はじめに
ニコニ立体です
リンク:ニコニ立体
TL;DR
- 去年末からニコニ立体を直してるよ
- AzureからAWSに移行したよ
- かなり近代化されたよ
誰
去年の12月1日にドワンゴに入社しました。
本記事は入社後初の投稿なので事実上の入社エントリです。
フラフラとRuby on RailsとAWSを触りながら5年ほどベンチャーを転々としていたらドワンゴに拾われました。
入社の経緯は転職ドラフトに "技術的負債解消のプロになりたい" というレジュメを貼り付けていたら目をつけられて、
「ニコニ立体というサービスが技術的負債たまりまくっててヤバいので直すのを手伝ってくれ」
と言われてなるほど〜〜〜と思ったので入社しました。
ニコニ立体
※入社前の出来事については当時のログや担当者からの証言を元に説明しています。正確ではない可能性もありますがご容赦ください。
2014年5月にサービスを開始したMMD(MikuMikuDance)のモデルデータをホスティングするサービスです。
ドワンゴの新卒研修で作成したサービスが2年ほどは継続して機能追加等の細々とした開発が行われていましたが、2016年頃にチームが解散され、以後開発人員0の期間が2年ほど続いていました。
2018年にVRMというVR向けモデル形式にニコニ立体を対応させようという動きが出て開発が再び行われるようになりましたが、ミドルウェアやフレームワークは2014年のリリースからずっと放置されており、サポート切れや配布終了等で環境の再構築もままならないという状況でした。
これらの技術的負債を解消するため、リプレイスプロジェクトが発足しました。
リプレイスプロジェクト
サービス概要
以後の解説を読む上で参考になるサービス概要を掲載します。
| Azure | AWS(移行直後) | AWS(現在) | |
|---|---|---|---|
| OS | Ubuntu14 | Ubuntu14 | Ubuntu18 |
| DB | Azure SQL Server 2014 | RDS SQL Server 2017(シングルAZ) | Aurora MySQL 5.7 |
| Ruby | 2.4.0 | 2.4.0 | 2.6.5 |
| Rails | 4.2 | 4.2 | 5.0 |
| LB | ClassicLB | ALB | ALB |
| ファイルサーバ | BLOB | S3 | S3 |
| CDN | なし | なし | CloudFront |
| 検索基盤 | Solr(セルフホスティング) | Solr(EC2) | ElasticSearch Service |
| サーバ | 3台固定 | 4台固定(t3.large) | オートスケーリング(t3.large) |
| 最大性能 | 4千request/min | 1万request/min | ←以上(限界不明) |
| 死活監視 | なし(エゴサ) | Cloudwatch | Cloudwatch |
やったこと一覧
- Azure から AWS への移行
- SQL Server から Aurora MySQL への移行
- Solr から ElasticSearch Service への移行
- Ubuntu14 から Ubuntu18 へのアップデート
- Cloudfront(CDN)の設置
- オートスケーリングの導入
リプレイス戦略
戦略、というほどのものではないですが、移行の指標を最初に策定しました。
それは 個々の変更を最小限にし、それを積み重ねる というものでした。
人間は基本的にマヌケなので変更点が増えると指数的に不具合が増えるという経験則からの決定でした。
そして、この指標に従って小さなリプレイスを繰り返していった結果、リプレイス規模に対して不具合の発生が少なく、不具合が発生しても変更点が小さいことから原因の特定や修正が容易となり、システムの安定性や工数の削減に寄与しました。
ホスティングサービス移行
移行先選定
ニコニ立体はAzure上にホスティングされていた(PDF)のですが、当時のAzureは現在はクラシックと呼ばれ、機能性や拡張性に乏しいものでした。リプレイスのタイミングで、移行先についての検討がありましたが、利用価格での折り合いがつかず、また社内で他にAzureを利用しているサービスもなく知見がほぼない状況でしたので、早々に選択肢から外れました。移行先の候補はオンプレとAWSのどちらかでした。オンプレは社内で大規模に展開しているため、安価で運用できるという利点がありましたが、立体システムがクラウドホスティングサービスに依存したコードとデプロイ機構になっていたため、オンプレ対応のコストが大きく、工数的に不可能であると試算されました。一方でAWSへの移行は同じ構成を再現できること、移行のためのシステム変更が実現可能な工数で可能であると見積もりが出たので、AWSへの移行を決定しました。
(おまけ)Azureの契約破棄
AWSへの移行が決定したタイミングでAzureの契約破棄に向けて動き出しましたが、契約代行企業を間に挟んでいた関係で次の契約は3年縛り以外できない状況になりました。その結果、契約更新期限である4月末が最終移行完了日に決定し、それまでに移行が完了しなければサービスの一時閉鎖も視野に入る危機的状況になりました。
ホスティングサービス移行戦略
リプレイスの作戦に従い、可能な限り変更がすくなるようにしました。
たとえば
- SQL ServerからMySQLへの移行などはやりたいが今回は行わず、AWS移行後にAWS内部で行う
- CDNを使わず、単純なLBで動かす。
といったふうに、ホスティングサービスが変わる以外の変更を行わないという方針にしました。
