時間制限のある環境下(kernel, colab等)においてDeep Learningの学習を引き継ぐ時の注意点
この記事は、kaggle その2 Advent Calendar 2019のアドベントカレンダー23日目の記事です。
Deep Learningで学習を行う際、オンプレのマシンを持っていない場合は、Kaggleのnotebook(旧kernel)やgoogle colaboratoryなど時間制限のある環境下で学習を行う人も多いと思いますが、そこで起こりうる問題と対処法を書きたいと思います。実装は全てPyTorchです。
問題
Kaggleで開催される画像コンペティションの多くは学習に時間がかかるものが多く、最終的なモデルは9時間で終わらないことが多い印象です。その場合途中で学習を切って、checkpointとしてmodelを保存し、別notebookを立て、そのmodelを読み込んで学習を続けることになります。その際2つの問題が発生します。
① optimizer, scheduler, epoch, best_score, best_accなどの状態が引き継がれない
② seedを固定している場合、各batchに含まれる画像のランダム性が失われる
①optimizer, scheduler, epoch, best_score, best_accなどの状態が引き継がれない
①についてはmodelと同じくschedulerやbest_scoreなども保存しておかなければ、途中まで学習し終わった状態から再開できません。learning rateが一定であれば関係ないのですが、通常learning rateはExponentialLRや、CosineAnnealingLRなどで変動させることが多いはずです。
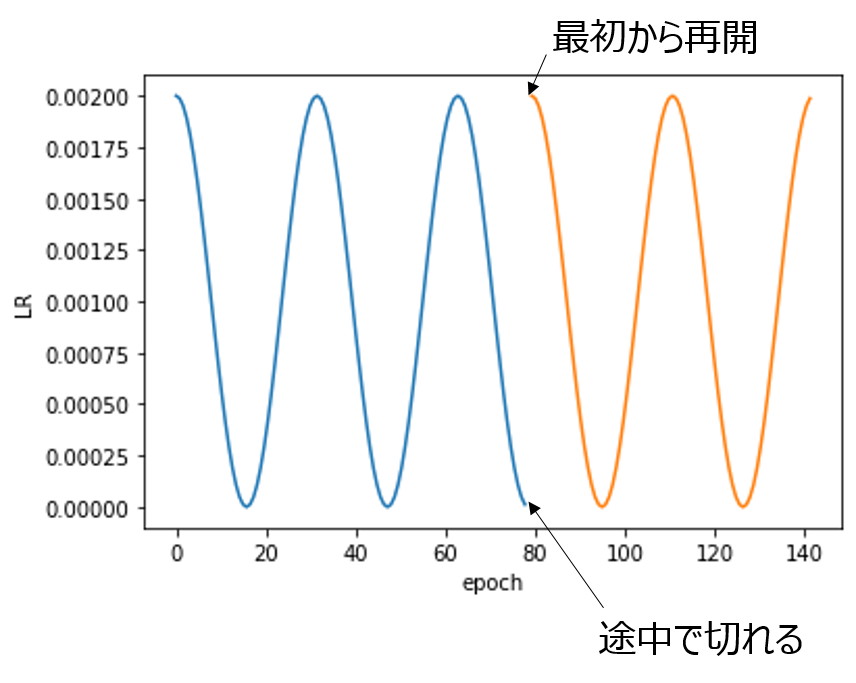
モデルだけ引き継ぐようにすると、上記の図のように、学習を引き継いだ際にまた最初からschedulerが動いてしまい、意図したものになりません(これはこれで悪くなさそうなんですが)。
解決法
毎epoch、モデルとともにoptimizer, scheduler等を保存して、引き継ぐ際に読み出すだけです。
② seedを固定している場合、各batchに含まれる画像のランダム性が失われる
PyTorchのDataLoaderでshuffleをTrueにすると、指定したバッチサイズで毎回データをランダムに吐き出してくれます。
train_loader = DataLoader(train_dataset,batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)
しかし、Kaggleで学習を行う際は再現性を担保するため下記のようなコードでseedを固定する場合が多いと思います。
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
SEED = conf.SEED
seed_everything(SEED)
しかし、学習を引き継ぐ場合、seedが固定されているので、1回目の学習でサンプルされた順番と全く同じ順番でデータが出力されます。下の図は画像が全部で10枚、バッチサイズが2、epochが2で引き継がれたときのイメージです。
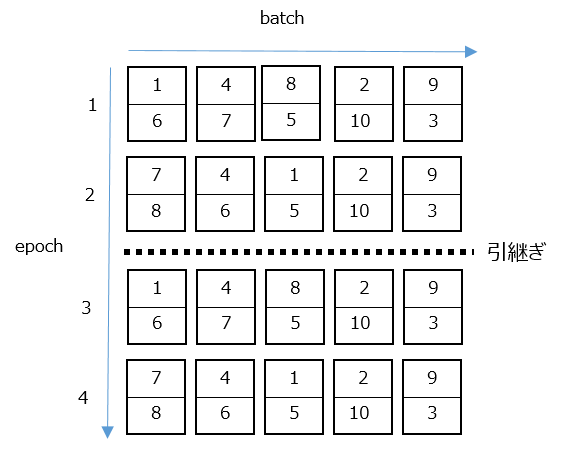
例えば9時間で10epochしか回せない学習の場合、1~10epoch目の画像の順番と11~20epoch目の画像の順番は全く同じになってしまいます。これが精度にどう影響を与えるのかは要検証なのですが、極端な話毎epoch同じ順番だったらまずそうとは感じるので、なんとかします。
方法はいろいろあるのですが、seed_everythingのseedはあまり変えたくないので、私は学習の引き継ぎ回数をconf.stageで管理しているので、train_datasetを作るときに、seedにconf.stageを入れてsampleして順番を強制的に変更しています。課題によってdatasetの書き方が異なるのであくまでも参考ですが、seed_everythingとは違う引き継ぎごとに変わるseedでshuffleを行うのがもっとも簡易だと思います。
train_dataset = Dataset(conf, df_trn.sample(frac=1, random_state=conf.stage), train_transforms)
参考
以下はRecursion Cellular Image Classificationの時のnotebookです。途中まではこんな感じでkernelのみで頑張ってました。重いモデルでは9時間で6epochぐらいしか回せずstage10ぐらいまで引き継いで学習していたと思います。