SRA Advent Calendarの4日目です。
ネットワークシステムサービス第1事業部の ふじまき です。
oVirt CentOS Host(a.k.a. Thick Host)のHyperconverged InfrastructureのSelf-Hosted Engine環境を4.3から4.4へアップグレードする方法を紹介します。
公式のアップグレード手順はこちらですが、これはFC/iSCSI接続の共有ディスクのある構成向けなので、Hyperconverged Infrastructure(以下、HCI)環境では使えません。
ということで公式なHCI環境向けアップグレード手順が無い中で試行錯誤して捻りだした非公式アップグレード手順を紹介したいと思います。
なお、商用版のRed Hat Hyperconverged Infrastructure for VirtualizationではThick Hostはサポート外となっているので今後も公式の手順は出てこない可能性が高いです。(この構成止めた方がよいかも)
注意事項
- 最悪の事態(クラスタ全滅、全データロスト)に備えてバックアップを取っておきましょう。

- 全ての手順が必須かどうかは不明です。(不要な作業が含まれている可能性あり)
用語
ここでは以下とします。
- 物理ホスト:oVirtおよびGlusterノードを兼務する物理サーバ
- EngineVM:Web管理コンソールを提供するoVirt管理用仮想マシン
前提条件
- 全ての物理ホスト及びEngineVMはoVirt 4.3.10までアップグレード済である事
- 全ての仮想マシンの互換性レベルが4.3になっている事(未適用は×)
- 新しいEngineVMのデプロイ先となる新規Glusterボリュームを作るための未使用領域が物理ホストに存在すること。商用版だと100GBと書かれていますが、対話形式のデプロイでは51GB以上を入力するように求められるので多少足りなくてもOKなはず。(ケチるところでもないけど)
作業の流れ
- 事前準備
- EngineVMのバックアップ
- 物理ホスト1号機をCentOS 8で再インストール
- 物理ホスト1号機をGlusterに再組み込み
- 新規のGlusterボリューム作成
- 物理ホスト1号機でoVirt 4.4のEngine VMをデプロイ
- 残りの物理ホストもCentOS 8インストール&Gluster再組み込み&再インストール
- クラスター&データセンター互換バージョン更新
事前準備
- NFSベースのストレージドメインのデタッチ
物理ホストにNFSベースのストレージドメイン(ISO またはエクスポートドメイン)を置いている場合はデタッチします。必要な中身を退避した後、ストレージドメインをメンテナンスモードに切り替え→デタッチします。
なお、物理ホストは全部再インストールするので最終的には作り直してリストアすることになります。 - 管理ネットワーク(ovirtmgmt)以外のネットワークの必須プロパティを無効にします。
バックアップ
バックアップは2種類あります。
EngineVMのバックアップ
いきなり公式アップグレード手順から逸れますが、EngineVMのバックアップを以下で取得
物理ホストの1台にsshログインしてローカルメンテナンスモードに切り替え
$ sudo hosted-engine --set-maintenance --mode=local
EngineVMにsshログインしてバックアップを取得
$ sudo engine-backup --scope=all --mode=backup \
--file=backup4310.bck --log=backuplog.log
取得したバックアップを別サーバ(oVirtクラスタ外)に退避
$ scp backup4310.bck backup.example.co.jp:~/
物理ホスト1台をメンテナンスモードにしてEngineVMのバックアップを取得するのは以前(oVirt 4.2の頃)の手順ですが、これでOKでした。
なお、この時ローカルメンテナンスにした物理ホストは最初にCentOS 8を再インストールする物理ホストになります。
物理ホスト1号機のGlusterノードUUIDとpeer情報のバックアップ
物理ホスト1号機にsshログインしてGluster関連の以下をバックアップし、oVirtクラスタ外に退避します。
$ ssh "物理ホスト1号機"
$ sudo tar cf - /var/lib/glusterd/glusterd.info /var/lib/glusterd/peers/ | \
xz -9 > host1-backup.tar.xz
$ scp host1-backup.tar.xz backup.example.co.jp:~/
oVirt 4.3のEngineVMの停止
バックアップが完了したら物理ホスト(どこでもいい)にsshログインして、グローバルメンテナンスモードに切り替え
$ ssh "物理ホスト(どれでもいい)"
$ sudo hosted-engine --set-maintenance --mode=global
この時点で、EngineVMの冗長化は機能しなくなります。
EngineVMにsshログインしてシャットダウン
$ ssh "EngineVM"
$ sudo shutdown -h now
EngineVMが停止するとEngineVM以外の仮想マシンの高可用性も機能しなくなります。
物理ホスト1号機をoVirt 4.4で再構築
ここから先に進むと簡単には引き返せなくなります。![]()
(大雑把に戻す方法は思いつくけど未検証)
CentOS 8インストール
