まえがき
マイナビ出版のビッグデータ分析・活用のためのSQLレシピp400あたりに
アソシーエーション分析という言葉がありました。
以下引用です。
『本来のアソシエーション分析は「商品の組み合わせ(A,B,C,・・・)を買った人のn%は、商品の組み合わせ(X,Y,Z,・・・)を買う」など、商品の組み合わせに関するルールも発見できる汎用的なアルゴリズムですが、完全なアソシエーション分析には再帰的な繰り返し処理が必要となるため、、』
そこで、ひとまず再帰的に商品の組み合わせを求めることができないかと思い、sql書いてみました。
【データ投入】
DROP TABLE purchase_detail_log;
CREATE TABLE purchase_detail_log(
stamp varchar(255)
, logsession varchar(255)
, purchase_id integer
, product_id varchar(255)
);
INSERT ALL
INTO purchase_detail_log VALUES('2016-11-03 18:10', '989004ea', 1, 'D001')
INTO purchase_detail_log VALUES('2016-11-03 18:10', '989004ea', 1, 'D002')
INTO purchase_detail_log VALUES('2016-11-03 20:00', '47db0370', 2, 'D001')
INTO purchase_detail_log VALUES('2016-11-04 13:00', '1cf7678e', 3, 'D002')
INTO purchase_detail_log VALUES('2016-11-04 15:00', '5eb2e107', 4, 'A001')
INTO purchase_detail_log VALUES('2016-11-04 15:00', '5eb2e107', 4, 'A002')
INTO purchase_detail_log VALUES('2016-11-04 16:00', 'fe05e1d8', 5, 'A001')
INTO purchase_detail_log VALUES('2016-11-04 16:00', 'fe05e1d8', 5, 'A003')
INTO purchase_detail_log VALUES('2016-11-04 17:00', '87b5725f', 6, 'A001')
INTO purchase_detail_log VALUES('2016-11-04 17:00', '87b5725f', 6, 'A003')
INTO purchase_detail_log VALUES('2016-11-04 17:00', '87b5725f', 6, 'A004')
INTO purchase_detail_log VALUES('2016-11-04 18:00', '5d5b0997', 7, 'A005')
INTO purchase_detail_log VALUES('2016-11-04 18:00', '5d5b0997', 7, 'A006')
INTO purchase_detail_log VALUES('2016-11-04 19:00', '111f2996', 8, 'A002')
INTO purchase_detail_log VALUES('2016-11-04 19:00', '111f2996', 8, 'A003')
INTO purchase_detail_log VALUES('2016-11-04 20:00', '3efe001c', 9, 'A001')
INTO purchase_detail_log VALUES('2016-11-04 20:00', '3efe001c', 9, 'A003')
INTO purchase_detail_log VALUES('2016-11-04 21:00', '9afaf87c', 10, 'D001')
INTO purchase_detail_log VALUES('2016-11-04 21:00', '9afaf87c', 10, 'D003')
INTO purchase_detail_log VALUES('2016-11-04 22:00', 'd45ec190', 11, 'D001')
INTO purchase_detail_log VALUES('2016-11-04 22:00', 'd45ec190', 11, 'D002')
INTO purchase_detail_log VALUES('2016-11-04 23:00', '36dd0df7', 12, 'A002')
INTO purchase_detail_log VALUES('2016-11-04 23:00', '36dd0df7', 12, 'A003')
INTO purchase_detail_log VALUES('2016-11-04 23:00', '36dd0df7', 12, 'A004')
INTO purchase_detail_log VALUES('2016-11-05 15:00', 'cabf98e8', 13, 'A002')
INTO purchase_detail_log VALUES('2016-11-05 15:00', 'cabf98e8', 13, 'A004')
INTO purchase_detail_log VALUES('2016-11-05 16:00', 'f3b47933', 14, 'A005')
select * from dual
;
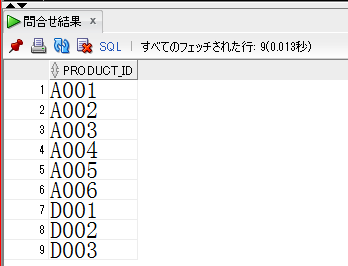
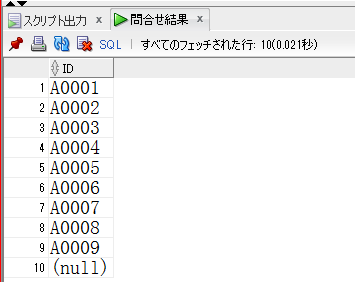
【商品数取得】
select distinct
PRODUCT_ID
from
PURCHASE_DETAIL_LOG
order by
PRODUCT_ID
;
【商品数取得結果】
【やりたいこと】
9つの商品が存在するので、
9つの中から1つ選ぶ組み合わせ
9つの中から2つ選ぶ組み合わせ
9つの中から3つ選ぶ組み合わせ
9つの中から4つ選ぶ組み合わせ
9つの中から5つ選ぶ組み合わせ
9つの中から6つ選ぶ組み合わせ
9つの中から7つ選ぶ組み合わせ
9つの中から8つ選ぶ組み合わせ
9つの中から9つ選ぶ組み合わせ
