はじめに
この記事では、GoogleI/O 2019にて発表されたFirebaseの新機能Firebase MLKit AutoML Vision Edgeについての概要と、実際に使用する際の流れを実例を用いて解説します。
「使ってみたいと思っているけど、大変そう。。。」とお考えの方々の後押しができればいいなと思っています。
Firebase MLKit AutoML Vision Edgeとは
Firebaseコンソールに画像をアップロードするだけで、カスタムモデルを作成できる機能です。
- What's new from Firebase at Google I/O 2019(Firebase公式ブログ)
- ML Kit: Machine Learning for Mobile with Firebase (Google I/O'19)(YouTube)
Firebase Console > ML Kit > AutoMLからスタートできます。
データセットの準備
新規データセットの作成
コンソールからデータセットを追加を選択。
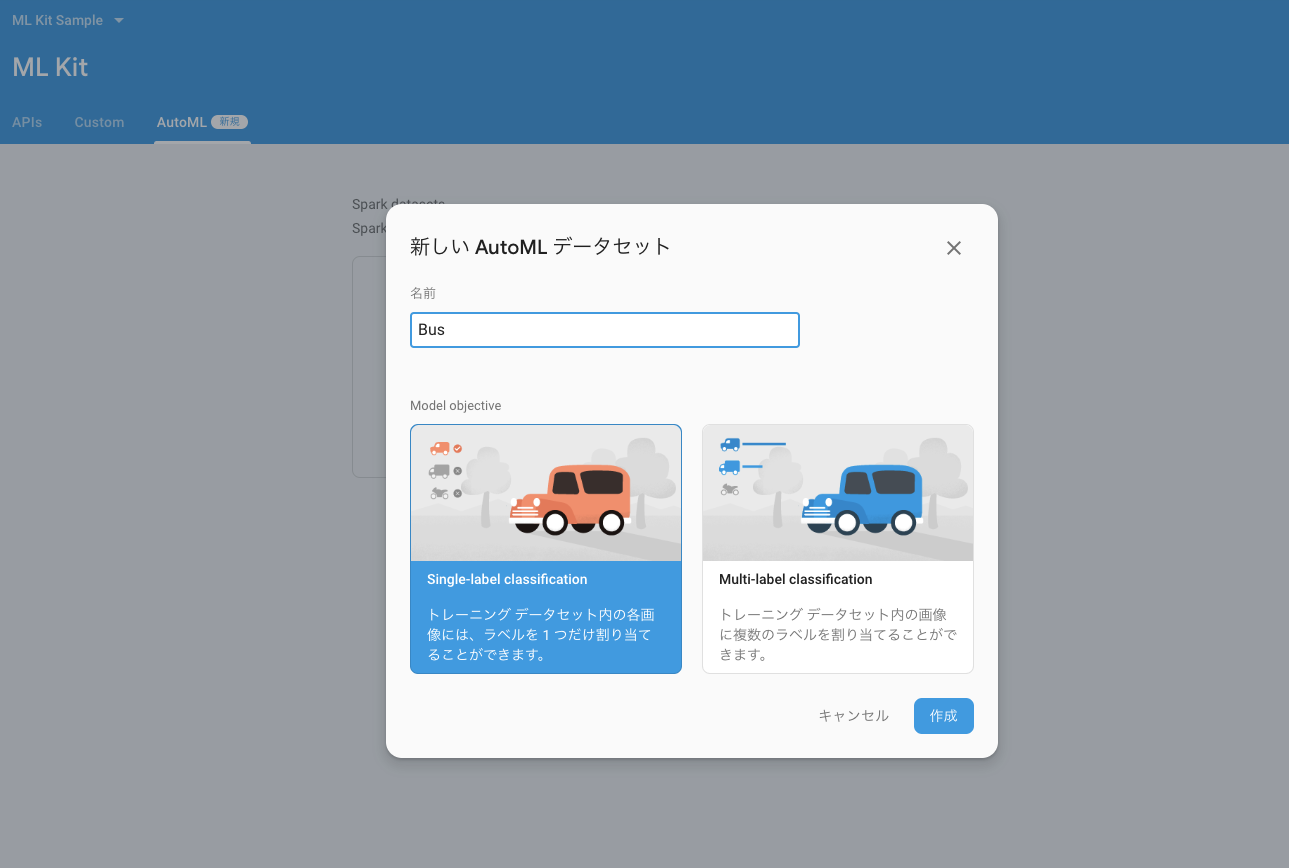
学習データの各画像に付与するラベルの数を選ぶことができます。
今回は1つを選択します。
トレーニングデータ画像の準備
今回はバスの判別をするために、3社のバス会社の画像を使います。
バス会社A(busA), バス会社B(busB), バス会社C(busC)と名付けました。
