はじめに
こんにちは、GxPのウメモトです。この記事はグロースエクスパートナーズ Advent Calendar 2024の11日目の記事となります。
さて、改めて言うことでもないですがここ数年におけるAI技術の浸透は目覚ましいですよね。ChatGPTを始めとした高性能なAIサービスがエンジニアの方以外にも手軽に利用できる時代となっており、スマートフォンのような一過性のブームを超えた新しい当たり前になりつつあるなとひしひし感じます。
そんな中、今年の5月にMicrosoftはAIを活用した新世代のWindows PCとして「Copilot+ PC」を発表しました。+は足し算の記号ではなく「"Copilot+" "PC"」です。
簡単に言うと、従来クラウドベースで使用できたMicrosoftのAIサービスである「Copilot」を手元で簡単かつ高速に利用できるPCデバイスです。
詳細は後述しますが、このCopilot+ PCの強みを支えるのは何といってもNPUでしょう。このNPUの登場によりローカルでAIモデルを高速に、効率的(省エネ)に実行することが可能となりました。
Copilot+ PCは今年発売されたばかりなため持っている方はまだ少ないかもしれまんが、今後シェアは着実に大きくなっていくのではと思っています。
しかし、せっかくのNPUも使わなければ意味がない!
そこでこの記事ではCopilot+ PCに搭載されているNPUをコード実装を通して実際に動かしてみようという試みをご紹介します。どうぞよろしくお願いします。
以降でご紹介する方法はCopilot+ PCを使用することが前提となりますが、コードを一部修正すればGPU環境でも動かすことが可能です。
自分のPCにNPUが搭載されているかどうかわからない方は下記の方法で確認することができます。
PCにNPUが搭載されているか確認する方法
1. 画面下部にあるWindowsのアイコンを右クリックしてタスクマネージャーを開いてください。
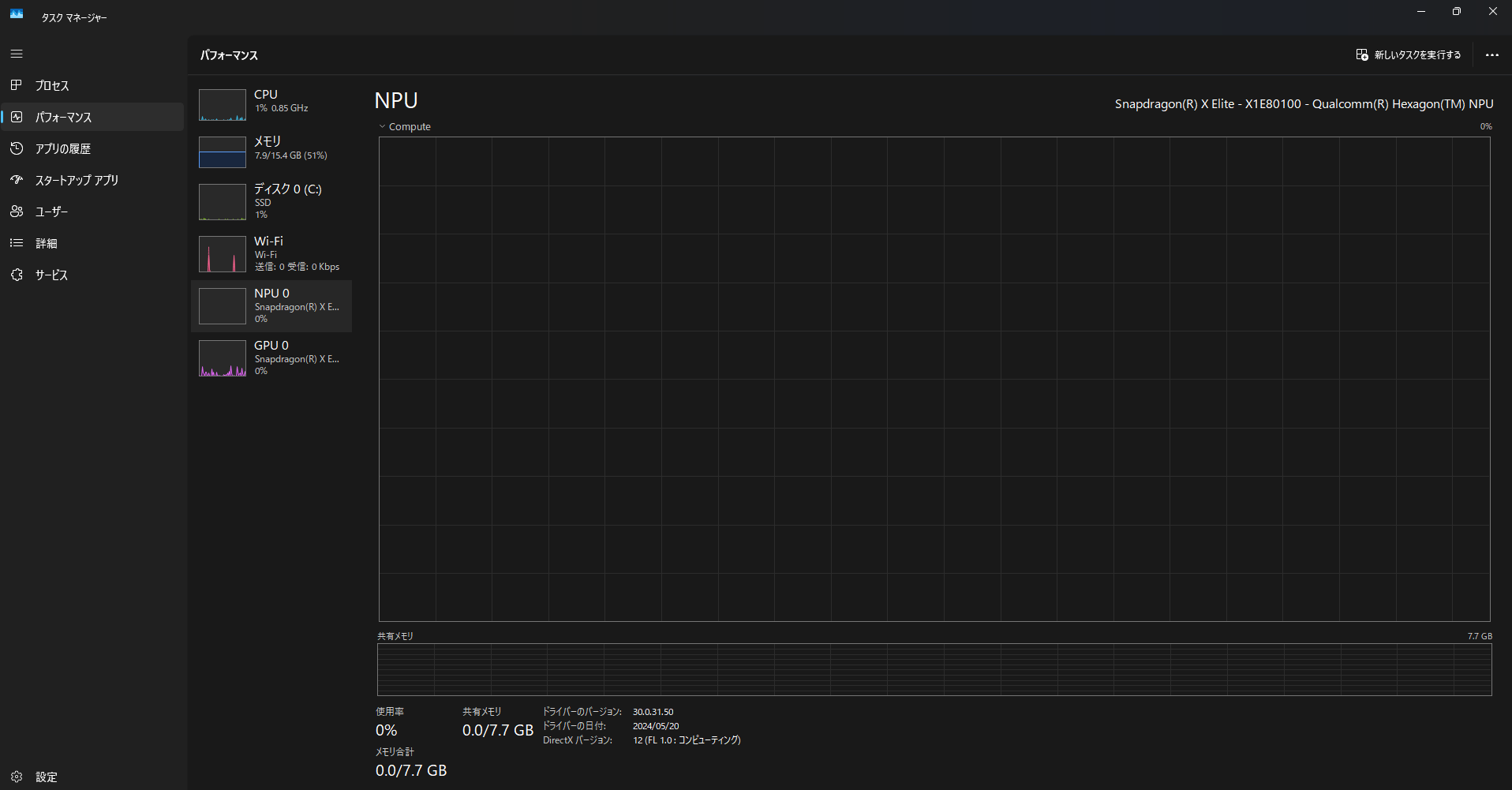
2. 左のサイドメニューからパフォーマンスを選択し、表示された情報の中にNPUがあればバッチリです。
そもそもNPUって?
本題へ入る前にNPUについて少しだけ。
NPU(Neural network Processing Unit)は簡単に言えばPCパーツの一種になります。名前が似ているのでもしやと思った方もいるかもしれませんが、「PCでゲームをするなら~」、「動画編集をするなら~」といった話題でよく出てくるGPUと似た立ち位置にいます。
GPUは並列で計算をする処理が得意ですが、NPUはAIに関連した処理に特化して設計されています。そのためAI処理に関していえばGPUよりも効率的に高速で処理ができるといううたい文句です。それがPCデバイスに搭載されているため高品質なAI機能がインターネット通信なしでも実行できるというわけです。すごい。
コードを実装する動かし方
今回は.NETのコンソールアプリをベースに、学習済みAIモデルを使った画像の高解像拡大をNPU上で動かすコードを実装します。ちょっとだけ専門用語が増えますがご容赦ください。
使用する画像はこちらの富士山の画像です。11月に静岡旅行へ行ったときに撮ったものを128×128のサイズにしてぼやかし加工をかけたものです。図らずも僕の記憶の中の富士山も今はこれくらいの解像度です。これを512×512のサイズに拡大します。

事前準備
実装をするためにいくつか準備をします。
NuGetパッケージの用意
今回は下記2つのパッケージを利用します。

-
ONNX Runtime
今回の実装例では機械学習モデルのオープンフォーマットであるONNX形式で作成されたAIモデルを使用します。ONNX RuntimeはそんなONNXモデルを動かすための推論エンジンで、すでにNPU対応のパッケージが公開されています。バージョン1.18.0以上であればこのパッケージだけでNPUでの実行準備が整うので試す場合は1.18.0以上をご使用ください。 -
ImageSharp
ONNX Runtimeのサンプルコードでも使用されていたので合わせて採用しました。画像ファイルを扱うために使用します。
