こんにちは。機械学習系のデモや、最近だとChatGPTなどLLMのチャットクライアントを作るのに人気のStreamlitについて、一度にどれくらいの人がアクセスできるのか調べてみました。
結論としては100人規模くらいまでだと問題なく使えるようです(本記事では200多重を問題なくクリア)。バックエンドの処理にかかるリソースの方を気にした方が良さそうでしょう。
それでは、具体的に何をどう調べたのか記事でご紹介していきます。
調べたきっかけ💡
VSSLiteという、ChatGPTによるRAGという手法を使ったQ&Aシステムを簡単に構築するライブラリーをOSSとして公開しているのですが、このChatUIとしてStreamlitを採用しています。もともとゴリゴリの本番用途を想定していないものの、何人くらいまでなら同時に使えるのか気になったので確かめてみたというものです。
そこでStreamlitのコミュニティーでのやりとりを見ると、以下のような記述がありました。
when a user connects to Streamlit, we spin up a thread just for them and run your app.py script for that user. And then Streamlit will re-run that script for that user each time they do something interactive (like pressing a button or sliding a slider); and each time the script is re-run, we spin up and down a thread again to run it.
リクエストごとにStreamlitのスクリプトが新たなスレッドで実行されるとあります。スレッド数の上限にぶつかって多重度の上限になるのでは?と思ったりしたので、今回実際に調べてみたというものです。
調べ方🔍
Streamlitにスレッドをブロックする重い処理(ここではSleep)を仕込んで、同時にリロードをかけます。終了時間をコンソールに出力することで、処理がブロックされた場合はSleep秒数分ずれて開始される(終了もその分ずれる)ものがないかを確認します。
なお、Streamlitにはアプリのスクリプトを更新して保存するとブラウザー側にリロードさせる機能があるため、今回はこれを利用することで一気にリロードをかけていきます。
用意したスクリプトは以下の通りです。
Streamlitアプリ
10秒待ってログを出力して終わるだけのものです。
import os
from datetime import datetime
from time import sleep
import threading
import streamlit as st
sleep(10.0)
log_str = f"{os.getpid()}: {threading.current_thread().ident}: {datetime.utcnow()}"
st.write(log_str)
print(log_str)
クライアントアプリ
指定枚数のブラウザーを開いて、Streamlitアプリを表示します。ここではまず4枚にしています。
import webbrowser
for i in range(4):
print(i)
webbrowser.open(f"http://localhost:8501?i={i}", 1)
検証と結果🧪
以下のシリーズで検証しました。
- 4多重
- 100多重
- 200多重
