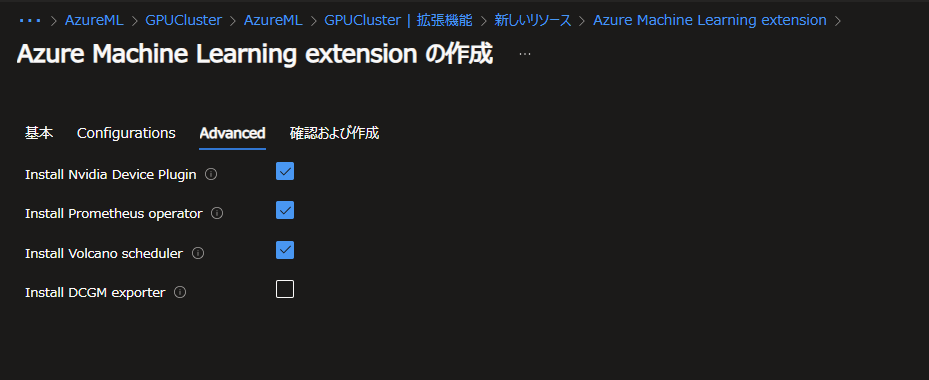
ここまで入力したら、確認画面にて作成ボタンをクリックし拡張機能を導入します。
完了すると、Kubernetesクラスターの azureml 名前空間内にPodが多数起動していることが確認できます。
NAME READY STATUS RESTARTS AGE
aml-operator-7d7fb554df-c6svs 2/2 Running 0 2m10s
amlarc-identity-controller-6bc498649d-rsz48 2/2 Running 0 2m9s
amlarc-identity-proxy-96c99c567-njbl4 2/2 Running 0 2m10s
azureml-fe-v2-65795b7bdb-g4mfs 4/4 Running 0 2m9s
azuremlextention-kube-state-metrics-74f786c6dc-hdsgx 1/1 Running 0 2m10s
azuremlextention-prometheus-operator-6bd9474d9b-swn52 1/1 Running 0 2m10s
gateway-65fbd55c4b-zqnhh 2/2 Running 0 2m9s
healthcheck 0/1 Completed 0 3m6s
inference-operator-controller-manager-6f55ffbf75-qrpzz 2/2 Running 0 2m10s
metrics-controller-manager-cfcd7fdc9-ncl52 2/2 Running 0 2m10s
nvidia-device-plugin-daemonset-krcbc 1/1 Running 0 2m10s
prometheus-prom-prometheus-0 2/2 Running 0 2m5s
relayserver-6774bd7fc6-pmkbj 2/2 Running 0 2m10s
relayserver-6774bd7fc6-rgbtw 2/2 Running 0 2m10s
volcano-admission-576669974f-b5b25 1/1 Running 0 2m10s
volcano-controllers-785698b5f7-4pt4g 1/1 Running 0 2m10s