学習済みモデルの用意
一から新しくAIモデルを作成するのはとても大変なので、Qualcomm AI Hubに公開されている学習済みモデルを拝借します。目的である画像の高解像拡大を行うため、それを実行してくれるモデルを選びます。今回はReal-ESRGAN-x4plusを選ばせていただきました。リンク内でダウンロードできる.onnxファイルが使用するAIモデルになります。また、Real-ESRGAN-x4plusのリンク画面は実装時にも出番があるのでその時に改めて説明します。
AIモデルの可視化ツールの用意
可視化ツールにはNetronを使用します(ダウンロード版もあります)。モデルのファイルをアップロードするだけで構造が丸見えになる優れもの。特に確認すべきは最初と最後です。実装をするうえでモデルの入力と出力の情報が必要になってきます。
実装コード
前置きが長くなってしまいましたが、ここから実際に解説を挟みつつ実装をしていきます。先にコードの全文は↓に載せておきます。
コード全文
using Microsoft.ML.OnnxRuntime;
using Microsoft.ML.OnnxRuntime.Tensors;
using SixLabors.ImageSharp;
using SixLabors.ImageSharp.PixelFormats;
using SixLabors.ImageSharp.Processing;
// ONNXモデルのパス
var modelPath = "./real_esrgan_x4plus.onnx";
// モデルに入力する画像データのパス
string imagePath = "./hoge.jpg";
using Image<Rgb24> image = Image.Load<Rgb24>(imagePath);
using Stream imageStream = new MemoryStream();
image.Mutate(x =>
{
x.Resize(new ResizeOptions
{
Size = new Size(128, 128),
Mode = ResizeMode.Crop
});
});
// 画像を 1 * 3 * 128 * 128のテンソルに変換する
Tensor<float> input = new DenseTensor<float>(new[] { 1, 3, 128, 128 });
image.ProcessPixelRows(accessor =>
{
for (int y = 0; y < accessor.Height; y++)
{
Span<Rgb24> pixelSpan = accessor.GetRowSpan(y);
for (int x = 0; x < accessor.Width; x++)
{
// それぞれの値は0.0 ~ 1.0の範囲に収める
input[0, 0, y, x] = pixelSpan[x].R / 255f;
input[0, 1, y, x] = pixelSpan[x].G / 255f;
input[0, 2, y, x] = pixelSpan[x].B / 255f;
}
}
});
var inputs = new List<NamedOnnxValue>
{
NamedOnnxValue.CreateFromTensor("image", input)
};
var sessionOptions = new SessionOptions
{
ExecutionMode = ExecutionMode.ORT_SEQUENTIAL,
IntraOpNumThreads = 0,
InterOpNumThreads = 0,
EnableMemoryPattern = false,
EnableCpuMemArena = false,
GraphOptimizationLevel = GraphOptimizationLevel.ORT_ENABLE_ALL,
};
sessionOptions.AppendExecutionProvider("QNN", new Dictionary<string, string>