のすべての事象を一覧化したい
メイン処理
select
sub.*
from
(
with rec (
flg
,prod1
,prod2
,prod3
,prod4
,prod5
,prod6
,prod7
,prod8
,prod9
)as(
select distinct
1
,product_id
,nvl(null,' ')
,nvl(null,' ')
,nvl(null,' ')
,nvl(null,' ')
,nvl(null,' ')
,nvl(null,' ')
,nvl(null,' ')
,nvl(null,' ')
from
purchase_detail_log
union all
select
rec.flg + 1
,rec.prod1
,case when rec.flg + 1 = 2 then src.product_id else nvl(rec.prod2,' ') end
,case when rec.flg + 1 = 3 then src.product_id else nvl(rec.prod3,' ') end
,case when rec.flg + 1 = 4 then src.product_id else nvl(rec.prod4,' ') end
,case when rec.flg + 1 = 5 then src.product_id else nvl(rec.prod5,' ') end
,case when rec.flg + 1 = 6 then src.product_id else nvl(rec.prod6,' ') end
,case when rec.flg + 1 = 7 then src.product_id else nvl(rec.prod7,' ') end
,case when rec.flg + 1 = 8 then src.product_id else nvl(rec.prod8,' ') end
,case when rec.flg + 1 = 9 then src.product_id else nvl(rec.prod9,' ') end
from
rec
inner join
(
select distinct
product_id
from
purchase_detail_log
) src
on
(--TorU
case
when--1回目のループ(9つの中から2つ選ぶの組み合わせ)
rec.flg = 1 then rec.prod1
when--2回目のループ(9つの中から3つ選ぶの組み合わせ)
rec.flg = 2
and rec.prod1 < rec.prod2 then rec.prod2
when--3回目のループ(9つの中から4つ選ぶの組み合わせ)
rec.flg = 3
and rec.prod1 < rec.prod2
and rec.prod2 < rec.prod3 then rec.prod3
when--4回目のループ(9つの中から5つ選ぶの組み合わせ)
rec.flg = 4
and rec.prod1 < rec.prod2
and rec.prod2 < rec.prod3
and rec.prod3 < rec.prod4 then rec.prod4
when--5回目のループ(9つの中から6つ選ぶの組み合わせ)
rec.flg = 5
and rec.prod1 < rec.prod2
and rec.prod2 < rec.prod3
and rec.prod3 < rec.prod4
and rec.prod4 < rec.prod5 then rec.prod5
when--6回目のループ(9つの中から7つ選ぶの組み合わせ)
rec.flg = 6
and rec.prod1 < rec.prod2
and rec.prod2 < rec.prod3
and rec.prod3 < rec.prod4
and rec.prod4 < rec.prod5
and rec.prod5 < rec.prod6 then rec.prod6
when--7回目のループ(9つの中から8つ選ぶの組み合わせ)
rec.flg = 7
and rec.prod1 < rec.prod2
and rec.prod2 < rec.prod3
and rec.prod3 < rec.prod4
and rec.prod4 < rec.prod5
and rec.prod5 < rec.prod6
and rec.prod6 < rec.prod7 then rec.prod7
when--8回目のループ(9つの中から9つ選ぶ組み合わせ)
rec.flg = 8
and rec.prod1 < rec.prod2
and rec.prod2 < rec.prod3
and rec.prod3 < rec.prod4
and rec.prod4 < rec.prod5
and rec.prod5 < rec.prod6
and rec.prod6 < rec.prod7
and rec.prod7 < rec.prod8 then rec.prod8
else null--10回目のループはunknownで評価対象外とする
end < src.product_id
)
)
select
flg
,row_number() over (
partition BY flg
order by
prod1
,prod2
,prod3
,prod4
,prod5
,prod6
,prod7
,prod8
,prod9
) as rn
,prod1
,prod2
,prod3
,prod4
,prod5
,prod6
,prod7
,prod8
,prod9
from
rec
) sub
order by
sub.flg
,sub.rn
;
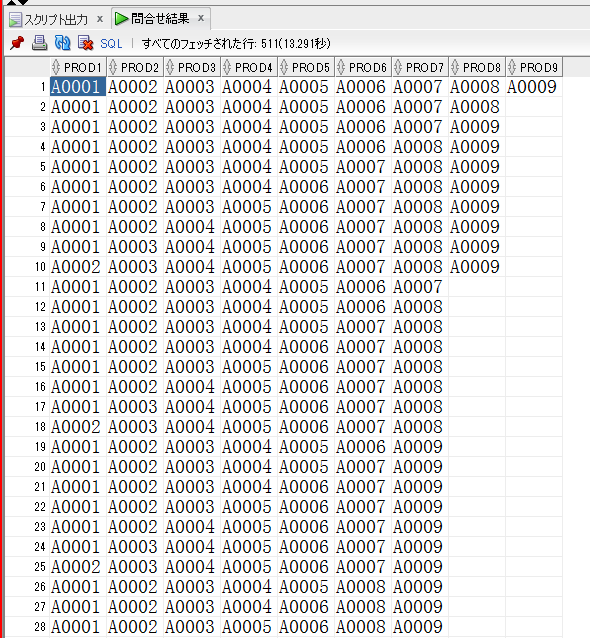
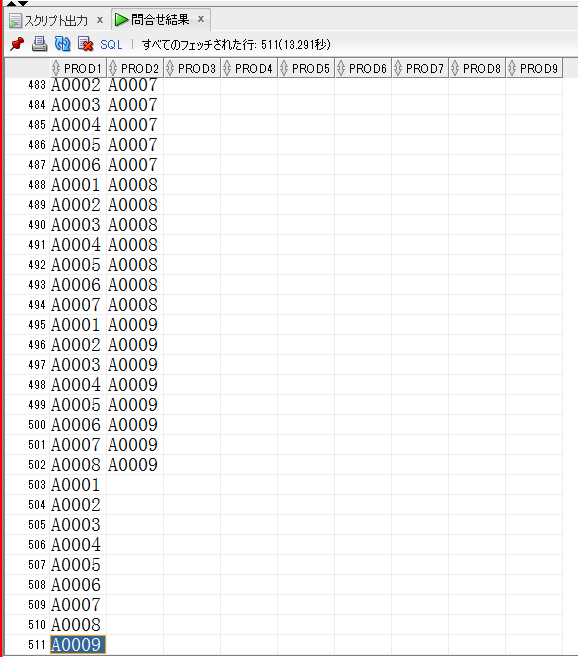
【組み合わせ取得結果(一部抜粋)】
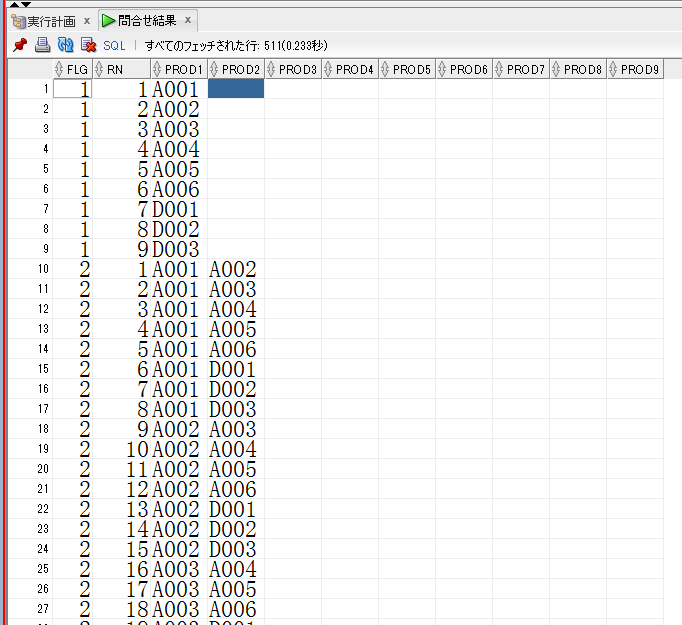
・
・
・
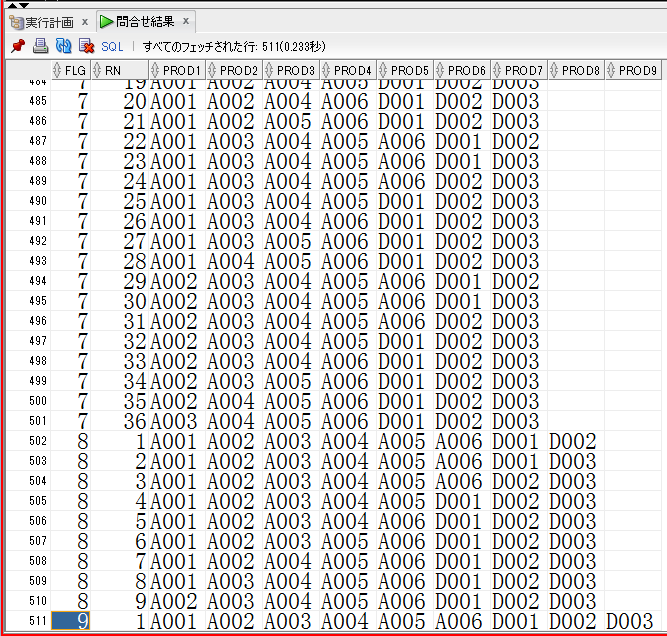
【計算式】
9C1 = 9
9C2 = 36
9C3 = 84
9C4 = 126
9C5 = 126
9C6 = 84
9C7 = 36
9C8 = 9
9C9 = 1
1 + (9 + 36 + 84 + 126) * 2
= 1 + 510
= 511
合ってそう!!
