はじめに
この記事はSnowflake Advent Calendar 2022の20日目の記事です。
18日目のrnikiさんの記事を読んで、普段あまり使っていないSnowflakeのクエリ構文が気になったので調べてみました。
引用元
Snowflakeの公式ドキュメントを参考にしています。
CHANGES
rnikiさんの記事をご参照ください。
CONNECT BY
下記のような階層化されたテーブルに対して、自己結合を行います。
クエリ例
以下のテーブルからmanagerをPresidentから辿ります。

select
sys_connect_by_path(title, ' -> '),
connect_by_root title as root_title,
level,
employee_id,
manager_id,
title
from employees
start with title = 'President'
connect by
manager_id = prior employee_id
order by employee_id;

再帰CTEと似ていますが、sys_connect_by_path, connect_by_root, levelなどの疑似列が使えます。
OBJECT_DEPENDENCIESなどで、ビューのリネージを見る際などに使えそうですね。
LATERAL
こちらはindigoさんが解説記事を出されています。
MATCH_RECOGNIZE
演算子を自分で定義して、それにあてはまるパターンにマッチングする行を取得します。パターンとしては以下のようなものがあります。
- 前行から増加/減少している
- ウィンドウ内の平均より大きい/小さい
クエリ例
ドキュメントの例そのままですが、株価がv字になっている時期を集計します。
select * from stock_price_history
match_recognize(
partition by company
order by price_date
measures
match_number() as match_number,
first(price_date) as start_date,
last(price_date) as end_date,
count(*) as rows_in_sequence,
count(row_with_price_decrease.*) as num_decreases,
count(row_with_price_increase.*) as num_increases
one row per match
after match skip to last row_with_price_increase
pattern(row_before_decrease row_with_price_decrease+ row_with_price_increase+)
define
row_with_price_decrease as price < lag(price),
row_with_price_increase as price > lag(price)
)
order by company, match_number;
pattern句で増減のパターン(減少2回以上->増加1回以上)、defineで増加、減少の演算子を指定している感じですね。
with句で地道にクエリするのとあまり変わらない気もしますが、、、パターンが柔軟に指定できるのはよさそうです。
SAMPLE
テーブルからランダムにサンプリングします。
クエリ例
test_tableから10%サンプリングする
select * from test_table sample (10);
sample system (10)で行をいくつかのブロックに分割してサンプリングするみたいです。
連番で何回か試してみましたが、特に通常と差があるようには見えませんでした。
開発環境のデータ生成などによさそうです。
GROUP BY ...
以下のようなテーブルを例に考えます。
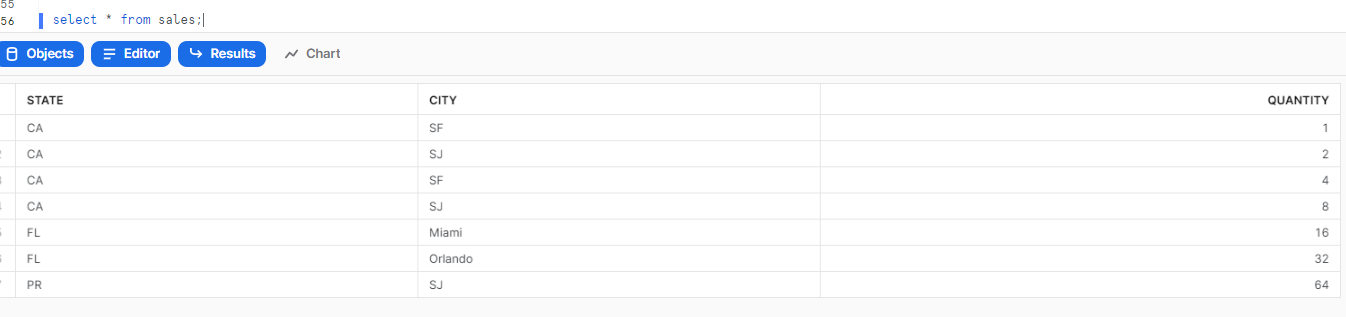
GROUP BY GROUPING SETS
group by a union all group by bと等価です
クエリ例
select
state,
city,
sum(quantity)
from
sales
group by grouping sets (state, city);

