概要
Fivetran, dbt, Snowflakeを使ってみた時のメモ。やりたいことは、Google Drive上のcsvやExcel、スプレッドシートをFivetranでSnowflakeにロードして、dbtで変換するという一連の流れの作成。手を動かす中での気付きや学びを書き殴っていく。結果的に作成した流れは以下の図の通り。
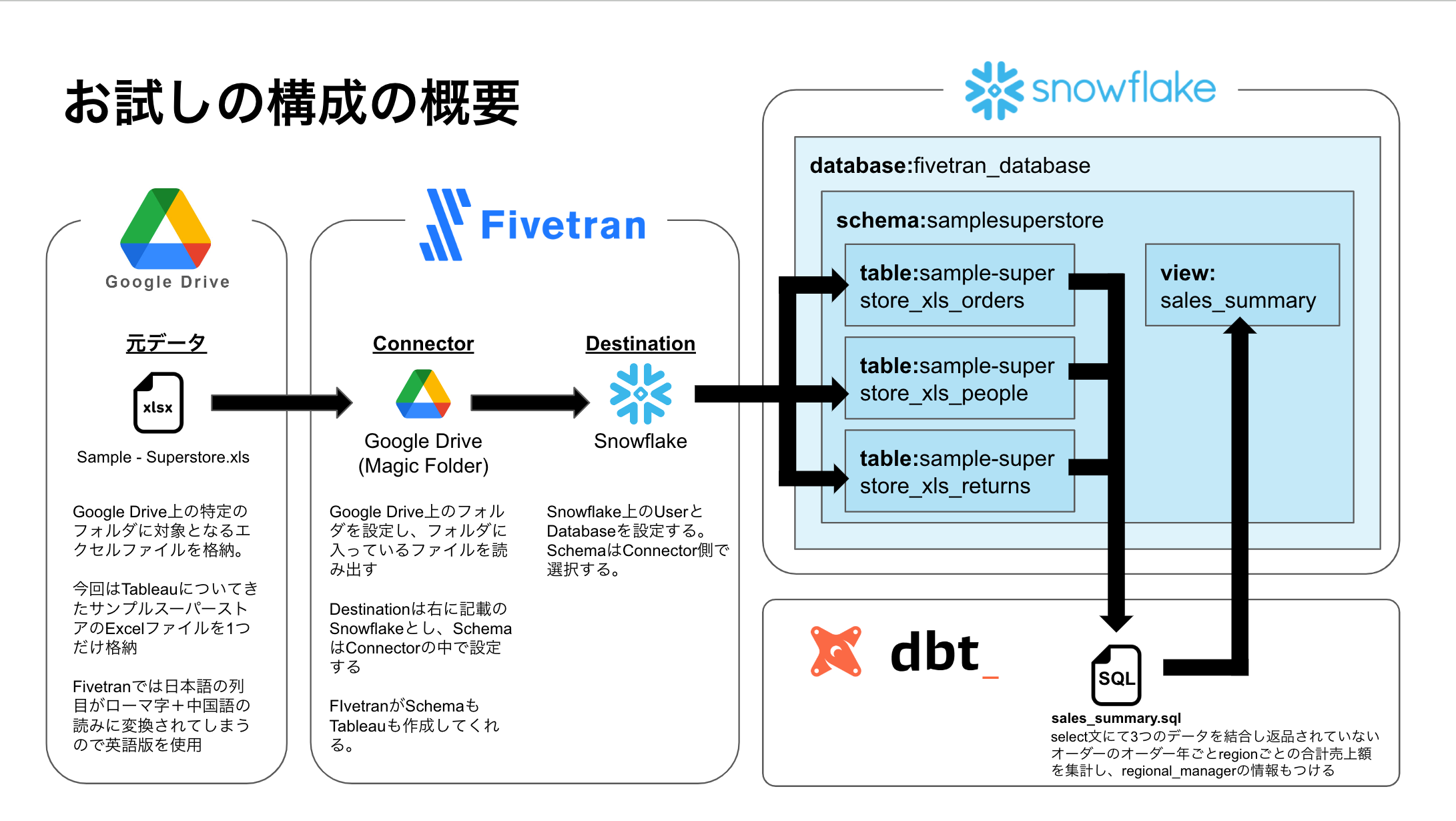
Snowflake
Snowflakeは1ヶ月トライアルの環境で実施。特に設定はいじっていない。
Fivetran
こちらはfree planで実施。50万MAR(Monthly Active Rows)を超えなければずっと無料で使えるとのこと。MARの概念は今は分かっていないけれど最初のロードの際はMARはカウントされないみたいなので今回のお試しの中ではMARは1つもカウントされなさそう。
Fivetranの構成としてはConnector, Destinationsの二つが基本な模様。Transformationの設定もあるが一旦触らないことにする。ELTのEとLだけやってもらう。Connectorでデータソースを指定して、Destinationでロード先を指定する。今回はConnectorにGoogle Driveを、DestinationにSnowflakeを設定する。
