過去記事でも書きましたが、しばらく前に担当した案件で、ラズパイ(Raspberry Pi 4 Model B)でAI外観検査システムを3日で作りました。
かかった経費(人件費除く)は、3万円以下!(ちなみに、一般的な外観検査装置を購入すると数十万円~百万円以上かかります。)
自作すれば予算の少ない小規模の工場でも外観検査を自動化できると思うので、私がAI外観検査システムを作成した時の手順を解説します!
(※今回、記事に掲載する写真を撮るために、自宅で改めて同じものを作ってしまいました!)
AI外観検査システム概要図
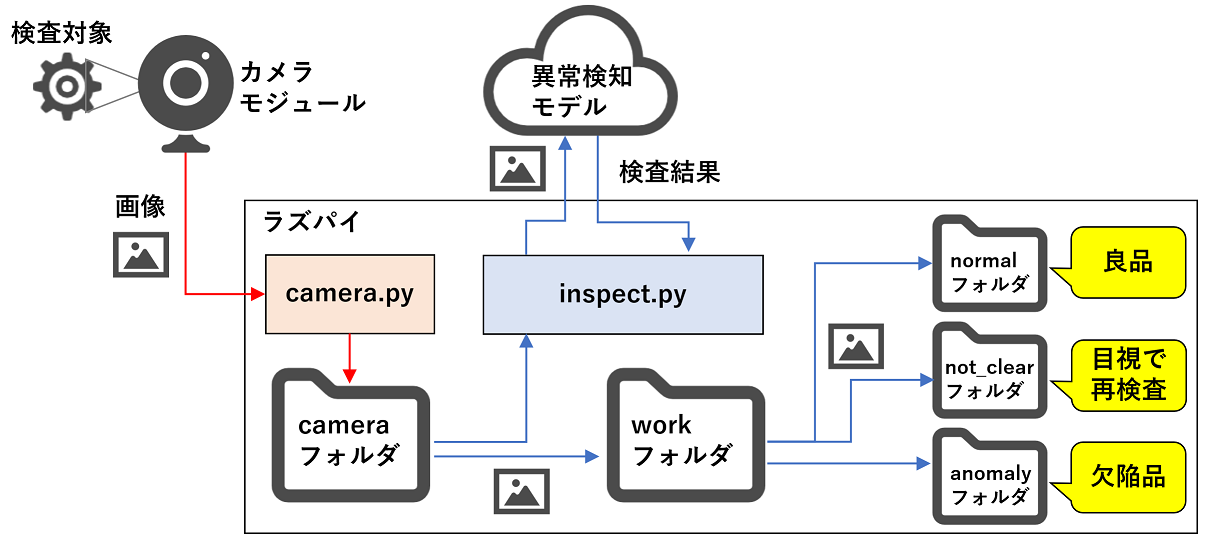
全体像
工場で生産する部品や製品などをカメラで撮影し、3パターン(良品、目視で再検査、欠陥品)に判定するシステムを作成します。
生産ラインにインラインで組み込めば、全数検査の自動化も実現可能です。
必要なもの
- ラズベリーパイ(「Raspberry Pi 4」など):約1万円
- カメラモジュール (「Kuman カメラモジュール Raspberry Pi用」など):約4千円
- microSDカード:約3千円
- HDMI-マイクロHDMIケーブル:約2千円
- ディスプレイ (※この記事では自宅にあったものを利用)
- マウス (※この記事では自宅にあったものを利用)
- キーボード (※この記事では自宅にあったものを利用)
- トリガーセンサー(※インラインで組み込む場合は必要):約4千円
※ラズベリーパイが用意できない場合は、Pythonが実行可能なPC(ノートPC等)+USBカメラ等で代用できます。その場合は「ラズベリーパイのセットアップ」の手順を飛ばして、「外観検査システムの作成」の手順からスタートしてください。