【振り返り】
商品数の数だけsqlメンテしないといけないところ。。
もっといい書き方あれば、共有していただきたいです。。
以上、ありがとうございました。
20180906追記
@tlokweng さんが
スマートな組み合わせの求め方をご教示してくださったので、
追記したいと思います。
@tlokweng さん、ありがとうございます。
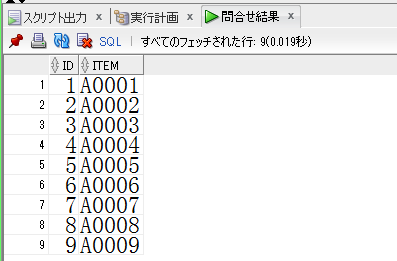
drop table test_tbl;
create table test_tbl (id,item) as (
select 1 ,'A0001' from dual union all
select 2 ,'A0002' from dual union all
select 3 ,'A0003' from dual union all
select 4 ,'A0004' from dual union all
select 5 ,'A0005' from dual union all
select 6 ,'A0006' from dual union all
select 7 ,'A0007' from dual union all
select 8 ,'A0008' from dual union all
select 9 ,'A0009' from dual
)
;
【init.sqlの実行結果】
WITH recur (
lv
, target
, list
) AS (
SELECT
1
, id
, item
FROM
test_tbl
UNION ALL
SELECT
lv + 1--どのパターンの組み合わせかlv擬似列で表現してくださいました
, id
, list
|| ','
|| item
FROM
recur
,test_tbl
WHERE
target < id
) SELECT
rownum--行数をrownum擬似列で表現してくださいました
, lv
, list
FROM
recur
;
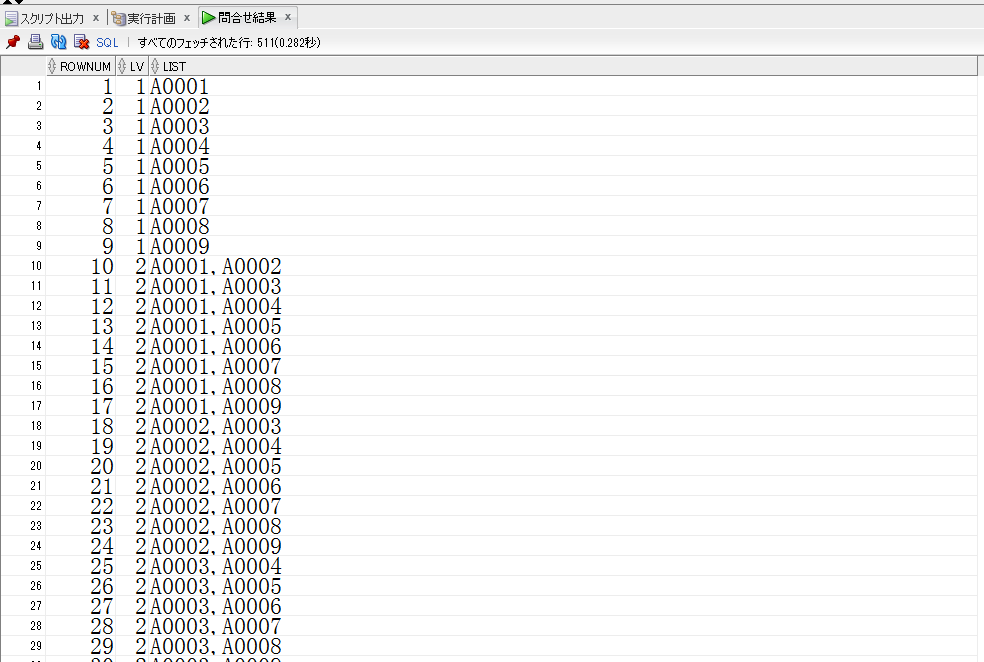
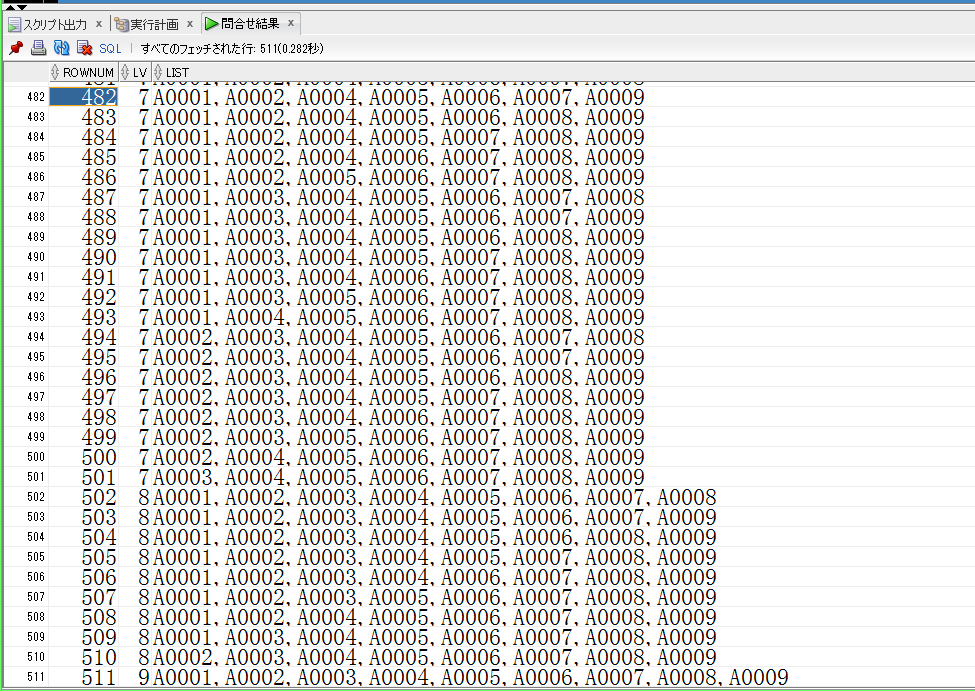
【rec_withの取得結果(一部抜粋)】
・
・
・
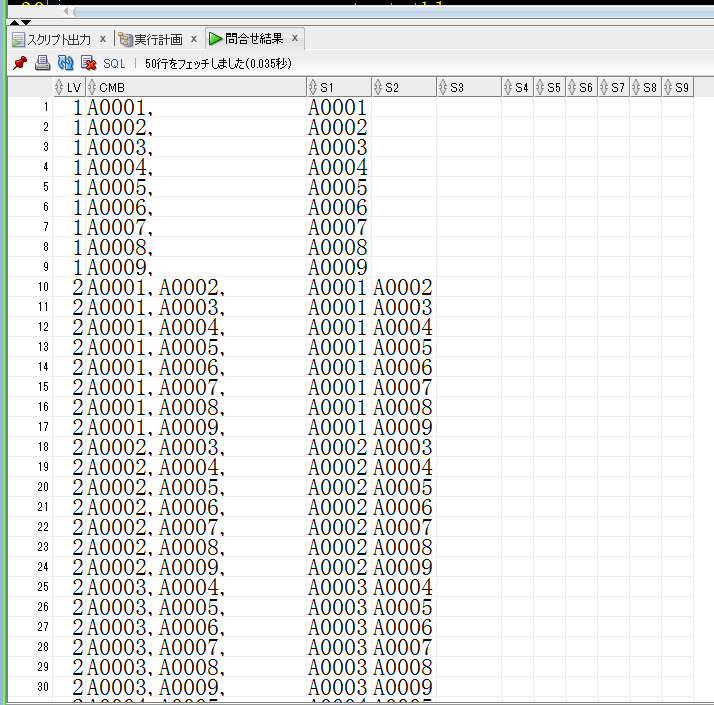
カンマ区切りを列持ちにばらしたいと思います。ばらしてみたくなった。。
select
lv
,cmb
,nvl(substr(cmb, 1, CASE WHEN instr(cmb,',',1,1) <> 0 THEN instr(cmb,',',1,1) - 1 ELSE NULL END),' ') AS s1
,nvl(substr(cmb, instr(cmb,',',1,1) + 1, CASE WHEN instr(cmb,',',1,2) <> 0 THEN instr(cmb,',',1,2) - instr(cmb,',',1,1) - 1 ELSE NULL END),' ') AS s2
,nvl(substr(cmb, instr(cmb,',',1,2) + 1, CASE WHEN instr(cmb,',',1,3) <> 0 THEN instr(cmb,',',1,3) - instr(cmb,',',1,2) - 1 ELSE NULL END),' ') AS s3
,nvl(substr(cmb, instr(cmb,',',1,3) + 1, CASE WHEN instr(cmb,',',1,4) <> 0 THEN instr(cmb,',',1,4) - instr(cmb,',',1,3) - 1 ELSE NULL END),' ') AS s4
,nvl(substr(cmb, instr(cmb,',',1,4) + 1, CASE WHEN instr(cmb,',',1,5) <> 0 THEN instr(cmb,',',1,5) - instr(cmb,',',1,4) - 1 ELSE NULL END),' ') AS s5