ホスティングサービス移行段階では以下の変更にとどめました。
| Azure | AWS |
|---|---|
| クラシックインスタンス(固定台数) | EC2インスタンス(固定台数) |
| ClassicLB | ALB |
| BLOB | S3 |
| SSLをnginxで処理※1 | SSLをALBで処理 |
| Azure SQL Server 2014 | RDS SQL Server 2017(シングルAZ※2) |
※1 AzureのClassicLBはSSLを処理してくれないため、インスタンス内部のnginxでSSLの処理をしていた
※2 本当はマルチAZにしたかったが、高すぎたためシングルAZ。なおAzure SQL Serverは冗長構成になっていたが、かつて障害で入れ替わったときは復旧に5分以上かかっており、RDSのシングルAZの復旧に要する時間とほぼ同じだったことから採用。障害でデータが飛んだときは諦めるということにし、運を天に任せて※3移行後に最速でAurora MySQLに移行しました。決して真似しないでください。100サービスが同じことをしたら1サービスは死にます。
※3 移行失敗で4月末を超えることによるサービス停止とデータが1日巻き戻ることを天秤にかけた結果、1日巻き戻ることになっても全停止よりはマシという結論になりました。
やること
- ホスティングサービスの移行
やらないこと
- ホスティングサービス以外のすべて
- ミドルウェア変更・更新
- ライブラリ変更・更新
- サーバ構成の変更
- ネットワーク構成の変更
AWS移行作業
ステージング構築
まず始めたことはAWSの上でニコニ立体システムが動作できるかどうかの検証作業でした。しかし、ここで大きな問題が立ちふさがりました。ニコニ立体の本番投入前に使用するステージング環境が本番とは全く異なる構成で構築されていました。
| ステージング | 本番 | |
|---|---|---|
| OS | CentOS6 | Ubuntu14 |
| DB | MySQL 5.6 | SQL Server |
| サーバ構成 | オンプレサーバ1台にすべて内包 | Web/Batch/DB/Redis/Solr に分割 |
こういった構成の違いからnginxのルーティング設定やRailsで使っているgemが違っていたりして、同一動作が保証されていませんでした。
そこで、AWSでは本番と同一環境のステージングを構築し、動作検証を行えるようにしました。
元となるサーバが根本的に違うため、ステージングは現行の本番サーバからコピーすることにしました。
後で解説しますが、nginxの再コンパイルができない問題や、aptパッケージのバージョン問題があり、AWSで新規インスタンスを建てるのではなく、V2Vで中身ごとAWSへ持っていき、その後にAWS内でアップデートを行うことにしました。
AzureでのVMエクスポート
リプレイス作業で最初にぶつかった難関はVMのエクスポートでした。
Azureから出ようという情報がほとんどなく、検索結果のほとんどがAzure への 移行でした。
Azureのサポートをくまなく探し、以下の記事を見つけました。
Azure から Linux VHD をダウンロードする
EC2化
AzureからエクスポートしたVMをそのままEC2で立ち上げても一部の設定がAzure用になっているため完全には動きません。そこで以下の修正をし、EC2になじませる必要がありました。
| 内容 | 修正 |
|---|---|
| aptリポジトリ設定の修正 | sed -i -e "s/azure.archive.ubuntu.com/ap-northeast-1.ec2.archive.ubuntu.com/g" /etc/apt/sources.list |
| Azure用監視デーモンの削除 | rm /etc/init/walinuxagent.conf |
| 起動時設定 | vi /etc/cloud/cloud.cfg => apt-configureを削除(毎回aptのsources.listを上書きしてくる) |
| ElasticNetworkAdaptor(t3系対応) | apt-get update && apt-get upgrade -y linux-aws + (CLI)aws ec2 modify-instance-attribute --ena-support --instance-id |
ステージング化
本番のVMについてはここでAMIを取って完了としましたが、ステージングは設定を変更しなければなりませんでした。本番へのアクセスが起こらないよう設定の洗い出しを行い、地道に一つ一つ変更していき、ステージングとして動作するように調整を行いました。地味な作業でしたが、システム間のつながりを把握するという点でとても効率的だったので思ったほど無意味な作業ではありませんでした。
データ移行(BLOB to S3)
データ移行はリプレイスプロジェクトでも難易度が高い部分でした。
ニコニ立体は3Dモデルホスティングサービスですが、この3Dモデルのファイル容量が大きく、移行に非常に時間がかかりました。試算では移行に24時間かかると出たため、日々増えるデータをどのようにスムーズに移行するかについて悩みました。
立体の負債解消を手伝ってくれていたまさらっき氏が偶然ALBのRuby on Lambdaを触っていたことで解決の糸口が出来ました。
nginxのリバースプロキシ機能を使い、先に構築したAWSのALBへ問い合わせを行い、「S3に該当ファイルがなければBLOBへリダイレクトする」というLambdaを設置して、データ移行の24時間を耐えるという作戦となりました。