全体の流れ
- ラズベリーパイのセットアップ
(1) OSのインストール
(2) ラズベリーパイ本体の起動
(3) OSの初期設定
(4) カメラモジュールの接続
(5) カメラモジュールの設定確認 - 外観検査システムの作成
(1) カメラ画像取得プログラムの作成
(2) 画像検査プログラムの作成
(3) 異常検知AIの作成
(4) 動作確認
ラズベリーパイのセットアップ
OSのインストール
(1) Raspberry Pi公式サイトから「Raspberry Pi Imager」をダウンロードして、PCにインストールします。
(2) PCにmicroSDカードをセットします。今回は容量が32GBのmicroSDカードにしました。
(3)「Raspberry Pi Imager」にて、microSDカードにOSをインストールします。
- 「Raspberry Pi Imager」を起動し、「OSを選ぶ」を押し、メニューの中からOSを選択します。今回は「Raspberry Pi OS(other)」内の「Raspberry Pi OS(64-bit)」を選択しました。
- 「Raspberry Pi Imager」の「ストレージを選ぶ」を押し、microSDカードを選択します。
- 「Raspberry Pi Imager」の「書き込む」を押し、イメージファイルの書き込みが完了するまで待ちます。
- 書き込みが完了したら、PCからmicroSDカードを取り出します。
ラズベリーパイ本体の起動
(1) ラズベリーパイ本体の裏面のSDカードスロットにmicroSDカードを差し込みます。

(2) ラズベリーパイ本体に、キーボード、マウス、ディスプレイを接続します。

(3) ラズベリーパイ本体に、電源ケーブルを接続します。ラズベリーパイには電源スイッチは無く、電源ケーブルを接続すると自動で起動します。起動まで時間がかかるので、しばらく待ちます。
OSの初期設定
(1) ディスプレイに、設定画面が表示されたら、右下の「Next」を押します。
(2) 「Set Country」の画面では、国・言語・タイムゾーンを選択した後、「Next」を押します。日本で利用するため「Japan」「Japanese」「Tokyo」を選択しました。

(3) ユーザー名とパスワードを設定します。「Confirm password」にパスワード確認のために再度パスワードを入力してから、「Next」を押してください。
(4) ディスプレイの表示サイズが合ってない場合(画面外側に黒い領域がある場合)は、チェックしてください。画面表示に問題なければ「Next」を押してください。
(5) 現在利用できるWiFi(無線LAN)が表示されます。利用するWiFiを選択して「Next」を押し、次の画面でWiFiのパスワードを入力してください。
(6) アップデートの画面では「Next」を押してください。アップデートが完了するまで、けっこう時間がかかります。完了したら、「Restart」を押して再起動させてください。
(7) 再起動すると「Raspberry Pi OS」のデスクトップ画面が表示されます。Windowsのようにマウスで操作できます。
(私の時は、再起動後、しばらく待ってもディスプレイに何も表示されませんでしたが、HDMIのケーブルを抜き差ししたらデスクトップ画面が表示されました。)
(8) インターネットに接続できるか確認します。左上の青いアイコンを押してください。

(9) ブラウザが起動します。お好きなWEBサイトのURLを入れてインターネットに接続できばOKです。
(10) 画面左上のラズベリーのアイコンを押して、メニュー内の「ログアウト」を押します。

(9) ポップアップウィンドウの「Shutdown」を押して、OSを一旦停止します。これで初期設定は完了です。
カメラモジュールの接続
(1) カメラモジュールをリボンケーブルでラズベリーパイ本体に接続します。まずは、カメラモジュールのコネクタの黒い箇所の両端を引っ張り、リボンケーブルを差し込む隙間を作ります。

(2) コネクタにリボンケーブルを差し込んだ状態(①)で、黒い箇所の両端を押し込みます(②)。リボンケーブルが固定されていることを確認します。

(3) 次に、ラズベリーパイ本体のコネクタにリボンケーブルを差し込みます。先ほどと同様に、一度コネクタの両端を引っ張って隙間を作ってからケーブルを差し込み、その状態のまま、コネクタの両端を押し込んでケーブルを固定してください。下の写真の赤丸がカメラモジュール用のコネクタです。

