この記事は、ただの集団 AdventCalendar 2019の22日目の記事です。
前回は@wataraiさんのElasticsearch で learning-to-rank を試してみた!でした。
概要
「分散システムデザインパターン」(Brendan Burns 著、松浦 隼人 訳)は、コンテナを用いた分散システムアーキテクチャのパターン事例集です。
この記事では本書にかかれたscatter-gatherパターンの概要と実装例について解説します。
scatter-gatherパターンとは
モノリシックなシステムの課題の1つに、処理のスケールが難しいというものがあります。例えば、1リクエストでユーザー情報の取得、商品の検索、スポンサー枠の商品の検索をするECシステムがあります。このときモノリシックなアプリケーションでは1サーバー内でこの処理を実行しなければならず、以下の問題が発生します。
- サーバーのコア数やメモリのスペックまでしか高速化できない
- サーバー内のディスクからデータを取る場合、サーバーのディスクサイズまでしかデータを増やせない
これらの課題をscatter-gatherパターンで解決します。scatter-gatherパターンは、一言で言えば、複数のシステムに処理を分散して計算を行い(scatter)、結果を1つに集約する(gather)パターンです。
処理を複数台のサーバーに分散して並列で計算させることで性能のスケールを行えます。また、大量のデータもパーティショニングを行い複数のサーバーで分散させて持つことで容量拡張も可能です。さらに、別々の検索を1サーバーで行う場合と比較すると、複数のマイクロサービスに分割することで関心の分離を行いアーキテクチャの再利用性が高まります。
具体例:分散ドキュメント検索システム
scatter-gatherパターンの具体例として、書籍でも紹介されていた分散ドキュメント検索システムを作ります。
システムの概要
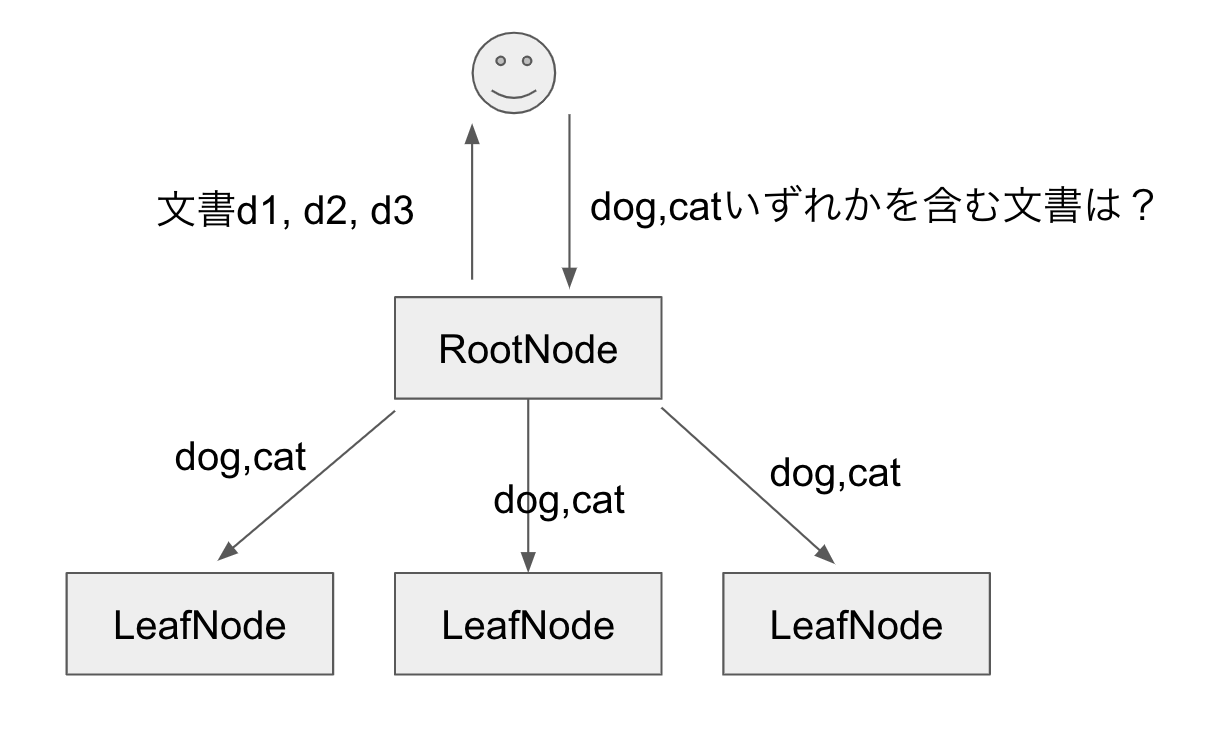
入力は単語の組(例: [dog, cat]、出力はそれぞれの単語のいずれかが含まれている文書のリストです。
前提として、ユーザーのリクエストを受け付けるノードをRootNode, 文書集合を持ち、単語のある文書を検索する役割を持つノードをLeafNodeとします。
処理の流れは、以下3段階に分かれます。
- scatter…RootNodeの処理です。ユーザーのリクエストをそのまま全てのLeafNodeへ送ります。
- 検索処理…LeafNodeの処理です。自身のディスクから単語の含まれている文書を検索します。
- gather…RootNodeの処理です。各LeafNodeが返した文書のリストを1つのリストにまとめ、ユーザーに返します。
ポイントは、図のように複数台のLeafNodeに処理を分散させることで、LeafNodeの増加に応じて処理速度を上げられる点です。
akka-httpを用いた実装
ソースコード
実装した例を以下リポジトリに置きました。
主に以下ライブラリを使用しています。
- akka-http
- circe
RootNodeの処理概要
RootNodeはリクエストを各LeafNodeに送り、各LeafNodeの結果をまとめてユーザーへ返却します。