アクロバティックな解決案でしたが、これが大成功して無停止でのデータ移行を完了できました。
以後、1日毎に差分を転送し、最後は移行当日の停止メンテ時間中に移行する事ができました。
データベース移行
データベース移行はプロジェクト全体の中で2番目に難易度が高い作業でした。
データの移行にはAWS Database Migration Serviceを利用しました。DMSには他のクラウドサービスやオンプレサーバにあるDBからRDSへデータをインポートできる機能があり、これを利用することで工数を小さくできました。
本番データに関しては素直に※1SQL ServerからSQL Serverへの移動で良かった※2のですが
まず、旧ステージング環境のデータベースがMySQL5.6で動作していたため、SQL Serverにコンバートする作業から開始しました。
AWS Database Migration Serviceにはデータベースの種類を超えてデータ移行できる機能が備わっており、これを利用することである程度楽になりましたが、スキーマの構築やインデックス情報はうまくコンバートできなかったため、本番のデータベースからスキーマを持ってきて投入※3し、その後にレコードだけをコピーしました。
この際にいくつか罠があって、AzureのSQL Serverが貧弱でDMSがデータ取得のために大量アクセスをするとハングアップして途中でDMSの移行タスクがコケるという問題がありました。3回ぐらいやり直せば1回は成功するぐらいの確率だったので移行当日にコケないことを祈ることにしました。
また、ステージングはオンプレ上でMySQL 5.6を使用して動作していたため、単純な移行は絶望的でした。本番と同様にスキーマのみでDBを先に構築し、DMSのDB種別を超えたコンバート機構に頼って移行、という作戦を行いましたが、一部のユニーク制約やデータの違い(DatetimeがMySQLは少数3桁だが、SQL Serverは秒までしか持たず、少数が切り捨てられた時に同じ時刻になってユニークがぶっ壊れる)といった障壁がありました。こういった齟齬を一つ一つ解いていってステージングデータをSQL Serverに移行しました。ここで罠を踏み潰しておいた※6おかげで本番移行の際はスムーズに移行することができました。
※1 DMSのマスターパスワード指定に#が使えないという罠があり、パスワード変更を余儀なくされましたが、全体の罠から見れば些細なことでした。RDSのマスターパスワード設定には#が使えるので釈然としませんが。
※2 実は罠があって、データベース設定はコピーされないため、そこに差異があると挙動がおかしくなる。まさにその罠を今回踏んで、ロック機構の設定の違いでアクセス量が増えるとデッドロックが発生する現象が起きました。SQL ServerはデフォルトではREAD_COMMITTED_SNAPSHOT=OFFなのですが、Azure SQL ServerはデフォルトがREAD_COMMITTED_SNAPSHOT=ONとなっていてロックレベルがRDSの場合だと厳しくなったことが原因でした。デフォルト設定で動作させようとすると立体のコードの書き換え量が膨大なことになるため、ALTER DATABASEで設定をAzureと同じREAD_COMMITTED_SNAPSHOT=ONにすることで回避しました。
※3 SQL ServerはもちろんMicrosoft製なのでWindows用のツール(SQL Server Management Studio)しか提供されていません。つまりMacでは一切手出しできないということです。このためだけにMac機とWindows機の2台持ちを余儀なく※4されました。ちなみにAzure Data Studioはこの件では役に立ちません。 Azure Data Studioは役に立ちません 。
※4 余談ですが、AzureのCLIもWindowsのPowershellが必須で、Mac版Powershellでは動かないコマンドがいくつかありました。Azureを使う場合はWindows Serverを使っていなくてもWindows機は絶対必要※5です。どういうことなの。
※5 どうしてもMacで動かないコマンド(LBのインスタンス切り離し)があって、Azureのサポートに問い合わせたら「Windows機がない?!」と困惑されたことを今でも思い出します。ちなみにWindowsのPowershellで実行したらすんなり通りました。
本番移行検証
実際の本番移行に先立ち、ステージングでの動作検証を行ってシステムが動作するところまでは持っていきました※1。
しかし、本番と同様のシステム構成で動作するかは依然として不明だったため、一度本当に本番を引っ越してくることにしました。
実際にDMSを使用し、Azureの本番DBからRDSへデータ移行を行い、サーバインスタンスも本番で動かす予定のものを用意しました。
ただし、他のニコニコサービスに影響がないようにニコニコ関連へのアクセスだけはダミーの設定を用意しました。
こうして構築した本番相当の環境で動作チェックを行い、つなぎこみ以外の部分は問題なく動作することを確認しました。
※1 サラッと流しましたがこの作業だけで1ヶ月ほどかかりました。ファイルサーバをBLOBからS3へ切り替えるためにAWS-SDK for Rubyを導入したり、データベースの特性の違い※2による設定やモンキーパッチの調整などを行いました。
※2 Azure SQL Serverは一般的なSQL Serverとは動作が異なっていてモンキーパッチを当てないとRailsでは接続が切れたり※3デッドロックが起こったりする。RDSのSQL Serverは市販のSQL Serverと同じ動作っぽいです。(少なくとも立体で利用しているレベルでは)