(推論精度を上げるためには、それぞれのラベルに対して最低100枚の画像が必要になりますが、今回はお試しでそれぞれ20枚ずつで挑戦してみました。)
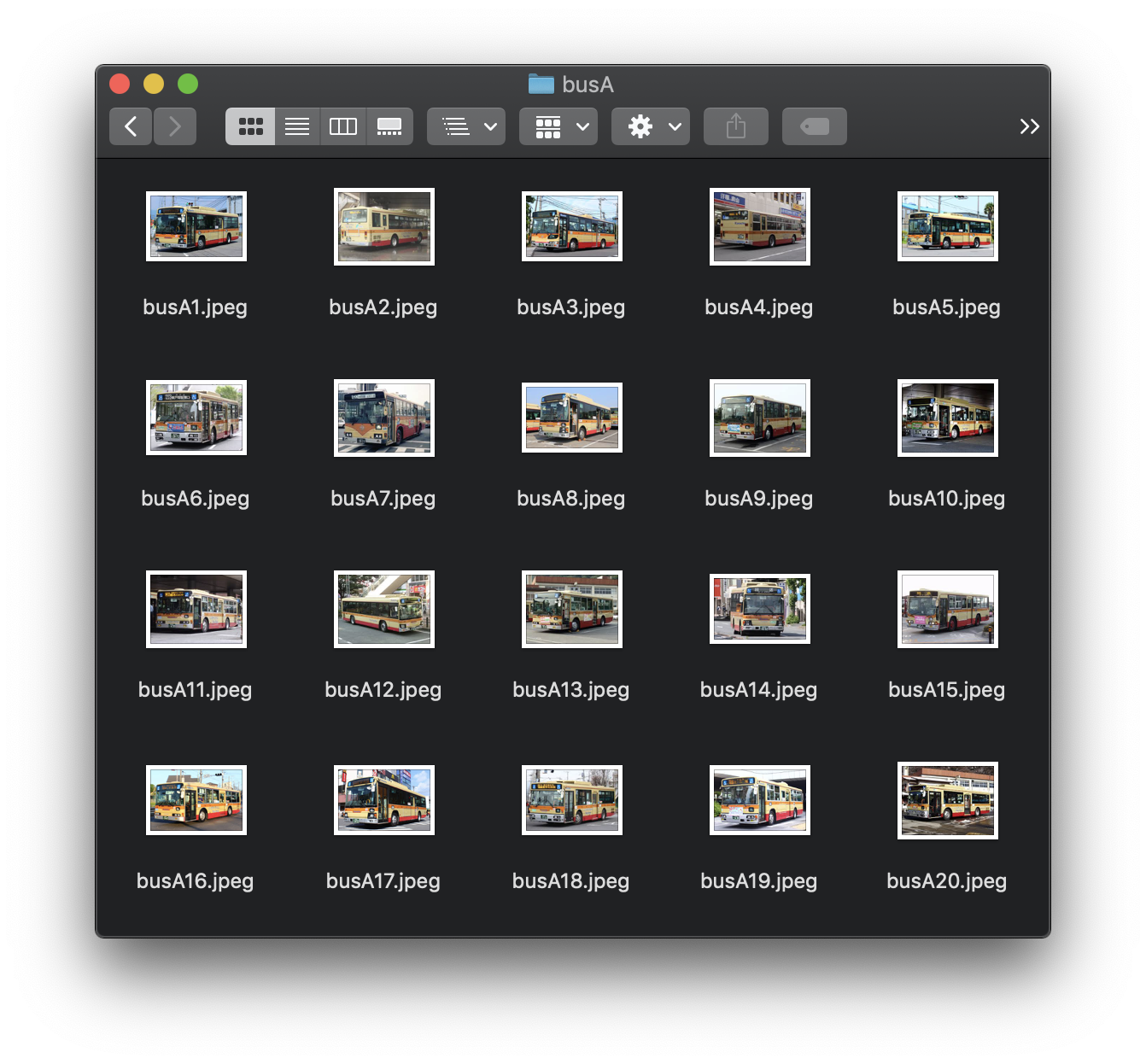
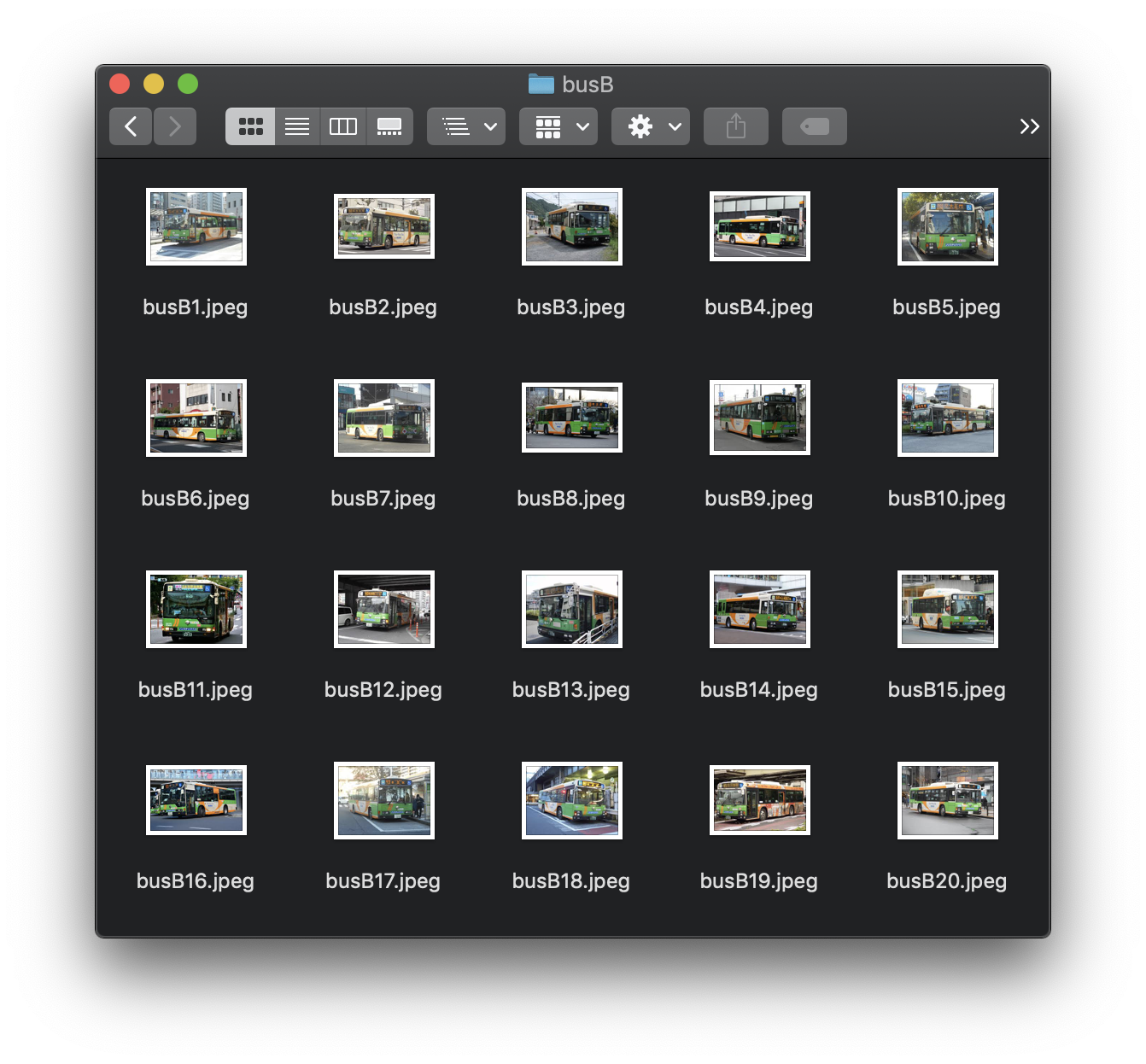
画像はそれぞれbusA, busB, busCというフォルダの中に保存しています。
コンソールにアップロードすると、それぞれのフォルダ名がラベルとして認識され、フォルダ内の画像全てにフォルダ名と同じ名前のラベルが付与されます。

これらの画像をzip圧縮してコンソールにアップロードします。

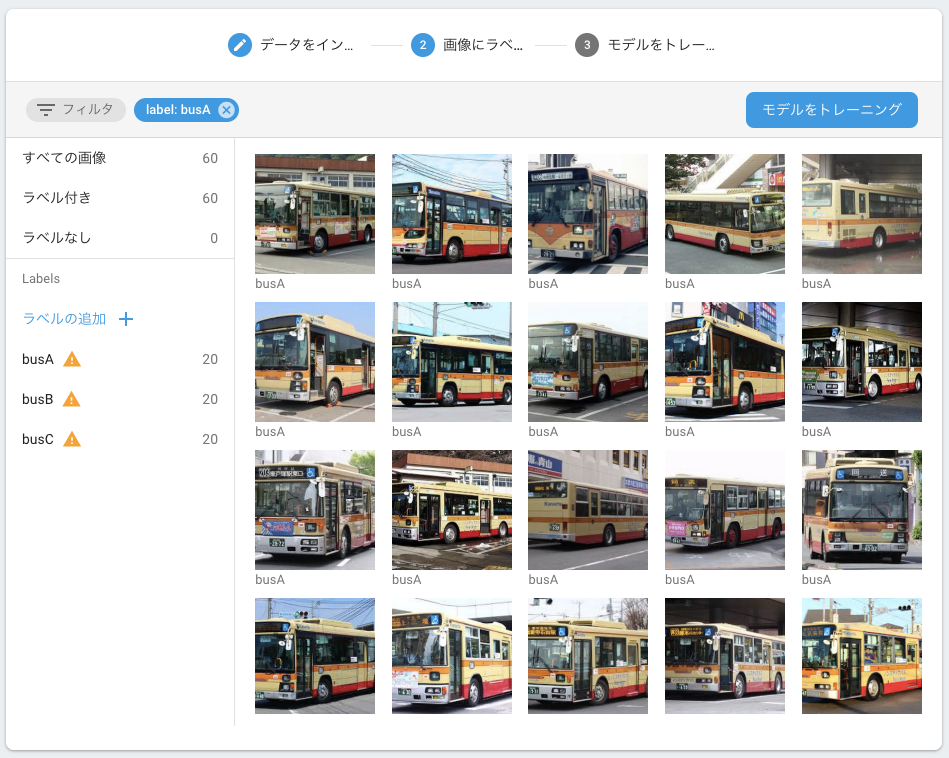