RootNodeに対するユーザーからのリクエストの例は、http://localhost:5000/search?q=dog,catという形です。
RootNodeはリクエストのクエリパラメータは特にいじらず、各LeafNodeへまったく同じリクエストを送ります。
class RootNodeRoute()(implicit ec: ExecutionContext) extends NodeRoute {
def routes: Route = path("search") {
parameter('q) { keywords =>
onSuccess(fetchLeafResponse(keywords)) { res =>
complete(res.asJson.toString())
}
}
}
private def fetchLeafResponse(keywords: String): Future[DocumentResponse] = {
// 省略(各LeafNodeへ並列でリクエストを送る)
}
}
}
LeafNodeの処理概要
LeafNodeはディスクからドキュメントを検索する役割を持ちます。
RootNodeから送られたクエリqは、まず単語のリスト(例:[dog, cat])に分割されます。
各単語の入ってる文書を求める時、どうすればいいでしょうか。全文書のファイルを読み取り単語が入っているか確かめるのも手ですが、処理時間がかかりすぎます。
そこで、インデックスを用いて高速化します。
インデックスは、例えば以下のように、単語と、その単語の含まれている文書IDのテーブルです。
"dog" -> Seq(0, 1),
"cat" -> Seq(2, 3, 4),
"bard" -> Seq(5, 8),
インデックスにより文書をピンポイントで探し出せます。
Routeの実装は以下です。
class LeafNodeRoute extends NodeRoute with FailFastCirceSupport {
// ...省略
def routes: Route =
path("search") {
parameter('q) { param =>
val words = param.split(",").toSeq // クエリをパースして単語リストを得る
val docIds = indexRepository.getDocumentIds(words) // インデックスを引いて文書IDのリストを得る
val docs = documentRepository.findAll(docIds) // ディスクアクセスして文書リストを得る
val response = DocumentResponse(docs) // レスポンスをRootNodeへ返す
complete(response.asJson)
}
}
}
scatter-gatherパターンの注意
最後に注意点としては、ノードを増やしていけば速度は上がりますが、台数の増加によって、故障確率も増える点があります。
100台のLeafNodeのすべてのレスポンスを結合する場合、1台でも停止していると全リクエストが失敗してしまいます。
そこで、各ノードのディスクのレプリカをもったノードを置くことで対処します。
レプリカを置くことで、各ノードの停止を伴うアップデートも行いやすくなります。