volcano-scheduler-65f9cf55b4-7f257 1/1 Running 0 2m10s
Azure Machine Learning ワークスペースの作成
次にAzure Machine Learing ワークスペースを作成していきましょう。
Azureポータルから Azure Machine Learning を開き、新しいワークスペース を作成します。
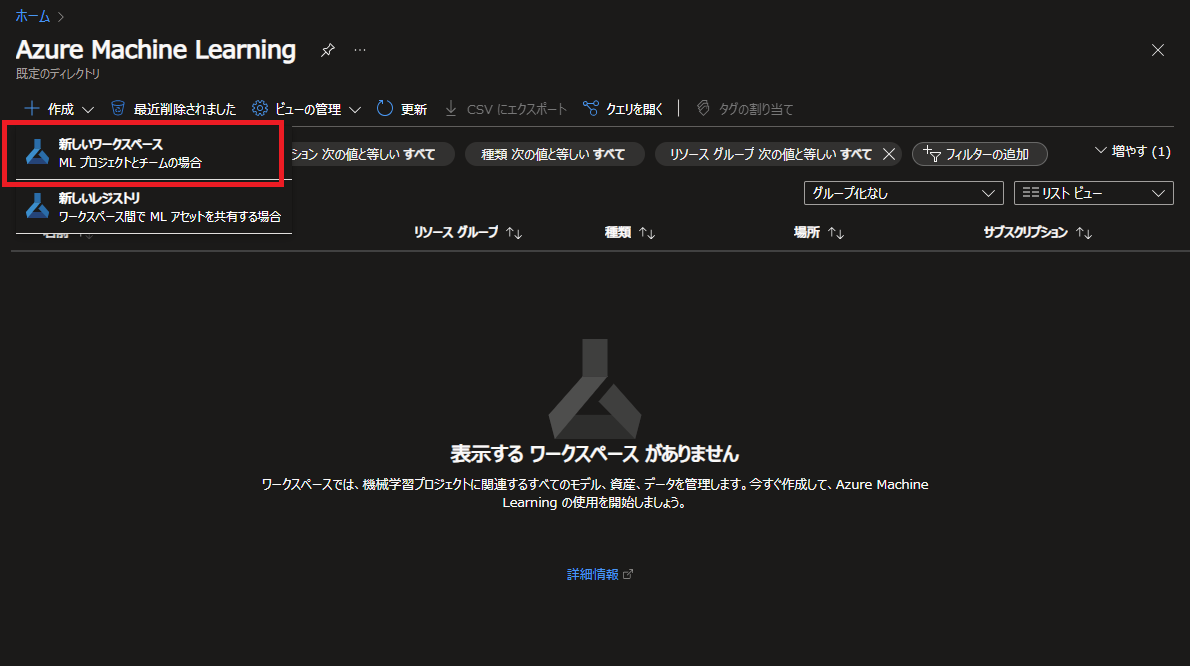
必要な情報を入力して作成を進めます。コンテナーレジストリは本記事の内容の範囲では必要ないので、作成は必須ではありません。
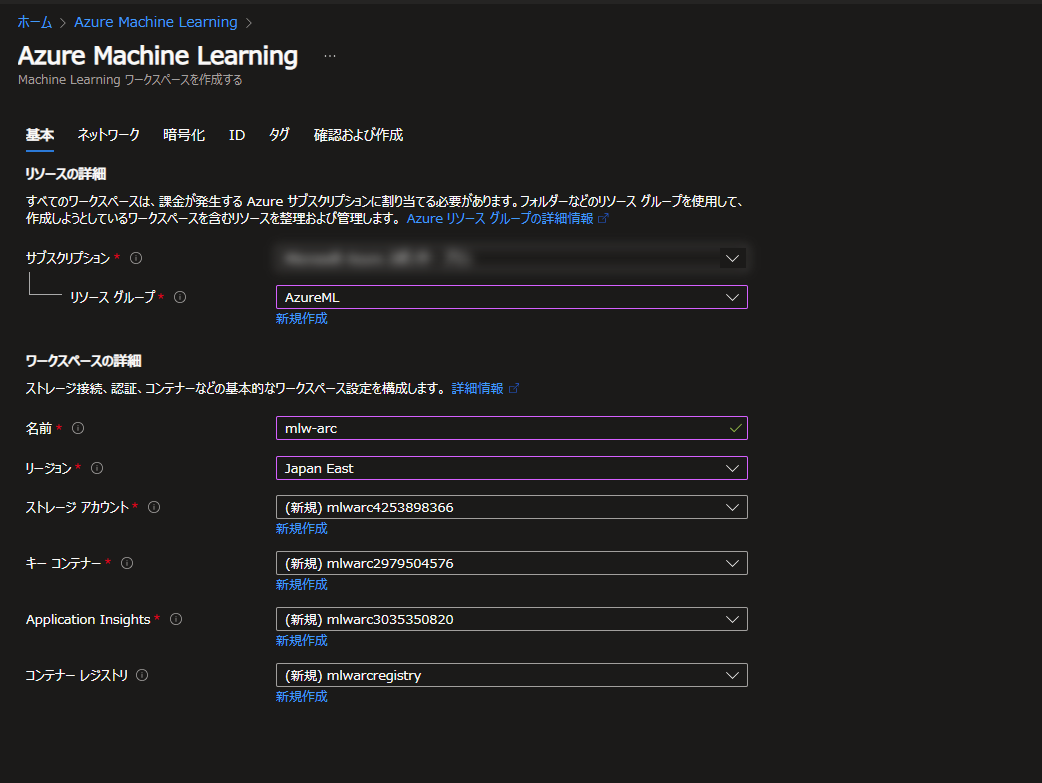
作成が完了したら、Azure MLワークスペースの画面から スタジオの起動 をクリックし、Machine Learning Studioを起動しましょう。
Machine Learning StudioからAzure Arc enabled Kubernetesクラスターを登録する
KubernetesクラスターをMachine Learning Studioで利用できるように登録を行います。
登録の前に、Kubernetesクラスター上にAzure MLジョブ用の名前空間を作成しておきます。ここでは azureml-workload という名前にしました。
kubectl create namespace azureml-workload
Namespaceを作成したらブラウザ上の作業に戻ります。
Machine Learning Studioの左メニュー コンピューティング を開き Kubernetesクラスター タブを選択、+ 新規 ボタンをクリックします。
新規の中には Kubernetes と AksCompute の2種類が表示されますが、Kubernetes を選びます。AksCompute はv1用の古いメニューであり、最新のv2ではKubernetesを利用します。(そもそもAksComputeではAKSしか登録できず、Azure Arc enabled Kubernetesクラスターは登録できません)
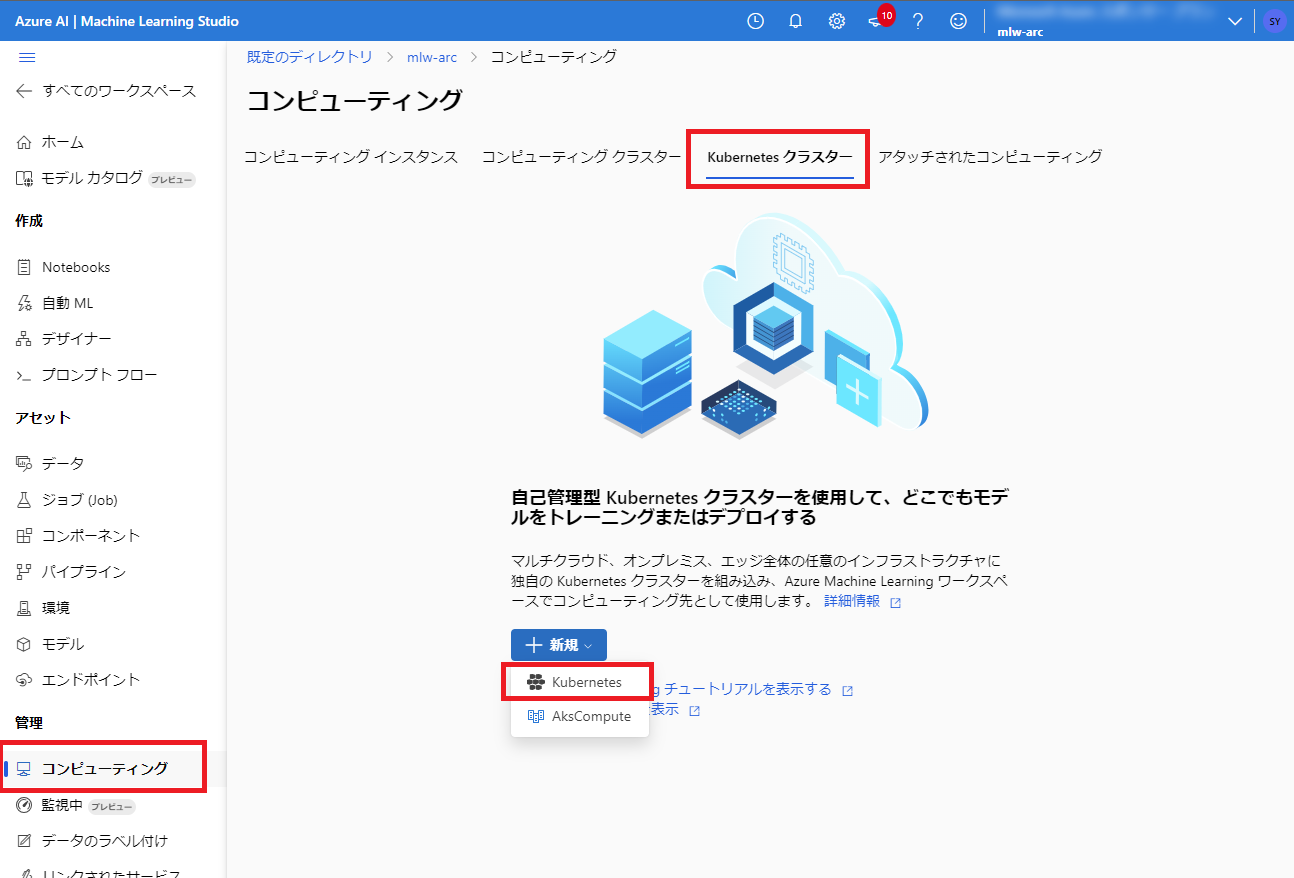