{
{ "backend_path", "QnnHtp.dll" },
{ "htp_performance_mode", "burst"},
{ "htp_graph_finalization_optimization_mode", "3" },
{ "enable_htp_fp16_precision", "1" }
});
// モデル実行
using var session = new InferenceSession(modelPath, sessionOptions);
using var results = session.Run(inputs);
var outputPath = "./fuga.jpg"; // 出力する画像のパス
int width = 512; // 出力画像の幅
int height = 512; // 出力画像の高さ
Image<Rgb24> genImage = new Image<Rgb24>(width, height);
var dataSpan = results[0].AsEnumerable<float>().ToList();
// 出力されたデータを画像に変換
for (int y = 0; y < height; y++)
{
for (int x = 0; x < width; x++)
{
// インデックスの計算
int pixelIndex = y * width + x;
// 推論結果の出力値は0.0 ~ 1.0の間なので0 ~ 255の範囲に変換する
byte r = (byte)(dataSpan[pixelIndex] * 255);
byte g = (byte)(dataSpan[pixelIndex + width * height] * 255);
byte b = (byte)(dataSpan[pixelIndex + width * height * 2] * 255);
// ピクセルを設定
genImage[x, y] = new Rgb24(r, g, b);
}
}
// 画像を保存
genImage.Save(outputPath);
それでは解説していきます。
最初にパッケージのインポートをします。
using Microsoft.ML.OnnxRuntime;
using Microsoft.ML.OnnxRuntime.Tensors;
using SixLabors.ImageSharp;
using SixLabors.ImageSharp.PixelFormats;
using SixLabors.ImageSharp.Processing;
そして入力として渡す画像データを読み込みます。
// モデルに入力する画像データのパス
string imagePath = "./hoge.jpg";
// 画像の読み込み
using Image<Rgb24> image = Image.Load<Rgb24>(imagePath);
読み込んだ画像をモデルが期待しているデータ形式に変換します。ここでNetronの出番その1です。モデルの入り口を見てあげると以下のようになっています。このモデルは入力形式として"image"という名前で1×3×128×128の形状のデータを欲しがっているということが分かります。

というわけでまずは読み込んだ画像を128×128のサイズに変換します。ただ先ほどお見せした富士山の画像はすでに128×128に加工しているので同じ画像を使うのであれば別になくても大丈夫です。ご自身で用意した画像を使いたいときにこちらを実装してください。
// 画像サイズを128 * 128にリサイズ
using Stream imageStream = new MemoryStream();
image.Mutate(x =>
{
x.Resize(new ResizeOptions
{
Size = new Size(128, 128),
Mode = ResizeMode.Crop
});
});