- 200多重(REST API呼び出しの待ち)
4多重での結果
まずはお手並み拝見で4多重で開いてみました。
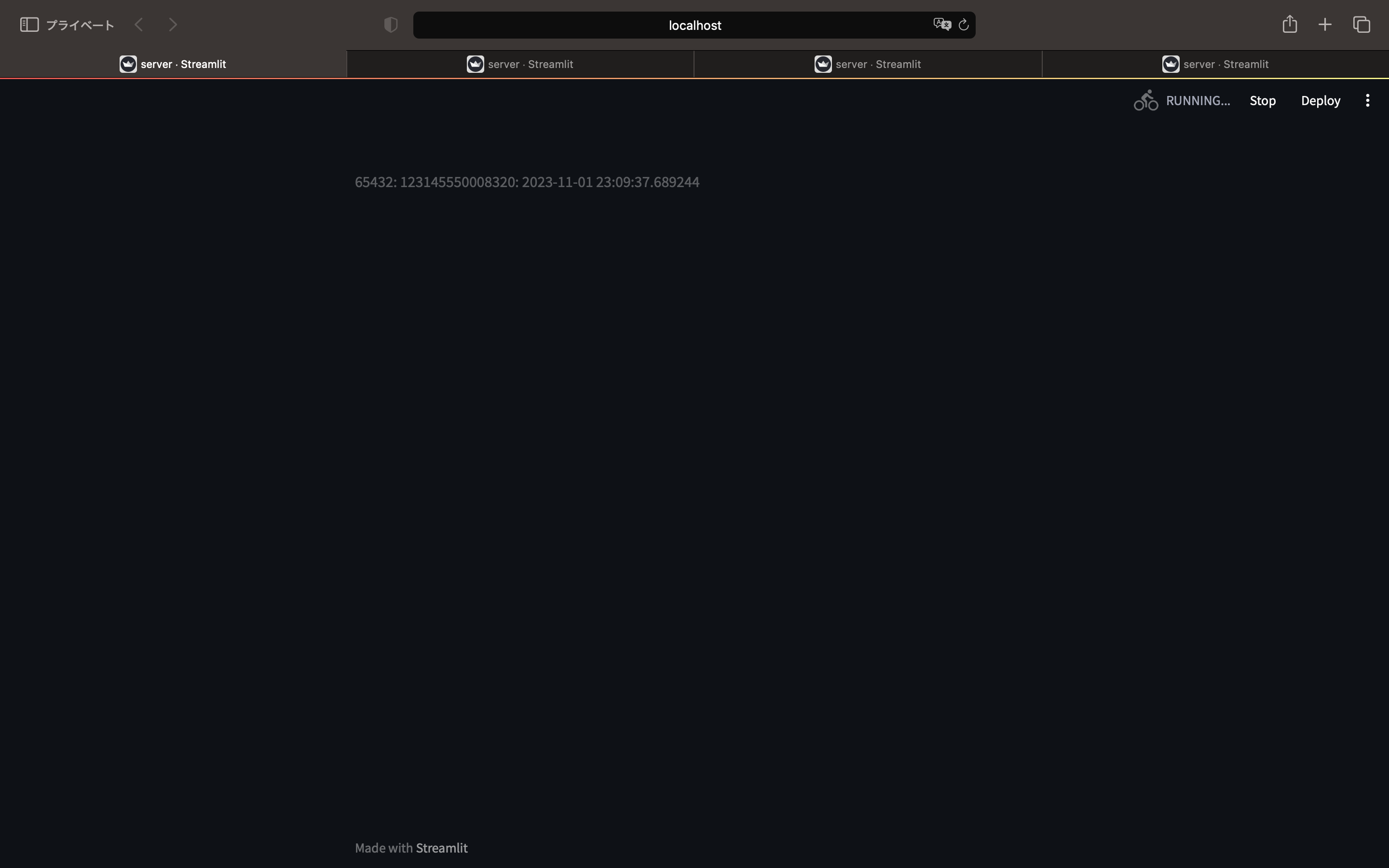
Steamlitアプリのログは以下の通りです。
65432: 123145499639808: 2023-11-01 23:10:04.806247
65432: 123145550008320: 2023-11-01 23:10:04.843306
65432: 123145566797824: 2023-11-01 23:10:04.936511
65432: 123145583587328: 2023-11-01 23:10:05.008870
微妙にずれていますが、10秒のずれはないので並列処理されていると思われます。また、全てが同一のプロセス(ID=65432)の別スレッド(ID=123145499639808、ほか)で動作したことがわかります。
100多重での結果
ちまちまやっても仕方がないので一気に増やします。
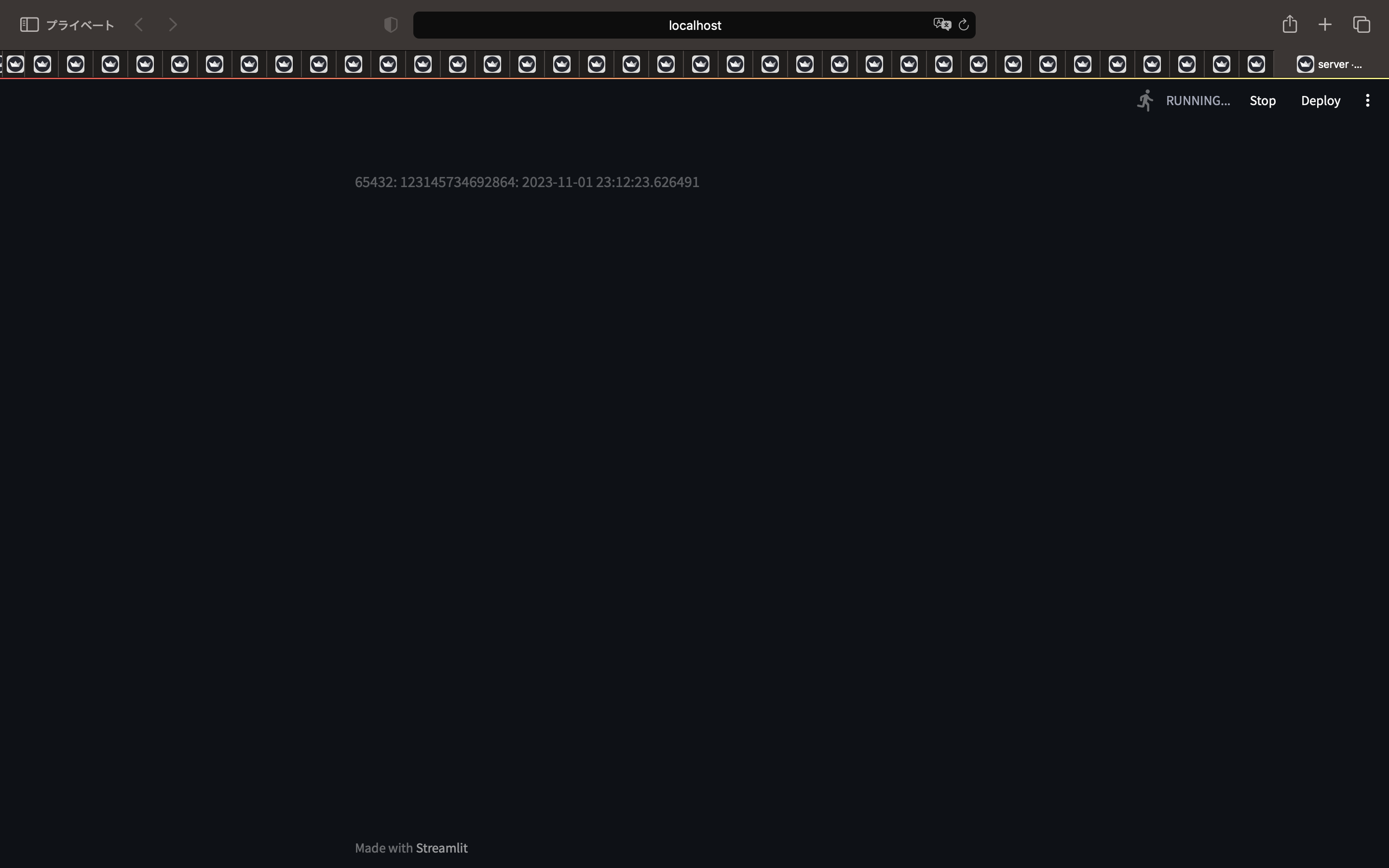
ログは以下の通り。
65432: 123145499639808: 2023-11-01 23:12:57.316321
65432: 123145583587328: 2023-11-01 23:12:57.368176
65432: 123145566797824: 2023-11-01 23:12:57.405504
65432: 123145550008320: 2023-11-01 23:12:57.367931
65432: 123145600376832: 2023-11-01 23:12:57.518936
(中略)
65432: 123147128221696: 2023-11-01 23:13:02.207040
65432: 123147161800704: 2023-11-01 23:13:02.252416
65432: 123147145011200: 2023-11-01 23:13:02.253220
65432: 123147178590208: 2023-11-01 23:13:02.306079
65432: 123147195379712: 2023-11-01 23:13:02.416480
微妙なズレが積み重なって、最初と最後とで5秒ずれました。しかしながら10秒はずれていませんので、並列処理されていると思っても良いのではないでしょうか。もし並列処理できていないとすれば、処理にかかる時間によりこのズレが大きくなるはずなので、Sleepの時間を30秒にしてリトライした結果は以下の通りです。
65432: 123145499639808: 2023-11-01 23:14:45.652605
65432: 123145566797824: 2023-11-01 23:14:45.690380
65432: 123145550008320: 2023-11-01 23:14:45.692074
65432: 123145583587328: 2023-11-01 23:14:45.860833
65432: 123145617166336: 2023-11-01 23:14:45.909181
(中略)
65432: 123147128221696: 2023-11-01 23:14:50.579358
65432: 123147161800704: 2023-11-01 23:14:50.626528
65432: 123147178590208: 2023-11-01 23:14:50.626972
