MultiRenderTargetについて
MultiRenderTarget(以降MRT)は、レンダリングの出力先に複数のバッファを指定することができるGPUの機能です。主にDeferredShadingなどを実現するために用いられます。
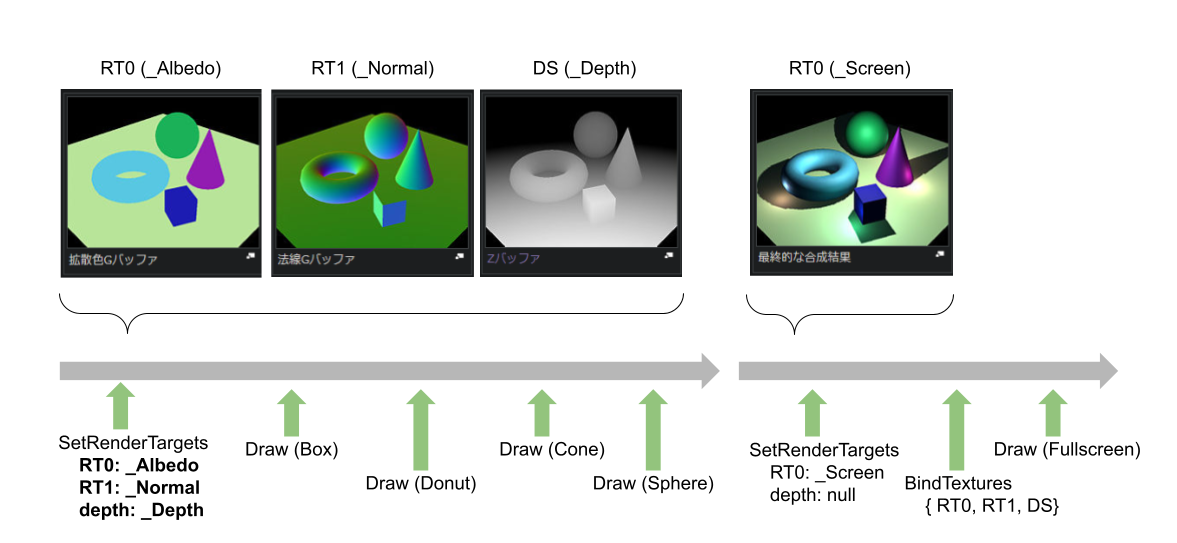
上記の例では、出力先のバッファとして、_Albedo、_Normalの2枚をセットしています。
Vulkanでは、RenderPassのAttatchmentsに指定した上で、SubPassのColorAttachmentsに指定することで利用できます。DirectXでは、ID3D12GraphicsCommandList::OMSetRenderTargetsに複数のRTを詰め込んだDescriptorを指定することで利用できます。
HLSLでは、PixelShader出力にSV_TARGET{N}セマンティックスを付けることで指定できます。
void FragmentMain(
Varings varings,
out albedo : SV_TARGET0,
out normal : SV_TARGET1)
{
float2 uv = varings.uv;
albedo = varings.color * _AlbedoMap.Sample(sampler, uv);
normal = varings.normal * _NormalMap.Sample(sampler, uv);;
}
RenderTargetの指定数が矛盾する場合
上記例のDeferredShadingのように、すべてのオブジェクトがそれぞれのバッファへの出力を持っているべき設計の場合は問題ありません。
しかし、特定のShaderで描かれたピクセルのみを記録しておきたい場合など(StencilBufferのような用途)では、それ以外のShaderでは出力を省略できると便利です。
また、逆に特定のPostEffectが不要な場合CPU側でセットするRTの枚数を減らしてShaderは共用したいという需要もあります。
疑問はいくつかあります。
- そもそも出来るのか、省略した場合どんな挙動になるのか
- 不要なRTをセットした場合のオーバーヘッド
- 不要な出力(
SV_TARGET{N})をした場合のオーバーヘッド
少し手抜きですが、Unity経由で確認してみます。
最小限のRenderPipline
URPやHDRPは、ScriptableRenderFeatureAPIやCustomPassAPIを使うことで拡張することができます。しかし、パフォーマンスを測る上でノイズになるので、最小限のパイプラインを構築します。タイルベースレンダリングの場合、RTの扱い変わるため、RenderPass/SubPassによる実装としています。
以下のRenderPipeline及び、RenderPipelineAssetを作成し、AssetインスタンスファイルをProjectSettings/Quality/RenderPiplineAssetにセットします。これがPixelShaderの出力の受け皿となる側ということです。

protected override void Render(ScriptableRenderContext context, Camera[] cameras)
{
foreach (var camera in cameras)
{
Render(context, camera);
}
context.Submit();
}
void Render(ScriptableRenderContext context, Camera camera)
{
camera.TryGetCullingParameters(false, out var cullingParameters);
var cullResults = context.Cull(ref cullingParameters);
var drawSettings = new DrawingSettings(m_ShaderTag, new SortingSettings(camera));
var filterSettings = new FilteringSettings(RenderQueueRange.all);
context.SetupCameraProperties(camera);
// Alloc
using (var cmd = new CommandsScope(context))
{
cmd.Cmd.GetTemporaryRT(_Depth, camera.pixelWidth, camera.pixelHeight, 24, FilterMode.Bilinear, GraphicsFormat.None);
cmd.Cmd.GetTemporaryRT(_Color0, camera.pixelWidth, camera.pixelHeight, 0, FilterMode.Bilinear, GraphicsFormat.R8G8B8A8_UNorm);