アップロードが完了すると、ラベル付けされた画像群が確認できます。
それぞれのラベルの横に表示されている警告マークは、データ数が100枚を満たしていないことを警告してくれています。
モデルのトレーニング
モデルをトレーニングを選択すると次の画面に遷移します。

レイテンシとパッケージサイズのオプションを選択します。
制度よりも速度やサイズを求める場合は下限レイテンシ、速度やサイズよりも精度を求める場合は高精度を選択します。
今回は中間の汎用を選択しました。
トレーニング時間を長くすることでモデルの精度を上げることが可能ですが、無料のSparkプランだと最大で1時間しか選択できません。
したがって、今回は1コンピューティング時間を選択します。
これで準備は整いました。
トレーニング開始を選択します。
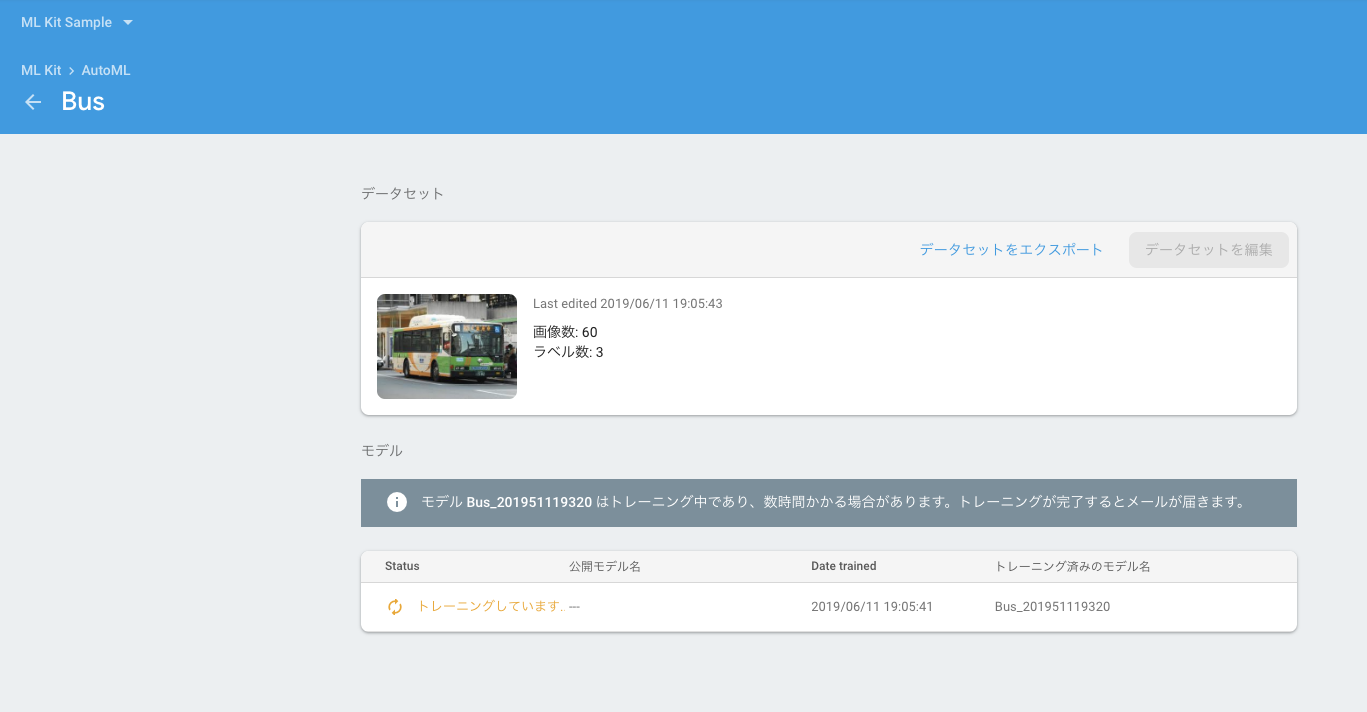
トレーニングが開始され次の画面に遷移します。
トレーニングが完了するとメールが送られてくるので待ちます。
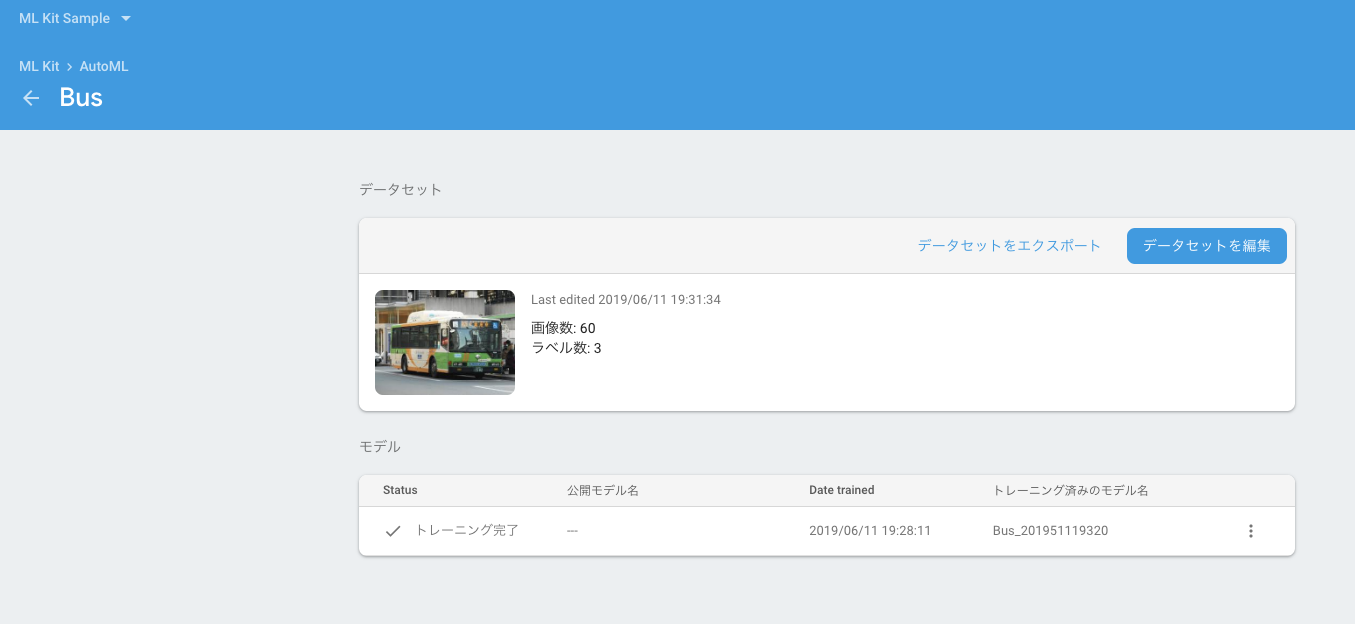
完了するとモデルのステータスがトレーニング完了になるので、クリックしてモデルの評価を確認します。
モデルの評価
この画面ではモデルの精度の確認、調整ができます。

スコアのしきい値
スコアのしきい値を調整することで、モデルの精度のカスタマイズが可能です。
適合率と再現率という2つの指標を元に調整することになります。
