はじめに
久しぶりにPythonの記事を書いてみました。おそらく最近は仕事、プライベートでビデオチャットを使うことが多くなったかと思います。今回はPythonとOpenCVを使ってビデオチャットをもっと楽しくするようなハックをしてみようかと思います。
つくるもの
せっかくのビデオチャットなので普段の自分とは違う姿になりたいなと誰もが思うはずです。今回は以下のような感じで「手をかざすと魔法陣が出てくる」ようなSnap Cameraもどきを作ってみます。

手の検出
手の検出にはOpenCVでサポートされているカスケード分類器を使用します。詳しい内容はこちらの記事を参照してみてください。簡単に説明すると物体検出をしてくれるライブラリです。OpenCVの導入方法については、OSによって異なるのと既に多くの記事が出回っているのでここでは省略いたします。
OpenCVでのカスケード分類器は「顔の検出」がメジャーかと思います。このカスケード分類器のモデルを自分で組み立てるのはものすごく大変な作業になるのでこちらの学習済みモデルを公式より拝借いたしました。
魔法陣の表示について
魔法陣の表示は単純に検出した手に魔法陣を被せるだけなのですが、それだと透過してくれないのでこちらを参考にしながらマスクを使用した画像合成を実装しました。
実装
コードは以下のような感じです。普段Pythonはあまり書かないので多少の汚さはご容赦ください。
import cv2
import numpy as np
import random
def masking(background, foreground, size):
gray = cv2.cvtColor(foreground, cv2.COLOR_BGR2GRAY)
_, binary = cv2.threshold(gray, 90, 255, cv2.THRESH_BINARY_INV)
_, contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
mask = np.zeros_like(foreground)
cv2.drawContours(mask, contours, -1, color=(255, 255, 255), thickness=-1)
roi = background[size[0]:size[2], size[1]:size[3], :]
result = np.where(mask==255, foreground, roi)
return result
def HandDetector(img):
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img_rgb = clahe.apply(img_rgb)
hand_rects = hand_cascade.detectMultiScale(img_rgb, 1.1, 5)
if len(hand_rects) > 0:
for i, (x,y,w,h) in enumerate(hand_rects):
size = [y-h//2, x-w//2, y+h//2*3, x+w//2*3]
if i == 0 and size[0] > 0 and size[1] > 0 and size[2] < img.shape[0] and size[3] < img.shape[1]:
magicsquare = cv2.imread(magic)
hand = img[size[0]:size[2], size[1]:size[3]]