count distinctなどでそれぞれの列で足し上げが不可能な場合で集計をしたい場合に便利ですね。
GROUP BY ROLLUP
通常のgroup byに加えて集計列で合計した行を生成します。
クエリ例
select
coalesce(state, 'all') as state,
coalesce(city, 'all') as city,
sum(quantity)
from
sales
group by rollup (state, city);
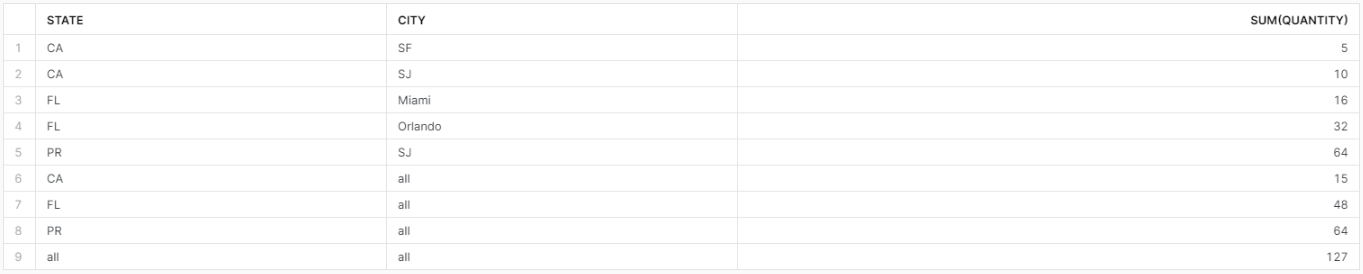
小計行はNULLで表示されます(今回はallで埋めました)。通常のNULLとは意味合いが異なるので、事前のNULL埋めがマストになります。
rollupは右から行われるためgroup by rollup (大項目, 中項目, 小項目)のように並べる必要があります。
NULLがある場合の挙動
適当にNULLが入った列を追加します。
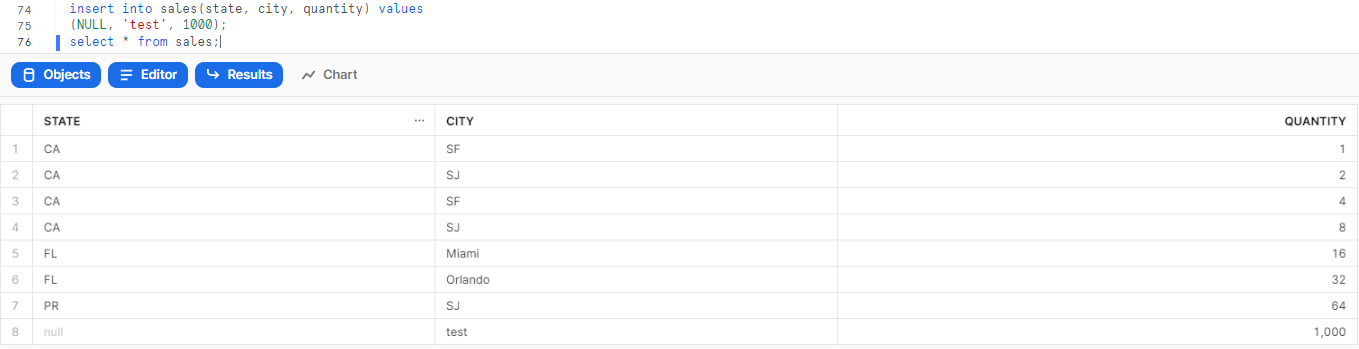
もう一度同じクエリを実行します。
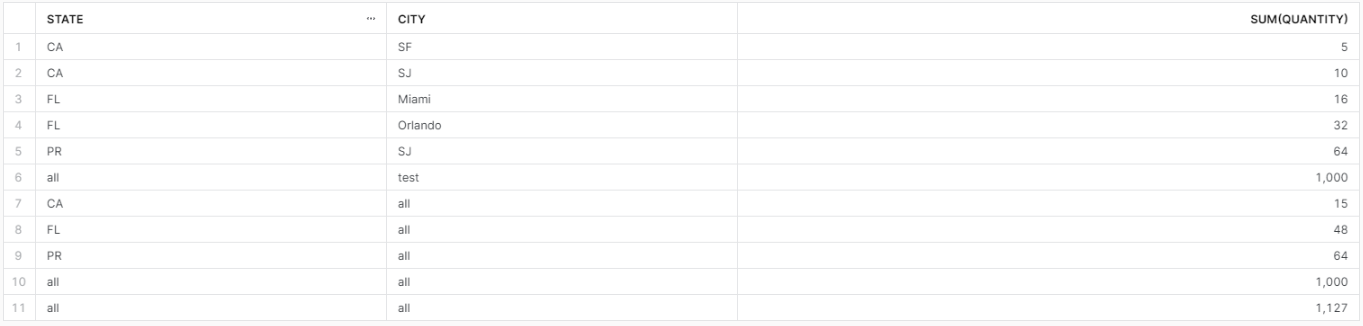
10行目と11行目に重複が発生していますね。こういった場合は事前にcteでNULL埋めの必要がありそうです。