,nvl(substr(cmb, instr(cmb,',',1,5) + 1, CASE WHEN instr(cmb,',',1,6) <> 0 THEN instr(cmb,',',1,6) - instr(cmb,',',1,5) - 1 ELSE NULL END),' ') AS s6
,nvl(substr(cmb, instr(cmb,',',1,6) + 1, CASE WHEN instr(cmb,',',1,7) <> 0 THEN instr(cmb,',',1,7) - instr(cmb,',',1,6) - 1 ELSE NULL END),' ') AS s7
,nvl(substr(cmb, instr(cmb,',',1,7) + 1, CASE WHEN instr(cmb,',',1,8) <> 0 THEN instr(cmb,',',1,8) - instr(cmb,',',1,7) - 1 ELSE NULL END),' ') AS s8
,nvl(substr(cmb, instr(cmb,',',1,8) + 1, CASE WHEN instr(cmb,',',1,9) <> 0 THEN instr(cmb,',',1,9) - instr(cmb,',',1,8) - 1 ELSE NULL END),' ') AS s9
from
(
select
lv
,list || ',' as cmb
from
(
WITH recur (
lv
, target
, list
) AS (
SELECT
1
, id
, item
FROM
test_tbl
UNION ALL
SELECT
lv + 1
, id
, list
|| ','
|| item
FROM
recur
,test_tbl
WHERE
target < id
) SELECT
lv
, list
FROM
recur
) cmb_rec
) cmb_tmp
;
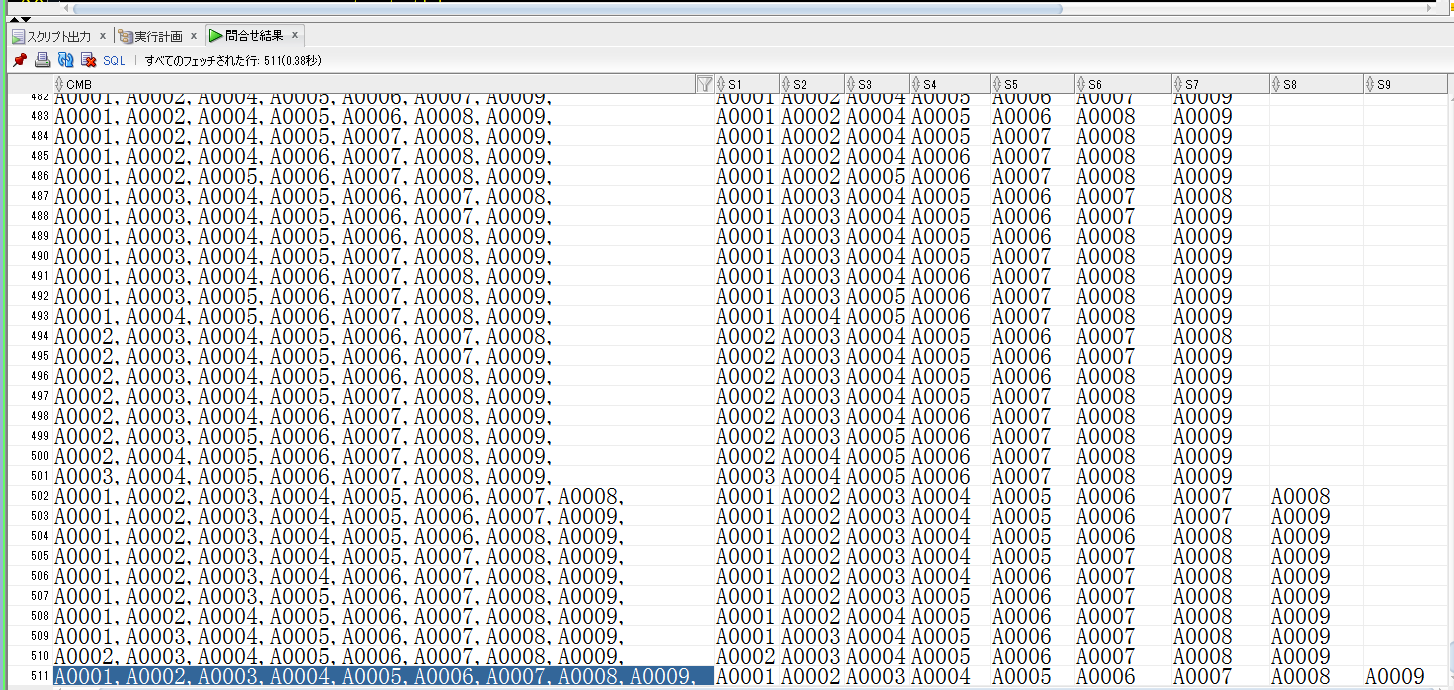
【conv_horizon.sqlの取得結果】
・
・
・
以上、ありがとうございました。
20180914追記
@youmil_rainさんからは
再帰なしでの組み合わせの出し方とビット演算をもちいたやり方をご教示いただきました。
ビット演算を用いた方は私自身の理解がまだ浅いので、今回は再帰なしの方を追記させていただきます。
@youmil_rainさん、ありがとうございます。
@tlokweng さんからは
collectionとtable()のスマートな使い方に加え、カンマ区切りをばらすやり方も
ご教示してくださいました。
@tlokweng さん、ありがとうございます。
まず、@youmil_rainさんの再帰なしでの組み合わせの出し方です。
drop table test_tbl;
create table test_tbl (id,item) as (
select 1 ,'A0001' from dual union all
select 2 ,'A0002' from dual union all
select 3 ,'A0003' from dual union all
select 4 ,'A0004' from dual union all
select 5 ,'A0005' from dual union all
select 6 ,'A0006' from dual union all
select 7 ,'A0007' from dual union all
select 8 ,'A0008' from dual union all
select 9 ,'A0009' from dual
)
;
WITH vals AS (
SELECT
item AS id
FROM
test_tbl
UNION ALL
SELECT
NULL AS id
FROM
dual
) SELECT
pr1.id AS prod1
, coalesce(pr2.id, ' ') AS prod2
, coalesce(pr3.id, ' ') AS prod3
, coalesce(pr4.id, ' ') AS prod4
, coalesce(pr5.id, ' ') AS prod5
