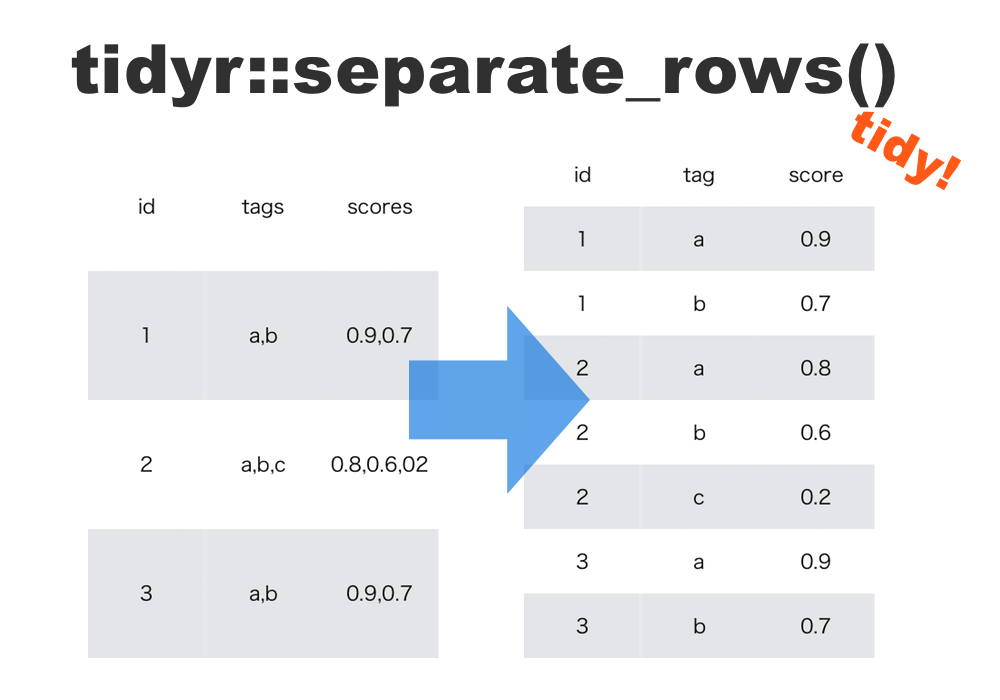
タイトルのように、一つの列の中で複数の値に分割できそうな値を含んだデータフレームを扱う場合、区切り文字を元にデータを分割するという処理が必要になるかと思います。次のようなデータです。
d <- data.frame(
id = 1:3,
tag = c("apple,banana,melon", "grape,orange", "peer,mango,pine apple"),
score = c("0.7,0.5,0.4", "0.6,0.2", "0.7,0.4,0.3")
)
tag、scoreという列に、カンマ区切りで複数の値が格納されています。このtagとscoreに含まれる個々の値は、apple = 0.7, banana = 0.5のように対となるデータであるとします。
こんなデータの持ち方をするなよ、と怒られそうですが、JSONのような階層構造をもったデータを無理にテーブル形式へ保存しようとするとこういうデータが生まれやすい気がします。
こうしたデータを処理・集計しやすく扱うためにはどうすれば良いでしょうか。tidyrパッケージには、まさにこのようなデータの処理をするための関数separate_rowsが用意されています。まずは関数の実行例を示します。
library(tidyr)
d %>%
separate_rows(tag, score, sep = ",")
## id tag score
## 1 1 apple 0.7
## 2 1 banana 0.5
## 3 1 melon 0.4
## 4 2 grape 0.6
## 5 2 orange 0.2
## 6 3 peer 0.7
## 7 3 mango 0.4
## 8 3 pine apple 0.3
関数separate_rowsは、tidyrのバージョン0.5.0(2016年6月リリース)で追加された関数です(tidyrの最新バージョンは0.6.3)。従来のsepare()が横方向に列を分割するのに対して、縦方向にデータを分割していきます。まさに今回のようなデータを処理するのに適しています。
詳しい使い方を説明します。と言っても難しいことは特になく、分割対象の列名を引数に与え、区切り文字をsep引数で指定するだけです。convertという引数も用意されていますが、これは分割後のデータ型を適当な型に変換するかのオプションです。初期値ではFALSEが指定されており、分割後のデータ型は元のデータ型を引き継ぎます。
convertの指定の違いを示します。今回のように、scoreの値を文字でなく数値にしたい場合にはTRUEを指定すると良いでしょう。
d %>%
separate_rows(tag, score, sep = ",") %>%
purrr::map_chr(class)
## id tag score
## "integer" "character" "character"
d %>%
separate_rows(tag, score, sep = ",", convert = TRUE) %>%
purrr::map_chr(class)
## id tag score
## "integer" "character" "numeric"
これまでのtidyrの記事で見かけない関数だったので紹介しました。
Enjoy!