Connectorの設定
Google系のコネクタは以下の二つが使えそう。setup手順は公式の手順がわかりやすかったのでその通り進めた。
今回はGoogle Drive上のExcelファイルを読み込みたいのでGoogle Driveコネクタを使用する。
Google Driveコネクタは2種類あり、Magic Folderと当該フォルダに入っている全てのファイルを読み込んでくれる。Merge Modeだとファイル名やファイルタイプを指定できる。ちなみに使えるファイル形式は以下の通り。文字コードは基本的にUTF系のみサポート。Shift-JISは読み込めない模様。
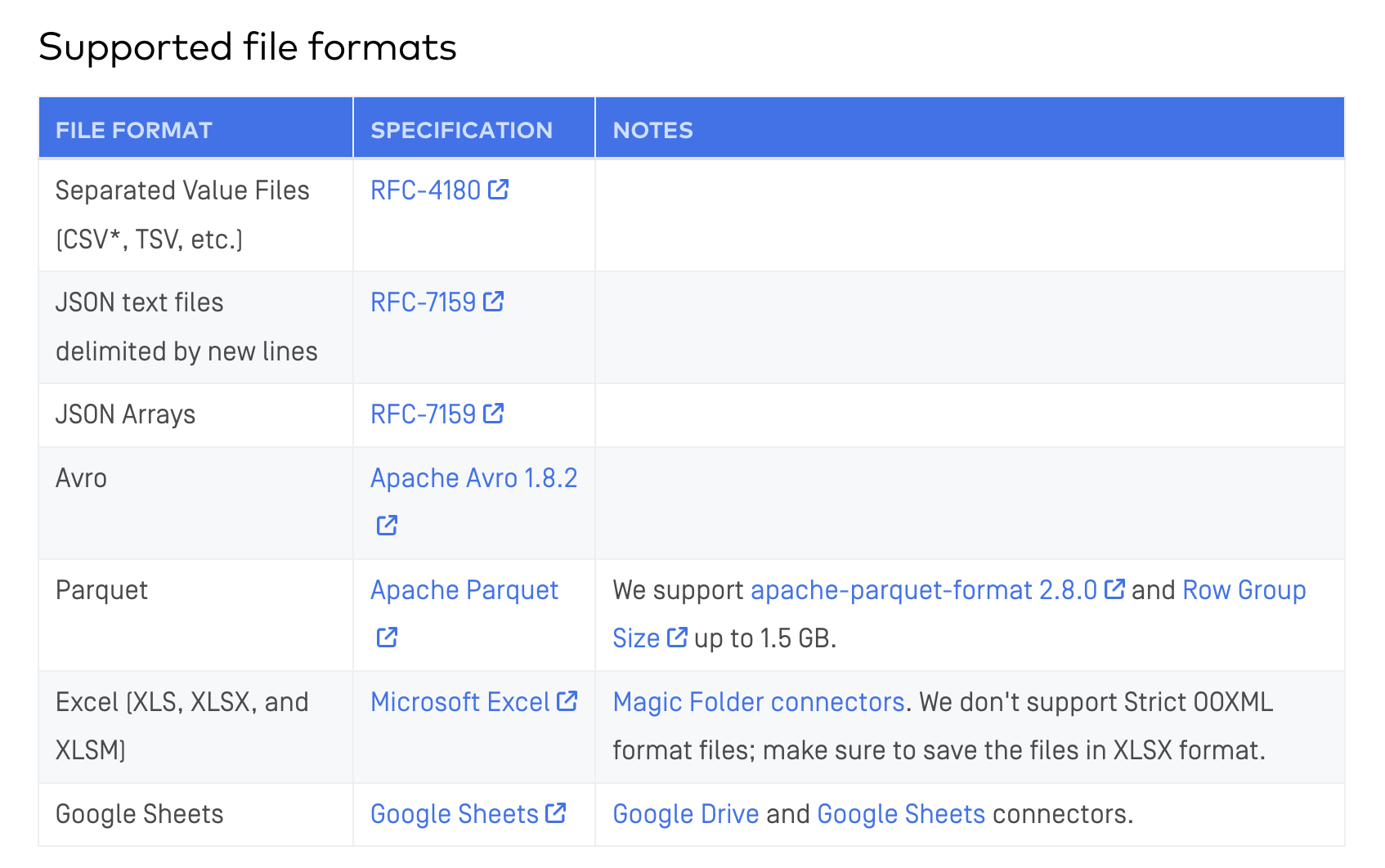
ただしExcelファイルをサポートしているのはMagic Folderの方だけ。Merge Modeだと対応していない模様。Excelファイルを読み込みたいのでMagic Folderで対応する。
Google Driveコネクタを使って以下画像の通り二つのファイルを置いたフォルダのデータを読み込んでみた。日本語の読み込みテストのため英語版と日本語版を用意した。