※3 Azure SQL Serverは不思議な挙動をしていて、ActiveRecordで張ったコネクションがなぜが5分ちょうどでSQL Server側から切断されるのですが、これをActiveRecord側が検出できず、コネクションの再接続が走らなくてエラーになるという最悪の現象が起きていました。そこでARにモンキーパッチを当て、直前のSQL発行から5分以上経過していたらコネクションを張り直す、という動きになっていました。しかし、通常のSQL Serverはそのような挙動がなく、コネクションをクライアントから切断しない限り維持し続けます。つまり、RDSのSQL Serverだとモンキーパッチにより何十分かごとにコネクションが貼り直されることになり、数時間でDBのコネクション限界に達して接続できなくなるという現象が起きました。
本番移行準備
DNS移管
DNSは社内DCでホスティングされているDNSサーバを使用していましたが、AWS化にあたっていろいろと不便になっており、route53へ移管することにしました。
サクッとできると思っていたのですが、立体が使っている3d.nicovideo.jpはメインドメインのnicovideo.jpがメジャードメインという判定を受けて、正当な所有者からのroute53への登録かを確認するという手順が発生し、最終的に有料サポートに入り、申請が正当であるという認定を受けなければなりませんでした。
有名サービス特有の罠を体験できて、面白くもあり、面倒だなと思ったり、複雑な気持ちになりました。
リハーサル
本番移行検証の時に手順が複雑だったり失敗することがあったので、当日のメンテでの失敗の可能性を減らすため、事前に移行訓練を行いました。
計2回、当日の移行手順に従い本番システムをAWSへ実際に引っ越しました。
ここで罠のほとんどを踏み抜いたので当日はそれらをほとんど回避でき、またオペレーションがスムーズに進み、想定していた中ではかなり良いペースでメンテを完了させることができました。
本番移行当日
メンテイン
当日は週の中でもっともアクセスが少なくなる火曜日の深夜2時を狙って行いました。
メンテインと同時にシステムをメンテナンスモードに切り替え、アクセスを遮断しました。
Azure側のメンテナンスモードはnginxで503の固定レスポンスを返すようにしました。残念ながらAzureクラシックにはインスタンスの前段にコンテンツを配信する機構がなかったため、この方法を取りました。
対するAWS側はALBでS3に設置したメンテナンスの静的ページを返却するように設定しました。
DBデータ移行
アクセスがなくなったことを確認し、事前にAzureからRDSへデータを移行するAWS DMSのタスクを起動しました。
このとき、Azure側でDMSからのアクセスを許可するようDBの設定を変更する必要があったのですが、オペミスをしてDBを再起動してしまいました。Webコンソールでの操作はうっかりがあるので恐ろしいです。
DBが復帰して、DMSタスクを開始しましたが、30分ほどたったところでタスクが途中でコケました。タスクがコケること自体は何回も行われた移行作業で確認しており、リトライ3回までは許容範囲としており、すぐにリトライを行いました。
2度めのタスクは最後まで完了し、3:30頃にDBのデータ移行が完了しました。
完了後すぐにDBのデータ検証を行いました。
事前にチェックスクリプトを作成※1し、各テーブルのレコード数がAzureとAWSで同じになっているか、サービスのコアとなる作品とユーザのテーブルのレコードが一致しているかを確認しました。
検証は30分程で完了し、正しくデータ移行完了したことを確認しました。
※1 DMSにはレコードチェック機能があるのですが、非常に残念なことにSQL Serverではこの機能が使えませんでした。つらい。
DNS切り替え
一番の懸念点であったDB移行が正常に完了したことを受け、切り替えはほぼ成功したと判断し、DNSをAWSに切り替えました。
DNSは事前にroute53へ移管しており、AWS側でAzureのIPからALBへ切り替えるだけで完了しました。
Railsデプロイ
DBデータ移行が完了し、schema_migrationsテーブルが一致していることを確認してAWSに対応したRailsをデプロイしました。
Railsデプロイはcapistranoで自動化されているのでホストだけ変更して普段どおり投入しました。
Solr再インデックス
検索基盤のSolrはDBのデータを元に構築可能なので移行は行わず、AWS上で再構築することにしました。
rakeタスクでDBの情報から再インデックスできるタスクが用意されているのでそれを利用しました。
BLOBからS3への転送
事前転送から毎日ファイル差分を送っていたモデルデータの最後の転送をDBのデータ移行と並行して実行しました。
ニコニ立体は1日に平均10ファイルがアップロードされますが、この程度なら転送は数分で完了でき、移行タスクの中では軽い部類でした。
動作確認
すべてのデータが揃ったので4:00にシステムチェックを開始しました。
デプロイ対象は自動テストは通していますが、他のニコニコサービスとのつなぎこみやDB、Solr、nginxなどの結合テストはカバーできない※1ので手動で実施しました。
システムチェックは40分程で完了し、主要機能はすべて正常に動作していることを確認しました。
※1 やろうと思えばやれなくはないことは知っていますが、残念ながらそこまでの技術力が私にはありませんでした。自動テストの道は果てしなく遠い・・・
メンテアウト
システムが動作していることを確認できたのでメンテアウトを実施しました。