, coalesce(pr6.id, ' ') AS prod6
, coalesce(pr7.id, ' ') AS prod7
, coalesce(pr8.id, ' ') AS prod8
, coalesce(pr9.id, ' ') AS prod9
FROM
(
SELECT
*
FROM
vals
WHERE
id IS NOT NULL
) pr1
INNER JOIN vals pr2
ON pr1.id < pr2.id OR pr2.id IS NULL
INNER JOIN vals pr3
ON pr2.id < pr3.id OR pr3.id IS NULL
INNER JOIN vals pr4
ON pr3.id < pr4.id OR pr4.id IS NULL
INNER JOIN vals pr5
ON pr4.id < pr5.id OR pr5.id IS NULL
INNER JOIN vals pr6
ON pr5.id < pr6.id OR pr6.id IS NULL
INNER JOIN vals pr7
ON pr6.id < pr7.id OR pr7.id IS NULL
INNER JOIN vals pr8
ON pr7.id < pr8.id OR pr8.id IS NULL
INNER JOIN vals pr9
ON pr8.id < pr9.id OR pr9.id IS NULL
;
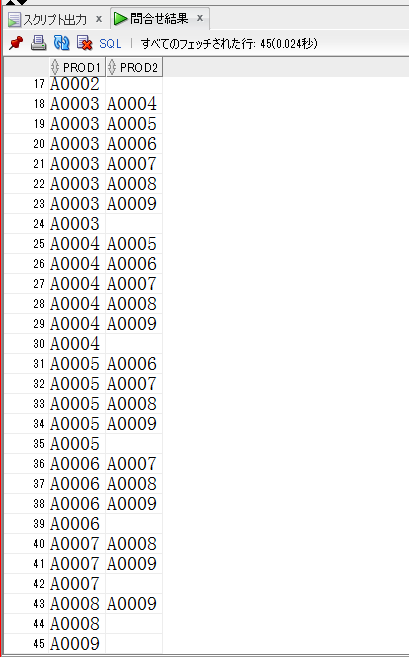
【without_rec.sqlの取得結果(一部抜粋)】
without_rec.sqlの過程を少しづつ追ってみたいとおもいます。
SELECT
item AS id
FROM
test_tbl
UNION ALL
SELECT
NULL AS id
FROM
dual
;
【without_rec_little_by_little_step1.sqlの取得結果】
WITH vals AS (
SELECT
item AS id
FROM
test_tbl
UNION ALL
SELECT
NULL AS id
FROM
dual
) SELECT
pr1.id AS prod1
, coalesce(pr2.id, ' ') AS prod2
-- , coalesce(pr3.id, ' ') AS prod3
-- , coalesce(pr4.id, ' ') AS prod4
-- , coalesce(pr5.id, ' ') AS prod5
-- , coalesce(pr6.id, ' ') AS prod6
-- , coalesce(pr7.id, ' ') AS prod7
-- , coalesce(pr8.id, ' ') AS prod8
-- , coalesce(pr9.id, ' ') AS prod9
FROM
(
SELECT
*
FROM
vals
WHERE
id IS NOT NULL
) pr1
INNER JOIN vals pr2
ON pr1.id < pr2.id OR pr2.id IS NULL
-- INNER JOIN vals pr3
-- ON pr2.id < pr3.id OR pr3.id IS NULL
-- INNER JOIN vals pr4
-- ON pr3.id < pr4.id OR pr4.id IS NULL
-- INNER JOIN vals pr5
-- ON pr4.id < pr5.id OR pr5.id IS NULL
-- INNER JOIN vals pr6
-- ON pr5.id < pr6.id OR pr6.id IS NULL
-- INNER JOIN vals pr7
-- ON pr6.id < pr7.id OR pr7.id IS NULL
-- INNER JOIN vals pr8
-- ON pr7.id < pr8.id OR pr8.id IS NULL
-- INNER JOIN vals pr9
-- ON pr8.id < pr9.id OR pr9.id IS NULL