cmd.Cmd.GetTemporaryRT(_Color1, camera.pixelWidth, camera.pixelHeight, 0, FilterMode.Bilinear, GraphicsFormat.R8G8B8A8_UNorm);
cmd.Cmd.GetTemporaryRT(_Color2, camera.pixelWidth, camera.pixelHeight, 0, FilterMode.Bilinear, GraphicsFormat.R8G8B8A8_UNorm);
cmd.Cmd.Blit(Texture2D.whiteTexture, _Depth);
cmd.Cmd.Blit(Texture2D.blackTexture, _Color0);
cmd.Cmd.Blit(Texture2D.blackTexture, _Color1);
cmd.Cmd.Blit(Texture2D.blackTexture, _Color2);
}
// Draw
using var attachments = (stackalloc[]
{
new AttachmentDescriptor(GraphicsFormat.D24_UNorm)
{
loadStoreTarget = _Depth,
loadAction = RenderBufferLoadAction.Clear, storeAction = RenderBufferStoreAction.Store,
clearColor = Color.clear, clearDepth = 1, clearStencil = 0,
},
new AttachmentDescriptor(GraphicsFormat.R8G8B8A8_UNorm)
{
loadStoreTarget = _Color0,
loadAction = RenderBufferLoadAction.Clear, storeAction = RenderBufferStoreAction.Store,
clearColor = Color.yellow, clearDepth = 1, clearStencil = 0,
},
new AttachmentDescriptor(GraphicsFormat.R8G8B8A8_UNorm)
{
loadStoreTarget = _Color1,
loadAction = RenderBufferLoadAction.Clear, storeAction = RenderBufferStoreAction.Store,
clearColor = Color.cyan, clearDepth = 1, clearStencil = 0,
},
new AttachmentDescriptor(GraphicsFormat.R8G8B8A8_UNorm)
{
loadStoreTarget = _Color2,
loadAction = RenderBufferLoadAction.Clear, storeAction = RenderBufferStoreAction.Store,
clearColor = Color.magenta, clearDepth = 1, clearStencil = 0,
},
}).ToNativeArray(Allocator.Temp);
using (context.BeginScopedRenderPass(camera.pixelWidth, camera.pixelHeight, 1, attachments, 0))
{
Span<int> colorsOnStack = stackalloc int[0];
switch (m_Asset.TargetsAndOutputsCount)
{
case TargetsAndOutputsCountMode.SomeCount:
colorsOnStack = stackalloc[] { 1, 2, 3};
Shader.SetKeyword(m_EnableMrtKeyword, true);
break;
case TargetsAndOutputsCountMode.TargetsIsFewThanOutputs:
colorsOnStack = stackalloc[] { 1, };
Shader.SetKeyword(m_EnableMrtKeyword, true);
break;
case TargetsAndOutputsCountMode.OutputsIsFewThanTargets:
colorsOnStack = stackalloc[] { 1, 2, 3};
Shader.SetKeyword(m_EnableMrtKeyword, false);
break;
}
using var colors = colorsOnStack.ToNativeArray(Allocator.Temp);
using (context.BeginScopedSubPass(colors))
{