magicsquare = cv2.resize(magicsquare, (hand.shape[0], hand.shape[1]))
magicsquare = masking(img, magicsquare, size)
img[size[0]:size[2], size[1]:size[3]] = magicsquare
center = np.array([x+w//2, y+h//2])
return img
cascade_path = "./data/aGest.xml" # 手の検出用モデルの読み込み
hand_cascade = cv2.CascadeClassifier(cascade_path)
clahe = cv2.createCLAHE(clipLimit=1.5, tileGridSize=(8,8))
cap = cv2.VideoCapture(1)
magic = './魔法陣の画像のPath.jpg'
while True:
ret, frame = cap.read()
frame = cv2.flip(frame, 1)
height, width, channels = frame.shape
frame = HandDetector(frame)
cv2.namedWindow('img', cv2.WINDOW_NORMAL)
cv2.imshow('img', frame)
c = cv2.waitKey(1)
if c == 27:#ESC
break
cap.release()
cv2.destroyAllWindows()
HandDetectorで手の検出、maskingで魔法陣を透過させるように合成させるといった感じです。後はimgshowで実際に合成させた映像を表示させます。
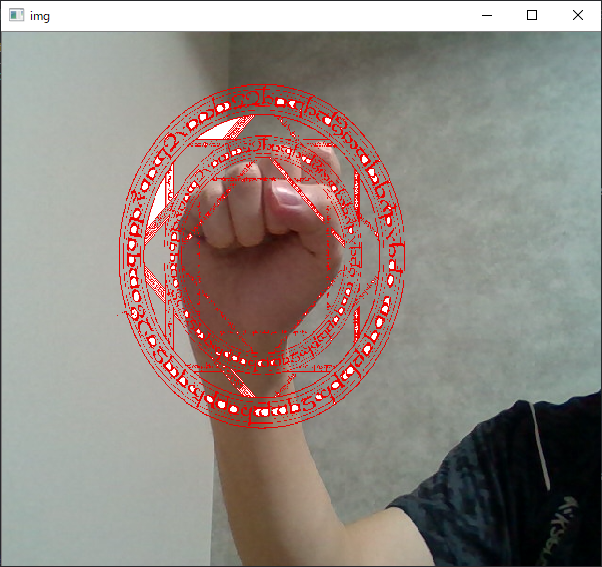
こんな感じでできました!魔法陣はどこかのフリーのものを拾ってきました。
ビデオチャットで使ってみる
せっかく作ったのでこれを実際のビデオチャットでも使ってみたいですよね。今回は簡単のためにSplitCamを使って、imgshowで出力した映像を仮想デバイスとして出力させました。あとはそれをビデオチャットツールに入力させました(今回は話題のZoomを用います)。以下で簡単にSplitCamでの手順を説明します。
Media Layersと呼ばれる操作エリアに「+」のボタンがあるのでそれをクリックすると以下のようなプルダウンメニューが表示されます。そのままScreenshareを選択します。するとプルダウンメニューがまた出てくるので、imgをAddします(上記のコードをそのまま実行した場合)。
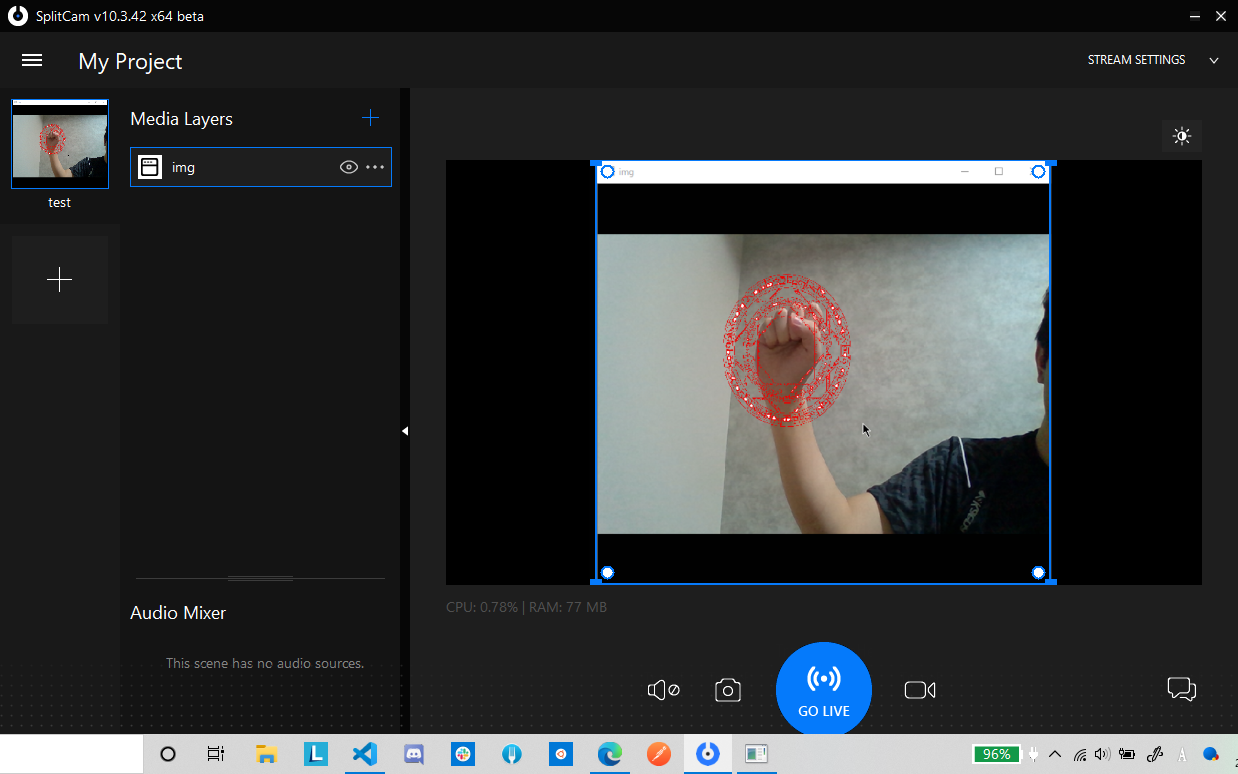
するとこんな感じにPythonで出力した映像がキャプチャされました。
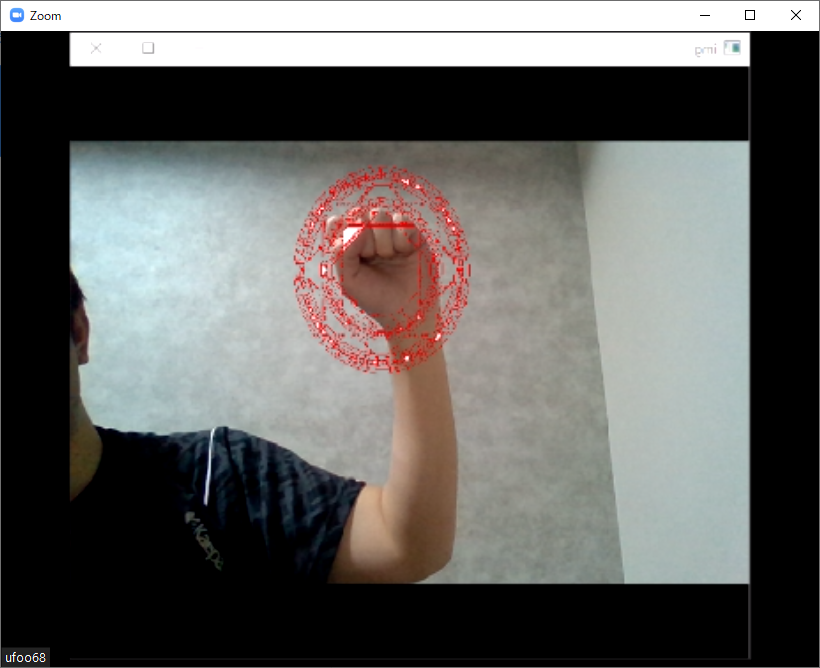
このままZoomを開くとカメラの選択メニューからSplitCam Video Driverが選択できるようになったのでそれを選びます。するとZoomにPythonからの映像を出すことができました!
さいごに
今回のコードを一応gistにも公開しておきます。画像や学習済みモデルは拾いものなので各自で探してください。学習済みモデルのリンクをここに再掲します。
ただこの手の検出なのですが、グーの形しか検出できないのでもう少しバリエーションのある手の画像を検出させたいですね。そうなるとTensorFlowに久しぶりに手を出すことになりそう。