メンテ時間は余裕を見て8:00まで取っていましたが、各作業がスムーズに進み、2時間繰り上げて5:00にメンテ開けしました。
メンテ時間は3時間でダウンタイムをかなり短くでき、満足の行く結果となりました。
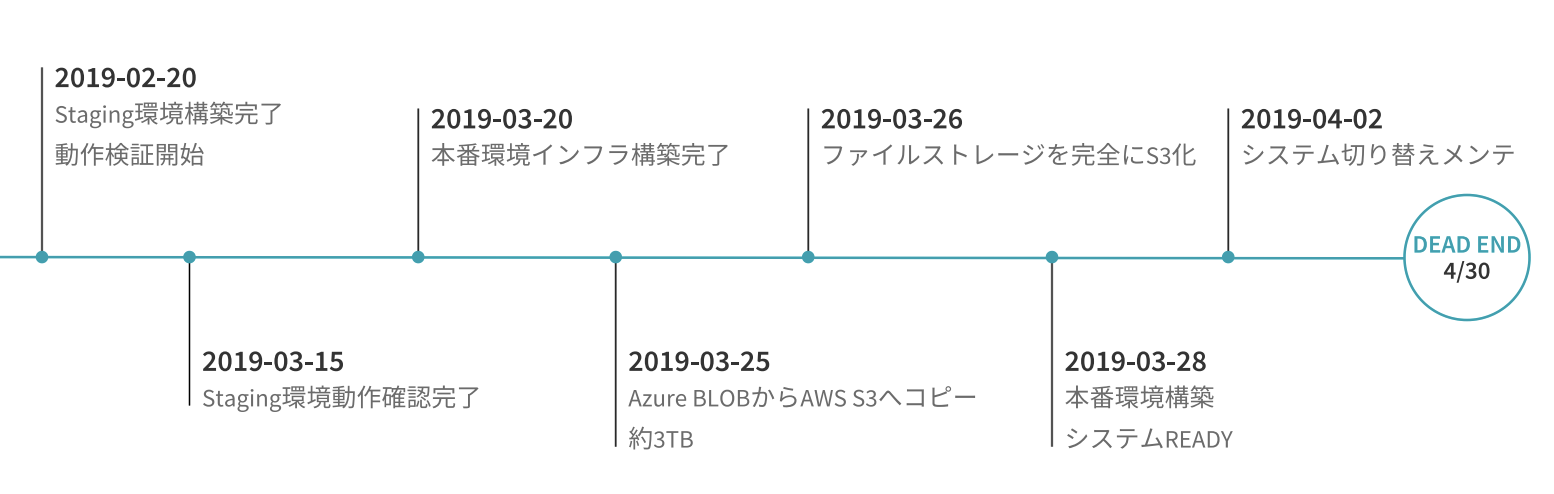
時系列まとめ
最終的にリプレイスプロジェクトは以下の図のように進みました。
2018年12月から翌年1月末までで移行方法を検証し、2/20にステージング環境を構築しました。
3/15にステージングでのシステムチェックが完了し、すべての機能が動作することを確認しました。
ステージングの構成を元に本番相当のサーバ構成でインスタンスとネットワークを構築し、3/20に本番動作可能な状態となりました。
3/28に本番環境での動作チェックが完了し、いつでもシステムを切り替えられる準備が整いました。
同時に、3/25から26にかけてBLOBからS3へのデータ移行を進め、ファイルストレージ切り替えが完了しました。
4/2の深夜にシステムを止め、AWSへ切り替えました。
4/2の深夜メンテは以下のように作業を行いました。
AM2:00にサーバアクセスを遮断してメンテINしました。
アクセスがなくなったことを確認し、2:10に最後のBLOBからS3への転送、およびDMSによるDBデータ移行を開始しました。
しかし、1回目のトライは30分経過時点でタスクがコケ、リトライを行いました。
2回目は成功し、3:30にデータ移行が完了しました。
3:30から4:00の間に担当者3人で平行にDBのデータ整合性チェック、AWS修正をしたRailsのデプロイ、SolrのIndex構築と結果チェックを行いました。
4:00にそれらがすべて問題なく完了し、DNSをAzureからAWSへ切り替えました。
4:00から本番環境でのシステム動作チェックを開始し、4:40にすべての試験項目が動作していることを確認しました。
移行作業がすべて終了したことを確認し、5:00にメンテを終了し、アクセスを開放しました。

Azure掃除
Azureからの脱却には成功しましたが、契約解除のために掃除が必要でした。
まず、S3にない場合にBLOBへリダイレクトする機能を削除し、Azureへの依存をすべて断ち切りました。
そして設定漏れなどでAzureへ向いたものが存在していないかを切り分けするために、徐々にAzureサービスを削っていくという作業を2週間かけて実施し、Azure側を削除しても問題なく動作することが確認でき、正式に移行作業が終了しました。
思わぬ収穫
AWSのインスタンスタイプはAzureのインスタンスのスペックを元に、ほぼ同じvCPUとメモリの種類を選択したのですが、5年越しでハードウェア性能が上がっていたのか、AWSの最適化がすごいのかは不明ですが、V2Vでもってきただけで何もしていないはずなのにレスポンス速度が3倍に高速化されました。
下にNewRelicの計測グラフを掲載します。
Azure時代はレスポンスに200~300ms程度かかっていましたが、AWSでは70~100msでレスポンスを返せています。あまりにも気持ちいいグラフなので印刷して精神が不安定になった時に眺めるようにしています。

また、5年の間に価格も下落しており同じスペックでも20%ほどインスタンス料金が削減できました。
フロントサーバは3台から4台に増えていて、ステージング環境分の追加もあったのですが・・・。
ミドルウェアとライブラリの改善
クラウドサービスの移行は完了しましたが、依然としてサービスの開発運用には難があるシステムです。
OSやDBをはじめ、システムの足元周りが安心できるものではありませんでした。
最初に書いたとおり、OSがUbuntu14だったり、Railsが4系だったりとサポート切れとなっているものが多くありました。
また、SQL ServerはRailsと相性が悪く、RDSのシングルAZでホストされていることもあり、早急な脱却が必要でした。
SQL Server脱却
移行先選定
5月から※1はリプレイス計画でも特に重要視していたSQL Serverの脱却を最優先で進めました。
理由はシングルAZのRDSです。Cloudwatchによる自動復旧は設置しましたが、冗長度が1であるため、障害耐性はかなり低い状況でした。
まず、移行先としてMySQLかPostgreSQLが上がりましたが、旧ステージング環境、CIテスト、ローカルマシンではMySQLを使用していたこと、社内でMySQLのほうが多く利用されていることからMySQLにしました。
私自身もRails+MySQLのほうが経験が多いので安定して保守できると考えたため、満場一致でMySQLに決定しました。
次に、RDSについては運用負荷を下げるため、フルマネージドで自動復旧などの機構がついているAuroraへの移行にしました。
Auroraはリードレプリカが昇格する際に同じエンドポイントでアクセスできることが強みですが、ActiveRecordが旧プライマリとのコネクションを離さなくて書き込みできなくなるという問題が懸念事項としてありました。偶然にも移行を検討していたタイミングでAuroraの接続問題を解消するgemが登場し、これを利用することにしました。
※1 ドワンゴあるある > 4月下旬は超会議があるので全社的にバタバタしてて通常業務に割ける時間が少なくなる。
データベース切り替え(コード編)
SQL ServerはRailsでのサポートが十分ではなく、動かすために大量のモンキーパッチが記述されていました。AWS移行と同時にDBを変更していたらこれの改修も同時に行わなければならなかったと考えるとゾッとします。段階を踏んで切り替えるという作戦にした年末の自分に盛大なる拍手を贈りました。本番環境でMySQLに影響を与えそうな※1モンキーパッチをすべて除去し、本番でMySQLを使用できるようにしました。
