Splunkのサーチバーで使うコマンドが自作できる(Splunkでは自作したコマンドを「カスタムサーチコマンド」と呼ぶらしい)と聞いたので試してみました。なお、この投稿はUbuntu18.04で検証していますので、他のOSの場合は作成方法が違うかもしれませんのでご了承ください。
カスタムサーチコマンドを登録する
プログラムを作成する前にまず登録を行います。登録するには、/opt/splunk/etc/apps/search/local/commands.confに以下のような文を追加します。
Splunkの初回インストールの直後は、/opt/splunk/etc/apps/search/配下にlocalフォルダすらないので、localフォルダを作成しcommands.confも新規作成します。
[hoge]
filename = test.py
streaming = true
[ ]で囲まれた中の文字がサーチバーで記載するカスタムサーチコマンド名になり、このコマンドが呼び出されるとfilename =で書かれているプログラム名を実行します。なお、今回はストリーミングモードで使用するコマンドを作成するので、streaming = trueを設定します。(他のモードは、また別に投稿します)
カスタムサーチコマンドの本体の作成
プログラムの本体は/opt/splunk/etc/apps/search/bin/のフォルダに作成します。プログラム名はcommands.confに記入したプログラム名test.pyと同じにします。今回作ったプログラムは、前のSPLの出力結果を受け取り、その結果をファイルtest.datに文字列として出力して、結果を変えずにそのまま次のSPLに渡すものとなっています。
import splunk.Intersplunk
data,dummy1,dummy2 = splunk.Intersplunk.getOrganizedResults(input_str=None)
with open('test.dat','w') as f:
f.write(str(data))
splunk.Intersplunk.outputResults(data)
3行目のsplunk.Intersplunk.getOrganizedResultsが前のSPLの結果を受け取る部分で、6行目のsplunk.Intersplunk.outputResultsが次のSPLに結果を送っている部分です。
プログラムの作成が完了したらSplunkを再起動します。test.pyは再起動しなくても変更が反映されますが、commands.confは再起動しないと変更が反映されません。
検証データを準備する
以下のような3件のデータを作成しました。これをパイプでカスタムサーチコマンドに渡して、どのようなデータ構造として受け取れるのか検証します。
"time","number","value"
"2020/01/01 12:00:00","1","a"
"2020/01/01 12:00:00","2","b"
"2020/01/01 12:00:00","3","c"
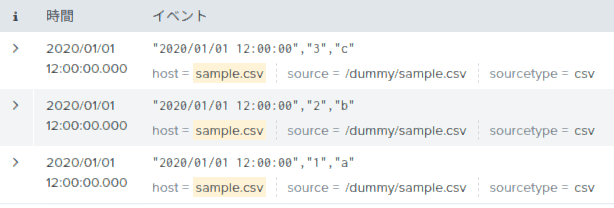
プログラムの実行
下のSPLを実行します。
host = sample.csv | hoge
実行後にtest.pyと同じフォルダにtest.datが作成されたと思います。内容を見ると、下のように、3つの辞書(正確にはsplunk.util.OrderedDictというクラス)が入ったリストを見ることができます。各辞書は検証データの1件に対応し、辞書のキーと値はフィールドとその値に対応していることがわかります。これらを書き換えれば、次のSPLへ好きな結果を送ることができそうです。
[
{'_cd': '0:15', 'date_minute': '0', 'source': '/dummy/sample.csv', 'date_year': '2020', 'splunk_server_group': '', '_sourcetype': 'csv', 'date_wday': 'wednesday', 'number': '3', 'eventtype': '', 'value': 'c', '_eventtype_color': '', 'date_hour': '12', '_time': '1577847600', 'date_second': '0', 'date_zone': 'local', 'linecount': '1', '_serial': '0', 'time': '2020/01/01 12:00:00', 'timeendpos': '20', '_indextime': '1585398968', 'splunk_server': 'dummy', 'date_mday': '1', '_bkt': 'main~0~38327377-7FDC-4E8B-B00E-61AA849FBF3E', '_raw': '"2020/01/01 12:00:00","3","c"', 'host': 'sample.csv', 'date_month': 'january', 'sourcetype': 'csv', 'punct': '"//_::","",""', 'timestartpos': '1', 'index': 'main', '_si': 'dummy\nmain'},
{'_cd': '0:12', 'date_minute': '0', 'source': '/dummy/sample.csv', 'date_year': '2020', 'splunk_server_group': '', '_sourcetype': 'csv', 'date_wday': 'wednesday', 'number': '2', 'eventtype': '', 'value': 'b', '_eventtype_color': '', 'date_hour': '12', '_time': '1577847600', 'date_second': '0', 'date_zone': 'local', 'linecount': '1', '_serial': '1', 'time': '2020/01/01 12:00:00', 'timeendpos': '20', '_indextime': '1585398968', 'splunk_server': 'dummy', 'date_mday': '1', '_bkt': 'main~0~38327377-7FDC-4E8B-B00E-61AA849FBF3E', '_raw': '"2020/01/01 12:00:00","2","b"', 'host': 'sample.csv', 'date_month': 'january', 'sourcetype': 'csv', 'punct': '"//_::","",""', 'timestartpos': '1', 'index': 'main', '_si': 'dummy\nmain'},
{'_cd': '0:9', 'date_minute': '0', 'source': '/dummy/sample.csv', 'date_year': '2020', 'splunk_server_group': '', '_sourcetype': 'csv', 'date_wday': 'wednesday', 'number': '1', 'eventtype': '', 'value': 'a', '_eventtype_color': '', 'date_hour': '12', '_time': '1577847600', 'date_second': '0', 'date_zone': 'local', 'linecount': '1', '_serial': '2', 'time': '2020/01/01 12:00:00', 'timeendpos': '20', '_indextime': '1585398968', 'splunk_server': 'dummy', 'date_mday': '1', '_bkt': 'main~0~38327377-7FDC-4E8B-B00E-61AA849FBF3E', '_raw': '"2020/01/01 12:00:00","1","a"', 'host': 'sample.csv', 'date_month': 'january', 'sourcetype': 'csv', 'punct': '"//_::","",""', 'timestartpos': '1', 'index': 'main', '_si': 'dummy\nmain'}
]
新しいフィールドを追加する機能を付ける
実際に辞書を操作して新しいフィールドを作成してみます。先程のtest.pyを下のように書き換えます。これは、フィールドnumberの数値を取り出して1を加え、新たなフィールドnew_fieldの値として入れています。
import splunk.Intersplunk
data,dummy1,dummy2 = splunk.Intersplunk.getOrganizedResults(input_str=None)
for tmp in data:
tmp['new_field'] = int(tmp['number']) + 1
splunk.Intersplunk.outputResults(data)
動作確認のために、下のSPLを実行します。
host = sample.csv | hoge | table number new_field

新しいフィールドが追加されていることが確認できました。
ストリーミングモードについて
ストリーミングモードでは、前のSPLの結果を50件くらいに小分けして受け取っているようです。つまり、プログラムを起動し最初の50件を処理し終了したら、またプログラムを起動し次の50件を処理し終了する・・・を繰り返しているようです。
おわりに
今回は初歩的なカスタムサーチコマンドを作成することを目的としました。次回はカスタムサーチコマンドのパラメータ受け取りやエラー表示などについて記載していきたいと思います。
動作環境
Ubuntu 18.04.4 LTS
Splunk 8.0.2.1