ECCV2016の論文
https://arxiv.org/pdf/1603.07057.pdf
モチベーション
・Face Recognitionにおいて、少ない学習データ枚数でそれなりの精度を出したい
・Googleの提案モデルが200M枚,Facebookが4.4M枚の顔画像で学習させているが,この論文では495K枚程度のデータセット(CASIA WebFace)で、同じくらいの精度を出したい
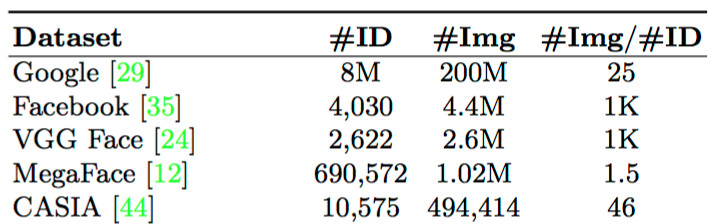
(a) Face set statistics
手法
・一枚の顔写真から、顔の多様なPose,Shape,Expressionをシミュレートできるようなモデルをつかって、データ数を増やした(詳しくは載ってなかった)
・Pose
顔の角度を{0◦, ±40◦, ±75◦}の範囲でシミュレート

・Shape
色んな顔の形(?)を既存の3Dモデルでシミュレート
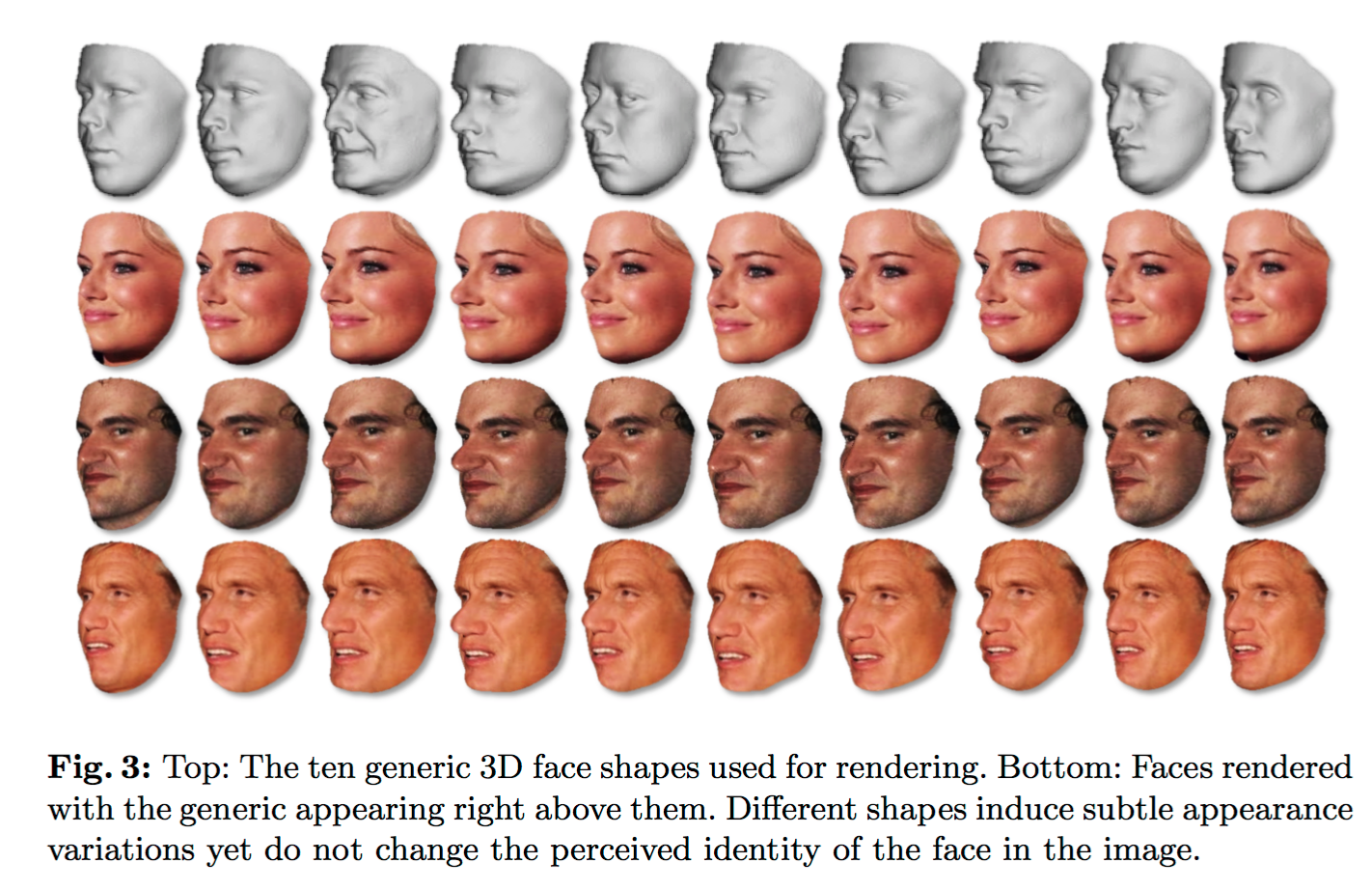
・Expression
口を閉じたり、開けたり、笑顔にしたりをシミュレート

結果
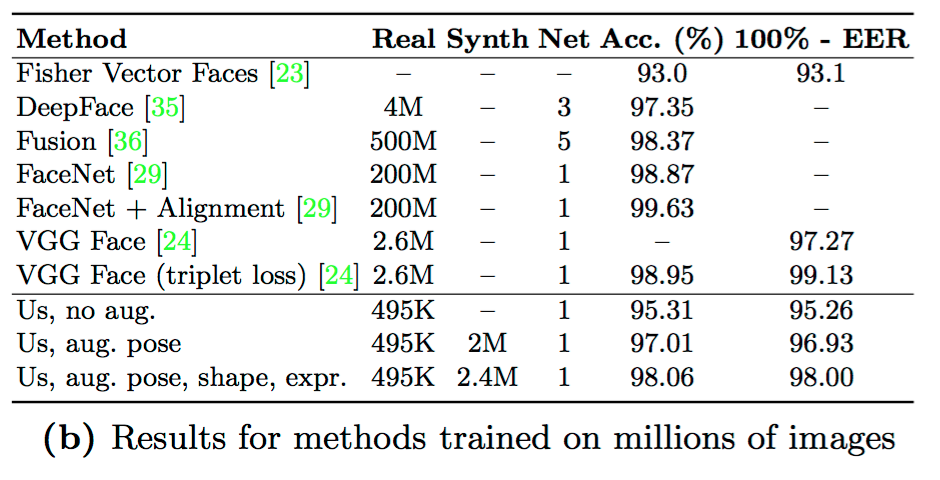
・学習データ枚数が495Kから2.4Mになって、LFWにおけるAccuracyも95.31%から98.06%くらいになった (Googleの99.63%には勝てなかった)
感想
・Google、Facebookのデータ数で同じことするとどうなるんだろう