新しいBing Search Serviceのドキュメントが分かりづらかったです・・・。
-
クイックスタート:Azure Bing Spell Check REST APIとPythonを使用してスペルをチェックする
こちらは、古いバージョンのドキュメントを参照して作られたもので「参考までにとってある」そうです - 新しい(v7.0)のドキュメントはこちら
Bing Search Services developer documentation
Spell Check API v7 reference
1. Azureアカウントを作成する
microsoftアカウントが必要かもしれないです。私はログインした後にAzureアカウントの作成をしました。
初回は、クレジットカードの連携が必要のようです。12ヶ月間基本無料+200USD分のクレジットが与えられ、無料期間が終了した後自動課金とはならないということで、さくっと作成しましょう。
Azure portal に入れることを確認する
GCPやAWSのように、Azureを試すポータル(コンソール)に入れることを確認します。
2. Azureリソースを作成する
portalのサービス検索窓から「Bing」と検索し、 Bing Search リソース を選択して作成します。
※Bing Spell Check APIは、Bing Search v7 リソースで提供されています。
よくわからないので、東京(東)リージョンで、一番小さな課金額にしてリソースを作成します。
3. jupyterでコーディング
python3系でjupyterを作成します。
クイックスタートのページ通りにやっているのですが、非常に解読がむずかしかったです。どうやらクイックスタートの情報は古いらしく、ジャンプした先のページも古いらしく、いろいろ悩みまくった結果をメモしておきます。
3-1. Spell Check API Key の取得
手順「2. Azureリソースを作成する」で作ったBingリソース画面上部から「キーの管理」または、左のメニューバーから「キーとエンドポイント」を選択します。
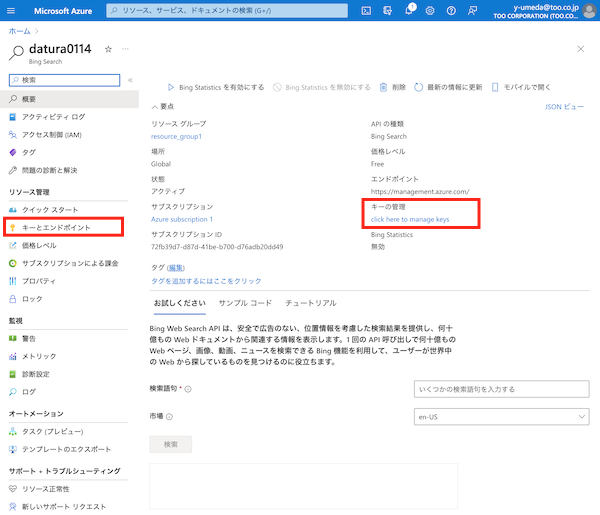
キー1 または キー2 をコピーします。これがAPI_KEYになります。
※ちなみに、1でも2でも、どちらでも動きました。
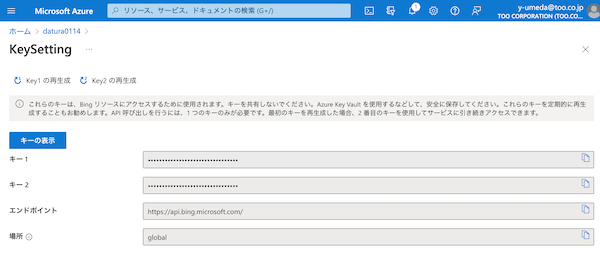
3-2. ENDPOINTの取得
SpellCheckはAzureの中でも移動が多く、Qiita一番上のクイックスタート情報は少し古かったです。
- 最初は専用のEndopointが用意されていたが
- Bingリソースの中で管理されるようになり、特にBing Searchの中で管理されることとなって
- さらにv5.0まではエンドポイントURLに
/bingがついていたところ、v7.0では削除され、 - さらにさらにv5.0のサブドメイン
cognitibeから、v7.0サブドメインbingに変更になった
ということでした。難しい〜〜〜。
Bing Web Search API v5 から v7 へのアップグレード
上記ページではsearch(web検索)APIのエンドポイントが記載されていますが、今回使いたいのはSpellCheckですので、新しいエンドポイントはhttps://api.bing.microsoft.com/v7.0/SpellCheckとなります。
(Spell Check API v7 reference)
3-3. python jupyter
python3系でjupyter notebookを立ち上げます。
古いクイックスタートの情報を参考にしながら、下記コードを書きます。
API_KEYには 3-1で入手したキー1またはキー2を記載してください。
import requests
import json
API_KEY = <yourkey>
ENDPOINT = "https://api.bing.microsoft.com/v7.0/spellcheck"
example_text = "Hollo, wrld"
data = {'text': example_text}
params = {
'mkt':'en-us',
'mode':'proof'
}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Ocp-Apim-Subscription-Key': API_KEY,
}
mktとはmarket codeのことで、使用する言語を指定できます。(Market and language codes used by Bing Spell Check API)
modeは、2つの校正モード(proofとspell)があります。ドキュメントの校正として用意されているものはproofで最も包括的なチェックが行われるそうです。大文字と小文字の修正、基本的な句読点の調整、ドキュメントの作成を支援するその他の校正が提供されています。ただし、言語に縛りがあり、「en-us(英語-米国)、es-es(スペイン語)、pt-br(ポルトガル語)」のみで使用できるそうです。
その他の言語では、spellモードが使用でき、単語のスペルミスのみ指摘可能です。proofモードで可能な文法エラー(大文字小文字エラーや単語の繰り返し表現など)は指摘できません。
(参考:古いドキュメント)
とあるのですが、今の所サンプルのproofモードで英語飲み成功しており、spell-日本語は失敗しています。むむむ。
実行セル
response = requests.post(ENDPOINT, headers=headers, params=params, data=data)
json_response = response.json()
print(json.dumps(json_response, indent=4))
結果
{
"_type": "SpellCheck",
"flaggedTokens": [
{
"offset": 0,
"token": "Hollo",
"type": "UnknownToken",
"suggestions": [
{
"suggestion": "Hello",
"score": 0.9170514570613154
},
{
"suggestion": "Hollow",
"score": 0.7531034639929816
}
]
},
{
"offset": 7,
"token": "wrld",
"type": "UnknownToken",
"suggestions": [
{
"suggestion": "world",
"score": 0.9170514570613154
}
]
}
]
}
👏👏👏
日本語ができない
ハンガリー語でもできないし、公式も強制クローズしているからウーン・・・
https://github.com/Azure/azure-sdk-for-python/issues/25073