「機械学習でどのアルゴリズムを使ったらいいの?」と迷った場合用のカタログです。
・アルゴリズムのざっくりとした3行イメージ
・メリット&デメリットおよび使用場面
この2点に特化して機械学習のアルゴリズムをまとめています。
記事の内容
- 教師あり学習のアルゴリズム
- 教師なし学習のアルゴリズム
- Neural Networkのアルゴリズム
教師あり学習のアルゴリズム
教師あり学習の分類問題に使用するアルゴリズムを中心に取り上げます。
「教師あり学習って何?」という方はこちらをご覧ください。
1. Random Forest
【3行で伝えるざっくりイメージ】
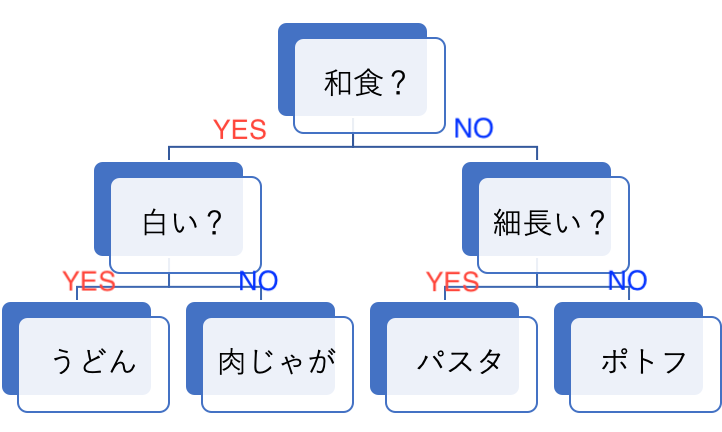
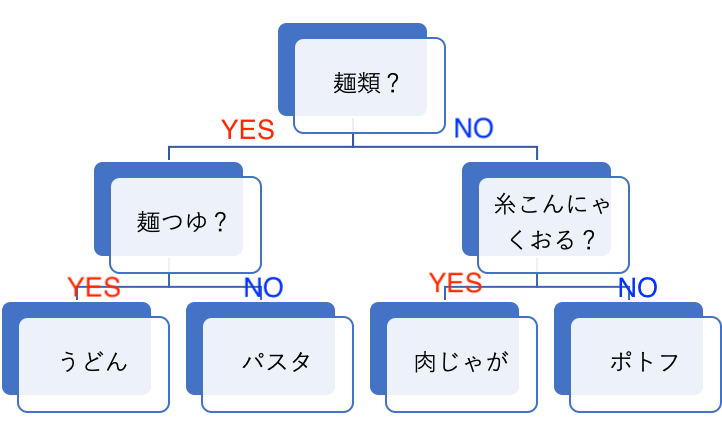
「YES」か「NO」かで分岐していくことで最終的に一つの答えにたどり着く構造を「木」といいます。
複数の説明変数からランダムでいくつかを選び、それらを分岐の質問に用いる「木」を作ります。
この方法で「木」を大量に作り、それぞれの出力結果のうち最も個数が多いものを正解とします。
(※分類問題ではなく回帰問題の場合、各木の出力結果の平均値をとります。)
【メリット】
- 説明変数が多くても大丈夫!