Azure ML上で管理するための名前を入力し、クラスターを選択します。名前空間欄には先ほど作成した名前空間を入力します。マネージドIDも割り当てておきましょう。
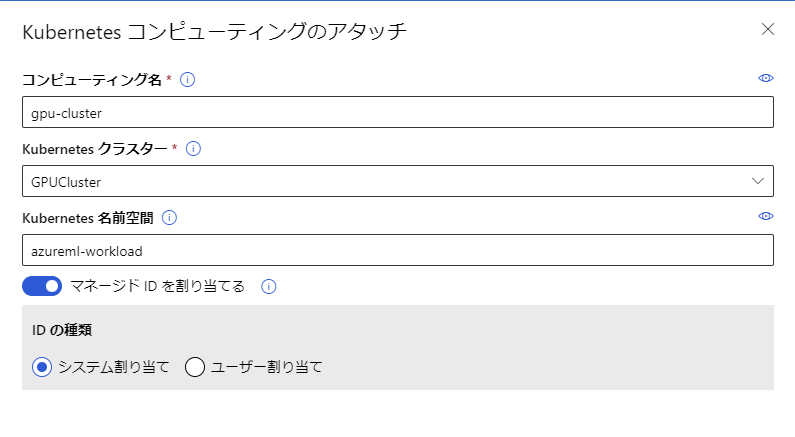
これでMachine Learning StudioにKubernetesクラスターを登録できました。
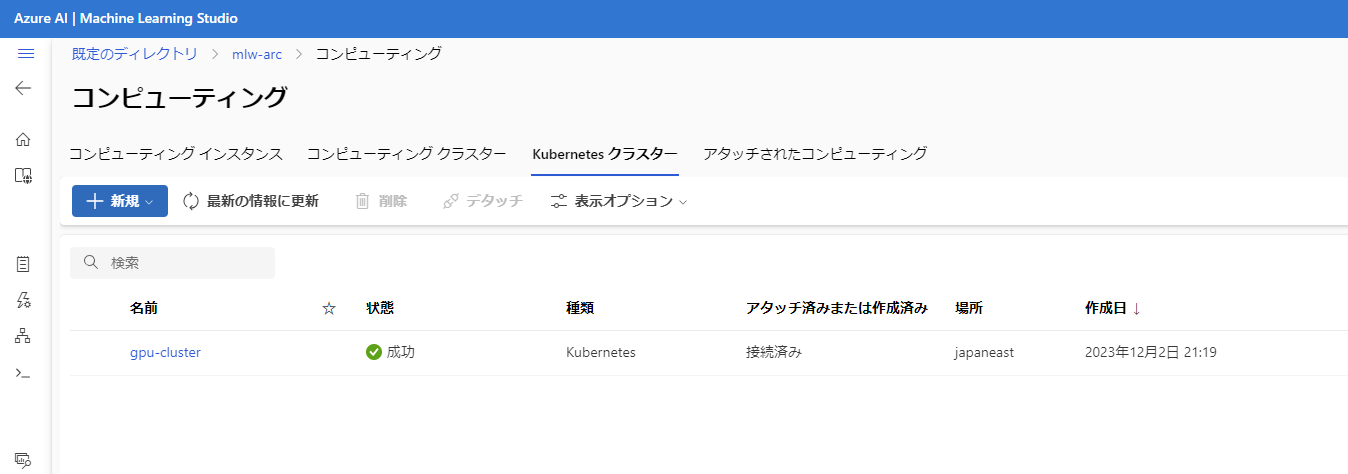
ただしこのままではGPUは利用できません。
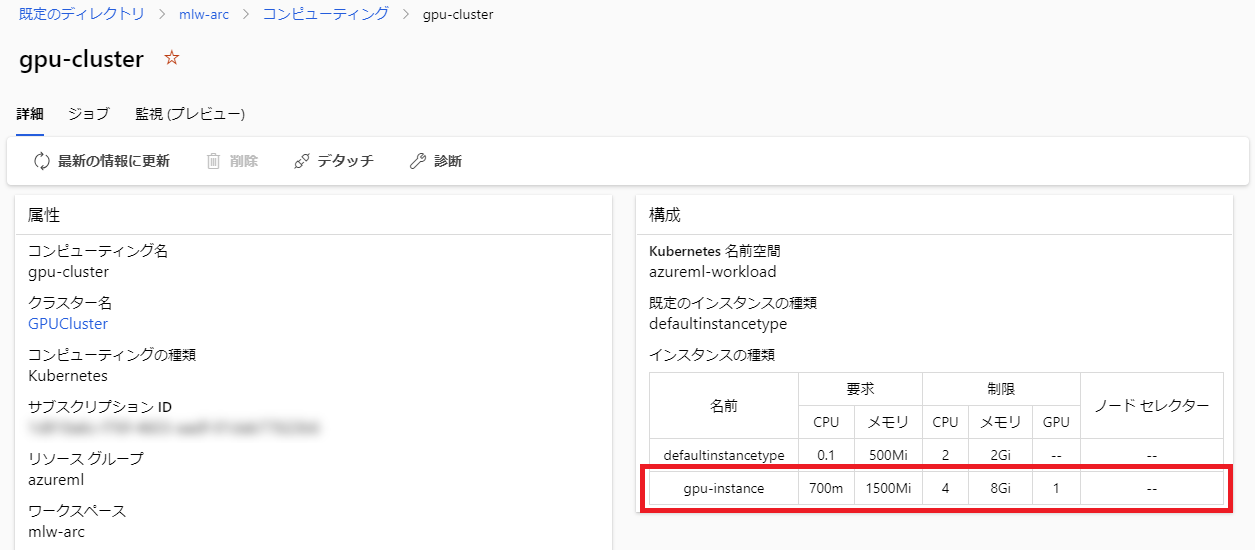
Azure MLではKubernetesクラスター内でジョブを稼働させる際のリソース割り当て量を インスタンス として構成しますが、デフォルトで作成される defaultinstancetype は GPUの割り当てが無し となっているためです。
ですので、GPUを利用できるインスタンスタイプを定義してあげましょう。
インスタンスタイプの定義はKubernetes上のCRDとして作成します。
以下のYAMLを作成し、Kubernetesクラスターにデプロイします。
apiVersion: amlarc.azureml.com/v1alpha1
kind: InstanceType
metadata:
name: gpu-instance
spec:
resources:
limits:
cpu: "4"
nvidia.com/gpu: 1
memory: "8Gi"
requests:
cpu: "700m"
memory: "1500Mi"
kubectl apply -f azureml_gpu-instance.yml
これで gpu-instance というインスタンスタイプが追加されました。GPUが必要なジョブではこのインスタンスタイプを指定することを忘れないようにしましょう。
動作確認
まずは簡単なジョブを実行して動作確認してみましょう。
端末にAzure ML用のAzure CLI拡張機能をインストールします。
az extension add -n ml -y
以下のYAMLを準備します。compute にML Studioに登録したKubernetesクラスター名を指定しています。インスタンスの指定を省略しているため、このジョブは defaultinstancetype で起動します。
command: python -c "print('Hello world!')"