ホスト名とIPアドレスは同じものを引き継ぎます。
ファイルシステム構成は再インストール前と同じ構成が望ましいですが、GlusterのBrickディレクトリ以外は厳密に同じでなくても大丈夫と思われます。
ネットワーク構成はovirtmgmt以外、再インストール前と同じにします。ただし、管理ネットワークのovirtmgmtはEngineVMのデプロイ中に指定したインターフェイスのIPアドレスを引き継いでブリッジとして自動的に作成されるので事前に作成してはいけません。
また、NetworkManagerの接続名(connection.id)はoVirtのネットワーク名と同じにします。(地味に重要)
CentOS 8インストール後、dnf updateでパッケージを更新し、(kernelが更新されるはずなので)再起動します。
$ sudo dnf -y update && sudo reboot
あと、警告が鬱陶しいので英語ロケールをインストール
$ sudo dnf -y install langpacks-en
oVirt 4.4インストール
oVirt 4.4のリポジトリ設定をインストール
$ sudo dnf -y install https://resources.ovirt.org/pub/yum-repo/ovirt-release44.rpm
Gluster 6のリポジトリを追加
$ sudo dnf -y install centos-release-gluster6
oVirt 4.4標準のGluster 7リポジトリを無効化
$ sudo dnf config-manager --disable ovirt-4.4-centos-gluster7
oVirt HCI環境向けパッケージインストール
$ sudo dnf -y install cockpit-ovirt-dashboard vdsm-gluster
Glusterのリストアと開始
退避しておいたバックアップを物理ホスト1号機にコピー
$ scp backup.example.co.jp:~/host1-backup.tar.xz .
元と同じパスにリストア
$ xz -dc host1-backup.tar.xz | sudo tar xf - -C /
再インストール前と同じ構成でBrickを準備します。
必要に応じてファイルシステム~fstab編集~マウント~Brickディレクトリを作成し、
$ lvcreate -L100g -n bricklv vgname
$ sudo mkfs.xfs /dev/mapper/vgname-bricklv
$ echo '/dev/mapper/vgname-bricklv /path/to/mountpoint xfs defaults 0 0' | sudo tee -a /etc/fstab
$ sudo mount /path/to/mountpoint
$ sudo mkdir -p /path/to/mountpoint/brick
Brickディレクトリのowner/groupをvdsm:kvmに設定
$ sudo chown vdsm:kvm /path/to/mountpoint/brick
インデックスディレクトリ(?)作成
$ sudo mkdir -p /path/to/mountpoint/brick/.glusterfs/indices
まだ再インストールしていない、2号機 or 3号機で全てのBrickディレクトリの拡張属性 trusted.glusterfs.volume-id を確認
# ここだけ物理ホスト2号機 or 3号機で実行
# 全てのGlusterボリュームに対して行う
$ sudo getfattr -d -m. -ehex /path/to/brick | grep trusted.glusterfs.volume-id
getfattr: Removing leading '/' from absolute path names
trusted.glusterfs.volume-id=0x41d13b6671de4a289e28b87e13a52226 # この16進数をメモ
確認したtrusted.glusterfs.volume-id属性を物理ホスト1号機で作成したBrickディレクトリに設定
# 確認した個々のGlusterボリュームのtrusted.glusterfs.volume-idを
# 物理ホスト1号機のBrickディレクトリそれぞれに設定
$ sudo setfattr -n trusted.glusterfs.volume-id \
-v 0x41d13b6671de4a289e28b87e13a52226 /path/to/mountpoint/brick
Firewall設定
$ sudo firewall-cmd --add-service glusterfs
$ sudo firewall-cmd --add-service glusterfs --permanent
hostsにGlusterノードのエントリを追加
$ sudo vi /etc/hosts
サービス起動
$ sudo systemctl enable --now glusterd.service
$ sudo systemctl enable --now glustereventsd.service
物理ホスト1号機自身のBrickが起動していることを確認
$ sudo gluster volume status
ボリューム修復
# 全てのGlusterボリュームに対し実行
$ sudo gluster volume heal "ボリューム名" full
修復結果確認