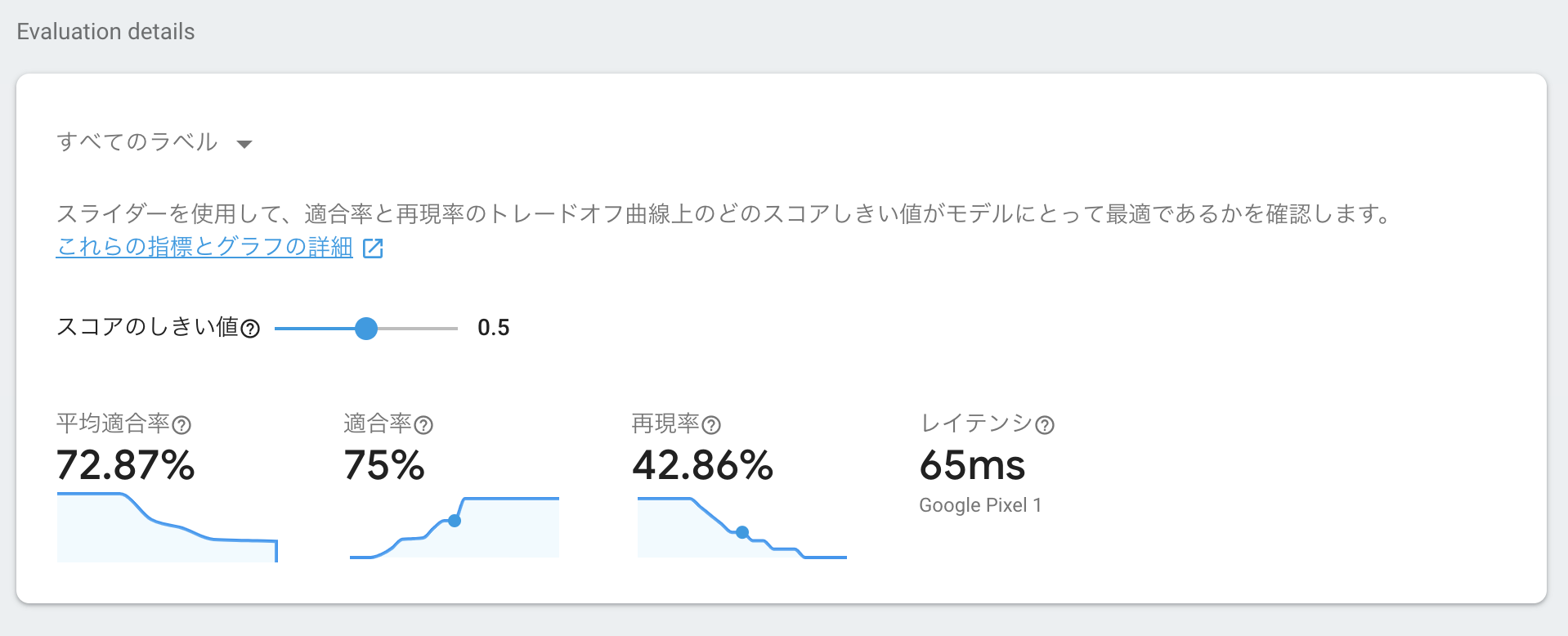
- 適合率
- 正確性のこと。適合率が高いほど偽陽性が低くなる。
- 偽陽性の具体例:バス会社Aが写っている画像に対してバス会社A以外のラベルを付与してしまうこと。
- つまり適合率を高くすると、、、判定精度が上がる代わりに、取りこぼしが多くなる。(狭く深く)
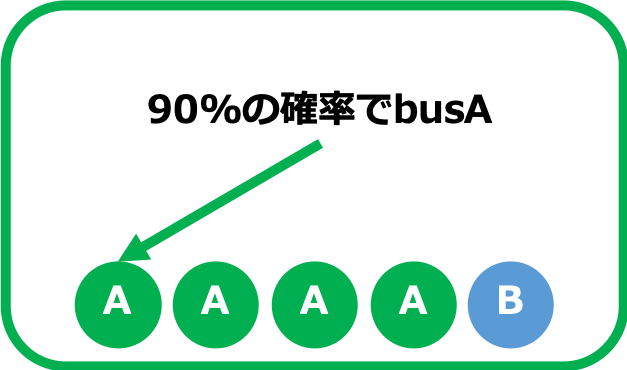
- 再現率
- 網羅生のこと。再現率が高いほど偽陰性が低くなる。
- 偽陰性の具体例:バス会社Aではない画像に対してバス会社Aのラベルを付与してしまうこと。
- つまり再現率を高くすると、、、取りこぼしが少なくなる代わりに、正確性が失われる。(広く浅く)