;
【without_rec_little_by_little_step2.sqlの取得結果】
step3以降も同じ感じで見ていくと、最初のsubqueryのwithでnullを含めたことがわかりました。
要素数をひとつふたつと増やしていく中で、
増やす直前までの組み合わせをor is nullで表現してくださいました。
自身よりも大きいアイテム文字コードを紐付けるのに加え、
要素数を増やす直前までの組み合わせを表現する行だけは
nullで紐付けて残すみたいな感じです。
こういう発想私にはなかったです、、貴重な視点からのコメントありがとうございます。

続きまして@tlokweng さんの
collectionとtable()のを使ったやり方とそのあとカンマ区切りをばらすやり方です。
11gと12cでの違いもあわせて記載したいと思います。
11gでは再帰withの中で、collectionは使えて、12cでは使えませんでした。。
【11g】
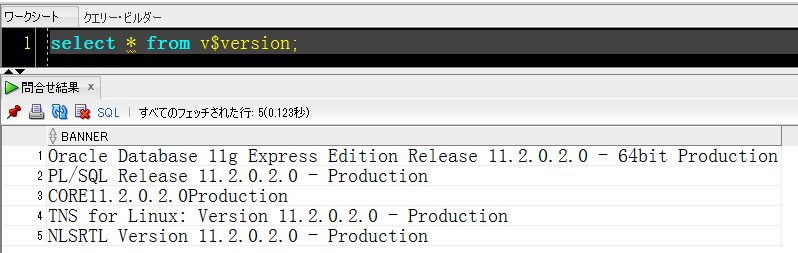
【12c】
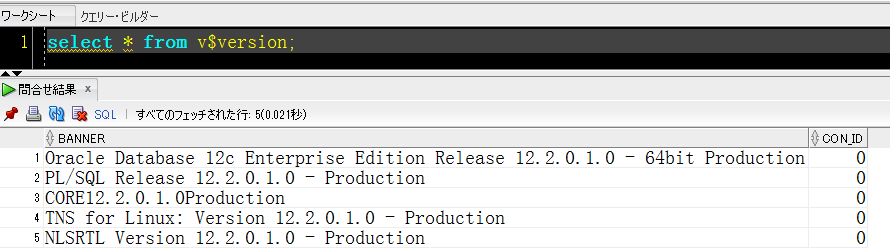
まずは11gからです。
drop table test_tbl;
create table test_tbl (id,item) as (
select 1 ,'A0001' from dual union all
select 2 ,'A0002' from dual union all
select 3 ,'A0003' from dual union all
select 4 ,'A0004' from dual union all
select 5 ,'A0005' from dual union all
select 6 ,'A0006' from dual union all
select 7 ,'A0007' from dual union all
select 8 ,'A0008' from dual union all
select 9 ,'A0009' from dual
)
;
drop type item_tbl;
create type item_tbl is table of varchar2(100);--テーブルのカラム値をcollectionに格納するための変数宣言
WITH rec (
lv
,TARGET
,list
) AS (
SELECT
1
,ID
,item_tbl(item)--collectionの形でカラム値を保持
FROM
test_tbl
UNION ALL
SELECT
lv + 1
,ID
,list MULTISET UNION item_tbl(item)--結合条件満たした分のみ、collectionに追加していく
FROM
rec
INNER JOIN test_tbl
ON
TARGET < ID
)
SELECT
*
FROM
(
SELECT
grp
,row_number() OVER(
PARTITION BY grp
ORDER BY
COLUMN_VALUE
) AS rn
,COLUMN_VALUE AS item--column_valueはtable()を使用したときに現れる擬似列で、各listの要素が入っている
FROM
(
SELECT
ROWNUM grp
, lv
, list
FROM
rec
) R
CROSS JOIN TABLE ( R.list )--table()でsubquery「R」をcollectionの要素数分縦持ちに行複写したあと、テーブルに変換
)
;
【non_pivot.sqlの取得結果(一部抜粋)】
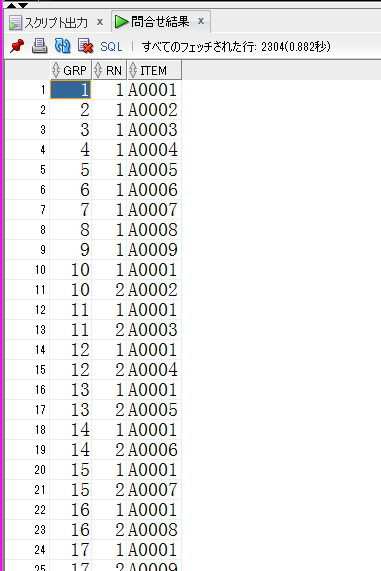
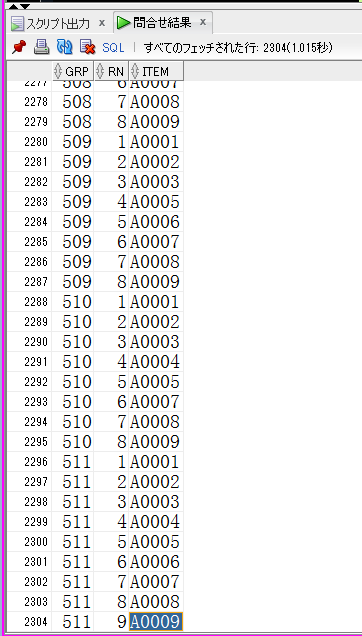
drop type item_tbl;
create type item_tbl is table of varchar2(100);--テーブルのカラム値をcollectionに格納するための変数宣言
WITH rec (
lv
,TARGET
,list
) AS (
SELECT