using (var cmd = new CommandsScope(context)) { m_DrawSampler.Begin(cmd.Cmd); }
context.DrawRenderers(cullResults, ref drawSettings, ref filterSettings);
using (var cmd = new CommandsScope(context)) { m_DrawSampler.End(cmd.Cmd); }
}
}
// FinalBlit
using (var cmd = new CommandsScope(context))
using (new ProfilingScope(cmd.Cmd, m_FinalBlitSampler))
{
if(camera.cameraType is CameraType.Game)
{
cmd.Cmd.SetRenderTarget(RenderTargetHandle.CameraTarget.Identifier());
cmd.Cmd.SetGlobalTexture("_MainTex", _Color0);
cmd.Cmd.DrawMesh(m_Mesh, Matrix4x4.TRS(new Vector3(-0.5f, +0.5f, 0), Quaternion.identity, Vector3.one * 0.5f), m_Material);
cmd.Cmd.SetGlobalTexture("_MainTex", _Color1);
cmd.Cmd.DrawMesh(m_Mesh, Matrix4x4.TRS(new Vector3(+0.5f, +0.5f, 0), Quaternion.identity, Vector3.one * 0.5f), m_Material);
cmd.Cmd.SetGlobalTexture("_MainTex", _Color2);
cmd.Cmd.DrawMesh(m_Mesh, Matrix4x4.TRS(new Vector3(-0.5f, -0.5f, 0), Quaternion.identity, Vector3.one * 0.5f), m_Material);
cmd.Cmd.SetGlobalTexture("_MainTex", _Depth);
cmd.Cmd.DrawMesh(m_Mesh, Matrix4x4.TRS(new Vector3(+0.5f, -0.5f, 0), Quaternion.identity, Vector3.one * 0.5f), m_Material);
}
else
{
cmd.Cmd.Blit(_Color0, RenderTargetHandle.CameraTarget.Identifier());
}
}
// Free
using (var cmd = new CommandsScope(context))
{
cmd.Cmd.ReleaseTemporaryRT(_Depth);
cmd.Cmd.ReleaseTemporaryRT(_Color0);
cmd.Cmd.ReleaseTemporaryRT(_Color1);
cmd.Cmd.ReleaseTemporaryRT(_Color2);
cmd.Cmd.SetRenderTarget(RenderTargetHandle.CameraTarget.Identifier());
}
}
一方のShader側は以下のように、PixelShaderの出力としてSV_Target0~SV_Target2の3つを出力します。わかりやすいように、それぞれ色を変えて出力しています。
class Target
{
half4 color0 : SV_Target0;
#if defined(ENABLE_MRT)
half4 color1 : SV_Target1;
half4 color2 : SV_Target2;
#endif
};
void frag(float4 vertex : SV_Position, float2 uv : TEXCOORD0, half4 color : COLOR, out Target target)
{
half3 tex = _MainTex.Sample(sampler_MainTex, uv).rgb * color.rgb * _Color.rgb;
target.color0 = half4(tex, color.a * _Color.a);
#if defined(ENABLE_MRT)
target.color1 = half4(1 - tex, color.a * _Color.a);
target.color2 = half4((tex.r + tex.g + tex.b).xxx / 3, color.a * _Color.a);
#endif
}
そもそも出来るのか、省略した場合どんな挙動になるのか
結論から言えば、どちらも「可能」でした。
ただし、ドキュメントに明示的な記述を見つけることはできなかったので、少しモヤっとする感じです。SRV(テクスチャ)なども余分にバインドされていても無視されるだけですから、当たり前のことなのかなという気もします。