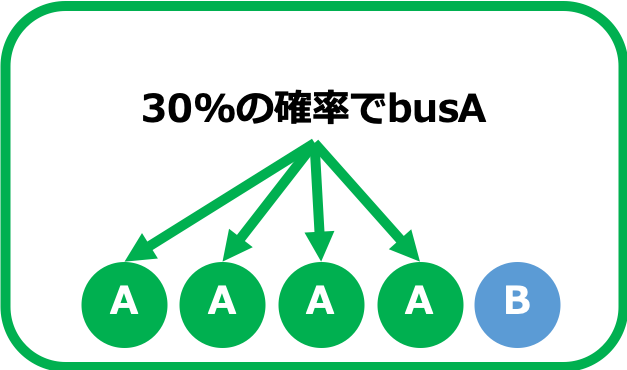
この2つはトレードオフになっているので、どちらを重要視するかは実現したいことによって変わってくると思います。
ちなみにGoogleはこれらの値とユースケースの関係を分かりやすく説明してくれています。
https://cloud.google.com/inclusive-ml/#jump-to-2
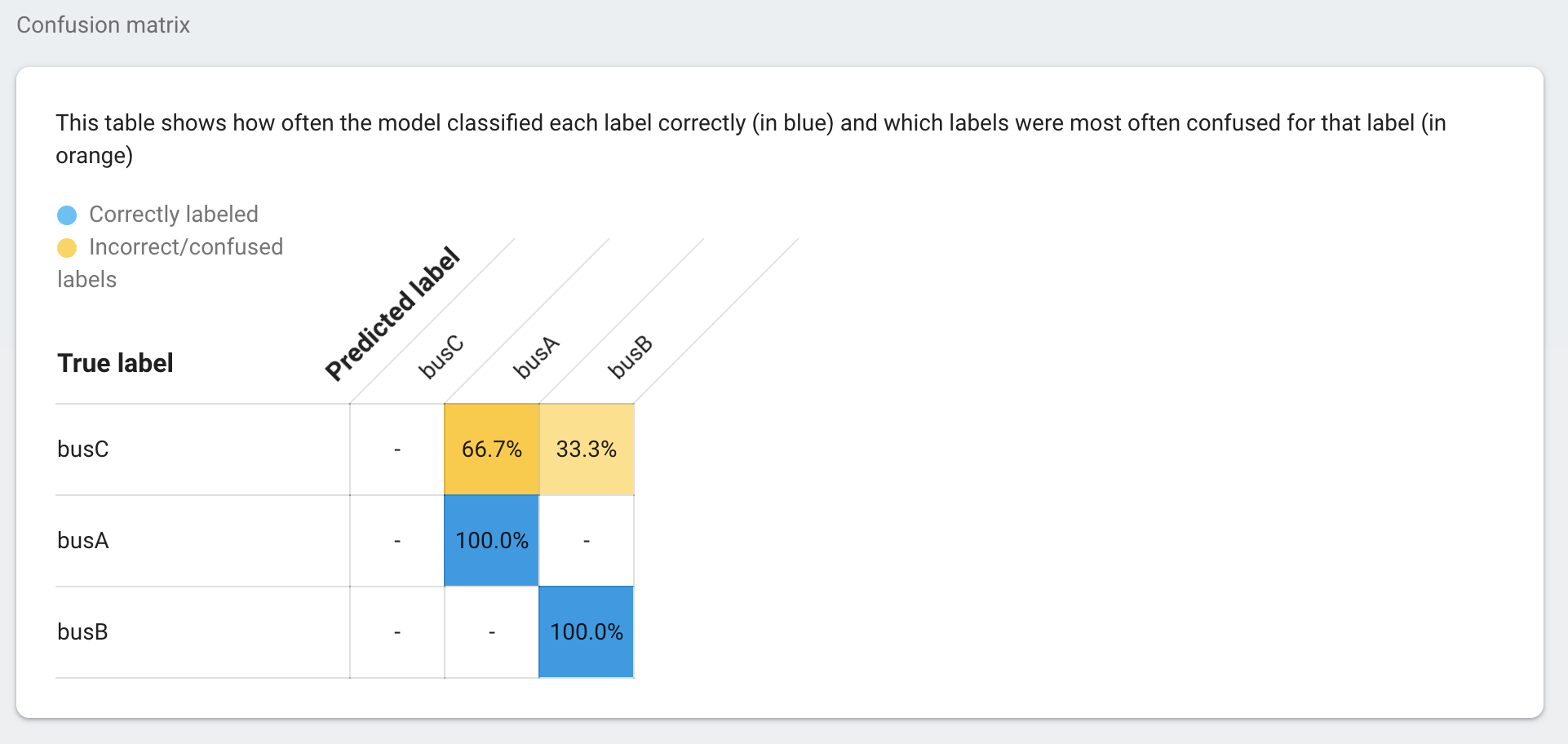
ラベル毎の予測精度
この表では、各ラベルがどれくらいの確率で正しいラベル付けを行うか、またどれくらいの確率で他のラベルと間違えるかを表しています。
モデルのテスト
コンソール上から、トレーニングしたモデルを実際に試すことができます。