1
,ID
,item_tbl(item)--collectionの形でカラム値を保持
FROM
test_tbl
UNION ALL
SELECT
lv + 1
,ID
,list MULTISET UNION item_tbl(item)--結合条件満たした分のみ、collectionに追加していく
FROM
rec
INNER JOIN test_tbl
ON
TARGET < ID
)
SELECT
*
FROM
(
SELECT
grp
,row_number() OVER(
PARTITION BY grp
ORDER BY
COLUMN_VALUE
) AS rn
,COLUMN_VALUE AS item--column_valueはtable()を使用したときに現れる擬似列で、各listの要素が入っている
FROM
(
SELECT
ROWNUM grp
, lv
, list
FROM
rec
) R
CROSS JOIN TABLE ( R.list )--table()でcollectionをcollectionの要素数分縦持ちに行複写したあと、テーブルに変換
)
PIVOT (--grpごとにアイテムの要素数を横持ちに変換
MAX(item) AS item--grpごとの要素数が一意に集約されるようにするために集約関数でサマル
--max(case when rn = 1 then item else null end) as item_1
--,max(case when rn = 2 then item else null end) as item_2
--,max(case when rn = 3 then item else null end) as item_3
--,max(case when rn = 4 then item else null end) as item_4
--,max(case when rn = 5 then item else null end) as item_5
--,max(case when rn = 6 then item else null end) as item_6
--,max(case when rn = 7 then item else null end) as item_7
--,max(case when rn = 8 then item else null end) as item_8
--,max(case when rn = 9 then item else null end) as item_9
--*
--*
--*
--group by grpみたいなイメージ。ただ、明示的に集約単位を指定しているわけではないので、暗黙の集約です
FOR rn IN (1, 2, 3, 4, 5, 6, 7, 8, 9)
)
;
【pivot.sqlの取得結果(一部抜粋)】
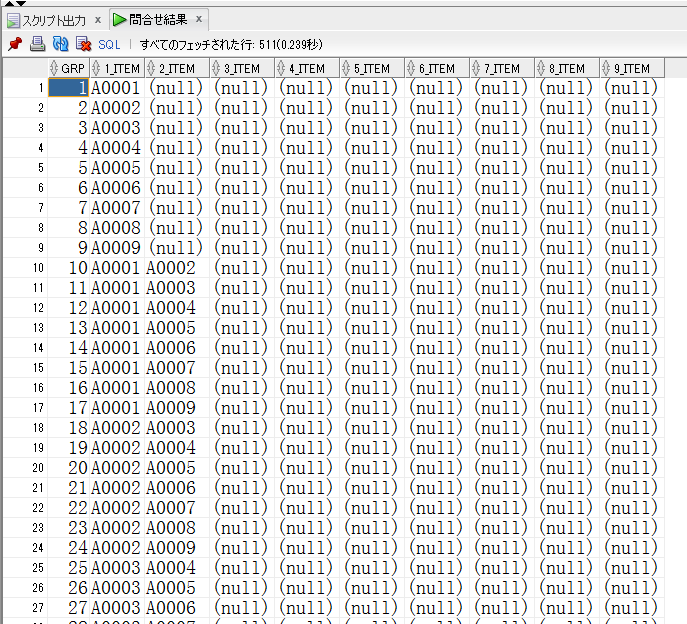
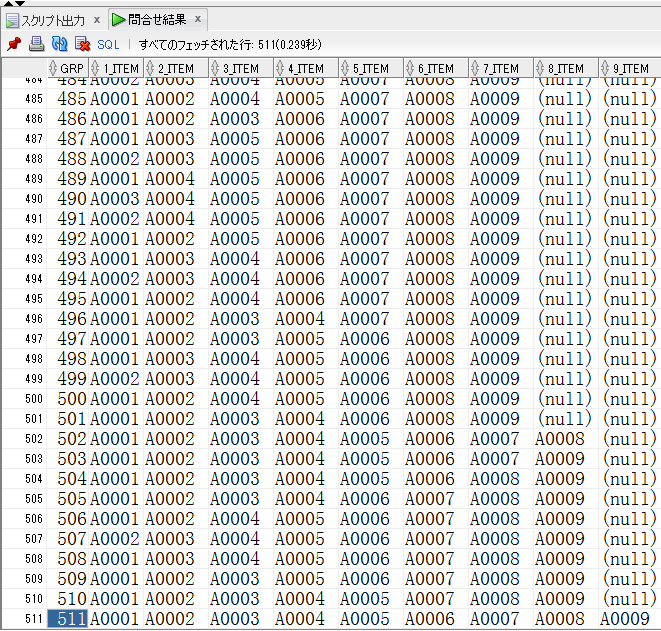
12cですと以下のようになりました。使用するsqlは同じです。
【non_pivot.sqlの取得結果(一部抜粋)】
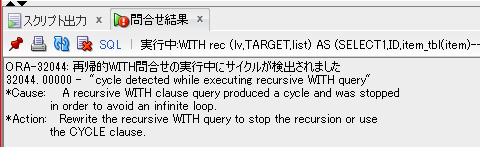
【pivot.sqlの取得結果(一部抜粋)】
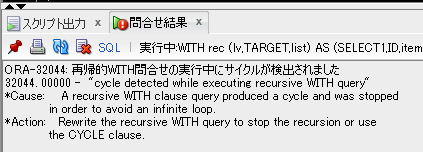
collectionとtable()について少し段階を追っていきたいと思います。
キャプチャは上が11gで下が12cの順で並べています。
まずはcollectionからです。
drop type item_tbl;
create type item_tbl is table of varchar2(100);--テーブルのカラム値をcollectionに格納するための変数宣言
SELECT
1
,ID
,item_tbl(item) as collection--collectionの形でカラム値を保持
FROM
test_tbl
;
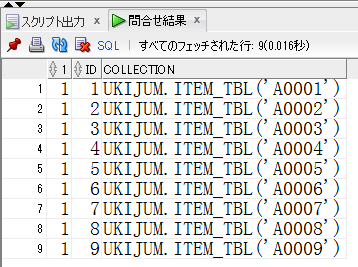