environment:
image: library/python:latest
compute: azureml:gpu-cluster
YAMLファイル, リソースグループ, Azure MLワークスペースを指定して、以下のコマンドを実行します。
az ml job create -f job_test.yml -g AzureML -w mlw-arc
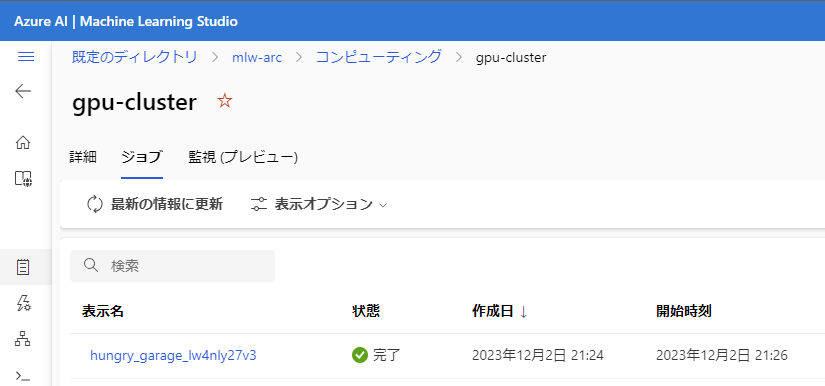
問題なく実行できていれば、ML StudioでKubernetesクラスターのジョブの一覧に以下のように表示されます。
出力とログ 欄を見ると、以下のように Hello world! と表示されていることが確認できます。
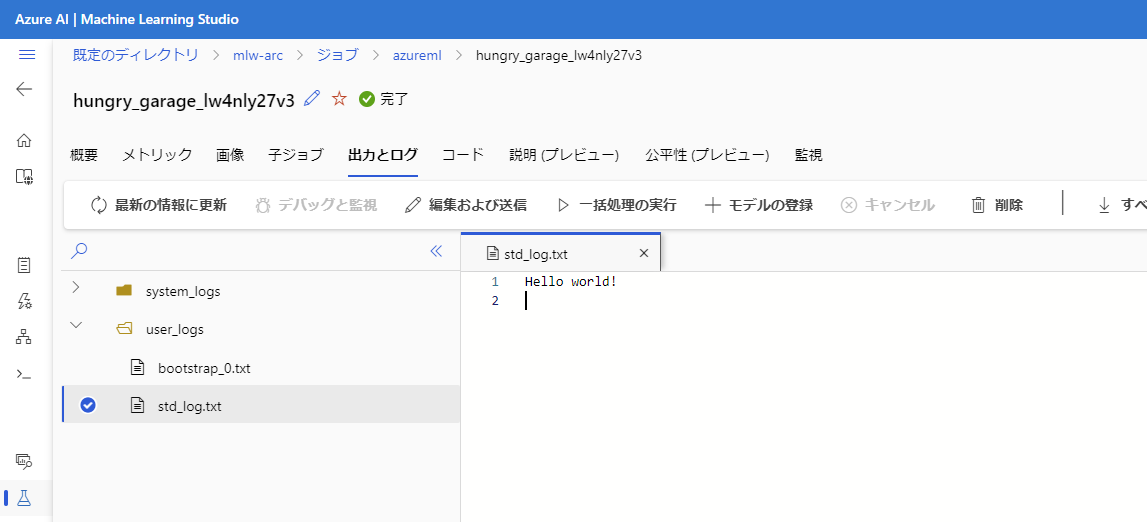
問題なくAzure MLのジョブがKubernetesクラスター上で動きそうですね!
GPUを利用したトレーニングの実行
以下のAzureドキュメントのPyTorchのトレーニングを参考にして動かしてみましょう。
必要なファイルを配置するためのディレクトリを作成します。
mkdir pytorch_test
cd pytorch_test
mkdir src
トレーニング用のPythonスクリプトを src ディレクトリにダウンロードします。
https://github.com/Azure/azureml-examples/blob/main/sdk/python/jobs/single-step/pytorch/train-hyperparameter-tune-deploy-with-pytorch/src/pytorch_train.py
curl https://raw.githubusercontent.com/Azure/azureml-examples/main/sdk/python/jobs/single-step/pytorch/train-hyperparameter-tune-deploy-with-pytorch/src/pytorch_train.py -o src/pytorch_train.py
トレーニングジョブを定義したYAMLファイルを作成します。GPUを使うので、resources.instance_type に gpu-instance を指定するのを忘れないようにしましょう。
inputs:
num_epochs: 30
learning_rate: 0.001
momentum: 0.9
output_dir: "./outputs"
code: "./src/"
command: "python pytorch_train.py --num_epochs ${{inputs.num_epochs}} --output_dir ${{inputs.output_dir}}"
environment:
image: "mcr.microsoft.com/azureml/curated/acpt-pytorch-1.13-cuda11.7:24"
compute: "azureml:gpu-cluster"
resources:
instance_type: "gpu-instance"
experiment_name: "pytorch-birds"
display_name: "pytorch-birds-image"
以下のようなファイル配置になります。
.
