word2vecを使用して前回(初めて自然言語処理をword2vecでしてみました)英文のデータから学習させて関連性をみました。
今回は、word2vecを使用して日本語の処理を行います。
日本語を処理する時に注意すること
日本語は英語と違って、単語ごとにスペースで分けられていないです。コンピューターにとっては、英語はスペースで区切られているので単語を認識するのが簡単ですが、日本語だと単語の区切りが分かりません。そこで、日本語の文章を名詞や形容詞、女子といった言葉の最小単位(形態素)に分解し、それぞれの品詞を推定する作業(形態素解析)を行って、コンピューターで処理しやすい形態に変換(分かち書き)します。
形態素解析をするソフトウェアにはChaSenやKAKASIなどがありますが、本では、MeCabというソフトウェアを使ってます。
こちらの書籍を見ながら今回は、実行しています。
参考にした本
パソコンで楽しむ自分で動かす人工知能
中島能和 (著)
実際にword2vecを使って日本語の文章の処理を行った手順
※word2vecは、インストールされているものとします。
①日本語を処理するためのソフトウェアをインストールする
②夏目漱石で試してみる
③文字コードを変換する
④ルビを取り除く
⑤形態素解析を行う
⑥word2vecで学習させよう
⑦日本語で関連語を調べよう
①日本語を処理するためのソフトウェアをインストールする
$ sudo apt install nkf mecab libmecab-dev mecab-jpadic-utf8
| ソフトウェア名 | 説明 |
|---|---|
| nkf | 文字コードや改行コードを変換するコマンド |
| MeCab | 形態素解析エンジンMeCab |
| libmecab-dev | MeCabの開発者向けパッケージ |
| mecab-ipadic-utf8 | MeCab用の辞書 |
②夏目漱石で試してみる
※自然言語処理をするうえでは、ある程度大きなサイズの日本語データが必要になるので、青空文庫を使用します。青空文庫ではテキスト形式のファイルを入手することができます。今回は夏目漱石の「坊ちゃん」を取り上げます。「テキストファイル(ルビあり)」を選んでダウンロードして、word2vecのディレクトリに移動
解凍する
$ unzip 752_ruby_2438.zip
※bocchan.txtというテキストファイルが出きます。
③文字コードを変換する
| 文字コード | 説明 |
|---|---|
| シフトJIS | WindowsやmacOSのアプリケーションで使われる文字コード |
| JIS | 電子メールなどで使われる文字コード |
| EUC-JP | 古いLinuxやUNIXの標準的な文字コード |
| UTF-8 | UbuntuなどのLinuxの標準的な文字コード |
文字コードの歴史や文字コードの変換については、以下のサイトで説明してくれている方がいるのでそちらを確認してください。
・知っておきたい! 文字コードの基礎知識 ……ASCII,シフトJIS,Unicode etc.
・文字コードとは?~UTF-8はパソコンの世界共通語~|データ分析用語を解説
※テキストファイル作成時に用いられた文字コードとファイルを開くときに用いる文字コードが異なると文字化けを起こすので確認します。
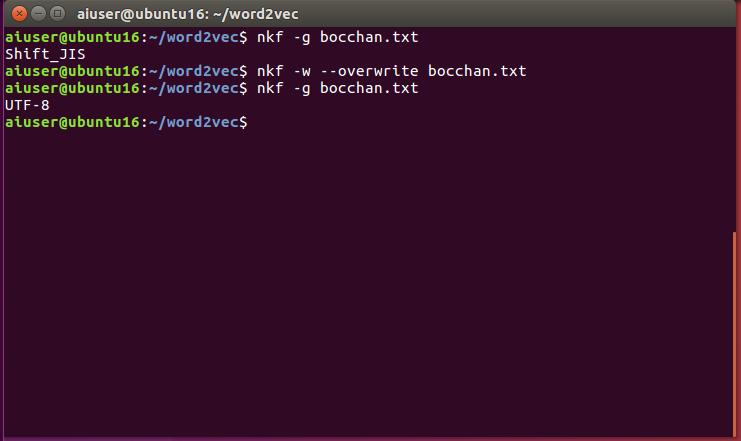
# 文字コードを確認する
$ nkf -g bocchan.txt
$ Shift_JIS
※UbuntuなどのLinuxディストリビューションはUTF-8を採用しているので、これをUTF-8に変換する
# 文字コードをUTF-8に変換する
$ nkf -w --overwrite bocchan.txt
※変換前と返還後のキャプチャー
補足(文字コードについて)
文字コードの歴史や文字コードについて説明している方
・知っておきたい! 文字コードの基礎知識 ……ASCII,シフトJIS,Unicode etc.