リサイズした画像をテンソルというデータ形式に変換します。サイズは先ほど確認した入力に合わせます。画素値は0 ~ 255の範囲を取りますが、テンソルへ変換する際には最大値である255で除算をして0.0 ~ 1.0の間に収まるようにします。
// 画像を 1 * 3 * 128 * 128のテンソルに変換する
Tensor<float> input = new DenseTensor<float>(new[] { 1, 3, 128, 128 });
image.ProcessPixelRows(accessor =>
{
for (int y = 0; y < accessor.Height; y++)
{
Span<Rgb24> pixelSpan = accessor.GetRowSpan(y);
for (int x = 0; x < accessor.Width; x++)
{
// それぞれの値は0.0 ~ 1.0の範囲に収める
input[0, 0, y, x] = pixelSpan[x].R / 255f;
input[0, 1, y, x] = pixelSpan[x].G / 255f;
input[0, 2, y, x] = pixelSpan[x].B / 255f;
}
}
});
このテンソルデータを使ってimageという名前でONNX用オブジェクトを定義して入力用のデータは完成です。
var inputs = new List<NamedOnnxValue>
{
NamedOnnxValue.CreateFromTensor("image", input)
};
次に推論エンジンを動かすための設定を行います。まずはセッションの設定ですがこれはざっくりいうとモデルを動かす際の挙動を決定するものです。
実装をするうえでここが一番沼りました。どれをどう設定すれば...と頭をしばらく抱えていましたところに救世主が。何を隠そう今回拝借したReal-ESRGAN-x4plusのページです。ここの「See more metric」ボタンを押すとモデルの詳細を確認することができるのですが、そのページの下部にある「Runtime Configuration」の欄に設定値が記載されていました。もしかしたら多少設定値が違っても動くのでしょうが、提供元から実績のある具体的な設定を教えてくれるのはありがたすぎる。
あとはドキュメントのこことかこことにらめっこしながら設定を行います。
var sessionOptions = new SessionOptions
{
ExecutionMode = ExecutionMode.ORT_SEQUENTIAL,
IntraOpNumThreads = 0,
InterOpNumThreads = 0,
EnableMemoryPattern = false,
EnableCpuMemArena = false,
GraphOptimizationLevel = GraphOptimizationLevel.ORT_ENABLE_ALL,
};
sessionOptions.AppendExecutionProvider("QNN", new Dictionary<string, string>
{
{ "backend_path", "QnnHtp.dll" },
{ "htp_performance_mode", "burst"},
{ "htp_graph_finalization_optimization_mode", "3" },
{ "enable_htp_fp16_precision", "1" }
});
AIモデルとセッション情報を使って処理を実行します。
// モデル実行
using var session = new InferenceSession(modelPath, sessionOptions);
using var results = session.Run(inputs);
最後です。出力されたデータはそのまま画像データとして出てくるのではなくテンソル形式のデータが一列でズラーっと並んでいます。しかも値は0.0~1.0の範囲です。
ここでNetronの出番その2です。モデルの出力を見てみると3×512×512のサイズとなっています。つまりズラーっと並んだ出力データはこのサイズに変換が可能です。

