はじめに
CloudFrontが何かなどについては、あまり詳しく書きませんが、今回はCDNやキャッシュサーバのようなものという認識だけしていただければ、大丈夫です。
今回はCloudFrontでキャッシュを効かせるに当たって困ったこと、工夫したことをCloudFrontの仕組みから記事できればと思っています。
読んでほしい人
- CloudFrontを使い始めたばかりの人
- CloudFrontを使っているのにキャッシュがうまく効かないと感じている人
- これから、CloudFrontを使ってシステムを構築しようと思っている人
背景
CloudFrontを使えば、キャッシュが効くから大量のファイル配信も余裕と思って仕組みを気にせずに、S3とCloudFrontでファイル配信システムを組んだら、大量の500エラーが出てしまいました。よく仕組みを見ずにCloudFrontを前段に置けばキャッシュが効くと思っていたら、そうでなかったので起きたことと対策をまとめてみました。
CloudFrontの仕組み
CloudFrontはエッジロケーション、リージョン別エッジキャッシュ、オリジンシールド(デフォルトでは使われない)という3層でキャッシュされており、エッジロケーション、リージョン別エッジキャッシュ、オリジンシールド、オリジンの順でキャッシュがない場合にはより上位の層にアクセスしファイルを取得する仕組みになっています。そして、同じエッジロケーションにアクセスがあった場合はエッジロケーションがキャッシュしたファイルを返答、最初のアクセスの場合はリージョン別エッジキャッシュに問い合わせ、リージョン別エッジキャッシュにキャッシュがあった場合はリージョン別エッジキャッシュがファイルを返答、ない場合はさらに上位に問い合わせを繰り返します。こうすることで一度ファイルが取得された、エッジロケーションではキャッシュが効きが応答が早くなり、アクセスが各エッジロケーションに分散することでオリジンの負荷を減らすことができます。
どのエッジロケーションに振り分けられるかは、その時のアクセス元からCloudFrontが自動で適切なエッジロケーションを判断して決めます。
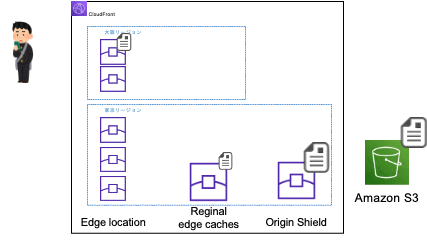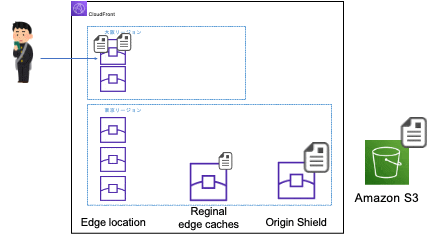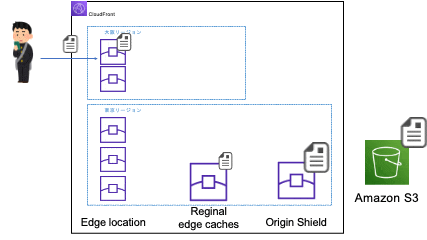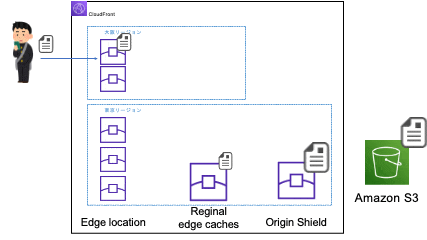
文章だけではイメージが湧きづらいと思ったので、簡単なイメージを作りました。
- 初回アクセス時
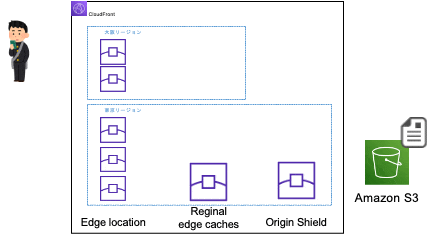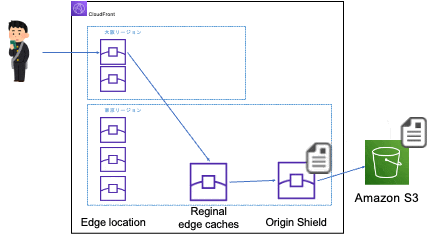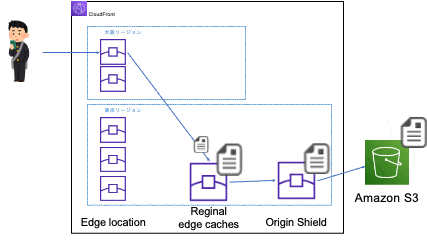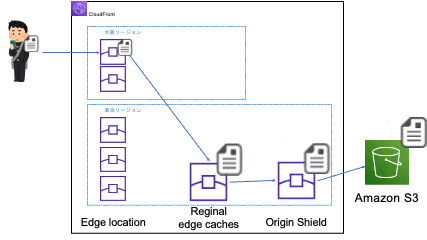
-
同じ場所で次にアクセスした時(同じエッジロケーションに振り分けられる時)
-
別のエッジロケーションに振り分けられる場合
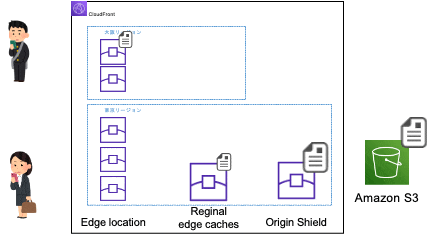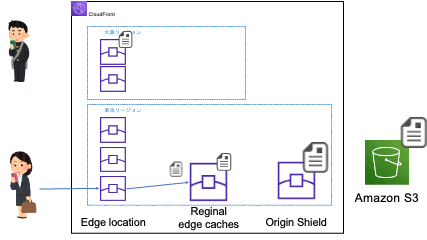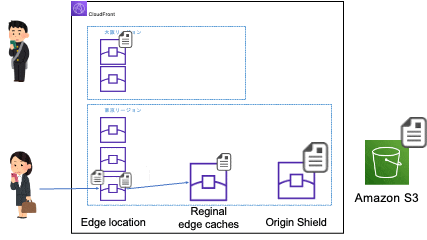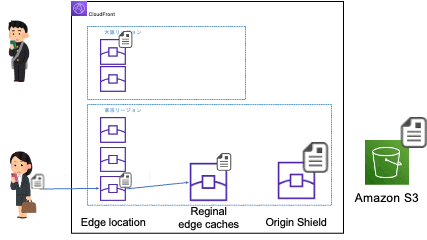
※大阪リージョンのエッジロケーションのアクセスが東京リージョンのリージョン別エッジキャッシュにアクセスするのは、大阪リージョンにはリージョン別エッジキャッシュがないためです。リージョン別エッジキャッシュのないリージョンのエッジロケーションはネットワーク的に一番近くのリージョン別エッジキャッシュにアクセスします。
途中でリクエストがキャンセルした場合のCloudFrontの仕様について
ここでは私が詰まった仕様について解説します。
CloudFrontはリクエストが正常に完了した場合にのみ、キャッシュをします。