MySQLを使うこと自体は本番以外の環境で使用していたこともあり、database.ymlのadapterをmysqlに差し替えるだけで動かすことができました。
問題はSQL Server関連のgemの切り離しで、なぜかTinyTDSのgemを外すと動かなくなるという現象が起こりました。
原因はTinyTDSがRails4系の動作を自身でも持っていたことでした。
TinyTDSを外そうとした時点でRailsのバージョンが5.0に上がっており、Rails 4 -> 5 の時にActiveRecordのbelongs_toの外部キーのデフォルトがrequired: trueとなりましたが、TinyTDSはこの部分をrequired: false相当で動作するように上書きしていました。しかし、Railsバージョンアップの際にこの修正を行っておらず、動作もしたため なぜかわからないが動く という状況に陥っていました。TinyTDSを外すとrequired: falseが効かなくなり、Not NULL制約に引っかかったためでした。外部キーにNULLが入る箇所を洗い出し、required: falseを指定することで回避しましたが、そもそもbelongs_toがnilな事自体が良くない設計だと思うので要再設計としてIssue化しました。
※1 「if Rails.env.production? # SQL Server対応」というコードを見るたびにめまいが起きていました。
データベース切り替え(データ移行)
別種のデータベースエンジンの移行は昔だと血反吐が出るような作業でしたが、AWS上ではDMSとSchema Conversion Toolを利用することでサクッと移行できるようになっています。
SCTでコンバートしたスキーマ情報は概ね問題ないのですが、DateTime型の精度がMySQLのデフォルトと違っていたりして※1、微妙に罠があるので
そしてここにもDMSの罠があって、RDS料金をケチるためにWebクラスのインスタンスを利用していたのですが、WebクラスだとDMSの継続的レプリケーション機能が利用できず、一括でデータ移行しなければなりませんでした。
幸い、MySQLでの動作確認を完了した2週間後にニコニコ全体停止メンテがスケジュールされたので、この時に同時に移行することにしました。
4/2の移行手順と同じ要領で、SCTで予め構築したAuroraインスタンスにDMSでマイグレーションを行いました。
今度は1発で成功し、15分ほどで移行完了しました。
※1 SQL Serverのデフォルトがミリ秒精度で、MySQLのデフォルトが秒精度なので。MySQL5.6以降はcreate table時にDATETIME(3)と指定することで少数以下の精度の拡張ができる。
Solr脱却
SolrからElasticSercchへの移行に関してはあまり詳しく書くことができません。
というのも、この作業はSolrとESの両方に詳しい同僚がやってくれたからです。
私がやったのはRailsのコードレビューぐらいで、環境構築やデータ移行は同僚におまかせしました。
Railsでの特徴的なことは、elasticsearch-rails gemではなく、chewy gemを利用したところです。
elasticsearch-railsはelastic社が公式で出しているのですが、率直に言うと学習コスト、メンテ、品質の点で難があります。
これを導入するとつらみしかないなと感じたのでなにかないかと探したところ、chewyという最高のgemをみつけました。
このgemは絶賛するところしかなく、modelを汚さず、豊富で便利なrakeタスクが用意されており、コードが読みやすいという最高の3点セットが揃っていました。レビュー時の体感で読みやすさが80倍ぐらい違ったのでこれからESを使う方はぜひ使ってみてください。
CDN導入
移行段階ではCDNがなく、全てのデータをnginxが返している状況でした。
立体モデルは静的なファイルですが、容量が最大で100MB近くあり、中央値でも20-30MBほどあります。
フロントサーバの帯域の8割がこのモデルデータの返却に使われており、ボトルネックとなっていました。
フロントサーバの不要な負荷を減らすため、前段にCloudfrontを導入し、静的なファイルをキャッシュから返却するようにしました。
ファイルキャッシュ
キャッシュするファイルはキャッシュによる不具合が起こらないものにしました。
S3に置かれているモデルデータは更新されるたびにファイル名を変更しており、衝突しないようになっているのでキャッシュバグは起こらず、オーソドックスな使い方でもあるので満を持して導入しました。
これによりフロントサーバの帯域負荷が70%削減できました。
Railsのキャッシュについては、トップページやランキングは1日毎にしか変わらないのですが、キャッシュ破棄のタイミングが難しく、また、おすすめなどはユーザごとに違うため、Railsのレスポンスはキャッシュしないことにしました。
一方で、Assets配下のCSSやJSのファイルはデプロイごとにファイル名が変わり、衝突しないことから、Asset配下はキャッシュをするようにしました。この中にはモデル表示用のWebGLプレイヤーのデータもあり、これが20MBほどあるのですが、これがCloudfrontでキャッシュされることで更に帯域不可の削減に寄与できました。
最終的にフロントサーバの返却データ量を97%削減することに成功し、サーバリソースをより重要なRailsの処理に集中できるようになりました。