では、0~255の画素値範囲に戻しつつ3×512×512の画像データに詰めなおして保存します。
var outputPath = "./fuga.jpg"; // 出力する画像のパス
int width = 512; // 出力画像の幅
int height = 512; // 出力画像の高さ
Image<Rgb24> genImage = new Image<Rgb24>(width, height);
var dataSpan = results[0].AsEnumerable<float>().ToList();
// データを画像に変換
for (int y = 0; y < height; y++)
{
for (int x = 0; x < width; x++)
{
// インデックスの計算
int pixelIndex = y * width + x;
// 推論結果の出力値は0.0 ~ 1.0の間なので0 ~ 255の範囲に変換する
byte r = (byte)(dataSpan[pixelIndex] * 255);
byte g = (byte)(dataSpan[pixelIndex + width * height] * 255);
byte b = (byte)(dataSpan[pixelIndex + width * height * 2] * 255);
// ピクセルを設定
genImage[x, y] = new Rgb24(r, g, b);
}
}
// 画像を保存
genImage.Save(outputPath);
これで実装は一通り終わりです。お疲れさまでした。
結果
では保存された画像を見てみましょう。
まずは元の画像を特に何もせず無理やり512×512に拡大したものがこちらです。ぼやぼやですね~。なにも思い出せません。

そしてこちらがAIが出力した画像です。おかげで思い出せました。確かにこんな感じの景色でした。

ちなみにオリジナルの画像がこちらです。頂上付近の細かい形状や雪のある所ないところも結構ちゃんと再現できていますね。木の部分も単色で塗りつぶさず葉っぱを表現しようとしているのもすごい。

肝心のタスク状況なのですが、しっかりNPUで動いてくれていました。

細かい違いは出てくるでしょうが、画像関連のAIモデル(特に画像を入力して画像を出力する)の使用時は今回の実装がベースに使える場面は結構あるんじゃないかと思います。
興味があればぜひQuallcom Hubでほかのモデルも探してみてください。今回紹介したのは「超解像」と呼ばれるモデルを使用しましたが、Quallcomm Hubには画像生成やテキスト生成のモデルもあるようだったので、ダウンロードしてモデルを入れ替えて遊んでみたりすると楽しいかもしれません。
余談
ちなみにコード実装をせずにNPUを動かすこともできます。それはWindows11に標準搭載されたAI機能を使うことです。最新のWindows11をインストールしたCopilot+ PCがあればすぐに使用できる機能もあるのでぜひ試してみてください。
おわりに
今回はNPUを搭載したCopilot+ PCで実際にNPUを使ってAIモデルを動かしてみる試みでした。
紹介した実装ベースの方法では公開されているAIモデルをダウンロードし使用しましたが、2025年1月に公開予定のWindows Copilot RuntimeAPIsを使えばCopilot+ PC内に入っているAIの機能をAPIで呼び出すことができるようになるそうです。その場合はモデルから用意する必要がなくなるのでやりたいことによってはさらにカロリーを下げたAI機能の実装が可能となりそうです。
ここまで読んでいただきありがとうございました!
本記事で使用したAIモデルは、Qualcomm AI Hubで提供されているものであり、以下のライセンス条件に基づいて使用されています。
Copyright 2024 Qualcomm Innovation Center, Inc.
Qualcomm AI Hub Proprietary License