今回、私が作っていたシステムは、クライアントの都合でファイルDLが中断する(リクエストをキャンセルする)ことが高い確率であります。
その場合にhttpのRangeヘッダーを使ってダウンロード未完了の部分からダウンロード再開します。
この仕様だと当然ですがリクエストが正常に完了しないため、キャッシュされません。
しかも、様々な都合からクライアント側の改修は不可能という状態でした。
CloudFrontはRangeヘッダーを使った場合は指定された範囲がキャッシュがされていない場合にオリジンに問い合わせます。
※ちなみにこういった場合、クライアントのリクエストのRangeヘッダーのダウンロード範囲を小さくし、一定のバイトまでダウンロードが完了するたびに200応答させ、リクエストを正常に終了させるのが良い実装です。なので、下記の対策でなくLambda@edgeでRangeヘッダーを書き換え対応するという方法もありますが、その場合のクライアント挙動がわからないので、今回下記の対策を取りました。
そもそも、httpのRangeヘッダーって何は下記のページなどを参照してください。
簡単に言ってしまえば、ファイルの何バイト目から何バイト目がほしいと指定できる仕組みです。
対策
クライアント改修が不可能である以上サーバ側で対応するしかありません。しかしCloudFront自体にはエッジロケーションなどに事前にキャッシュする機能はありません。
今回はオリジンにS3を使っているので、S3にファイルが追加されたことをトリガーにCloudFrontにhttp経由でアクセスし、ダウンロードすることで事前にキャッシュさせます。エッジローケーションは多数あるので、エッジローケーション単位で見るとあまり効果がありませんが、その後ろにはリージョン別エッジキャッシュ、オリジンシールドがあるので、オリジンの保護にはこの方法は有効です。
実装
S3にファイルがアップロードされたことをフックする方法は今回はLambdaを使って実装するので、LambdaのS3アップロードをトリガーにし、CloudFrontからhttp経由でファイルをダウンロードします。
httpでファイルをダウンロードするだけなので、言語はなんでもいいですが、pythonの場合はこんな感じです。
# -*- coding: utf-8 -*-
import urllib
import os
import requests
def lambda_handler(event, context):
file_download(event, context)
def file_download(event, context):
key = urllib.parse.unquote_plus((event['Records'][0]['s3']['object']['key'], encoding='utf-8')
url = "https://" + os.environ.get('CF_DOMAIN', '') + "/" + key
requests.get(url)
※ keyの部分はEventBridgeでフックする場合は下記のように変更してください。
key = urllib.parse.unquote_plus(event['detail']['object']['key'], encoding='utf-8')
環境変数名をCF_DOMAINにしてCloudFrontのドメインをLambdaに登録してください。
ちなみに、CloudFrontのドメインはCloudFrontから標準的に出されるドメインでなく、代替ドメイン名を設定する方が運用的には何かあった時に別のCloudFrontに変更しやすいなど、運用的に楽です。
まとめ
CloudFrontを利用する環境で、クライアントの都合でファイルDLが中断し、DL未完了部分から再開するという稀な環境でしか起きない現象ですが、起こるとなぜキャッシュが効いているはずなのに500系エラーが多発するのかわからず、意外とドツボにハマりました。AWSのサポートが比較的丁寧に状況を教えてくれたので、早く対策を立てることができました。せっかくサポート体制が充実しているクラウドサービスを使っているので、サポートは有効に使っていきたいと思いました。