RTが1枚、SV_Targetが0,1,2の場合(RTs < SV_Targets)
対応するRTが設定されていなかった出力(SV_Target)は無視されます。
また、これはおそらくUnity特有の挙動ですが、SubPassで使われなかったAttachmentはRenderPassに指定していてもVulkanAPIレベルではなかったことにされてしまうようです。そのため、colorsにBindしなかったRT1とRT2はLoadActionのClear色すら反映されていません。
// TODO: VulkanAPIを直接叩いた場合の挙動も確認

RTが3枚、SV_Targetが0だけの場合(RTs > SV_Targets)
SV_Targetが無かったインデックスのRTには何も描画されず、LoadActionでClearしたままの状態になっています。

オーバーヘッドについて
ZTestを無効にした状態(オーバードロー)でチェッカーテクスチャを貼ったQuadを描画しました。環境はSH-M09(Adreno630)で、解像度が2280x1080なので、1Quad当たり、1000x1000Pixel程度の描画になります。グラフでは左から、RTs = SV_Targets、RTs > SV_Targets、RTs < SV_Targetsの順です。
-
60個のQuadを描画した場合(約60Mpx)
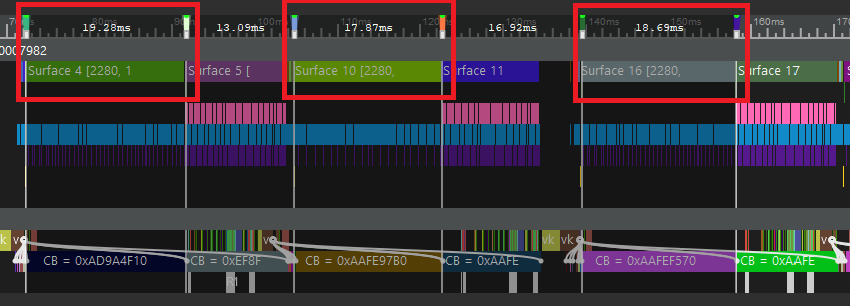
-
1個のQuadを描画した場合(約1Mpx)

RTs = SV_Targets |
RTs < SV_Targetss |
RTs > SV_Targets |
|
|---|---|---|---|
| 60Quad($Q_{60}$) | 19.3 ms | 17.8 ms | 18.7 ms |
| 1Quad($Q_1$) | 3.0 ms | 1.7 ms | 3.0 ms |
| 賞味の1Quad($Q=\frac{Q_{60}-Q_1}{59}$) | 0.276 ms | 0.273 ms | 0.266 ms |
| StoreOverhead($S=Q_1-Q$) | 2.724 ms | 1.427 ms | 2.734 ms |
| 1byte当たりのStoreOverhead($s=\frac{S}{B}$) | 0.170 ms | 0.178 ms | 0.171 ms |
| 1px当たりのRTsのbyte数($B$) | 16 byte | 8 byte | 16 byte |
RTs < SV_Targetssがやや軽く、他2つがほぼ同じぐらいとなりました。
ここで、内部的に以下のような処理がされていることが想像できます。
- PixelShader内で計算をして
SV_Targetのレジスタに書き込むまで(X) -
SV_TargetのレジスタからGMEMにコピーする(Y) - GMEMからRTにStoreする(Z)
RTs = SV_TargetsとRTs < SV_Targetssに関しては、そもそも同じShaderプログラムが実行されるわけです。RTs > SV_Targetsも単純な加減乗除と高速なレジスタへの書き込みの有無の差にすぎませんので、Xの処理はほとんど変わらないと予想できます。また、Zの処理に関しては、1px当たりのRTsのbyte数に比例すると予想できます。
問題はYの処理ですが、これが非常に小さいと仮定して$Q$、$s$を計算すると、どちらもほぼ一定で前述の予想と整合性が取れます。
「RTとSV_Targetの数が異なっていても余分なオーバーヘッド(Yの処理)は無視できるほど小さい」という結論を、この実験を以て断定するまではできないかもしれませんが、実用レベルではほぼ問題としなくて良さそうです。
応用する際の注意点
先述に「特定のShaderで描かれたピクセルのみを記録しておきたい場合(StencilBufferのような用途)」を挙げました。このケースについて考えてみます。特定のShaderではSV_Target1を出力し、それ以外のShaderでは出力しないようにします。
まず、計算結果の整合性としてはSV_Target1のないShaderを実行しても、何も描かれないだけですので問題ないと考えられます。オーバーヘッドについても特定外のShaderではSV_Target1のための計算は含まれていないはずですから、X、Yの処理のオーバーヘッドは無視できます。問題はZの処理(RTのStore)のオーバーヘッドです。特定Shaderを1枚も描画しなかった場合、完全に無駄なRTをStoreする羽目になってしまいます。
一例ではありますが、SH-M09の場合だと、1chのRTで0.18msという無視できるようなできないようなレベルなので、0.1msでも節約したい場合はCPU側で余分なRTをBindするか否の分岐が必要かもしれません。或いは、RenderPassの最後で圧縮したり、他のRTに反映と合成してGMEMに閉じ込めて最終的なStore量を減らしてしまうという戦略もあり得ると思います。
コード全文