├── src
│ └── pytorch_train.py
└── trainingjob_pytorch.yml
ファイルの準備ができたらジョブを実行してみましょう。
az ml job create -f trainingjob_pytorch.yml -g AzureML -w mlw-arc
ジョブが完了すると、以下のようにメトリックが確認できます。
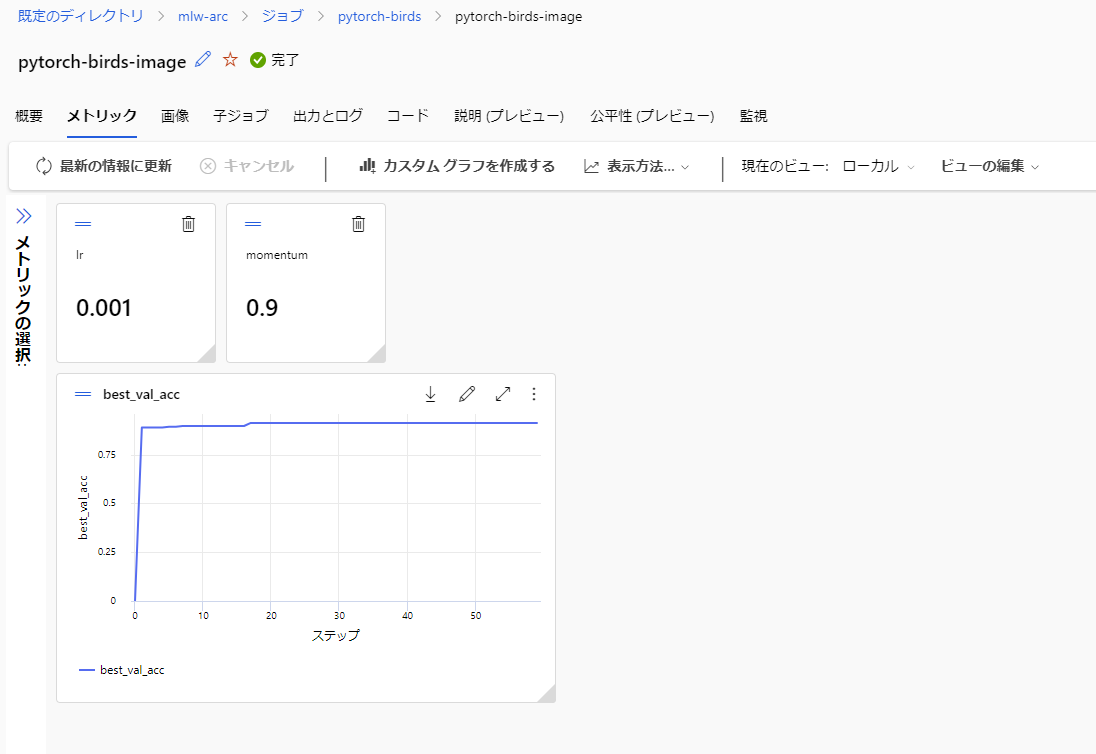
このジョブの実行結果を基にモデルを作成します。
ジョブの概要メニューの上部から + モデルの登録 をクリックします。
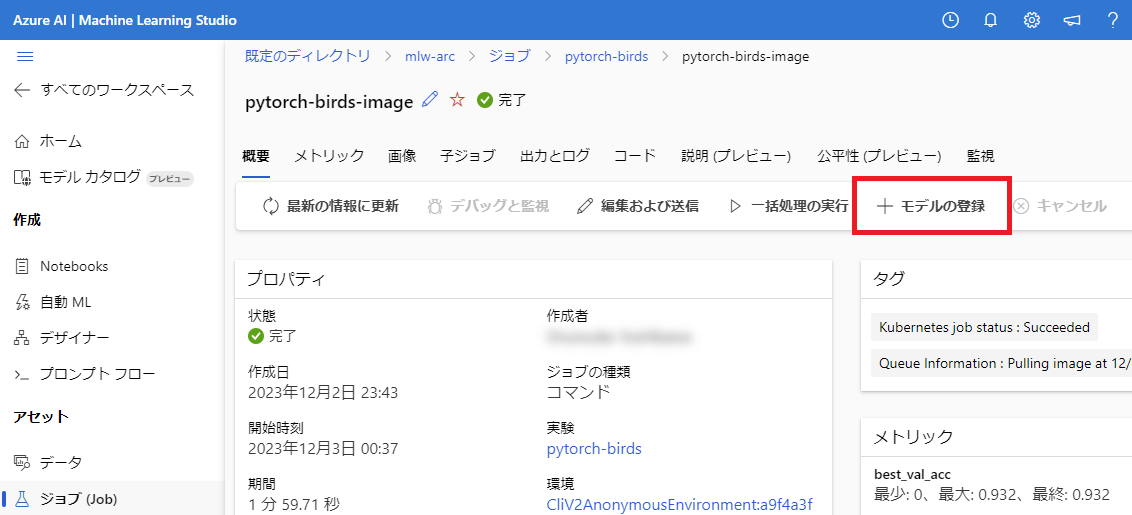
モデル登録のウィザードが表示されます。
モデルの種類で Unspecidied型、ジョブ出力で outputs を選択します。
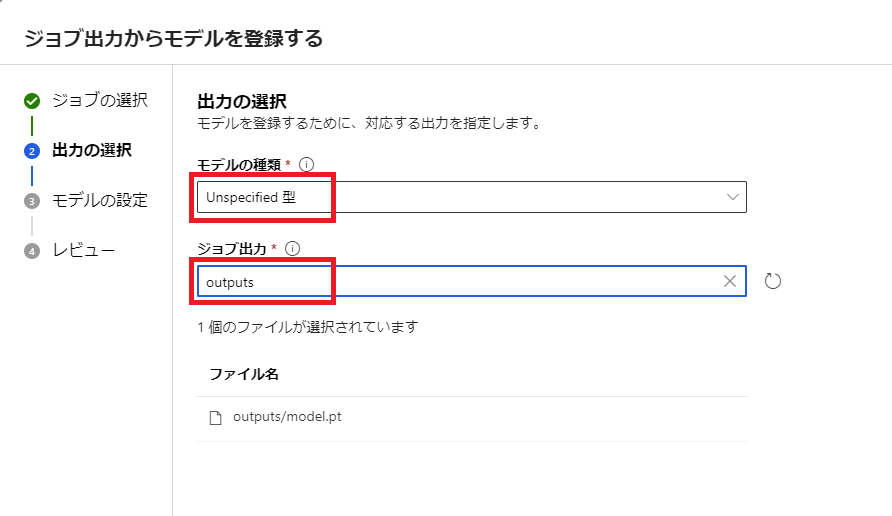
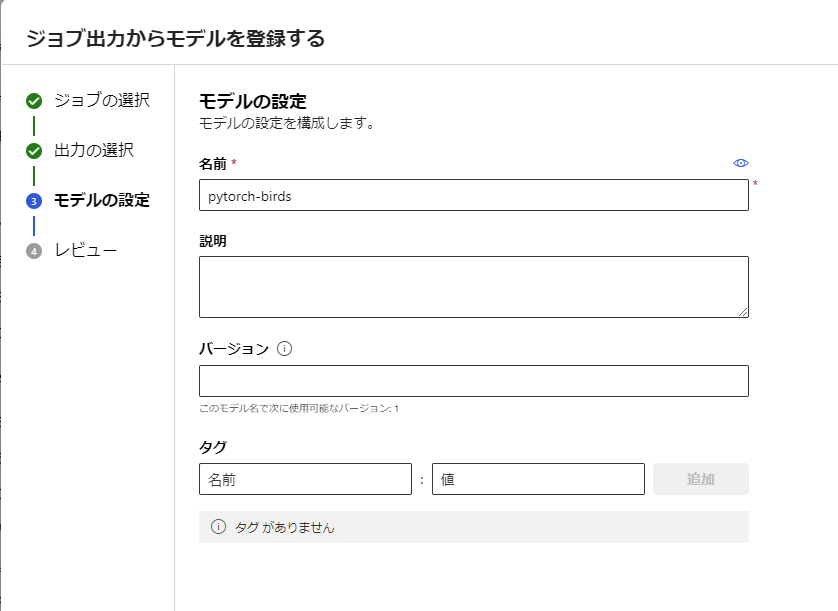
次の画面ではモデルの情報を入力します。
ここではモデル名に pytorch-birds を入力し、以下は空白のままとしました。
最後にレビュー画面が表示されます。登録 ボタンをクリックして完了します。
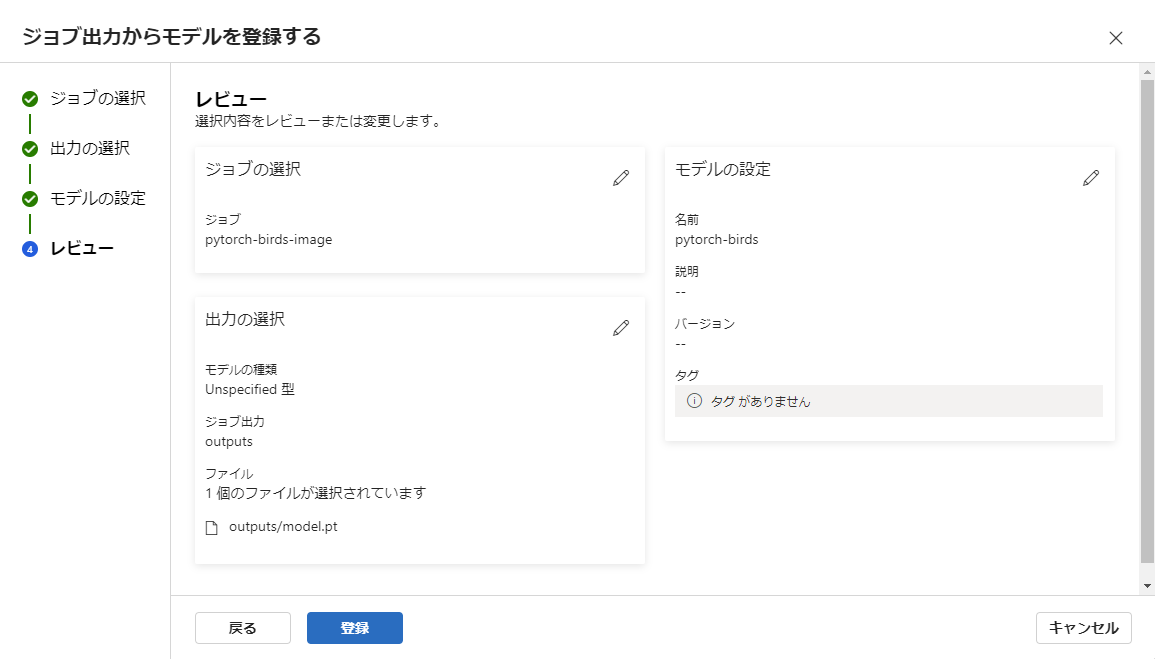
これで、トレーニングの実行とその結果のモデル作成が完了しました。
モデルのデプロイ
では、トレーニングしたモデルをKubernetesクラスター上にデプロイしてみましょう。
Azure MLでモデルをデプロイする場合、まず エンドポイント を作成する必要があります。
以下のYAMLを作成し、
name: arc-endpoint
compute: azureml:gpu-cluster
auth_mode: Key
次のコマンドで作成します。
az ml online-endpoint create -f endpoint.yml -g AzureML -w mlw-arc
作成が完了すると、ML Studioの エンドポイント メニューに表示されます。
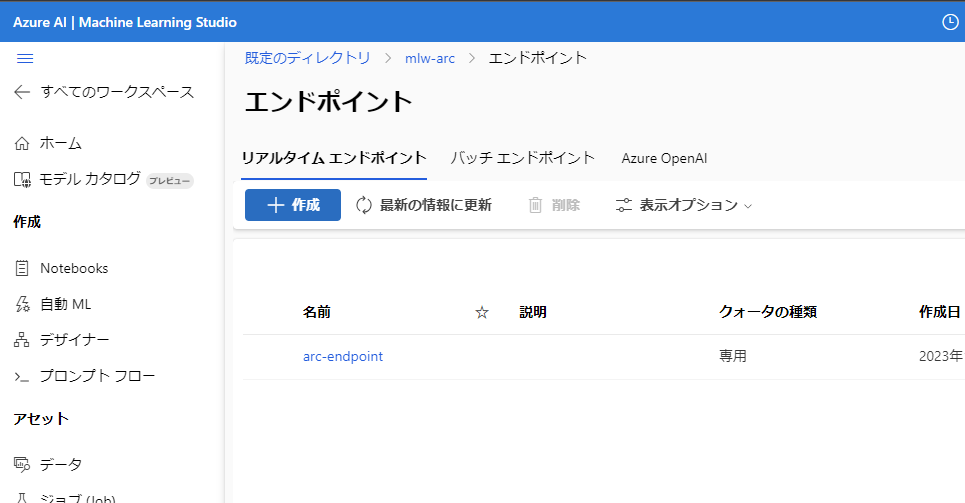
エンドポイントのURLをみると、Azure ML拡張機能のインストール時に指定したように、HTTPかつNodePortを利用していることが確認できます。
では、このエンドポイントにモデルをデプロイしていきましょう。
スコアリング用のPythonスクリプトをダウンロードします。