(4) カメラモジュールの接続が完了したら、ラズベリーパイに電源ケーブルを差し込み、OSを起動します。
カメラモジュールの設定確認
(1) デスクトップ左上のラズベリーのアイコンを押してます。メニューボタンから「設定」⇒「Raspberry Piの設定」を選択し、「Raspberry Piの設定」画面を開きます。
(2) 「インターフェイス」タブをクリックし、「カメラ」が「有効」になっていることを確認します。もし「無効」の場合は「有効」を選択して「OK」ボタンを押してください。「カメラ」の項目自体が無い場合は、以降の(3)~(9)の手順を実行してください。(最新バージョンのOS「bullseye」では、「カメラ」の項目がありません。)
(3) 上部のアイコンからターミナルを開きます。
(4) 下記コマンドをターミナルに入力してEnterを押します。
sudo raspi-config
(5) 「3 Interface Options」を選択してEnterを押します。

(4) 「I1 Legacy Camera Enable/disable legacy camera support」を選択して、Enterを押します。

(5) 「はい」を選択してEnterを押します。

(6) 「了解」を選択してEnterを押します。

(7) 「Finish」を選択してEnterを押します。

(8) 「はい」を選択してOSを再起動します。再起動するとカメラが有効化されます。

(9) OS再起動後、ターミナルを起動して下記コマンドを入力します。「supported=1 detected=1」または「supported=1 detected=1, libcamera interfaces=0」と表示されることを確認します。これでカメラの準備は完了です。
vcgencmd get_camera
外観検査システムの作成
続いて、外観検査システムを作成します。
システム概要
この外観検査システムは、「camera.py」「inspect.py」の2つのプログラムで構成されています。
camera.py:カメラ画像取得プログラム。カメラモジュールで撮影した検査対象の画像を「camera」ディレクトリに保存。
inspect.py:画像検査プログラム。「camera」ディレクトリ内の画像を検査。判定結果に応じて、3つのディレクトリに画像を振り分け。
カメラ画像取得プログラムの作成
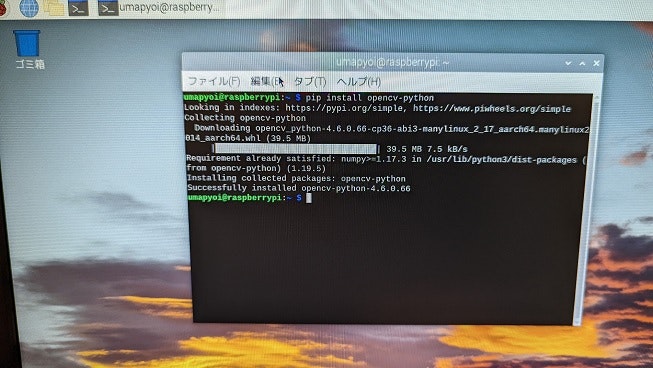
(1) ターミナルを開いて、下記コマンドを入力してください。OpenCVのライブラリをインストールします。最終行に「Successfully installed opencv-python-(バージョンの番号)」が表示されればインストール成功です。
pip install opencv-python
(2) 「Thonny Python IDE」を使ってPythonプログラムを作成します。左上のラズベリーアイコンを押して、メニューの「プログラミング」⇒「Thonny Python IDE」を選択してください。
(3) Thonnyが起動します。上半分の「<untitled>」と書いてあるエリアが、Pythonのプログラムを入力する場所です。