# 全てのGlusterボリュームに対し実行
$ sudo gluster volume heal "ボリューム名" info
Brickは起動しているのにヒーリングが動かない場合は
- 1号機のBrickを一旦削除
- Brickディレクトリも削除
- 1号機のBrick追加
とやると修復出来ます。
新しいEngineVMのデプロイ
Glusterボリューム追加
oVirt 4.4の新しいEngineVMのデプロイ先となるGlusterボリュームを新規作成します。
パーティション作成、LV作成、ファイルシステム作成等は構成によるので割愛。肝心のGlusterボリューム作成は以下
$ sudo gluster volume create "新EngineVM用Volume" replica 3 \
"物理ホスト1号機Glusterノード名":/path/to/brick \
"物理ホスト2号機Glusterノード名":/path/to/brick \
"物理ホスト3号機Glusterノード名":/path/to/brick
作成したボリュームに仮想マシン用のパラメータを設定
$ sudo gluster vol set "新EngineVM用Volume" cluster.data-self-heal-algorithm full
$ sudo gluster vol set "新EngineVM用Volume" cluster.eager-lock enable
$ sudo gluster vol set "新EngineVM用Volume" cluster.choose-local off
$ sudo gluster vol set "新EngineVM用Volume" performance.low-prio-threads 32
$ sudo gluster vol set "新EngineVM用Volume" performance.strict-o-direct on
$ sudo gluster vol set "新EngineVM用Volume" network.ping-timeout 30
$ sudo gluster vol set "新EngineVM用Volume" network.remote-dio disable
$ sudo gluster vol set "新EngineVM用Volume" performance.read-ahead off
$ sudo gluster vol set "新EngineVM用Volume" performance.io-cache off
$ sudo gluster vol set "新EngineVM用Volume" performance.quick-read off
$ sudo gluster vol set "新EngineVM用Volume" storage.owner-uid 36
$ sudo gluster vol set "新EngineVM用Volume" storage.owner-gid 36
$ sudo gluster vol set "新EngineVM用Volume" cluster.server-quorum-type server
$ sudo gluster vol set "新EngineVM用Volume" features.shard on
$ sudo gluster vol set "新EngineVM用Volume" cluster.shd-max-threads 8
$ sudo gluster vol set "新EngineVM用Volume" cluster.shd-wait-qlength 10000
$ sudo gluster vol set "新EngineVM用Volume" cluster.locking-scheme granular
$ sudo gluster vol set "新EngineVM用Volume" cluster.granular-entry-heal enable
$ sudo gluster vol set "新EngineVM用Volume" client.event-threads 4
$ sudo gluster vol set "新EngineVM用Volume" server.event-threads 4
$ sudo gluster vol set "新EngineVM用Volume" performance.client-io-threads on
$ sudo gluster vol set "新EngineVM用Volume" performance.stat-prefetch off
なお、公式の設定はこちらで、/var/lib/glusterd/groups/virtにstorage.owner-uid,storage.owner-gidの設定を追加したものになっており、上記とは微妙に異なります。(上記はCockpitからデプロイした設定+oVirtのバージョンアップで変わった設定+バグ回避設定のミックス)
パラメータ設定完了したらボリュームを起動
$ sudo gluster vol start "新EngineVM用Volume"
EngineVMのデプロイ
CentOS 8を再インストールした物理ホスト1号機で新しいEngineVMをデプロイします。
物理ホスト1号機にログインして、EngienVMのイメージをダウンロード
$ ssh "物理ホスト1号機"
$ sudo dnf -y install ovirt-engine-appliance
oVirt 4.3のEngineVMのバックアップを退避先からコピー
$ scp backup.example.co.jp:~/backup4310.bck .