https://github.com/Azure/azureml-examples/blob/main/sdk/python/jobs/single-step/pytorch/train-hyperparameter-tune-deploy-with-pytorch/score/score.py
mkdir score
curl https://raw.githubusercontent.com/Azure/azureml-examples/main/sdk/python/jobs/single-step/pytorch/train-hyperparameter-tune-deploy-with-pytorch/score/score.py -o score/score.py
デプロイ用のYAMLファイルを作成します。
name: "pytorch-birds-blue"
app_insights_enabled: true
endpoint_name: "arc-endpoint"
model: "azureml:pytorch-birds:1"
code_configuration:
code: "./score/"
scoring_script: "score.py"
environment:
image: "mcr.microsoft.com/azureml/curated/acpt-pytorch-1.13-cuda11.7:24"
instance_type: "gpu-instance"
instance_count: 1
type: "kubernetes"
ディレクトリ構造は以下のようになります。
.
├── deployment.yml
├── endpoint.yml
├── score
│ └── score.py
├── src
│ └── pytorch_train.py
└── trainingjob_pytorch.yml
以下のコマンドでモデルをデプロイします。
az ml online-deployment create -f deployment.yml -g AzureML -w mlw-arc
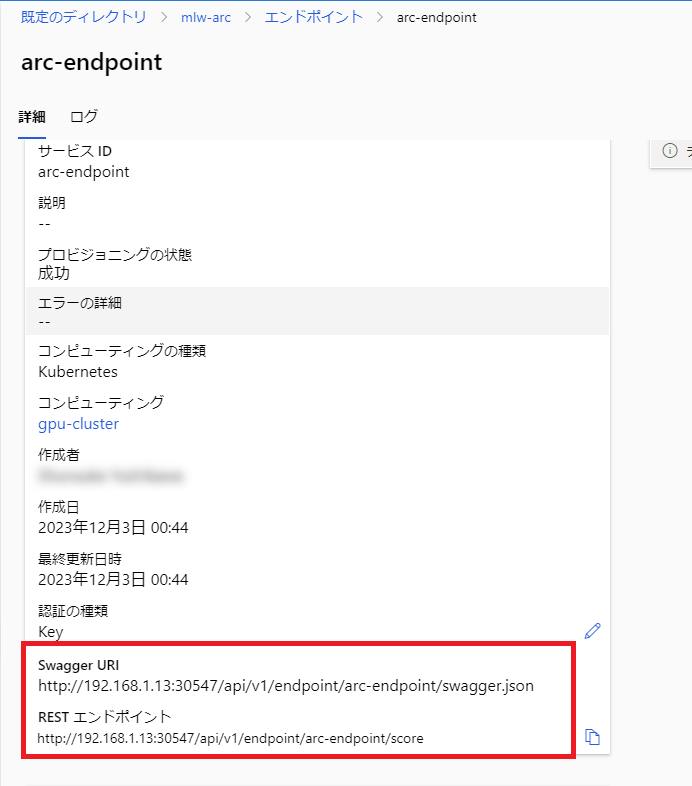
デプロイが成功すると、エンドポイントのページにデプロイの情報が表示されます。
Kubernetesクラスター上にもPodが起動しています。
kubectl get pod -n azureml-workload
NAME READY STATUS RESTARTS AGE