GROUP BY CUBE
group by rollupと似ていますが、クロス集計を行った行を追加します。
クエリ例
select
coalesce(state, 'all') as state,
coalesce(city, 'all') as city,
sum(quantity)
from
sales
group by cube (state, city);
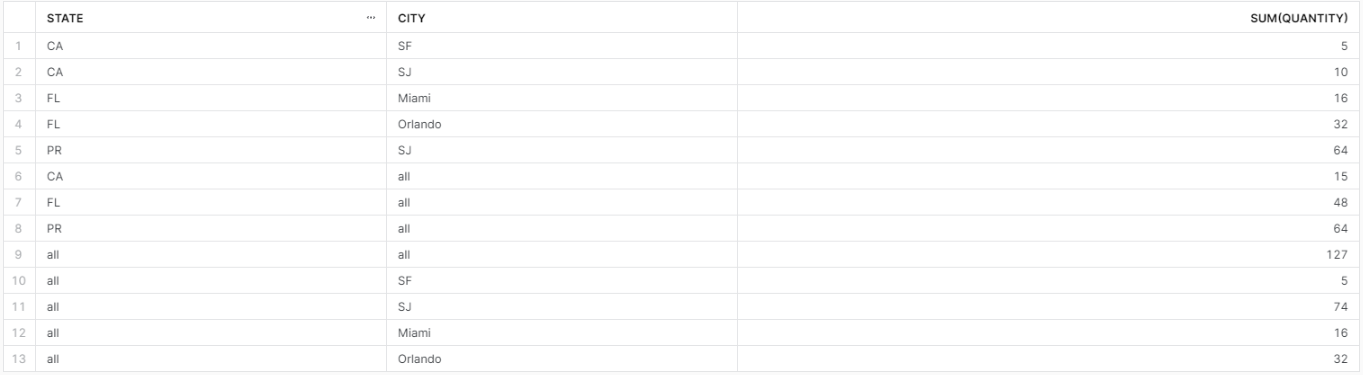
group by rollupでは小計列はSTATE列での集計と全体のみでしたが、こちらはCITY列での集計も行われています。こちらは(STATE, CITY)のように包含関係のある列では使わずに、それぞれが独立した属性を持った列どうしで集計する際に有用ですね。
QUALIFY
ウィンドウ関数でのフィルタを行います。
クエリ例

山田家、田中家から一番年齢の高い人物を取得します。
select
*
from
family
qualify row_number() over (partition by last_name order by age desc) = 1;

cte内でrow_number()を書いてからwhere句で絞り込まなくてもよくなるので、少しクエリが短くなりますね。
実行計画は同じだったので、速度は特に変わらないと思います。