65432: 123147145011200: 2023-11-01 23:14:50.627483
65432: 123147195379712: 2023-11-01 23:14:50.785922
ズレは5秒間で、10秒の時と同じでした。処理時間が並列処理に与えているわけではなさそうです。
200多重での結果
枚数を200に増やしてみます。また、処理時間(sleep時間)は30秒のままです。
65432: 123145550008320: 2023-11-01 23:22:36.348929
65432: 123145566797824: 2023-11-01 23:22:36.415134
65432: 123145499639808: 2023-11-01 23:22:36.465294
65432: 123145583587328: 2023-11-01 23:22:36.516872
65432: 123145617166336: 2023-11-01 23:22:36.568418
(中略)
65432: 123148857540608: 2023-11-01 23:22:46.500898
65432: 123148840751104: 2023-11-01 23:22:46.499789
65432: 123148807172096: 2023-11-01 23:22:46.501530
65432: 123148823961600: 2023-11-01 23:22:46.500552
65432: 123148874330112: 2023-11-01 23:22:46.612816
ズレが10秒間になりました。枚数が増えれば増えるほどリニアにズレるようですが、いずれにしても30秒ずれるものがないのでブロックされているわけではなさそうです。
REST APIで200多重
個人的に一番気にしているのは、API呼び出しの待ち時間にスレッドがブロックされることで多重度が頭打ちになるというものです。そこで以下のようなレスポンスに30秒かかるAPIサーバーを作成し、sleepの代わりにこのAPIの呼び出しを待つように変更して結果に変化がないかみてみることにしました。
from fastapi import FastAPI
from asyncio import sleep
from datetime import datetime
app = FastAPI()
@app.get("/")
async def root():
print(f"{datetime.utcnow()}")
await sleep(30.0)
return "ok"
なおStreamlit側は以下の通りです。
import os
from datetime import datetime
from time import sleep
import threading
import streamlit as st
import requests
# sleep(30.0)
requests.get("http://127.0.0.1:8000/")
log_str = f"{os.getpid()}: {threading.current_thread().ident}: {datetime.utcnow()}"
st.write(log_str)
print(log_str)
結果です。
65432: 123145499639808: 2023-11-01 23:31:15.446009
65432: 123145566797824: 2023-11-01 23:31:15.524414
65432: 123145550008320: 2023-11-01 23:31:15.589050