(4) 下記のプログラムをコピー&ペーストしてください。そして、上部の「Save」アイコンを押します。ここでは「camera.py」という名前を設定して、Desktopのディレクトリ内に保存しましょう。
import cv2
import datetime
import os
# カメラ映像から画像を取得
def save_camera_image(device_num, dir_path, basename, cycle=-1, ext='png', delay=1, window_name='camera', width=480, height=480):
cap = cv2.VideoCapture(device_num)
# 画像サイズの指定
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
if not cap.isOpened():
return
os.makedirs(dir_path, exist_ok=True)
base_path = os.path.join(dir_path, basename)
n = 0
c = 0
while True:
ret, frame = cap.read()
cv2.imshow(window_name, frame)
key = cv2.waitKey(delay) & 0xFF
# キーボードのqを押すと終了
if key == ord('q'):
break
# キーボードのcを押すと手動で画像を取得
if key == ord('c'):
img_path = '{}_{}.{}'.format(base_path, c, ext)
cv2.imwrite(img_path, frame)
print(img_path)
c += 1
if n == cycle:
n = 0
img_path = '{}_{}.{}'.format(base_path, datetime.datetime.now().strftime('%Y%m%d%H%M%S%f'), ext)
cv2.imwrite(img_path, frame)
print(img_path)
n += 1
# 生産ラインにインラインで組み込む場合、
# ここに生産ラインに設置したトリガーとなる機器(光電センサー等)の信号を受信する処理を追加してください。
#if 信号を受信した場合:
# img_path = '{}_{}.{}'.format(base_path, c, ext)
# cv2.imwrite(img_path, frame)
# print(img_path)
# c += 1
cv2.destroyWindow(window_name)
# main
def main():
save_dir = 'camera'
save_camera_image(0, save_dir, 'camera_capture')
if __name__ == '__main__':
main()
(5) デスクトップ上に「camera.py」が作成されたら、Thonnyの上部の「Run」アイコンを押します。すると、プログラムが実行されます。
キーボードの「c」を押すと、デスクトップに作成された「camera」フォルダ内にキャプチャした画像が保存されます。キーボードの「q」を押すと、プログラムを終了します。
もし工場の生産ラインにインラインで組み込みたい場合は、「save_camera_image」メソッドの後半のコメントアウトを外して、センサーの信号を受信する処理を追加してください。