ファイルのアクセス制限
ニコニ立体はニコニコアカウントでログインしていないとモデルの閲覧とダウンロードができないようになっていますが、これまではアクセス制限をnginxでやっていました。Cloudfrontには似たような機構として署名付きURLというものがあり、Railsでダウンロードリンクを生成する時にIP制限付き署名付きURLを発行して他の人からアクセスできないようにしました。ただ、この署名付きURLが非常に長く、IEなどの一部のレガシーなブラウザでは途切れてしまってダウンロードできないという状態になりました。不要なパスやパラメータを限界まで削ってIE11では動くようにはしましたが、ブラウザによっては閲覧できないこともあります。サポート対象のChrome,Firefox,Edgeのいずれかのブラウザをご利用ください。開発チームからの切実なお願いですのでなにとぞよろしくお願いします。
Ubuntuバージョンアップ
OSバージョンアップは最も難易度が高い作業でした。
リプレイスプロジェクトの最初に決めた「変更を最小限にする」という原則を守ることが困難で、一気に変更する箇所が10箇所近く発生しました。結果的には不具合が一つで済み、その修正も長引かなかったのでマシな方でしたが、プロジェクトを通して最大の失敗をしてしまいました。
この改修は項目が多いので個別に解説していきます。
Ubuntu 14 => 18
5年の間にメジャーバージョンが4も上がりました※1。
このバージョンアップで最大の変更は起動スクリプトのSystemd採用でした。
Ubuntu14用に書かれたinit.dスクリプトも動くことは動くのですが、あまり古いコードを持っていたくないこと、Systemdの死活監視、自動復旧機能が魅力的だったのでSystemdに移行しました。
OSアップデートによる変更はこの1点のみでしたが、変更を小さくするという原則を守るならinit.dスクリプトをコピーし、その後にsystemdに切り替えるべきでしたが、init.dの書き方がまずく、Ubuntu18では起動できませんでした。
※1 UbuntuのLTSは偶数バージョンだけなのでそういう意味では2個しか上がっていない。
debパッケージアップデート
OSアップデートの難易度が高い原因の9割がこのdebパッケージでした。最初はaptのバージョン指定でUbuntu14のものと同じバージョンを入れるか、Ubuntu14側で最新までアップデートをしてからUbuntu18に移行と思いました。
しかし、一部のパッケージが同等のバージョンの提供を終了しており、依存パッケージが連鎖的に導入できないということが判明し、個別に手動インストールするのも時間がかかりすぎるということもあり、同一バージョンでのインストールは断念しました。
もう一方のUbuntu14側でのアップデートも困難を極めました。HTTPサーバとしてnginxを使用しているのですが、このnginxが魔改造コンパイル品で、改造コードからのコンパイルができなくなっていました。このnginxがクセモノで、apt upgradeではアップグレードできず、新しく入れようとしても依存パッケージのバージョンでインストールできず、依存パッケージを上げると古いnginxが起動できなくなる上、新しく入れたnginxも起動しないという状況でした。
にっちもさっちもいかず1ヶ月ほど格闘したのですが、解決方法が思いつかず、運を天に任せてえいやと入れ替えてしまうことにしました。
結果として問題となっていたnginxはうまく移行できたのですが、そちらに気を取られて他のパッケージの罠を踏み抜いてしまいました。
ImageMagick破壊的変更の罠
ImageMagick6.8.0の変更で色空間の指定方法が真逆に変わりました。どうして・・・。
Ubuntu14に入っていたImageMagickのバージョンは6.7系で、Ubuntu18でapt installすると6.8系になり色空間が入れ替わりました。
ImageMagickのこの修正を認知しておらず、バージョンアップの差異チェックで気づかずに上げてしまったため、変換後の画像が白飛びするという不具合が発生してしまいました。ご迷惑をおかけして申し訳ありませんでした。
この件は変換時の色がおかしいという症状からすぐに原因にたどり着き、変換時のオプションにsRGBを指定する修正を入れることでなおりました。
- colorspace: Magick::RGBColorspace
+ colorspace: Magick::SRGBColorspace
ansible作成
Ubuntu18での環境構築には新しくansibleを作成しました。
Ubuntu14を作成した当時はchefを使ったようなのですが、残念ながら現行環境では動作しませんでした。
chefから当時の状況を読み解き、Ubuntu18で動作するようにansibleに書き直しました。
どちらにしろAWS関連の設定やバージョンが変わったことによる設定ファイルの更新なども行わなければならなかったので、使えるものはニコニコサービスとのつなぎこみ部分だけでした。
Railsのデプロイはcapistranoを使用しているので、ansibleではcapでRailsが起動できるところまで整えるようにしました。
Railsを動かす最小限にとどめたのでplaybookの量は少なく、rbenvとrubyのビルドに必要なaptパッケージのインストールとコンフィグファイルの設置ぐらいです。
オートスケーリング導入
下の与太話で書いているのですが、ニコニ立体は毎年12月25日にVTuberのMMDモデル投稿があり、そのたびにサーバがダウンしていました。