・文字コードとは?~UTF-8はパソコンの世界共通語~|データ分析用語を解説
④ルビを取り除く
# Ubuntuのエディターを開く
$ gedit bocchan.txt
** 検索前**
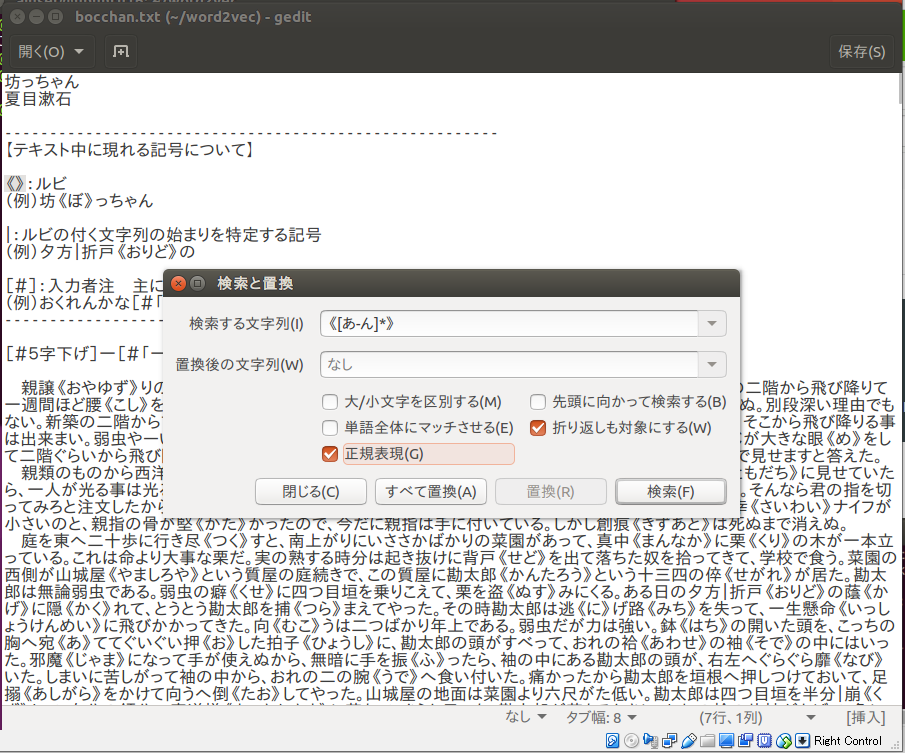
** 検索後**
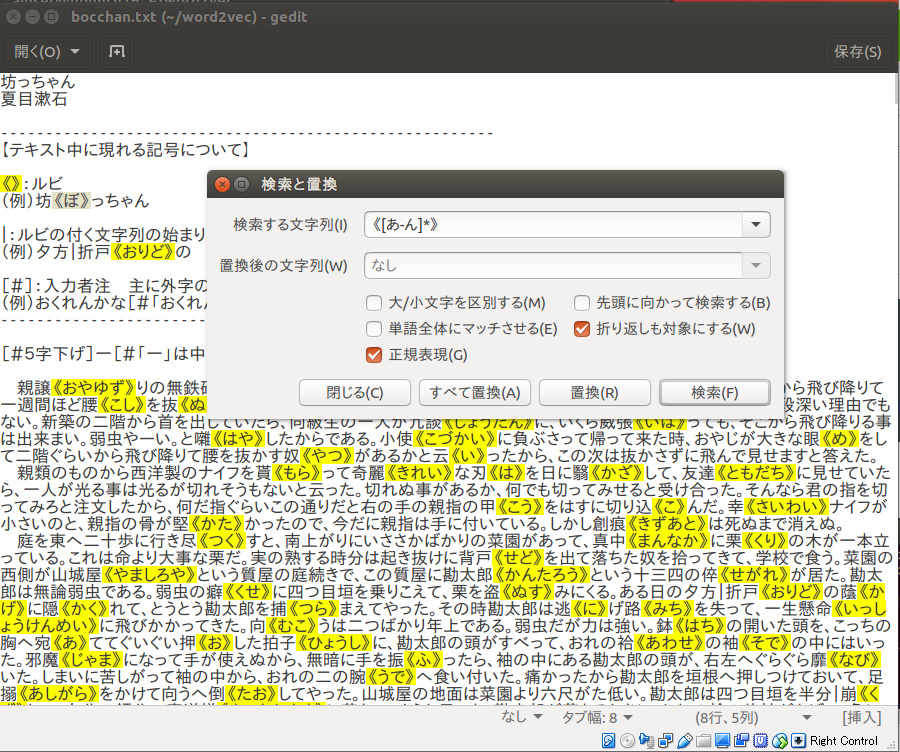
※すべて置換後に冒頭と末尾の余計なデータを消して学習精度をあげる前処理を忘れずに行います。
⑤形態素解析を行う
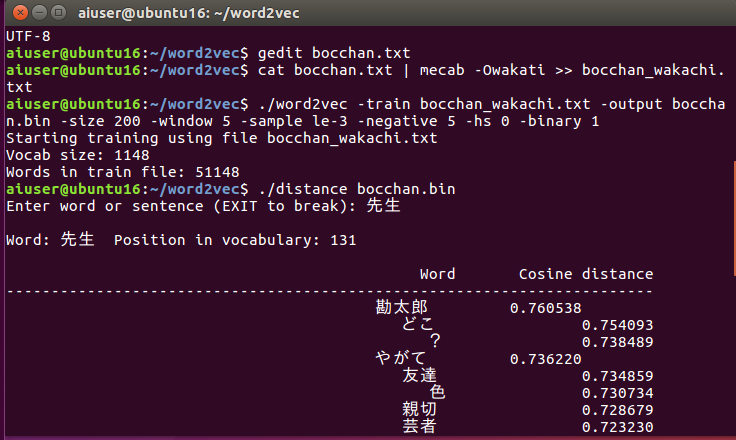
# 形態素解析を行って分かち書きする
$ cat bocchan.txt | mecab -Owakati >> bocchan_wakachi.txt
⑥word2vecで学習させよう
$ ./word2vec -train bocchan_wakachi.txt -output bocchan.bin -size 200 -window 5
-sample le-3 -negative 5 -hs 0 -binary 1
word2vecコマンドの主なオプション
| オプション | 説明 |
|---|---|
| -train | 学習に用いるファイルを指定する |
| -output | 学習結果を保存するファイルを指定する |
| -size | ベクトルの次元数を指定する(既定値は100) |
| -window | 単語間の最大スキップ数を指定する(既定値は5) |
| -sample | 単語を無視する頻度を指定する(既定値は1e-3、有用な範囲は0~1e-5) |
| -negative | ネガティブサンプリング数を指定する(既定値は5、一般的には0~10) |
| -hs | ソフトマックス回帰を使うかどうかを指定する(既定値は0で使用しない) |
| -binary | バイナリで出力するかどうかを指定する (1ならバイナリ、既定値は0で使用しない) |
⑦日本語で関連語を調べよう**
※先生と日本語で入力
関連情報(文字コードについて)
書籍情報
パソコンで楽しむ自分で動かす人工知能
中島能和 (著)