この記事は株式会社ビットキー Advent Calendar 2022 8日目の記事です。
Home Product所属の @uminoooon18 が担当します。
はじめに
この記事では、システム間の大量データ連携処理を Cloud Run, Cloud Tasks などのGCPサービスを利用して構築した際にハマった事と、改善のために工夫した事を紹介します。
Cloud Run, Cloud Tasks 何それおいしいの?という方や、
GCPのサービスで大量処理を取り扱うための知見を深めたい方の助けになれば幸いです。
目次
1. Cloud Run, Cloud Tasksとは
2. 今回のシステム間データ連携に求められる要件
3. システム全体像
4. ハマったポイント
5. 解決策
1. Cloud Run, Cloud Tasks とは
Cloud Runとは
- Googleが提供するサーバレスのコンテナ実行環境です。(公式ドキュメント)
- 従来はコンテナ化されたアプリケーションを管理するためには、Kubernetes など管理用のソフトウェアを利用する必要があり学習コストが大変でした。
- それに対し、Cloud Run はフルマネージドなコンテナ実行環境のため、より手軽にコンテナ化されたアプリケーションをデプロイ、運用が可能になっています。
- GCPのサーバレスのサービスとして他に Cloud Functions, App Engine がありますが、それぞれの違いについてはこの記事では詳しく触れません。
- 今回はFunctionsベースなAPIロジックに対して、より柔軟なインフラ設定を行いたかったのでCloud Runを選択しています。
Cloud Tasks とは
- Googleが提供する大量の分散タスクの実行、ディスパッチ、配信を管理できるフルマネージド サービスです。(公式ドキュメント)
- AWSのSQSと似たサービスになります。
- アプリケーションのメイン処理の後に、非同期的に実行しておきたい作業を管理できます。
- App Engine上で構築されたプログラム
- 別サーバに立てているAPIへのHTTPリクエスト
- タスクのディスパッチレートや再試行について管理可能です。
2. 今回のシステム間データ連携に求められる要件
ビットキーのHome事業では、不動産管理会社向けのB2B2Cプロダクトを展開しています。
不動産管理会社の基幹システムから物件情報や入居者情報をシームレスに連携することで鍵の受け渡しをデジタル上で完結しています。
筆者はそのプロダクトの開発担当者なのですが、
今回はその連携において過去最大規模の企業との連携を実現する必要がありました。
具体的な要件として、下記が一例です。
- 前提として連携先のDBはFirestore(既存アプリケーションでDBとして利用しているため)
- 1度に数千-数万件のデータ連携
- 最大で100万件ほどのデータ量
- 日次で実行される
- 夜中実施され、ユーザーの業務開始までには完了していること(3-4時間程度で処理完了)
3. システム全体像
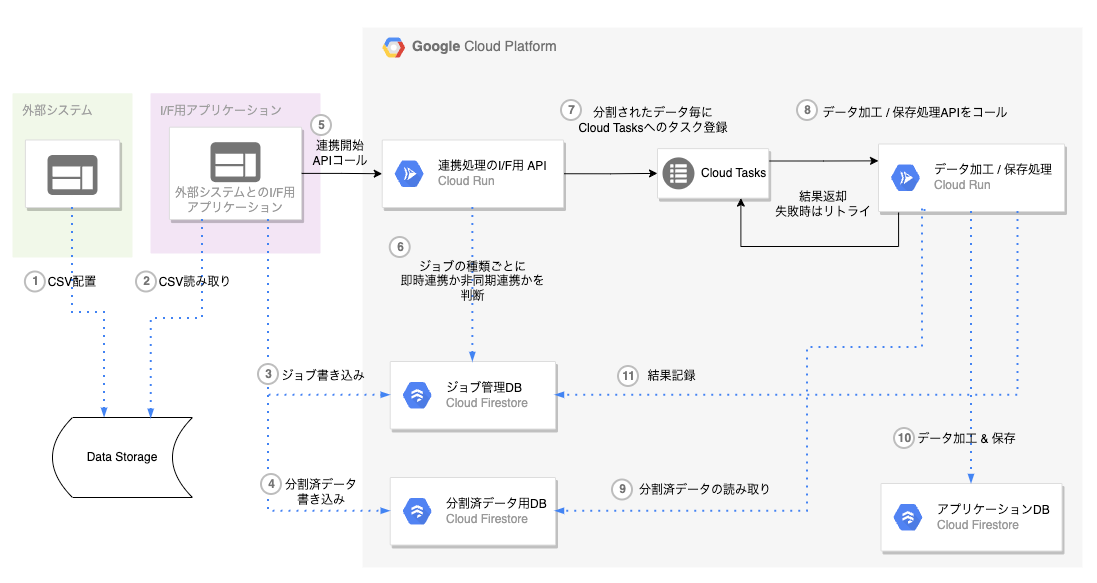
大きく以下の構成になっています。
- A. 外部システム
- B. 外部システムとのI/F用アプリケーション
- C. 連携処理のアプリケーション (← 今回のテーマ)
ざっくり言うと、
- A. 外部システムが連携対象のデータをCSVでinputし、
- B. 外部システムとのI/FアプリケーションがCSVから対象データを分割し、分割後に連携処理アプリケーションをキックし、
- C. 連携処理アプリケーションが大量データを加工/保存する処理をCloud Tasks、Cloud Runを利用して並列で実行しています。
Cloud Runの旨味
- タイムアウト時間がCloud Functionsよりも長く設定可能
- (最大3600秒、Cloud Functionsでは最大540秒)
- 割り当てメモリがCloud Functionsよりも多く設定可能
- (最大32GB、Cloud Functionsでは最大8GB)
- コンテナあたりの最大リクエスト数を設定できるので、コンテナに対して同時にアクセスできる流入量の調整が可能。
Cloud Tasksの旨味
- 時間を指定してHTTPリクエストのスケジュール実行が可能
- 対象のHTTPリクエストが失敗した場合に、自動でリトライする仕組みがある
- タスクの実行間隔や同時実行可能数、失敗時のリトライ上限数などが調整可能
4. ハマったポイント
機能開発が完了し少量データでの動作確認は完了していましが、
実際の運用想定の数十万件のデータを処理するパフォーマンステスト実施時に様々な問題が発生しました。
タイムアウト問題
v13以前のNode.js の http.server のデフォルトタイムアウト設定の違い
Cloud Runの最大タイムアウト時間は3600秒まで設定可能です。
しかし、当時実際に動かしていたコードではなぜか2分でCloud Tasksにタイムアウトを返却してしまっていました。