画像検査プログラムの作成
(1) Thonnyの左上の「New」アイコンを押して、画像検査プログラムを作成します。上半分の「<untitled>」と書いてあるエリアに下記のコードをコピー&ペーストしてください。(インラインで利用する場合は、プログラム後半の「num_process」の値を5~10くらいに増やしてください。)
import glob
import os
import requests
import shutil
import time
from io import BytesIO
from multiprocessing import Process
from PIL import Image
# 画像検査メソッド
def inspect_image(work_dir, api_url, api_info_dict, input_dir, normal_dir="normal", not_clear_dir="not_clear", anomaly_dir="anomaly"):
loop_count = 0
while True:
# 1秒に1回実行
time.sleep(1)
# 未検査ディレクトリから作業ディレクトリに画像を移動
images = glob.glob(input_dir + "/*.png") + glob.glob(input_dir + "/*.jp*g")
if len(images) > 0:
if os.path.exists(images[0]):
# ディレクトリが存在しなければ作成
if not os.path.isdir(work_dir):
os.makedirs(work_dir)
try:
# 1枚目の画像を移動
image_path = shutil.move(images[0], work_dir + "/")
filename = os.path.basename(images[0])
# 画像を読み込み
img = Image.open(image_path)
# ADFIのAPIサンプルコードを流用
MAX_SIZE = 800
height = img.height
width = img.width
if (img.height > MAX_SIZE):
height = MAX_SIZE
if (img.width > MAX_SIZE):
width = MAX_SIZE
img = img.resize((width, height), Image.ANTIALIAS)
img_bytes = BytesIO()
img.save(img_bytes, format="PNG")
img_bytes = img_bytes.getvalue()
files = {"image_data": (filename, img_bytes, "image/png")}
# APIリクエストを送信
response = requests.post(api_url, files=files, data=api_info_dict)
# APIリクエストが成功した場合
if(response.status_code == 200):
result_json = response.json()
# 異常の場合、メッセージを表示
if "Anomaly" in result_json["result"]:
print(result_json["result"] + " (異常): " + filename)