65432: 123145583587328: 2023-11-01 23:31:15.590601
65432: 123145600376832: 2023-11-01 23:31:15.654893
(中略)
65432: 123148807172096: 2023-11-01 23:31:25.641415
65432: 123148823961600: 2023-11-01 23:31:25.817275
65432: 123148723224576: 2023-11-01 23:31:25.231936
65432: 123148756803584: 2023-11-01 23:31:25.408198
65432: 123148857540608: 2023-11-01 23:31:25.642219
Sleepのときと何ら変化ありませんでした。大丈夫そうです。
なおAPI側は以下の通り出力されていましたので、きちんとAPIアクセスもされていることが確認できます。
2023-11-01 23:30:45.443161
2023-11-01 23:30:45.468665
2023-11-01 23:30:45.508950
2023-11-01 23:30:45.513844
2023-11-01 23:30:45.648047
(中略)
2023-11-01 23:30:55.502404
2023-11-01 23:30:55.592280
2023-11-01 23:30:55.611339
2023-11-01 23:30:55.615575
2023-11-01 23:30:55.705953
結論🥳
これまでの実験から、以下のことがわかりました。
- Streamlitは3桁規模までの多重度で処理することが可能
- 具体的にはスレッドをブロックして応答を待機するAPI呼び出し処理で上記を実現
- 全てのリクエストは同一プロセス・個別のスレッドで動作
また、以下についてはわかりませんでした。ソースコードを読み解けばわかりそうですが、ご存じの方・ヒントをお持ちの方は教えていただけるとうれしいです✨🙏✨
- 並列処理されるが、終了タイミング(おそらく開始タイミングも)にわずかにズレがある(100多重で5秒)。勘でしかないですが、ブラウザー側へのリロード要求の通知タイミングがズレるからとかでしょうかね
- 何多重までいけるのか。上限はよくわかりませんでした。たとえば
concurrent.futuresのワーカーには以下のように明示的な上限があります。これみたいなものがあるのかないのか、よくわかりませんでした
Default value of max_workers is changed to min(32, os.cpu_count() + 4). This default value preserves at least 5 workers for I/O bound tasks. It utilizes at most 32 CPU cores for CPU bound tasks which release the GIL. And it avoids using very large resources implicitly on many-core machines.
・・・ということで、100人くらいでデモ利用する程度であれば、Streamlit自体がネックとなって多重度が頭打ちになることはなさそうです。とはいえ今回リソースの使われ方はみていないので、大人数で利用する際にはそのあたりも調べて(できれば記事として公開して🙏)からの方が良いでしょう。