今回Cloud Tasks からのターゲットとして、HTTPリクエストを受ける形でCloud Runのコンテナに Node.js の expressサーバを立てていたのですが、利用していたNode.jsのversionが v12と若干古かったためにCloud Runのタイムアウト時間よりも先に Node.js のhttps.server のタイムアウト時間に抵触していました。
v13以上であればデフォルトのタイムアウトは0秒(= 無制限)でしたが、
v12ではデフォルト値が120秒で動作してしまうため、別途タイムアウト時間をコード上で指定する必要がありました。(公式ドキュメント)
const app = express();
app.use(express.json());
const port = process.env.PORT || 8080;
// Api はAPIのエンドポイントのソースファイル
app.use(Api);
const server = app.listen(port);
// node v13からはdefault 0 だが、v12なのでデフォルト2分(120000)に設定されている
// Cloud Run側のtimeoutのMAXが3600秒なので、Cloud Run側のMAXに合わせておく
// <https://cloud.google.com/run/docs/troubleshooting#timeout-503>
// <https://nodejs.org/api/http.html#http_server_settimeout_msecs_callback>
server.setTimeout(60 * 60 * 1000);
上記でCloud Runの最大値の3600秒までタイムアウト時間を伸ばすことはできましたが、
万が一3600秒を超えた場合のことも検討する必要がありました。
→ 解決策は後述
OutOfMemory問題
「夜中実施され、ユーザーの業務開始(朝)までには完了していること」の要件を達成するため、処理の並列数を増やして連携処理全体の時間短縮を行なっていました。
Cloud Runのコンテナ環境では柔軟にメモリを指定することが可能ですが、4GBなど大きな値を設定していても並列試行回数が増加した時にOutOfMemoryが発生してしまっていました。
データ量が大量の場合に、「C. 連携処理アプリケーション」が Cloud Tasks から断続的にHTTPリクエストを受け続け、一定時間経過後にOutOfMemoryで処理落ちすることがありました。
→ 解決策は後述
Firestoreへのアクセス数上限問題
高負荷時のFirestore接続エラー
「C. 連携処理アプリケーション」において、FirestoreへのアクセスをFirebase Admin SDKを利用して実現していました。
普段通常利用している範囲では気付かなかったのですが、大量のデータ読み込み/書き込みの処理を複数のコンテナで並列実行している時にFirestoreへのアクセスでエラーが頻発するようになりました。
最初はFirestoreの書き込み制限を疑い、現状把握と上限値の緩和を行うためにGCPの「IAMと管理 > 割り当て」メニューから Cloud Firestore APIなどDB関連の割り当ての値を調査していました。
しかし、割り当てに対する現在の使用率は10%にも満たず、Firestoreに対する書き込み制限ではありませんでした。
詳細調査するためにFirebaseから返却されるエラーを元にGCPサポートに問合せたりしていましたが有力な回答は得られず…
実際にFirebase Admin SDKのライブラリ経由でFirebaseから返却されていたエラーの一例です。
16 UNAUTHENTICATED: Failed to retrieve auth metadata with error: request to <https://www.googleapis.com/oauth2/v4/token> failed, reason: socket hang up16 UNAUTHENTICATED: Failed to retrieve auth metadata with error: request to <https://www.googleapis.com/oauth2/v4/token> failed, reason: Client network socket disconnected before secure TLS connection was established4 DEADLINE_EXCEEDED: Deadline exceeded14 UNAVAILABLE: No connection established2 UNKNOWN: Authentication backend unknown error.14 UNAVAILABLE: 502:Bad Gateway13 INTERNAL: An internal error occurred.