【collection_non_rec_11g.sqlの取得結果】
ukijumはスキーマ名です。。
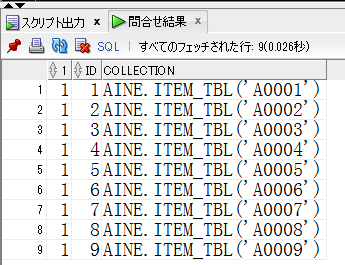
【collection_non_rec_12c.sqlの取得結果】
aineはスキーマ名です。。
drop type item_tbl;
create type item_tbl is table of varchar2(100);--テーブルのカラム値をcollectionに格納するための変数宣言
WITH rec (
lv
,TARGET
,list
) AS (
SELECT
1
,ID
,item_tbl(item)--collectionの形でカラム値を保持
FROM
test_tbl
UNION ALL
SELECT
lv + 1
,ID
,list MULTISET UNION item_tbl(item)--結合条件満たした分のみ、collectionに追加していく
FROM
rec
INNER JOIN test_tbl
ON
TARGET < ID
)
select
*
from
rec
;
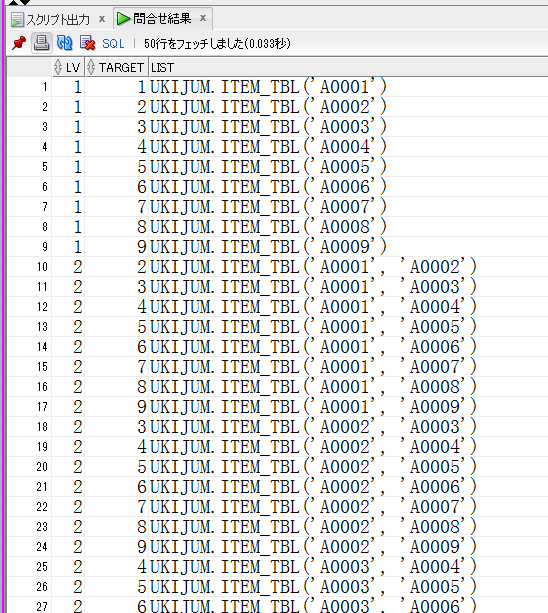
【collection_rec_11g.sqlの取得結果(一部抜粋)】
結合条件で紐づいた分だけ、カンマ区切りでうしろに溜まっていきます。
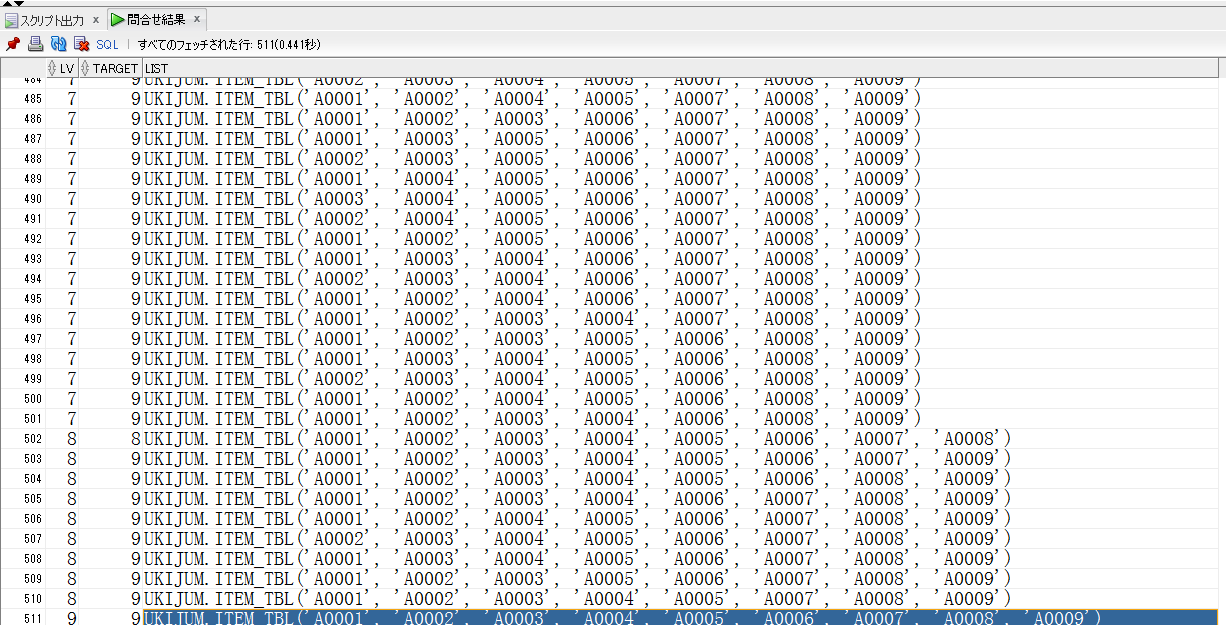
【collection_rec_12c.sqlの取得結果】
続いてtable()です。
drop type item_tbl;
create type item_tbl is table of varchar2(100);--テーブルのカラム値をcollectionに格納するための変数宣言
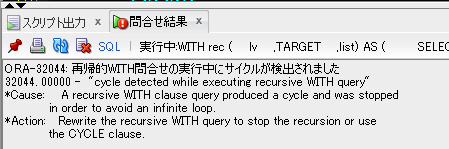
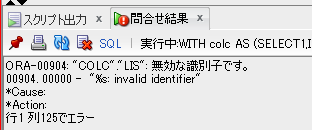
WITH colc AS (
SELECT
1
,ID
,item_tbl(item) AS lis--collectionの形でカラム値を保持
FROM
test_tbl
)
SELECT
*
FROM
TABLE(colc.lis)
;
【table()_with_subq_ng_11g.sqlの取得結果】
直接は見れませんでした。。
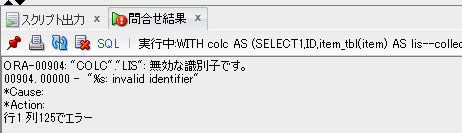
【table()_with_subq_ng_12c.sqlの取得結果】
こちらも直接は見れませんでした。。
いけたやつを。
drop type item_tbl;
create type item_tbl is table of varchar2(100);--テーブルのカラム値をcollectionに格納するための変数宣言
WITH colc AS (
SELECT
1
,ID
,item_tbl(item) AS lis--collectionの形でカラム値を保持
FROM
test_tbl
)
SELECT
*
FROM
(
SELECT * FROM colc
) tmp--table()の直前でsubqueryにしてあげる必要があるぽいです。
,TABLE(tmp.lis)--cross join TABLE(tmp.lis)と同じ
;
【table()_with_subq_ok_11g.sqlの取得結果】
column_valueはtable()をかました結果でできる列です。
collectionをテーブルに整形するには直前で流し込む感じで使います。
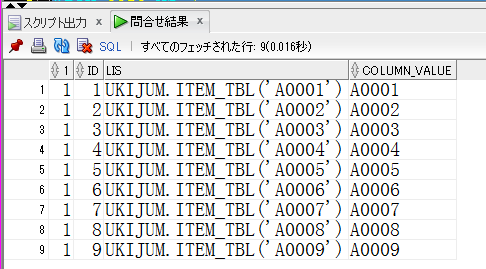
【table()_with_subq_ok_12c.sqlの取得結果】
12cでも同じように使えます。
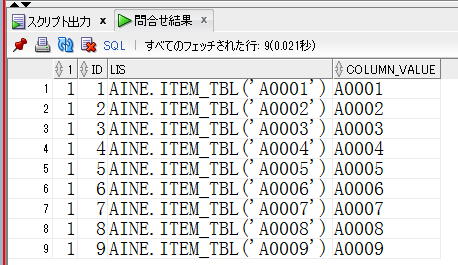
collectionとtable()とカンマ区切りはlistaggとイメージは
なんとなく似ているなーと思いました。
あと、個人的にcollectionとtable()のコンボが好きになりました!
以上、ありがとうございました。