バス会社Aの画像を入れてみると、busAは60.5%と予測されました。

バス会社Bでは、busBが69.6%でした。
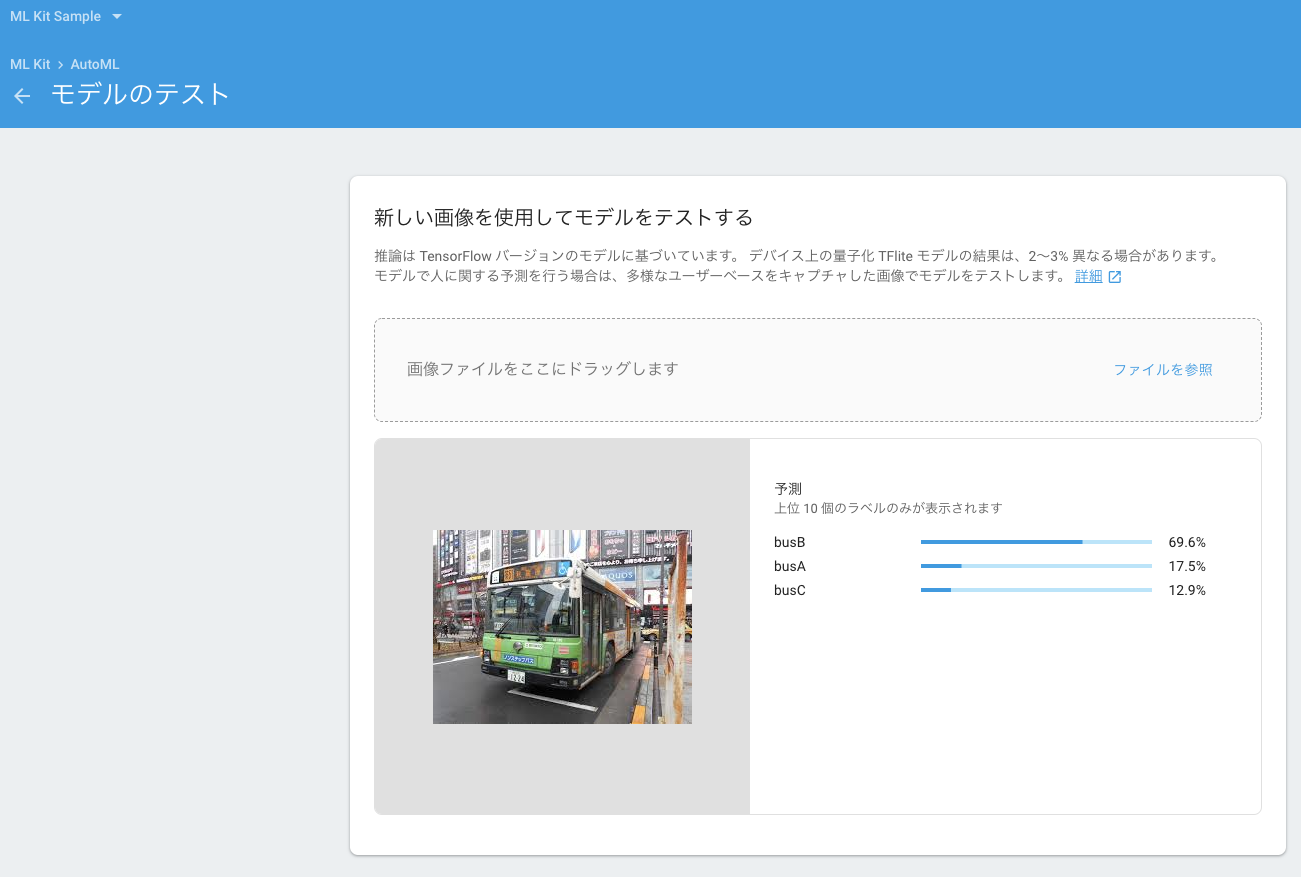
学習に用いた画像数が少なく学習時間も少ないながら、ML初心者からすると高い精度が出ているように感じました。
まとめ
- Firebase MLKit AutoML Vision Edgeを使うと、Googleがモデル作成を肩代わりしてくれます。
- MLの専門知識がなくても、コンソールの手順通りに進めるだけで簡単にモデルを作成できます。
アプリへの組み込み部分も完了次第、追記したいと思います。
是非みなさんもご自分で試してみてください!