# ディレクトリが存在しなければ作成
if not os.path.isdir(anomaly_dir):
os.makedirs(anomaly_dir)
# 検査した画像を移動
shutil.move(image_path, anomaly_dir + "/")
# 画像を読み込み
result_img = Image.open(anomaly_dir + "/" + filename)
# OS標準の画像ビューアで表示
result_img.show()
# 不明の場合、メッセージを表示
elif "Not-clear" in result_json["result"]:
print(result_json["result"] + " (不明): " + filename)
# ディレクトリが存在しなければ作成
if not os.path.isdir(not_clear_dir):
os.makedirs(not_clear_dir)
# 検査した画像を移動
shutil.move(image_path, not_clear_dir + "/")
# 画像を読み込み
result_img = Image.open(not_clear_dir + "/" + filename)
# OS標準の画像ビューアで表示
result_img.show()
# 正常の場合、メッセージを表示
else:
print(result_json["result"] + " (正常): " + filename)
# ディレクトリが存在しなければ作成
if not os.path.isdir(normal_dir):
os.makedirs(normal_dir)
# 検査した画像を移動
shutil.move(image_path, normal_dir + "/")
# APIリクエストが失敗した場合
else:
print("画像を送信できませんでした: " + filename)
# 画像を元のディレクトリに戻す
shutil.move(image_path, input_dir + "/")
time.sleep(10)
except:
pass
else:
loop_count += 1
if loop_count % 10 == 0:
print("検査対象の画像がありません: " + input_dir)
loop_count = 0
if __name__ == '__main__':
# ADFI(https://adfi.jp/ja)で作成した異常検知モデルのAPI情報をここに設定してください
apikey = "" # 設定要
aimodel_id = "" # 設定要
model_type = "" # 設定要
# ADFIのAPIのURL
api_url = "https://us.adfi.karakurai.com/API/ap/api/apidata/"
# 検査対象画像のディレクトリ
input_dir = "camera"
# 検査対象後に画像を移動するディレクトリ
normal_dir = "normal"
not_clear_dir = "not_clear"
anomaly_dir = "anomaly"
# 並列プロセス実行数(※通常は1にする。インラインで大量に検査する場合はプロセス数を増やす。)
num_process = 1
api_info_dict = {"apikey": apikey, "aimodel_id": aimodel_id, "model_type": model_type}
process_list = []