pytorch-birds-blue-arc-endpoint-6b656954f-sg4cl 2/2 Running 0 98s
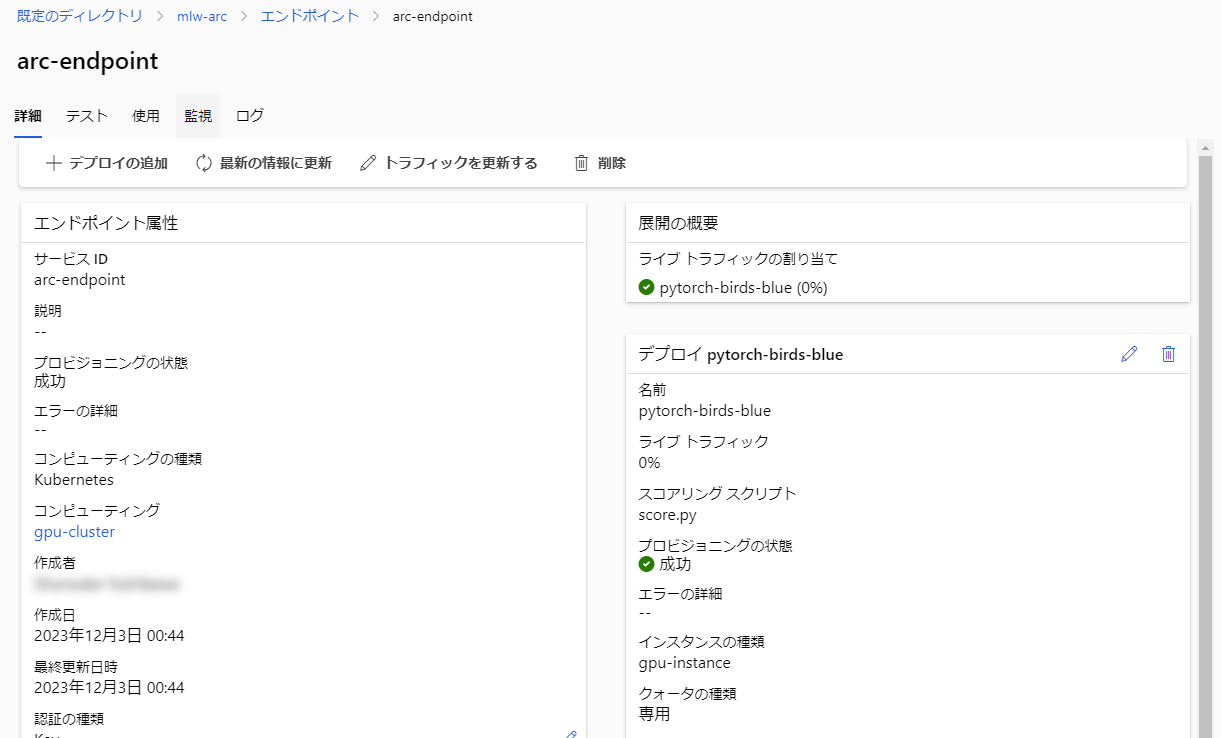
デプロイ直後の状態ではエンドポイント宛のトラフィックがデプロイに連携されない状態です(0%)
トラフィックを更新する をクリックし、デプロイのトラフィック割り当てを 100% に設定しましょう。
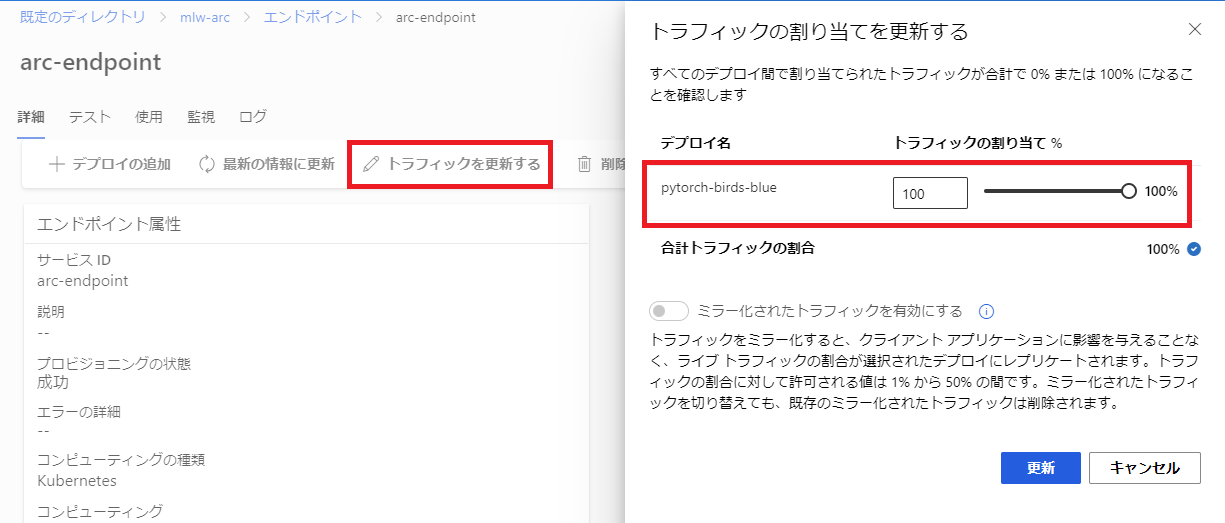
これでKubernetesクラスターのエンドポイントが利用できるようになりました。
エンドポイントのテスト
今回サンプルで利用したモデルは鳥の種類を分類するためのものです。
テスト用の画像もリポジトリから借りてきました。

この画像をエンドポイントに投げて結果を表示するPythonスクリプトを準備します。
スクリプト内の subscription_id の値として AzureサブスクリプションID を指定してください。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from PIL import Image
from torchvision import transforms
import torch
import json
def preprocess(image_file):
"""Preprocess the input image."""
data_transforms = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
image = Image.open(image_file)
image = data_transforms(image).float()
image = image.clone().detach()
image = image.unsqueeze(0)
return image.numpy()
credential = DefaultAzureCredential()
ml_client = MLClient(
credential=credential,
subscription_id="<AzureのサブスクリプションID>",
resource_group_name="AzureML",
workspace_name="mlw-arc"
)
image_data = preprocess("test_img.jpg")
input_data = json.dumps({"data": image_data.tolist()})
