はじめに
この記事は STORES.jp Advent Calendar 2019 の 18 日目です。
最近、プロダクトのコードの計測と可視化を少しずつはじめています。
まだ始めたばかりなので大きな知見が蓄積されているわけではないのですが、以下のような自問を繰り返しながらやってみるなかで、見えてきたことも増えてきました。
- 計測・可視化の仕組みを整えるためにはその他の作業を止めることになる。そうまでして行うメリットはどこにあるのだろうか
- なるべく効果的に実施するためには、何を、どう計測するのが良いだろうか
この記事では、これらに対する自分なりの答えについて、実際にやってみたことを踏まえて簡単に書こうと思います。
なぜ計測・可視化をするのか
いわゆる技術的負債を返済していくためには、多くの場合は既存コードのリファクタリングを行うことになります。
そのようなシチュエーションでは、大きくなったモノリスや、複雑に絡み合ったコードに立ち向かうことになりますが、具体的には何から着手したら良いか明らかではない場合が多いと思います。
例えば以下のような問題があったとしたら、どれを優先して、どこから着手すべきでしょうか?
- 複雑で長大なクラス、モジュール、メソッド
- 参照されていない(かもしれない)不要なコード
- ミスリーディングな名前付け
- 再利用のメリットの高い重複したコード
- 変更可能性、安定性の違う結合したコード
実際の数や量、影響度、関連性などなどが不明だからよくわからない、というのが正直なところですよね。
問題が分かっていればまだ良くて、そもそもどんな問題があるか明らかではない場合もありますし、問題だと認識していたけれども実はそんなに問題でもなかった場合も多くあります。
また、改善したつもりが逆に複雑さを増してしまったとか、意図したトレードオフが取れていなかったようなこともあります。
そしてこれらの問題の解釈や解決方法には個人差があり、チームとして認識を揃えるのが難しいのもやっかいな点です。
作業が人に依存してしまうと、全体として成果を出しづらかったり品質が安定しなかったりします(これは普段の開発でも同じことがいえますが)。
このように、リファクタリングを行うといっても、技術的負債を返すという文脈ではなかなか単純な話ではありません。
結局はとにかくやっていくしかないのですが、リソースはいつでも有限なので、むやみに動いて浪費したり手戻りがあったりしないように、効率的に動きたいものです。
そのために、計測を行って個々の問題を可視化することが大事なのではと思います。問題とその影響を完全に明らかにすることはできませんが、少しでも見える部分を増やして、分析しやすい状態にするのです。
また、可視化によってチームの認識を揃えて、あらたな技術的負債を意図せず生み出していないか、気づきやすい状態にすることも有効だと思います。
よくある格言に「推測するな、計測せよ」というのもあります。
これは(おそらく) Rob Pike の Notes on Programming in C のルール 1 と 2 が元になっていて、主にパフォーマンスの最適化に対して言及したものですが、事実に基づいて設計判断をするという姿勢は同じではないかなと思います。
どうやって行っているのか
計測・可視化に必要なものは、ざっくりと
- 計測を実行する仕組み
- 計測結果を記録する仕組み
- 記録した計測結果を加工して可視化する仕組み
の 3 つが必要です。
これらを実現する方法としては様々な選択肢がありますが、まだまだ効果的な計測や可視化というものが何か見えていません。
従って、実験的に小さく始めて、仕組みに(時間的・金銭的)コストを掛けすぎないようにしたいと考えました。
なので、とりあえずは個人的に使い慣れた手頃な道具ではじめてみました。以下のような構成です。
- 計測を実行する仕組み → CircleCI
- 計測結果を記録する仕組み → Google スプレッドシート + GAS
- 記録した計測結果を加工して可視化する仕組み → Google データポータル
具体的な例を示したほうがわかりやすそうなので、以下、2 つほど紹介します。
例 1: コード行数内訳の推移
コード行数の内訳推移がわかると、コードの全体的な変化の傾向が可視化されます。
たとえば Controller と Model の行数の増減関係であったり、Controller spec から Request spec への移行進捗であったりがわかりやすくなります。
コード行数内訳を出力する rake task を作成
Rails アプリケーションでコード行数といえば rake stats なのですが、この結果はヒューマンリーダブルではあるものの、計測結果としては扱いづらい面があります。
なので、JSON で結果を出してくれる rake stats:code_lines なるものをざっくり作りました。
require 'rails/code_statistics'