- 分類問題にも回帰問題にも使える。
- 結果を見て人間が説明しやすい
【デメリット】
- 説明変数のうち、意味のないものが多いときは向かない
- 計算時間がやや長い
【使用場面】
- 教師あり学習の回帰問題と分類問題に幅広く使える。
- 特に、データ量や説明変数の多いものを得意とする。
2. Naive Bayes
【3行で伝えるざっくりイメージ】
ある出来事が起こったときに、「原因がこれだ!」と推定できる確率を求めるための定理に「ベイズの定理」というものがあります。
Naive Bayesは、この「ベイズの定理」を応用したアルゴリズムで、分類問題に使われます。
説明変数の値から目的変数ごとの「起こる確率」を計算して、最も確率が高いと判断したものを正解とします。

【メリット】
- 実装が簡単で性能も良い
- 計算が高速
- 重要でない説明変数が多くても影響を受けない
- 超巨大なデータに対しても使える
【デメリット】
- 説明変数同士に相関関係がある場合、成り立たないことがある
【使用場面】
- 教師あり学習の分類問題に使用する。
- 高速で超巨大なデータを扱う場合には、特に有効。
- 具体的には、交通量や株価などのリアルタイム予測や、文書データの分類に使われることが多い。
3. SVM
【3行で伝えるざっくりイメージ】
SVMはサポートベクターマシンの略称で、教師ありの分類問題に使われます。
データを散布図にプロットし、境界となる線を引くのがSVMの基本的なイメージになります。
直線で分離できるものを線形SVM、曲線でないと分離できないものをカーネルSVMといいます。

【メリット】
- 過学習が起こりにくい
- 特に2クラスの分類が得意
- 実装が簡単で、精度が高い
【デメリット】
- データ量が多いと計算に時間がかかる
- 他クラス分類の場合、手間がかかる
【使用場面】
- 教師あり学習の分類問題に使用する。
- 2クラス分類で高精度なので特に使われる。
4. ロジスティック回帰
【3行で伝えるざっくりイメージ】
ロジスティック回帰は「回帰」という言葉がついていますが、教師ありの分類問題に使われるアルゴリズムです。
目的変数と説明変数の関係を式で表す「回帰」の考え方を用いて、ある事象が発生する確率を計算します。
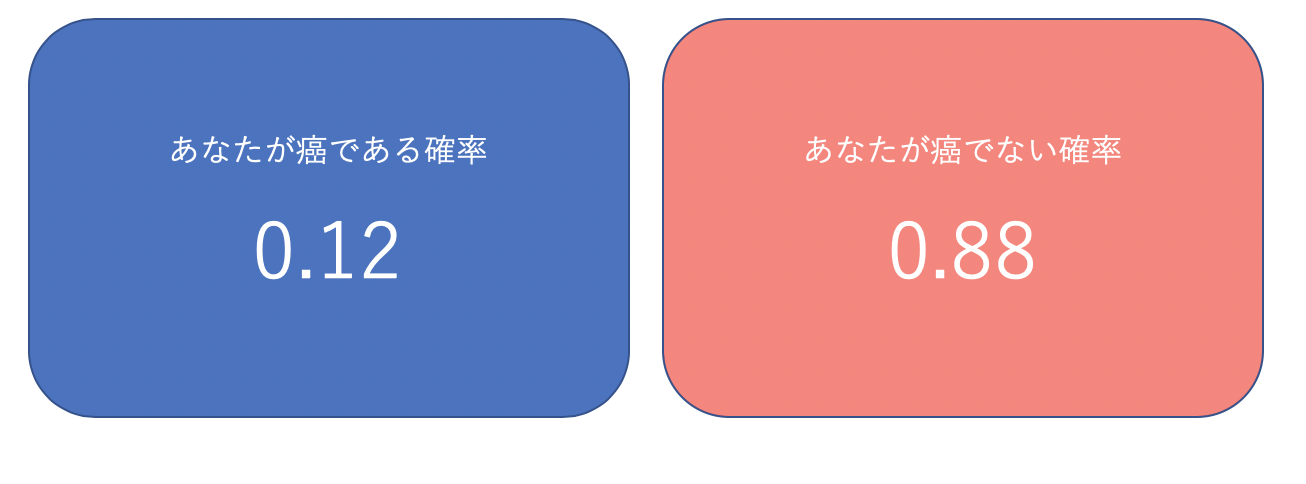