with open("request.json", "w") as outfile:
outfile.write(input_data)
result = ml_client.online_endpoints.invoke(
endpoint_name="arc-endpoint",
request_file="request.json",
deployment_name="pytorch-birds-blue"
)
print(result)
これを実行してみましょう。
# テスト用画像ファイルのダウンロード
curl https://raw.githubusercontent.com/Azure/azureml-examples/main/sdk/python/jobs/single-step/pytorch/train-hyperparameter-tune-deploy-with-pytorch/test_img.jpg -o test_img.jpg
# 必要なパッケージのインストール
pip install azure-ai-ml azure-identity pillow torch torchvision
# スクリプトの実行
python endpoint_test.py
結果は以下のように出力されました。
{"label": "turkey", "probability": "0.5904749"}
シチメンチョウである確率が高いと出ました。無事動いているようです。
おわりに
Azure Arc enabled KubernetesクラスターをAzure Machine Learning Studioのコンピューティングインスタンスとして活用する方法を2回に分けて紹介しました。
前半ではNVIDIAのGPUを搭載したマシンをKubernetesクラスターで利用するための NVIDIA Container Toolkit を導入する方法を、後半である今回はAzure Machine Learning Studioへの接続と利用方法を中心に解説しました。
今回の内容では触れていませんが、オンプレミスのKubernetesクラスターを活用できるメリットとして、「オンプレミス上にあるデータをクラウド上にアップロードしなくてもAzure MLを利用したモデルトレーニングができる」という点が挙げられます。
データが大量にありすぎてクラウド上にアップロードできない、あるいはガバナンス上外部に持ち出すことが困難という状況に対し、有効に活用できるのではないかと思います。
世の中にまとまった情報がなかなか少ないので、環境構築するうえで本記事が参考になれば幸いです。