するとこんな感じでファイル名を元に自動的にテーブルを作成してくれた。スキーマ名はコネクタの設定の中で指定した。Merge Modeだとテーブル名も指定が可能なのでMerge Modeの方が制御がしやすそうです。

元データのファイル名やカラム名が日本語の場合、ひらがな/カタカナはローマ字に、漢字は中国語に変換される模様。日本語データを扱う場合はこの対策は考えないといけない。今回は英語版のSample - Superstore.xlsを使っていくことにする。
https://dev.classmethod.jp/articles/fivetran-and-hightouch-self-knowledge/
ちなみにKintoneなど対応してないAPIからデータを取得する際は独自コネクタの作成が必要。独自コネクタを使う場合はAWSのLambdaのようなFaaS(Function as a Service)を準備する必要があり、Fivetranは当該FaaSをキックする模様。
https://cloudfit.co.jp/blog/fivetran-custom-connector
Snowflake側でそういう機能がないか調べてみよう。
Destinationの設定
今回はSnowflakeを利用する。こちらも公式の手順をもとに作成。
https://fivetran.com/docs/destinations/snowflake/setup-guide
作り方は簡単でした。Fivetranで用意されたスクリプトをSnowflakeのworksheetで実行するとFIVETRAN用のウェアハウスとデータベース、ユーザーが作成されるる。あとはFivetran上のDestination設定で、作成されたデータベース名やユーザ名を設定すればOK。
スキーマやテーブル名はコネクタ側で設定することになる。
FivetranでSyncした日時が列として追加されるのはありがたい。

dbt
Snowflakeに格納された3つのテーブルをdbtを使ってJOINして集計する。まずは以下の記事を参考に最初のプロジェクトを作成。
プロジェクトが出来上がった後の基本的な手順は以下の通り。
- プロジェクトを初期化して初期テンプレを生成する
- branchを作成する(branchを作成しないと編集作業ができない)
- modelのexampleは削除して新たに以下のsqlを作成。更新が走ったタイミングは記録したかったので
current_timestamp()で現在時刻を追加してみました。timezoneを日本・するために一行目のALTER SESSION...というのを追加しています。ALTER SESSION SET TIMEZONE = 'Asia/Tokyo'; select date_part('year', order_date) as year ,orders.region ,regional_manager ,sum(sales) as sales ,current_timestamp() as running_datetime from samplesuperstore.sample_superstore_xls_orders as orders left join samplesuperstore.sample_superstore_xls_returns as returns on orders.order_id = returns.order_id left join samplesuperstore.sample_superstore_xls_people as people on orders.region = people.region where returns.returned is null group by year, orders.region, regional_manager - dbt_project.ymlを編集。もとあったexampleフォルダについての記述を削除して、その上位部分に
materialized: viewを追記して、models直下の.sqlファイルの実行結果がviewとして保存されるように設定。

- 変更をcommit
- brancheをmainにmerge
branchを作ったりcommitしてmergeしたりがgitを普段使っていなかったので手間取りました。
あとはenviromentを設定して、jobをセットしてrunしてみたら無事snowflakeにviewが生成されました。


おわりに
なんとか一通りの設定をやり切れてよかった。fivetranの設定は楽ちんだったし、dbtでのバージョン管理やテストの実行しやすさはとても魅力でした。Snowflakeとの連携も楽々でした。それぞれ全部コーディングして作ることを考えるとしんどいのでこういうサービスを使うのが効率的なのだろうと実感。
データの活用についてのメモ
データの活用としてはTableauやLooker Studio、Google Colaboratory(Python)を考えている。
TableauとLooker Studioはネイティブコネクタを持っているので安心している。Pythonでもsnowvlake-connector-pythonなるものがあるようなので、それを使ってもよさそう。