for i in range(num_process):
work_dir = "work_dir_" + str(i)
process = Process(
target=inspect_image,
args=(work_dir, api_url, api_info_dict, input_dir, normal_dir, not_clear_dir, anomaly_dir)
)
process.start()
process_list.append(process)
time.sleep(1/num_process)
print("Process: ", process_list)
(2) 「Save」アイコンを押します。ここでは「inspect.py」という名前を設定して、Desktopのディレクトリ内に保存しましょう。
異常検知AIの作成
今回、異常検知AI作成プラットフォーム「ADFI」を利用して、異常検知モデルを作成します。
(1) まずは異常検知モデル作成に必要な学習データを撮影します。工場の生産ラインなど、実際に外観検査を行う場所にカメラモジュールを設置してください。(学習データを撮影する環境と実際に検査を行う環境が異なると検査精度が悪くなるため、学習データを撮影する時点で、カメラを工場の現場に設置する必要があります。)
(2) ターミナルを起動して下記コマンドを実行してカメラ画像取得プログラムを起動します。
python Desktop/camera.py
(3) 検査対象の画像を撮影します。正常画像(良品の画像)を50枚以上、異常画像(欠陥品の画像)を10枚以上、撮影しましょう。
(4) 撮影した画像を使って、ADFIで異常検知モデルを作成します。
ADFIの操作手順は、下記の過去記事を参照してください。
(5) ADFIで異常検知モデルを作成できたら、inspect.pyの104行目から106行目(下図赤枠の部分)にADFIのAPI情報(API Key、AI Model ID、Model Type)を入力してください。
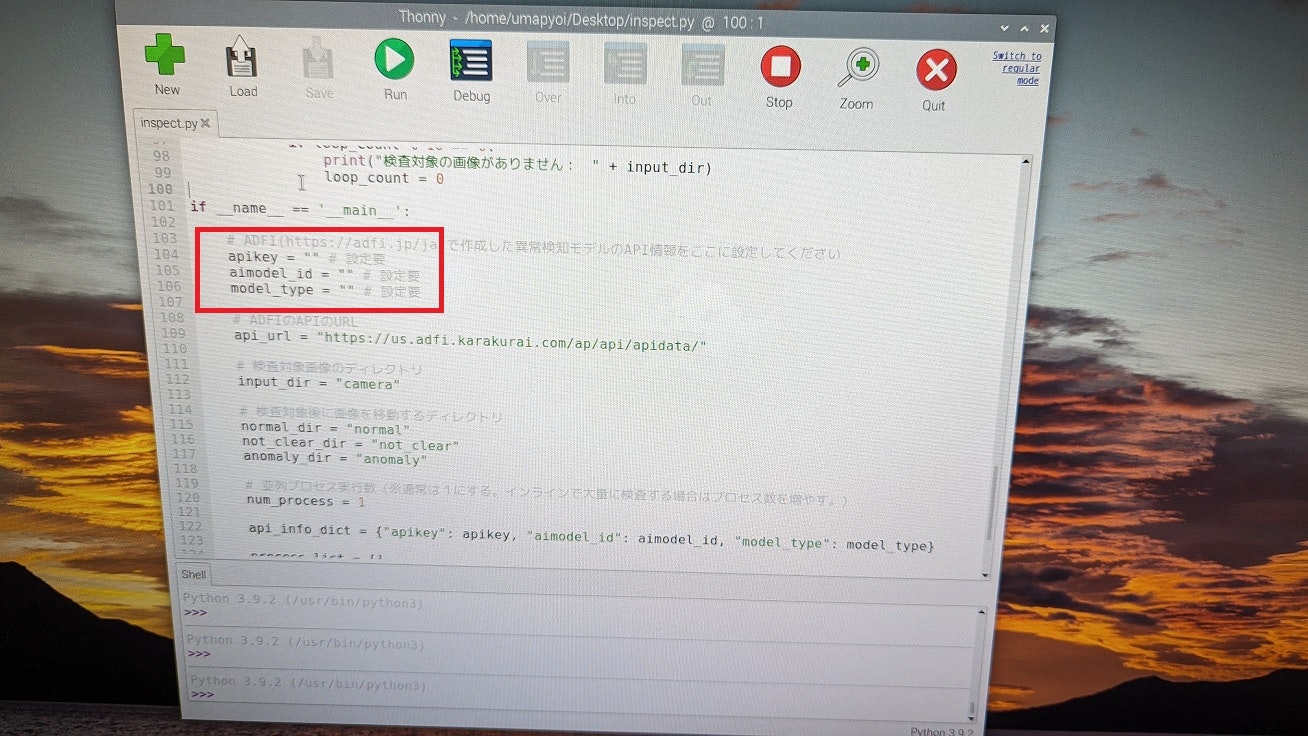
ADFIのAPI情報(API Key、AI Model ID、Model Type)はAPIタブの下図赤枠の部分に記載されています。
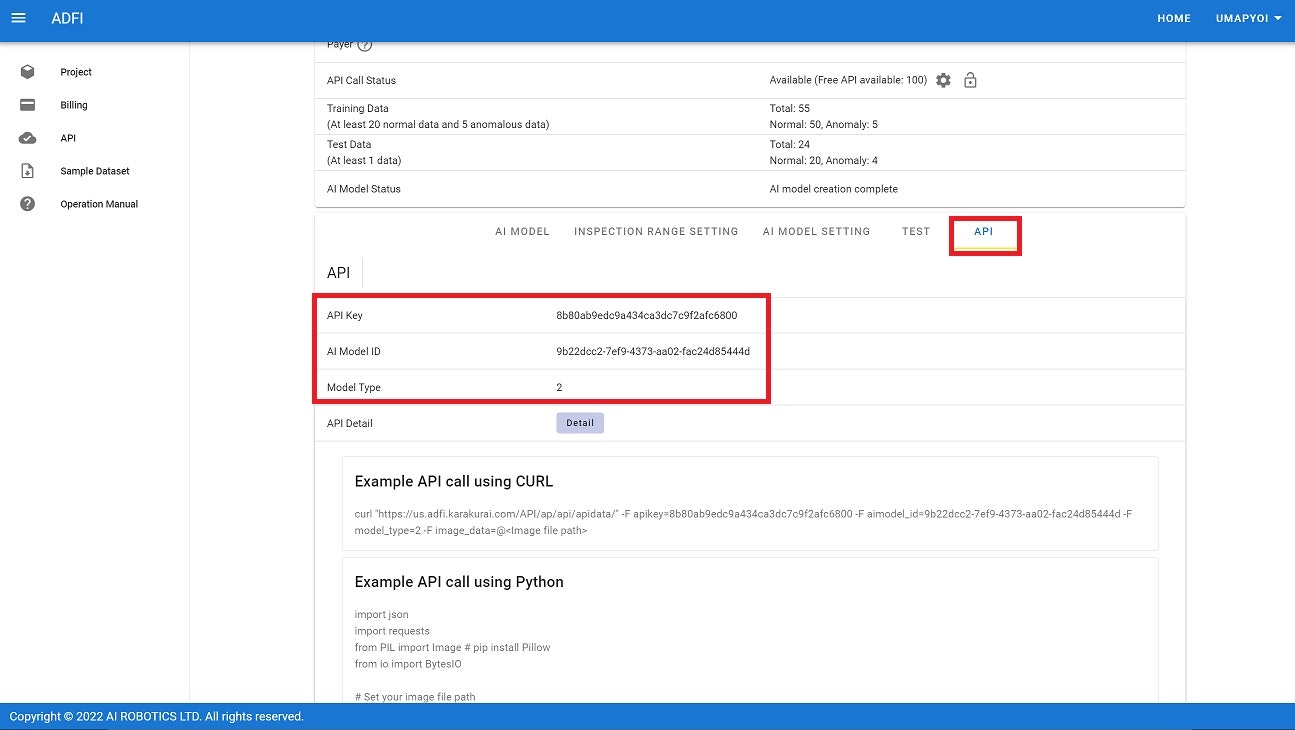
下図はAPI情報入力後のinspect.pyの画像です。

動作確認
異常検知モデルの作成が終わったら、動作確認をしましょう。
デスクトップ上の「camera」ディレクトリの中に、撮影した画像が入っている状態で、inspect.pyを実行して(「Run」アイコンを押して)ください。
「camera」ディレクトリ内の画像を検査し、検査結果に応じて「normal」「anomaly」「not_clear」のフォルダに画像を振り分けます。(さらに、「anomaly」「not_clear」だった場合は、画像ファイルを開きます。)

実際に外観検査を行う際は、ターミナルを2つ起動して下記コマンドで「camera.py」「inspect.py」を実行してください。
python Desktop/camera.py
python Desktop/inspect.py

まとめ
ラズパイとカメラを使って、自作でAI外観検査システムを超速で作れました!
かかった費用は3万円以下なので、低予算でも外観検査を自動化できそうですね!
今回は仕事でラズパイを使ってシステムを作りましたが、次回はラズパイで趣味のシステムでも作ってみたいと思います。
関連記事