前職の業務で英語の文章の翻訳を行っておりました。
送られてくるデータがjpegだった場合、写真の文章を目視で手入力しており大変苦労しました。
そこで
GoogleCloud
GoogleVisonAPI(画像認識)
GoogleTranslationAPI(翻訳)
Python
を用いて文字起こしと翻訳を自動で実行行うプログラムを作成しました。
コードと実行結果を共有しますので是非使ってみて下さい。
今回のコードでは文字起こしした翻訳データを
スプレッドシートに保存するため
GoogleCloudの
GoogleDriveAPI
も使っています。
できること:
写真またはpdfから文字を起こす
起こした文字を翻訳する
翻訳したデータをスプレッドシートに貼り付ける
import os
import pandas as pd
from PIL import Image
from google.cloud import vision
from googletrans import Translator
from pdf2image import convert_from_path
import pytesseract
from oauth2client.service_account import ServiceAccountCredentials
import gspread
import gspread_dataframe as gd
# Google Spreadsheetsに接続
scope = ['https://spreadsheets.google.com/feeds',
'https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name('ディレクトリ', scope)
gc = gspread.authorize(credentials)
# 新規スプレッドシートを作成
spreadsheet = gc.create('翻訳')
spreadsheet.share('googleメールアドレス', perm_type='user', role='writer') # 自分のメールアドレスに置き換えてください
def detect_text(path):
"""Detects text in the file based on its extension."""
_, ext = os.path.splitext(path)
if ext in ['.png', '.jpg', '.jpeg']:
return detect_text_from_image(path)
elif ext == '.pdf':
return detect_text_from_pdf(path)
else:
return ''
def detect_text_from_image(path):
"""Detects text in the image file."""
client = vision.ImageAnnotatorClient()
with open(path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
return texts[0].description if texts else ''
def detect_text_from_pdf(path):
"""Extracts text from the PDF file using OCR."""
# Convert the PDF to images
images = convert_from_path(path)
# Use OCR to extract text from each image
text = ''
for img in images:
text += pytesseract.image_to_string(img)
return text
# 指定したフォルダ内のすべてのファイルのパスを取得
dir_path = "/Users/XXX/Desktop/OCR/photo"
files = [os.path.join(dir_path, f) for f in os.listdir(dir_path) if f.endswith(('.png', '.jpg', '.jpeg', '.pdf'))]
# 各ファイルのテキストを検出し、その結果をテキストファイルに書き出す
translator = Translator()
data = []
for file_path in files:
text = detect_text(file_path)
if text:
# 全体のテキストを翻訳
detected_lang = translator.detect(text).lang
if detected_lang == 'ja':
translated_text = translator.translate(text, dest='en').text
else:
translated_text = translator.translate(text, dest='ja').text
# テキストと翻訳されたテキストを段落ごとに分割
text_paragraphs = text.split('\n')
translated_paragraphs = translated_text.split('\n')
# 各段落の原文と翻訳文をdataに追加
for original, translated in zip(text_paragraphs, translated_paragraphs):
if original and translated: # 空の段落を無視する
if detected_lang == 'ja':
data.append([translated, original]) # 英訳結果と原文(日本語)
else:
data.append([original, translated]) # 原文(英語)と日本訳結果
# DataFrameに変換
df = pd.DataFrame(data, columns=['English', 'Japanese'])
# Google Spreadsheetに書き込み
gd.set_with_dataframe(spreadsheet.sheet1, df)
# DataFrameに変換
df = pd.DataFrame(data, columns=['English', 'Japanese'])
# Google Spreadsheetに書き込み
gd.set_with_dataframe(spreadsheet.sheet1, df)
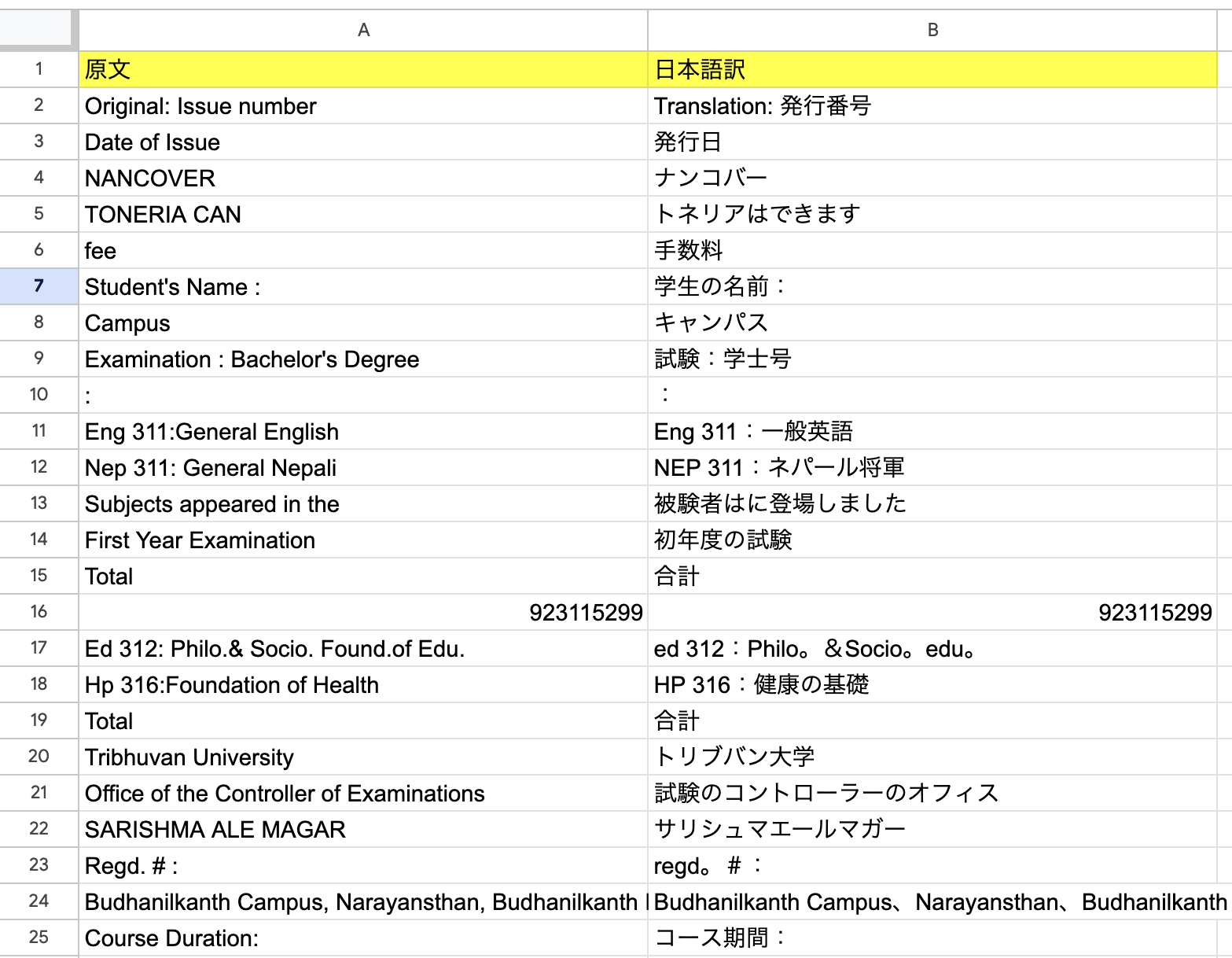
実行結果