病気の診断など「YES / NO」で答えられる質問に対し「YES」の確率を計算し、例えば50%以上だと病気だと診断する、といった流れのイメージになります。
【メリット】
- 判定に至る確率がわかるので、人間が見てわかりやすい
- 実装が簡単で精度が高い
【デメリット】
- 多クラス分類に応用できないわけではないが、手間がかかる
【使用場面】
- 基本的には2クラスの分類問題に用いる。
- 「Aである確率」確率をもとに「Aであるか否か」を判断するのに使われる。
- 例えば、「患者が癌かどうか」というようなYes/Noの分類問題に有効である。
教師なし学習のアルゴリズム
教師なし学習のクラスタリングに使用するアルゴリズムを中心に取り上げます。
「教師なし学習、クラスタリングって何?」という方はこちらをご覧ください。
k-means
【3行で伝えるざっくりイメージ】
k-meansはサンプル数が大きいビッグデータのクラスタリングに用いる手法です。
あらかじめ分けるクラスターの数を決めた上で、その数の塊にデータを分けるアルゴリズムです。
クラスターの数だけランダムに点をとり、最も近い点ごとにクラスターを分けるという作業を繰り返していきます。
k-meansの仕組みは比較的理解が簡単なので、気になる方はこちらの記事をご覧ください

【メリット】
- 階層型クラスタリングのアルゴリズムに比べて、計算が速い。
- データ量が増えても対応できる。
【デメリット】
- 最適なクラスター数を人間が探す必要がある。
- 代表点の選び方によって結果が変わってしまうこともある。
【使用場面】
- 教師なし学習の非階層型クラスタリングに使われる。
- コメントなどの曖昧性の高いデータや莫大な量のデータのクラスタリングで使用。
Neural Networkのアルゴリズム
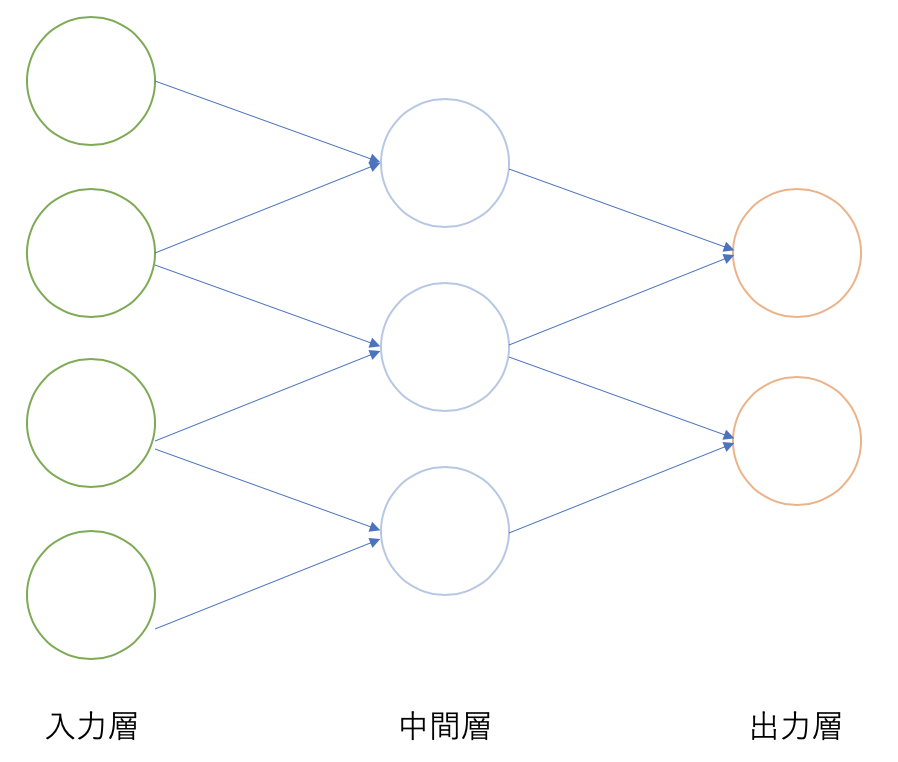
下の図のように、2つの入力に対して計算を行って、1つの出力を得る構造をパーセプトロンといいます。
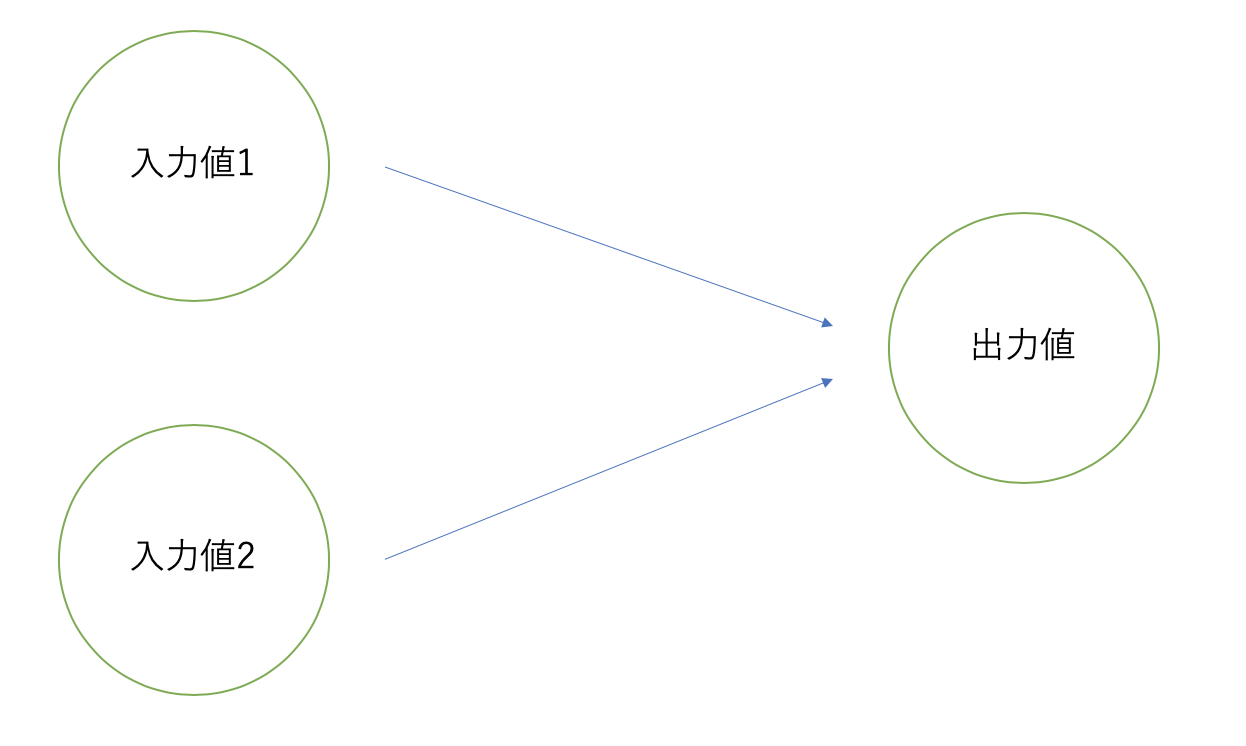
パーセプトロンをいくつも組み合わせて、人間の脳のように一つの回路を構成したアルゴリズムを総称してNeural Networkといいます。
Neural Networkにも様々なアルゴリズムがあり、教師ありの分類問題や回帰問題を中心に様々な場面で使用されます。
1. CNN
【3行で伝えるざっくりイメージ】