module CodeStatisticsExposable
refine CodeStatistics do
def code_lines
pairs = @statistics.map { |name, statistics| [name, statistics.code_lines] }
Hash[pairs + [["Total", @total.code_lines]]]
end
end
end
namespace :stats do
# spec ディレクトリしたも集計対象にするために rspec-rails のタスクを先に実行
# https://github.com/rspec/rspec-rails/blob/v3.8.3/lib/rspec/rails/tasks/rspec.rake#L48
task code_lines: "spec:statsetup" do
using CodeStatisticsExposable
code_lines = CodeStatistics.new(*STATS_DIRECTORIES).code_lines
meta = {
commit: `git rev-parse HEAD`.chomp,
sheetname: "code_lines"
}
puts code_lines.merge(meta).to_json
end
end
結果はたとえばこんな感じ。
$ bin/rake stats:code_lines
{"Controllers":12345,"Helpers":123,"Models":12345, ... ,"sheetname":"code_lines"}
sheetname というメタデータは、あとで GAS がスプレッドシートに書き込むときの目印に使います。
CircleCI で計測を実行して結果を記録 Web API に送信
先程の rake stats:code_lines を CircleCI で定期実行し、結果を記録用の Web API に送信します。
その時の設定は大体こんな感じ(簡略化してます)。
jobs:
code_lines:
executor: default
steps:
- run:
name: Record code stats
command: |
bundle exec rake stats:code_lines > code_lines.json
curl -L $STATISTICS_POST_ENDPOINT -d @code_lines.json
workflows:
version: 2
metrics:
triggers:
- schedule:
cron: "0 16 * * *" # 16:00 UTC (1:00 JST)
filters:
branches:
only:
- master
jobs:
- code_lines:
計測結果を受け取った GAS がスプレッドシートに記録
GAS は https://github.com/upinetree/gas-post-json-app で公開しているようなものです。
POST エンドポイントが、受け取った JSON の sheetname の値をもとに書き込むシートを特定し、行を追記していきます。
これを記録用スプレッドシートに紐づけて、Web API としてデプロイしました。
そのあたりの詳細なやり方は他にたくさん情報源があるのでここでは割愛させてください(書く体力が… 👴)。
ハマったポイントは、GAS の POST はレスポンスがリダイレクトになるので、そのための GET エンドポイントを用意する必要があることと、 curl するときに -L オプションが必要なことでした。
Google データポータルで可視化
Google データポータルは他の様々なサービスと連携できる、無料のダッシュボードサービスです。
Google の提供するサービスとの連携はもちろん、サードパーティのサービスも連携できるようです。Twitter 検索の連携とかもあって、色々遊べそうですね。
海外では Google Data Studio という名前なのですが、なんか商標?の関係で日本だけデータポータルと呼ぶっぽいです。
先程の記録用スプレッドシートをデータソースに指定して、ダッシュボード(データポータル的にはレポート)を作成します。
そのあたりの詳細なやり方は他にたくさん情報源があるのでここでは割愛させてください(書く体力が… 👴)。
これでコード行数の推移が可視化されました!
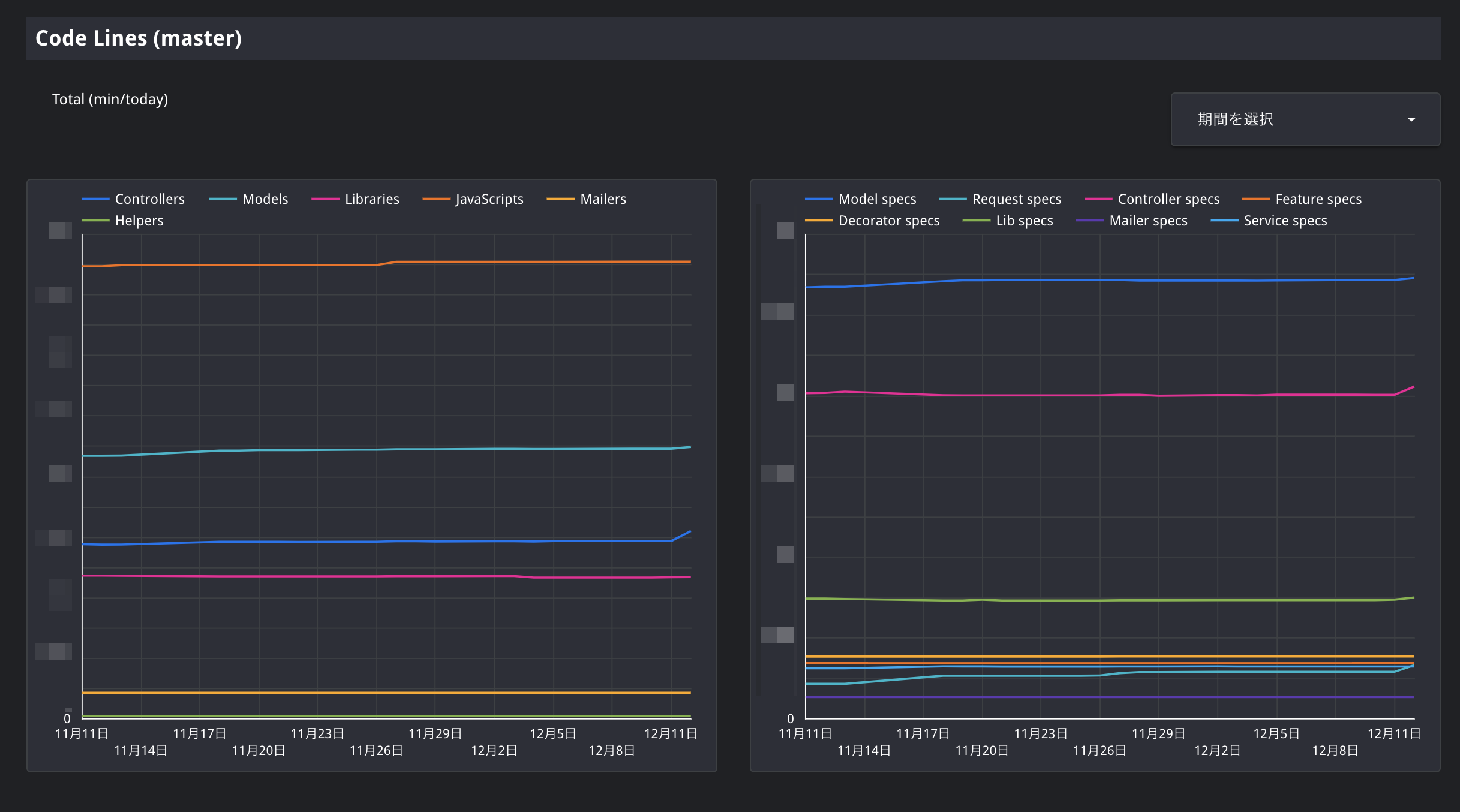
実際にコード行数の推移を見てみると、増加傾向のコードがある一方で、減少傾向のコードもあることもわかります。コードは線形に増加しているわけではなくて、生き物のように日々姿を変えていることが興味深いと思いました。その姿をひと目で観測できるようになり、プロダクトのイベントと照らし合わせて分析しやすくなったというだけでも、可視化してよかったと思います。