EngineVMのデプロイは対話形式ですが、選択肢がない設定は事前に応答ファイルに記載しておきます。
以下の内容(YourClusterNameをクラスター名、YourDataCenterNameをデータセンター名、YourEngineVMFQDNをEngineVMのFQDNに置き換える)をhe-deploy-answer.confという名前で作成
[environment:default]
OVEHOSTED_ENGINE/clusterName=str:YourClusterName
OVEHOSTED_ENGINE/datacenterName=str:YourDataCenterName
OVEHOSTED_NETWORK/fqdn=str:YourEngineVMFQDN
デプロイ中にネットワーク切れても大丈夫なようにtmux起動
$ tmux
バックアップデータのリストア+応答ファイル指定でEngineVMのデプロイ開始
# インターネットに直接出られる環境の場合
$ sudo hosted-engine \
--deploy --restore-from-file=backup4310.bck \
--config-append=he-deploy-answer.conf
プロキシ環境下の場合は以下のように環境変数とオプションを追加します。
# プロキシ環境下の場合
$ sudo http_proxy="Proxy IP":"Proxy Port" https_proxy="Proxy IP":"Proxy Port" no_proxy="EngineVMのFQDN" hosted-engine \
--deploy --restore-from-file=backup4310.bck \
--config-append=he-deploy-answer.conf \
--ansible-extra-vars=he_offline_deployment=true
なお、--ansible-extra-vars=he_offline_deployment=trueというオプションはoVirt 4.4.3から追加されたものなので古いバージョンでは使えません。(oVirt 4.4.2以下は色々小細工が必要だった)
デプロイは対話形式で応答ファイルに書かれていない事は逐一入力を求められますが、oVirt 4.3.10と変わらないので割愛します。
デプロイ先のストレージ選択の所は新規追加したGlusterボリュームを選択します。
Please specify the storage you would like to use (glusterfs, iscsi, fc, nfs)[nfs]: glusterfs
Please specify the full shared storage connection path to use (example: host:/path): "物理ホスト1号機のGlusterノード名":/"新規追加したGlusterボリューム名"
If needed, specify additional mount options for the connection to the hosted-engine storagedomain (example: rsize=32768,wsize=32768) []: backup-volfile-servers="物理ホスト2号機のGlusterノード名":"物理ホスト3号機のGlusterノード名"
デプロイが成功するとブラウザで管理画面にログイン出来るようになります。
物理ホスト1号機のネットワーク設定
物理ホスト1号機のネットワークはovirtmgmt以外は"Unmanaged"になっているので、(事前準備で"必須"を外しておいたのはこれが理由)
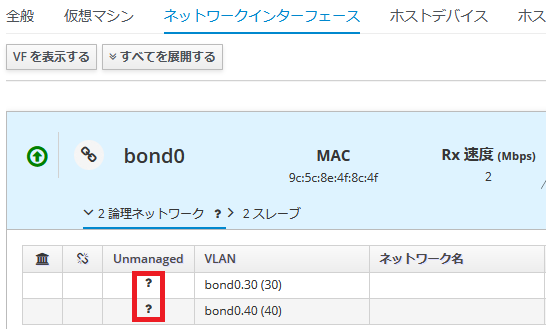
物理ホスト1号機の[ホストネットワーク設定]で全て設定しておきます。
なお、oVirt 4.4ではoVirtのネットワーク名==NetworkManagerの接続名(connection.id)となるのですが、oVirtのネットワーク名と異なるNetworkManager接続名を作成しIPを付与していた場合、
- oVirtネットワーク名で新しいNetworkManagerの接続設定が作られる
- 作成した接続設定にIPアドレスを設定しようとしたところで重複IPでエラー
になります。
oVirt 4.3の頃は物理ホストのネットワークはNetworkManager管理外となっており、上記のオペレーションを行ってもNetworkManagerの設定削除→管理外設定が作られるだけで平気だったようですが、oVirt 4.4では処理途中でエラーになります。
その2へ続く