前書き
この記事は、2023のUnityアドカレの12/19の記事です。
今年は、完走賞に挑戦してみたいと思います。Qiita君ぬい欲しい!
はじめに
前回は、Shaderの分岐について、コンパイル時定数によるstatic分岐、ConstantBufferによるuniform分岐、スレッドごとに別のパスを通りうるdivegent分岐について、パフォーマンスを計測しました。結果、uniformやdivegent分岐でも、グループ内のすべてのスレッドが同じパスを通るなら、もう一方のパスは待機ではなくスキップされることが確かめられました。
Powを計算するという、純粋に計算量が多くなるようなタスクを実行しました。Shaderで重たい処理と言えば、Textureのフェッチです。
テクスチャフェッチが重い理由
昨今のGPUは高速化が進み、単純な四則演算ならお茶の子さいさいですから、10000次まで計算して差を見ました。数の暴力です✊(それでもRTXでは0.2msなので驚きですが)
一方テクスチャフェッチは事情が異なります。テクスチャフェッチをもっと一般的に言うと、ShaderResouceObjectのあるメモリへのアクセスということになります。ShaderResouceObjectはDirectXでの呼称でTextureとStructuredBufferを含む概念です。Expの計算ではレジスタ内での演算で済みましたが、メモリへのアクセスを伴うというところが重くなるポイントです。
厳密に言うと、負荷が高いというよりレイテンシ(遅延)が長いというのが正確でしょう。レジスタは演算コアと同じチップ内の隣にありすぐにアクセスできますが、メモリ(ここでいうメモリはVRAM、GPUに搭載されたメモリ)は別チップで基板上の限られた通信線を使って通信しなければなりません。故にデータが欲しくなってFetchをかけてから、応答のデータがやってくるまで数百クロック待たされることになるというわけです。
テクスチャのプリフェッチ
上記の話だけなら、分岐に関しては、単に演算が重い場合と変わりありません。しかし、GPUにはプリフェッチという機能があるという噂を耳にします。
もしもプリフェッチによってShaderの頭でフェッチをかけてしまうのであれば、if文で必要なかったとしても読み出しが発生してしまいかねません。
一方で、GPUではプリフェッチは難しいという言及も見られます。「Boosting Application Performance with GPU Memory Prefetching」では、GPUではプリフェッチに代わりとして余剰のワープを使うと書かれています。余剰のワープというのは、テクスチャのフェッチをかけ応答が到達するまで待機している間、そのワープは後回しにして他のワープを実行するということです。
Prefetching is a useful technique but expensive in terms of silicon area on the chip. These costs would be even higher, relatively speaking, on a GPU, which has many more execution units than the CPU. Instead, the GPU uses excess warps to hide memory latency. When that is not enough, you may employ prefetching in software. It follows the same principle as hardware-supported prefetching but requires explicit instructions to fetch the data.
計測
ということで実際に確かめてみましょう。
実装
基本的には前回と同じです。
Powを10000次のマクローリン展開で求めていた部分を、20回のテクスチャサンプルに置き換えました。逐次的にならないよう手動でFlattenしました。
Texture2D<float> _Input;
SamplerState sampler_linear_repeat;
uint _Input_Width, _Input_Height;
float Fetch(float u)
{
float r = 0;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.00), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.05), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.10), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.15), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.20), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.25), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.30), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.35), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.40), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.45), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.50), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.55), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.60), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.65), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.70), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.75), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.80), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.85), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.90), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 0.95), 0).r;
r += _Input.SampleLevel(sampler_linear_repeat, float2(u, 1.00), 0).r;
r /= 20;
return r;
}
// CSMain
float u = id.x / (float)_Input_Width;
float r;
{
#if defined(BRANCH)
[branch]
#elif defined(FLATTEN)
[flatten]
#endif
if(fast)
r = u; // fast
else
r = Fetch(u); // slow
}
_Output[id.x] = r;
プロジェクト
結果
前回と同じく、それぞれ60フレームの平均をμsで出力しました。
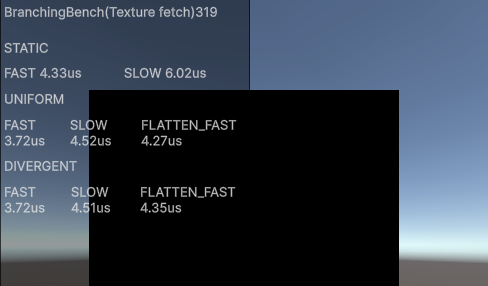
以下はFastパスです。テクスチャアクセスを実際にはしない場合です。
| GPU | API | static | uniform | divergent |
|---|---|---|---|---|
| RTX 4070 ti | DX11 | 6.02 | 4.52 | 4.51 |
| Adreno730(SM8475) | Vulkan | 16.30 | 13.29 | 13.76 |
| Adreno619(SM6375) | Vulkan | 19.30 | 20.57 | 23.50 |
以下はSlowパスです。RTXはテクスチャサンプルが速すぎてFastパスとの差がよくわかりません…w
| GPU | API | static | uniform | divegent | uniform (Flatten) | divegent (Flatten) |
|---|---|---|---|---|---|---|
| RTX 4070 ti | DX11 | 4.33 | 3.72 | 3.72 | 4.27 | 4.35 |
| Adreno730 (Snapdragon8+Gen1) | Vulkan | 47.38 | 44.26 | 45.06 | 45.59 | 48.13 |
| Adreno619 (Snapdragon 695) | Vulkan | 209.99 | 199.32 | 198.85 | 199.83 | 198.08 |
前回と同様に、uniform、divegentであってもstaticと同等近くまで速くなりました。
考察
上記の結果より、GPUでテクスチャのプリフェッチはされていなさそう、あるいはプリフェッチが無駄になったとしてもパフォーマンスへの影響がないということが言えそうです。
まとめ
前回のように演算が分岐でスキップされることは知っていたのでif文で書いていて、テクスチャの有無に関してはstatic分岐を使っていたのですが、どうやらその必要もなさそうでした。
やはり、総じてShaderでのif文は無理に避けるべきものでもないということが言えそうです。