**CNN(Convolutional Neural Network)**は、画像の処理に用いられるNeural Networkです。
画像データの箇所ごとのおおまかな特徴を掴むために、次のパーセプトロンに進む際に「畳み込み」と「プーリング」という処理を行います。
「畳み込み」では画像を正方形のフィルタごとに見ることで特徴を際立たせ、「プーリング」で重要な情報以外をノイズカットします。
 (画像は[https://kenyu-life.com/]()様より引用)
(画像は[https://kenyu-life.com/]()様より引用)
【メリット】
- 畳み込みで圧縮することで計算コストが抑えられる
- 画像の識別に関して高精度
【デメリット】
- 判別の理由を説明するのが難しい
【使用場面】
- 主に画像の処理に使われる。
- 画像の教師あり分類問題や、画像を使った顔認証などで有効。
2. RNN
【3行で伝えるざっくりイメージ】
**RNN(Recursive Neural Network)**は、言語や時系列データなど前後のつながりが重要なデータの分析に使われます。
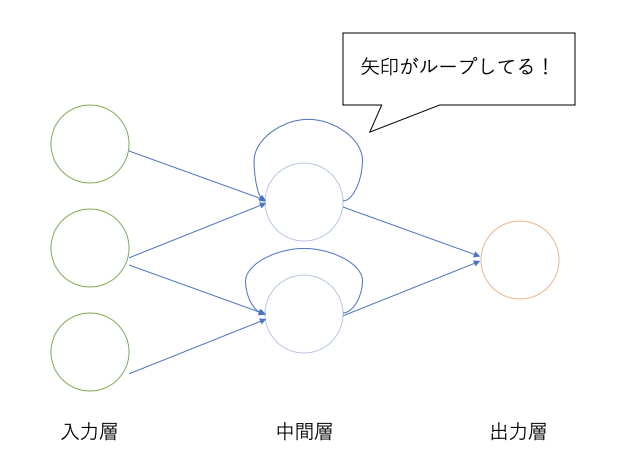
通常パーセプトロンを通過した計算結果は次の層に進み、出力層へと一方向に向かっていきます。
一方RNNでは計算結果は次の層に進むとともに、通過層のパーセプトロンに再び戻って次の計算結果に影響を与えます。
「ある時点の入力が、それ以降の出力に影響を及ぼす」特徴を持ったNeural Networkだと認識してください。
【メリット】
- データごとのつながりや前後の文脈も反映できる。
【デメリット】
- 判別の理由を説明するのが難しい
【使用場面】
- 連続性のあるデータの分析や予測に使われる。
- 前後の文脈を重視する自然言語処理で有効。
- 株価などの時系列データの分析にも使用される。
3. Deep Learning
【3行で伝えるざっくりイメージ】
最近よくきくDeep Learningという言葉ですが、実はNeural Networkとほとんど同じ意味です。
Neural Networkのうち、経由するパーセプトロンの層が3層以上のものをDeep Learningと呼んでいます。
そのため、3層以上であればCNNもRNNに分類されます。
Deep Learningはアルゴリズムというよりは「呼称」という認識に近いかもしれません。