上記それぞれがDBアクセス時にランダムに返却されてしまうため原因の特定に難航しましたが、デバックを進める上で「どうやらDBアクセス前のFirebase Admin SDKの認証っぽい」ということが分かってきたので、Firebase Admin SDKの公式ドキュメントを読み込むことで原因の仮説が立ちました。
[仮説] Firebase Admin SDKを利用したサービスアカウント認証の上限に抵触している可能性
アプリケーション内でFirebase Admin SDKの admin.initializeApp()を利用してサーバ認証を通していたのですが、その際に利用しているサービスアカウントがプロダクトの他APIと同じものを利用していました。
そのため、1サービスアカウントあたりの認証情報の生成リクエストの上限(60,000回/分)に抵触している可能性がありました。(公式ドキュメント)
→ 解決策は後述
5. 解決策
タイムアウト発生時の解決策
Cloud Runの最大タイムアウト時間は3600秒なので、万が一を考えて途中で処理が失敗していた場合に続きから再実行できるように実装を行いました。
- 連携処理の進捗を記録
- 「C. 連携処理アプリケーション」において、ジョブ管理DBと分割済データ用DBに対して「どこまで連携完了しているか」を記録するようにしています。
- タイムアウトなど意図しないエラーで処理終了した場合に再実行時に続きから処理を再開できるようになっています。
- Cloud Tasks のリトライ機構を利用
- 「C. 連携処理アプリケーション」の連携処理でエラー発生時に、呼び出し元にあたる Cloud Tasks にHttp Responseをエラーとして返却することで、Cloud Tasks側で自動でAPIの再呼び出しが実行されます。
- GCPのコンソールからCloud Tasksの 「再試行の構成 > 最大試行回数」 の設定を行うことで、失敗したタスクに対して最大何回までリトライするかを設定できます。(公式ドキュメント)
- 「-1」を指定するとAPIが成功を返却するまで無制限にリトライする設定も可能ですが、無限ループ状態に陥る可能性があるのでおすすめはしません。
OutOfMemoryに対する解決策
Cloud Run および Cloud Tasksの設定を編集することで、OutOfMemoryの発生頻度を下げることに成功しました。
- Cloud Run の設定
- 「容量 > コンテナあたりの最大リクエスト数」 を制限することで、制限した数以上のリクエストを受けた際に新しいコンテナが立ち上がるように設定しました。(公式ドキュメント)
- 1コンテナあたりで捌く処理の数を減らすことで、1コンテナあたりのメモリ使用率を抑えてメモリ不足の発生頻度を抑える狙いです。
- これを設定しなかった場合、1〜2コンテナでリクエストを受け続けてしまい、メモリ使用率が時間経過と共に右肩上がりでOutOfMemoryまっしぐらのグラフになっていました…
- Cloud Tasks の設定
- 「タスク ディスパッチのレートに関する上限 > 最大同時ディスパッチ数」 を制限することで、並列で実行されるタスクの量を調整しました。(公式ドキュメント)
- タスク開始時に同時実行数の上限に達していた場合は前のタスクが完了した後に、次のタスクが開始されるようになるため、「C. 連携処理アプリケーション」へのリクエスト頻度を下げる狙いです。
(※ 上記以外に根本解決策として、グローバル領域のインスタンスや変数スコープを見直したりなどのソース修正も行っています。)
Firestoreへのアクセス数上限問題
サービスアカウントあたりの認証情報の生成リクエスト上限の解決策
GCPサポートによるサービスアカウントの認証情報の生成リクエスト上限の緩和は対応していなかったため、次の2つの方法で上限の回避を行いました。
- コンテナ毎に利用するサービスアカウントを分ける
- 上限エラー発生時にクールタイムを設けてリトライする
- 「1. コンテナ毎に利用するサービスアカウントを分ける」
- 並列実行するデータ加工/保存用の処理をコンテナ毎に別々のサービスアカウントが割り当てられるように実装を行いました。
- これにより、大量データ連携時に同時処理する並列数が増えた場合でも1サービスアカウントあたりの上限に抵触する可能性が低くなりました。
- 「2. 上限エラー発生時にクールタイムを設けてリトライする」
- Firestoreからの接続エラー発生時に出力されるエラー内容はパターン化されていたので、特定のエラー発生時には1分間のクールタイムを空けて、同じ処理をリトライするようにしました。
- Cloud Tasksの自動リトライの仕組みに則っているため、アプリケーション側はクールタイム後にCloud Tasksにエラーを返却するだけで次回Cloud Tasksからリトライされた際に続きから再処理が走るようになっています。
おわりに
今回は 大量データを取り扱うアプリケーションにおいて、
Cloud Run, Cloud Tasks を活用しながらハマったポイントとその解決策についてお話しさせていただきました。
記事内では詳しくお話しできませんでしたが今回のProjectを通して自身としては
パフォーマンスチューニングの大変さと課題発生時に公式ドキュメントを読み込むことの大事さを痛感しました。
普段の開発では遭遇しない問題も多かったかと思いますが、
各GCPのサービスについて「こんな使い方もあるんだ!」と何かの助けになっていれば嬉しいです。
9日目の株式会社ビットキー Advent Calendar 2022は、
Work & Experience Product所属 の@usu_shin が担当します!