きっと比率とかで表示しても面白いんだろうなあとか、毎週Slackに画像で通知するとかしてみんなでああだこうだ分析できたら楽しそうだなあとか夢が広がります。
データポータルは今回初めて使ったのですが、スプレッドシートとの連携がスムーズで簡単に操作できました。
一方でグラフを思ったように表現することができずハマったこともあったので、ある程度の試行錯誤は織り込んでおくとよさそうです。
例 2: Rubocop の Metrics cop 違反数の推移
AbcSize とか BlockLines とか、デフォルト設定だとそこそこキツいアレ。
refs. https://docs.rubocop.org/en/stable/cops_metrics/
理想的にはデフォルトでパスできているのが良い状態ですが、既存コードに Rubocop を適用する場合はそう簡単にはいきません。
一度に違反をゼロにするのは非現実的なので、徐々に減らしていきたいところです。
そのために、まずは違反の数を記録して、その推移を可視化することで、リファクタリングによって違反を減らせたとか、逆に新しく作った機能が違反を増やしてしまったとかを検知しやすくします。
また、それぞれのルールの違反数がどれだけあって、どれが一番多いのかという情報も、コードの形を客観的に知るために便利そうです。
CircleCI で違反数を計算
CircleCI の設定はだいたいこんな感じ。
orbs:
jq: circleci/jq@1.9.1
jobs:
rubocop_metrics:
executor: default
steps:
- jq/install
- run:
name: Calculate rubocop metrics violations
command: |
mkdir -p ${CIRCLE_ARTIFACTS}
bundle exec rubocop --only Metrics --config .rubocop-strict.yml --format json --parallel > ${CIRCLE_ARTIFACTS}/metrics_cop_result.json || true
- run:
name: Count rubocop metrics violations
environment:
JQ_FILTER: '[.files[] | .offenses[]] | group_by(.cop_name) | map({(.[0].cop_name): length}) | add + {sheetname: "rubocop_metrics_count"}'
command: |
jq -c "${JQ_FILTER}" ${CIRCLE_ARTIFACTS}/metrics_cop_result.json > ${CIRCLE_ARTIFACTS}/metrics_cop_violations.json
- run:
name: Send rubocop metrics violations
command: |
curl -L $STATISTICS_POST_ENDPOINT -d @${CIRCLE_ARTIFACTS}/metrics_cop_violations.json
ご覧の通り、rubocop の実行結果を --format json によって JSON 形式で取得して、 jq で必要な形に変換しています。
また、普段の rubocop のルールは Metrics cop がゆるく設定されているので、ほぼデフォルトの設定を --config .rubocop-strict.yml で指定します。
jq は便利なのですが、呪文になりがちなのがデメリットかなと思います。
かといってこのためのスクリプトを組むほどでもなく、使い慣れた道具で小さく始めるというコンセプトとしてはまあよしとしてます。
計測結果を受け取った GAS がスプレッドシートに記録
書き込み先のシートを JSON のsheetname によって切り替えただけで、あとはコード行数のときと同じです。かんたん!
Google データポータルで可視化
これもデータソースを切り替えるだけで、コード行数のときと同じ手順で実現できます。かんたん!
まとめ
コードの計測・可視化の意義を考えた上で、小さく実験的にはじめるために、(私にとって)使い慣れた道具で実現することができました。
今回はコード行数と Rubocop 違反数の推移の計測を紹介しましたが、そもそも何を計測するのが効果的なのか?というところはまだ考えを深められていません。
これに関してはいくつかアイデアはあるものの、決定的な基準というのもないので、やっぱり試行錯誤しながらやっていくことになりそうです。
これからも地道に少しずつ進めていきたいと思います。