一昨年は運用担当がおらず、翌日に偶然気づいた社員がslackで発言したことで発覚しました。
去年はAWSリプレイス計画が進んでおり、私も担当として当日オフィスにいて気が付きました。
この時は手動でスケールアップし対応しましたが、これらの二の舞を避けるべくオートスケーリングを導入して手動オペレーションをなくすことにしました。
最初はDockerとECSでモダンに構築する案も出たのですが、Docker化は現行のシステムから修正しなければならない箇所が多くすぐには不可能でした。
そこで、とりあえずの対応ということでEC2の単純なオートスケーリングを導入しました。
デプロイスクリプトが固定サーバに特化した書き方をされており、またcapistranoがオートスケーリングと相性が悪いということもあり、capタスクにパッチを当てて、以下の動作をするようにしました。
- スケールアップ/ダウンの停止
- 起動中のインスタンスへのデプロイ
- AMI作成
- 起動設定の更新
- スケーリングの再開
少し強引にオートスケーリングを導入しましたが、Docker化までのつなぎということで一旦許容しました。
オートスケーリングのメトリクスは、ALBのターゲットごとのリクエスト数にしました。
1インスタンスの限界スループットがわかっていたので、それの8割程度でスケールアップするように設定しました。
これから
ニコニ立体の負債はまだまだ残っており、これからもゆっくりとですが改善を続けていく予定です。
直近ではRailsのバージョンが5.0で足踏みしている状態の解消を目指し、gemやaptの継続的なアップデートを行います。
また、インフラもまだまだ改善の余地があるため、これらの現代化も進める予定です。
個人的にはTerraform+FargateでBlueGreenDeployまで持っていければ最高だと考えていますが、どこまでできるかは今後の状況次第、といったところです。
ほかにもレガシーなコードがたくさんあるので負債解消を趣味にしている身としてはやることが尽きないという状況です。
ニコニ立体与太話
2018/12/25 シロ砲事件
AWS移行検証をカタカタやっていると、エゴサ欄が慌ただしくなって、何だと思って本番を見たら落ちてました。
ちなみに本番監視アラートはなく、エゴサだよりでした。
原因はVTuberのクリスマスプレゼントで、.LIVE所属のライバーのMMDモデルが12人分投稿され、祭り状態となったようです。
翌日の報告会で投稿したアカウントが「電脳少女シロ」さんのアカウントであったことから「シロ砲事件」と呼称され、定着しました。
アップされたのは午後9時頃でしたが偶然勤務中※1でしたのでそのまま対応に当たりました。
当時はまだAzureで動いていたのでクラシックなサーバ3台で動作しており、バックアップやLBへの組み込みもできなかったためスケールアウトという手順はすぐに棄却されました。
コンソールから再起動を伴うスケールアップの機能は問題なく動くことが(手違いで※2)判明してたので、スケールアップを行い、nginxとunicornのプロセスを増やして捌くという手段のほうが対応時間が短く、間違いも無いということでインスタンスタイプを2段階引き上げました。
結果、ダウンから1時間ほどで重いながらもリクエスト漏れやエラーはなくなり、サービス復旧しました。
※1 ドワンゴは裁量労働制が完全に導入されており、この日も午後2時に出社したばかりでした。クリスマス?知らない文化ですねえ・・・
※2 この前週にwebコンソールをいじっていたらいきなりスケールアップして焦りました。なんと起動中のインスタンスを選択してプルダウンリストを変更すると確認無しで再起動が走りインスタンスタイプが変更されます。おどろき!
2019/08/23 メリーミルク砲
この日は休暇をとって諏訪湖に避暑旅行をしていたのですが、湖畔で涼んでいると突然アラート着信が来ました。
担当は基本的に私一人なので旅行先にも作業用PCを持っていっているのですが、まさか開くことになるとは思いませんでした。
原因は去年に続き.LIVE所属のメリーミルクさんのMMDが投稿されたことでした。
このときはAWS化の効果でフロントサーバ4台※1となり、CloudFrontでモデルデータをキャッシュするようにしたこともあって数万rpm程度出るようになっていたため、操作することもなく5分ほどでサーバエラーは収束しました。
※1 デプロイスクリプトの調整が思いのほか大変でオートスケーリングは未導入でした。
2019/11/29 ホロライブMMD
去年の二の舞を避けるべく年末に向けて11月中旬にオートスケーリングの導入をおこなったところ、導入して2週間目にホロライブ所属のVTuver10人のMMDモデルが投稿されました。
時間帯が平日の午後5時だったこともあり流入は緩やかで、オートスケーリングがうまく追従できました。総転送量は.LIVEの時と同等で、ピークとなった午後8時台でもオートスケーリングのおかげで落ちることなく、レスポンスタイムも安定して100ms前後に保つことができました。
最大ピーク流量は去年のクリスマスのバズの60%ほどでしたが、去年はリクエストの7割がサーバ到達前にパケットロスしてしまっていたのに対し、今年はパケットロスもなく、500エラーも0.01%未満にできました。去年は3時間ほどで収束しましたが、今回は休日前ということもあり、6時間以上に渡って普段のピーク時の5~10倍の流入がありました。
翌日には白上フブキ氏のチャンネルでMMD解説実況が行われ、この時は急激にアクセスが増え、瞬間的に前日のピークの1.2倍ほどの分速流量を記録しました。このときは追従が間に合わず、最初の数分間レスポンスが遅くなっておりましたが、すぐに追従し、レスポンスタイムも正常に戻りました。